

本文始发于个人公众号:TechFlow
在计算机系统的领域,一致性可以说是一个高频词,可能出现的场景很多。从分布式系统到数据库的事务,都有它的身影。
之前我们在介绍数据库事务的时候,谈到过事务的一致性。在数据库当中,一致性是一种目的,不是一种手段。数据库希望控制事务的原子性、隔离性和持久性来保证数据的一致性。这里的一致性更多的指的是实际和我们观念的一致。也就是说结果都在我们预期之内。而在分布式系统当中,一致性有另外的含义,一个是多份数据副本之间的一致性问题,另一个是多阶段提交的一致性问题。我们今天先来聊聊副本一致性问题。
这个问题出现的原因很简单,因为分布式系统当中,数据往往会有多个副本。如果是一台数据库处理所有的数据请求,那么通过ACID四原则,基本可以保证数据的一致性。而多个副本就需要保证数据会有多份拷贝。这就带来了同步的问题,因为我们几乎没有办法保证可以同时更新所有机器当中的包括备份所有数据。尤其是当这些机器分布在全国各地甚至是世界各地的时候,由于网络延迟,即使我在同一时间给所有机器发送了更新数据的请求,也不能保证这些请求被响应的时间保持一致。只要存在时间差,就会存在某些机器之间的数据不一致的情况。也就是说,在分布式系统当中的一致性,指的是数据一致性。
这其实是一个两难问题,为了解决流量过大的压力问题,我们设计了分布式系统。但是分布式系统又会带来数据多份拷贝不同步违反一致性的问题,我们既不能容忍数据出错,也不能放弃分布式系统,唯一的办法就是采取一些措施,来最大可能地降低这个问题的影响力。
多种多样的一致性模型,就是这些措施的体现。让我们从最简单的严格一致性说起。
严格一致性
严格一致性是最理想的情况,如果我们每次请求一个数据,不管什么情况下,我们都能获得它的最后一次改动的结果。很遗憾的是,严格一致性是不可能实现的。
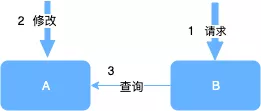
不可能实现的原因很简单,因为多台机器之间的数据同步需要时间,无论这个时间多小,它都是确定存在的。只要存在,就不可能实现严格一致性。举个简单的例子,我们有A和B两台机器。在t时刻,A机器修改了某条数据,在1毫秒之前,B机器收到了一条查询该数据的请求。当B执行这个查询的时候,A机器已经修改完成,那么究竟B查询到的值应该是什么呢?是A修改之前的还是修改之后的呢?在A机器看来,B的查询发生在它修改之后,可是B机器看来却恰恰相反,A修改值发生了在它收到请求之后。如果我们要保证严格一致性,那么究竟什么结果才是对的呢?
当然上面这个例子只是最极端的情况,一般只会在理论上发生,但是通过对极端情况的分析,我们也可以看得出来,严格一致性是不可能实现的。
强一致性与弱一致性
数据不一致出现的根本原因在于多台机器更新数据的时间差,我们更新多台机器,总有先有后,很难保证完全同步。根据同步数据时采用同步还是异步策略,又可以将一致性分为强一致性与弱一致性。
使用同步策略更新数据时,我们每次请求发给主节点,主节点收到数据之后使用同步更新的策略将数据发送给从节点。当所有的从节点更新成功之后,主节点会更新数据的状态,使它生效,之后返回response给用户,告知更新成功。
显然,通过同步更新数据的策略下,一致性的保障更强。如果我们在主机上做好隔离措施,比如在更新结束之前,用户不能发起下一次更新,那么尽可能地保证数据一致性不出问题。但是这种做法也有很大的弊端,最大的弊端就在于使用同步更新的操作,而且要所有从库都更新成功才能返回,这样的时间开销非常大。最关键的一个缺点在于,如果一个从库宕机,那么主库就不可能更新所有的从库,那么新来的请求永远不会更新,这显然是不能接受的。
和强一致性对应的是弱一致性,我们不采用同步策略来更新数据,而采用异步更新的方式。好处也很明显,同步改成了异步,时间消耗大大缩减。但是问题也很明显,除了异步本身带来的问题之外,由于多个副本之间的数据更新发生不同时,如果连续多次访问落到了不同的副本上,就会出现多次访问的结果不一致的情况。
本质上来说分布式系统的一致性模型,只有强弱两种。只不过在这两种基础的模型上,针对许多可能出现的问题还会进行相应的优化。总体上而言,分布式系统对于性能的要求要高于一致性,所以大多分布式系统的一致性模型,还是基于弱一致性设计的。下面就来列举几种,比较经典的弱一致性模型的优化方案。
读写一致性
读写一致性在日常中经常遇见,比如在某论坛当中,用户回复了某个帖子。但是当用户刷新的时候,可能会出现这个回复消失的情况。用户会陷入困扰,不知道这个回复究竟有没有成功。

会发生这种情况的原因也很简单,因为用户刷新的时候,访问的从库可能还没有获取到用户回复的数据,所以显示的结果当中自然就没有用户刚刚回复的内容。在这种情况下,我们需要保证读写一致性。也就是说用户读取自己写入结果的一致性,保证用户永远能够第一时间看到自己更新的内容。比如我们发一条朋友圈,朋友圈的内容是不是第一时间被朋友看见不重要,但是一定要显示在自己的列表上。
那如何实现呢?
方案有好几种,一种方案是对于一些特定的内容我们每次都去主库读取。比如我们读取帖子当中回复信息的时候,永远都去主库读取。但是这样的问题也很明显,可能会导致主库的压力过大。另一种方案是我们设置一个更新时间窗口,在刚刚更新的一段时间内,我们默认都从主库读取,过了这个窗口之后,我们会挑选最近有过更新的从库进行读取。
还有一种更好的方案是我们直接记录用户更新的时间戳,在请求的时候把这个时间戳带上,凡是最后更新时间小于这个时间戳的从库都不予以响应。也就是说只有包含用户写入这个更新的库可以响应这个请求,就可以保证实现用户端的读写性一致了。
单调读
单调读解决的是最经典的弱一致性的不一致问题,出现的场景也很简单。由于主从节点更新数据的时间不一致,导致用户在不停地刷新的时候,有时候能刷出来,再次刷新之后会发现数据不见了,再刷新又可能再刷出来,就好像遇见灵异事件一样。我记得以前微博或者人人就存在这个问题,单调读就是针对的这个场景,可以保证不会出现这种情况。
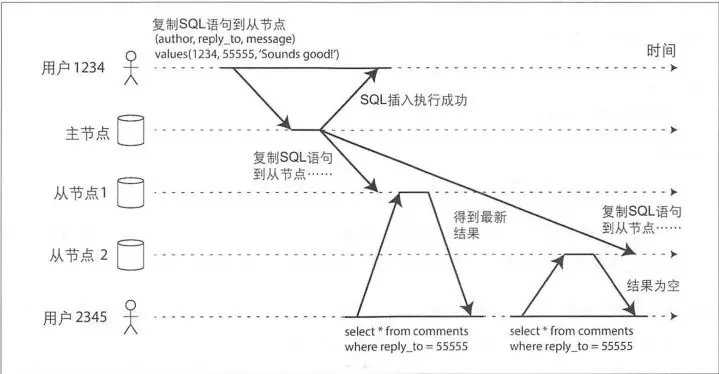
解决的方法其实很简单,就是根据用户ID计算一个hash值,再通过hash值映射到机器。同一个用户不管怎么刷新,都只会被映射到同一台机器上。这样就保证了不会读到其他从库的内容,带来用户体验不好的影响。当然,这只是一种解决方案,其他的解决方法还有很多,这里不一一讨论。
因果一致性
因果一致性针对的数据之间逻辑上的因果问题,举个例子,比如说用户在知乎里提问题和回答问题。想要回答问题,必须要保证有对应的问题。也就是说一定是先有问题,再有的回答。可是问题和回答并不一定存储在同一个节点上,很有可能出现问题存入节点A,回答存入节点B的情况。因为存在同步延迟,所以就可能出现查询的用户只看得到回答,却找不到对应问题的情况,违反了事物之间的因果性。
为了解决这个问题,一种方案是在写入的时候遵循某种逻辑顺序,那么在读取的时候,就可以保证不会出现因果错乱的情况。但问题是,很多因果性并不想问题和回答这么明显,一些隐藏的因果性可能很难被轻易判断,就需要引入更高深的技术,感兴趣的同学可以去搜索一下向量时钟深入了解。
最终一致性
听名字这种方案似乎很厉害,其实最终一致性是所有分布式一致性模型当中最弱的。可以认为是没有任何优化的“最”弱一致性,它的意思是说,我不考虑所有的中间状态的影响,只保证当没有新的更新之后,经过一段时间之后,最终系统内所有副本的数据是正确的。
有大神打了这么一个比方,就好像你去点星巴克。你并不知道星巴克什么时候做好,你在做好之前去拿,拿到的结果是错的。但是你知道,经过一段时间之后,你一定可以拿到你想要的。至于星巴克做好需要多久,往往没有定论,可以是几百分之一秒,也可以是几个小时。
听起来这个方案很不靠谱,在确定它可行之前,我们还想问几个问题,首先,系统能不能保证一段时间是多久?如果天荒地老怎么办?其次,因为最终才能收敛,那么在收敛之前,多个副本之间的值可能都不同,究竟又该以哪个为准?
好在,这两个问题都能回答。对于第一个问题,答案是系统没办法确定究竟需要多久收敛,但是可以确定最大的收敛时间。有点像是物理学上的半衰期,我们不知道一个粒子究竟需要多久衰变,但是可以确定足够多的粒子当中的一半衰变所需要的时间。第二个问题更好回答,当有多份数据出现的时候,通常的做法是选择其中时间戳较大的,也就是说出现较晚的值。
虽然最终一致性看起来很不靠谱,但是它最大程度上保证了系统的并发能力,也因此,在高并发的场景下,它也是使用最广的一致性模型。
到这里为止,分布式系统当中常见的一致性模型就介绍完了。分布式系统有一个很大的特点,就是我们看专业名词的时候往往云里雾里,不知所云。但是当我们去了解它背后的设计理念与出现的原因,就能发现它的有趣。衷心希望大家都能从中发现自己的乐趣,都有学有收获。
如果喜欢本文,请顺手点个关注吧,你们的支持是我最大的动力。

