

为什么要使用缓存?
缓存的应用场景是读多写少。可是秒杀,写不是很多吗?每次都要读和写。
那为什么还要使用缓存呢?没什么作用啊?有作用。缓存主要是解决读的问题。写还是每次都要走数据库。但是读是走缓存。
所以,缓存解决了读这一部分的问题。但是,并没有解决写多的问题。
能解决一部分问题,就解决一部分问题。不然,如果读也走数据库,数据库更扛不住。
缓存能解决的问题
1.提升性能
绝大多数情况下,select 是出现性能问题最大的地方。一方面,select 会有很多像 join、group、order、like 等这样丰富的语义,而这些语义是非常耗性能的;另一方面,大多数应用都是读多写少,所以加剧了慢查询的问题。分布式系统中远程调用也会耗很多性能,因为有网络开销,会导致整体的响应时间下降。为了挽救这样的性能开销,在业务允许的情况(不需要太实时的数据)下,使用缓存是非常必要的事情。// 1.数据库里包含复杂功能关键字的sql,都很慢。2.数据库是磁盘,缓存是内存。所以数据库很慢。3.数据库索引的数据结构是b+树(速度是logN),redis是map(速度是1)。所以数据库很慢。
2.缓解数据库压力
当用户请求增多时,数据库的压力将大大增加,通过缓存能够大大降低数据库的压力。//所有的socket连接都很耗资源,不管是本地socket,还是网络socket。
缓存的适用场景
1.对于数据实时性要求不高
对于一些经常访问但是很少改变的数据,读明显多于写,适用缓存就很有必要。比如一些网站配置项。
2.对于性能要求高
比如一些秒杀活动场景。//虽然秒杀是读多写也多,但是仍然还是必须要使用缓存,因为缓存可以解决读多的问题。
问题
秒杀要使用缓存,这个大家都知道。但是,使用缓存的时候,有哪些问题需要注意呢?
1.初始化缓存数据 //预热数据
2.发现热点数据
3.数据一致性问题
初始化缓存数据
为什么要初始化数据?
不是第一次读的时候,缓存没有数据,然后访问数据库吗?因为瞬间流量高峰,如果这个时候缓存没有数据,全部访问数据库,会击垮数据库。
如何实现?
启动服务的时候初始化。难道上线一个新的商品之后,还要重启服务?这不合理啊。
优化
可以做一个配置项,手动操作把数据从数据库写到缓存。这样就不需要重启服务。
三、缓存预热 缓存预热这个应该是一个比较常见的概念,相信很多小伙伴都应该可以很容易的理解,缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
解决思路:
1、直接写个缓存刷新页面,上线时手工操作下;
2、数据量不大,可以在项目启动的时候自动进行加载;
3、定时刷新缓存;
————————————————
版权声明:本文为CSDN博主「徐刘根」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:blog.csdn.net/xlgen157387…
总结
所以,按预热时间节点分为
1.启动服务时预热
有的数据是固定的,就适合启动服务时预热。
如果再优化的话,可能就是只预热热点数据。这个时候需要找到预热数据。
2.服务运行过程当中,随时预热指定数据
比如,商品库存数据。你上了一个新的商品,然后现在要秒杀。这个时候就适合实现一个操作按钮,手工预热指定数据。
总的来说,不管是什么时间节点,但是必须要在使用之前,就预热数据。而不是等到用的时候,才预热数据。
预热哪些数据?
一般只预热热点数据。因为内存有限。然后,还要淘汰掉最近使用少的数据。
如何找到热点数据?
实现起来比较麻烦。尽量使用简单一点的解决方法。
什么时候更新数据库?
在一段时间之后,秒杀活动结束。卖了多少,就减去多少。也就是说,秒杀活动结束的时候,会更新数据库里的数据。
其他情况也类似,就是肯定是有一个结束的时间节点作为标志,就是这个时间节点之后更新数据库。
参考
zq99299.github.io/note-book/c…
热点数据
为什么要找热点数据?
因为内存不够。如果够,那就放进内存,也就不需要找哪些是热点数据。
分类
1.静态数据
秒杀的商品库存,哪个商品的库存参与秒杀,这个提前确认好的。
2.动态数据
系统运行过程中,动态实时统一热点数据。动态热点数据,实现起来比较麻烦一点。
如何找到热点数据?
实现起来比较麻烦。
如何解决热点数据?
缓存起来。
参考
time.geekbang.org/column/arti…
数据一致性
为什么会出现数据一致性问题?
因为有两个数据源。而且你要保持数据一致。保持不了,就会出现数据一致性的问题。本质是,要保证缓存里的数据和数据库里的数据一致,本质是以数据库数据为准。
什么时候会出现两个数据源的数据不一致的问题?两个并发写操作。只要是两个并发写,就可能会篡改数据,就像多线程里的并发问题一样。
示意图
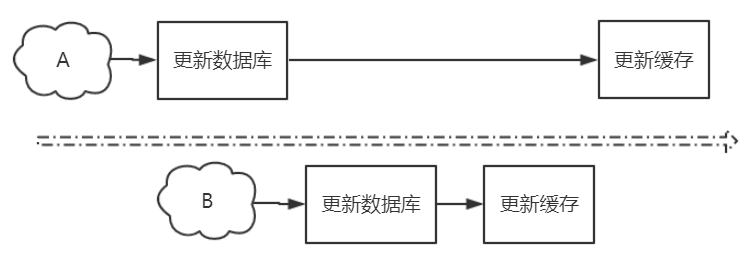
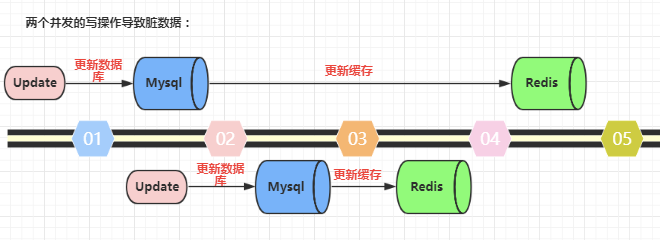
解决方案
步骤
1.更新数据库
2.删除缓存数据,而不是更新缓存数据
示意图
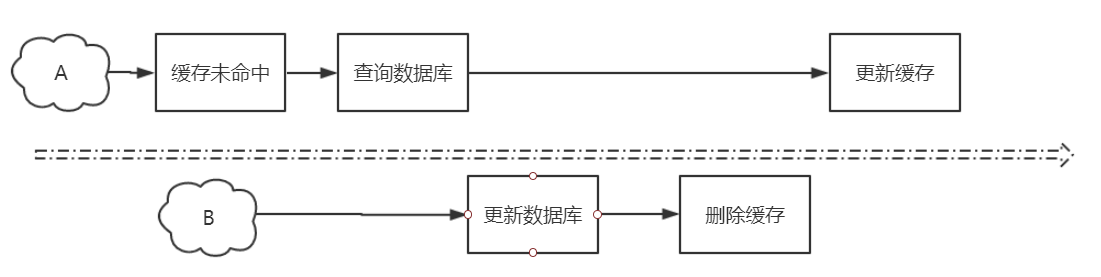
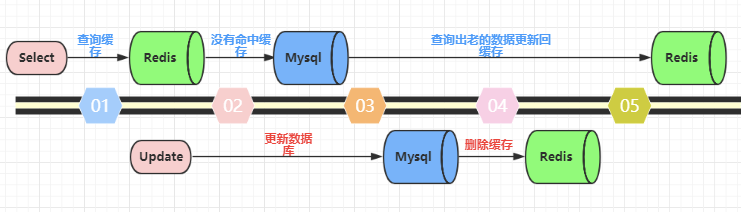
为什么不是更新数据库之后,更新新的数据到缓存,而是删除缓存数据?
因为如果是更新,不是删除。这种情况,出现数据不一致的可能性比较大。所以,本质是为了优化数据一致性。
为什么?因为更新缓存数据之前(这个时候,缓存里的数据是旧数据),可能别的线程修改了数据库(这个时候,数据库里的数据是最新的新数据)。这个是很有可能的。那么这个时候,就会导致数据库和缓存里的数据不一致。
但是,为什么删除缓存数据,就可以优化呢?因为删除缓存数据之前,别的线程修改了数据库并且删除了缓存数据,也没有关系。为什么没有关系?因为缓存里没有数据,所以这个时候根本就不存在数据一致性问题。当然,现在缓存里没有数据,下次查询缓存数据的时候,未命中。
未命中就
1.读数据库
2.更新缓存
