

串(Sequence)
在本章节内容中研究的串是开发中熟悉的字符串,大家都知道,字符串是由若干个字符组成的有限序列。
例如有下图所示的字符串,可以看到该字符串有5个字符组成

其中,字符串thank的前缀(prefix),真前缀(proper prefix),后缀(suffix),真后缀(proper suffix),表示如下

可以看出,前缀与真前缀的区别,后缀与真后缀的区别在于前缀/后缀可以是自己,真前缀/真后缀不可以是自己。
串匹配算法
本章节主要研究串的匹配问题,例如
通过一个模式串(Pattern)在文本串(Text)中的位置,例如下面代码
String text = "Hello world";
String pattern = "or";
text.indexOf(pattern);//7
text.indexOf("other");//-1
通过一个模式串,在文本中查找位置,如果找到,则返回对应的索引,如果找不到,返回-1。通过对串匹配算法的讨论,研究哪一种算法更加高效。
以下为常见的几个经典串匹配算法
- 蛮力(Brute Force)
- KMP
- Boyer-Moore
- Rabin-Karp
- Sunday
由于后面内容会经常使用到Text的长度与Pattern的长度,因此后面将Text长度简写为tlen,将Pattern长度简写为plen。
蛮力(Brute Force)
以字符为单位,从左到右移动模式串,直到匹配成功为止。
例如文本串如下图所示

模式串如下图所示

从左到右进行匹配,如果模式串中的第一个字符匹配成功,这继续往后进行匹配,如果匹配失败,则模式串从文本串的下一个字符进行匹配,一直重复。直到匹配成功或者匹配完所有的文本串为止。
根据这种方式,上面文本串与模式串的匹配流程如下
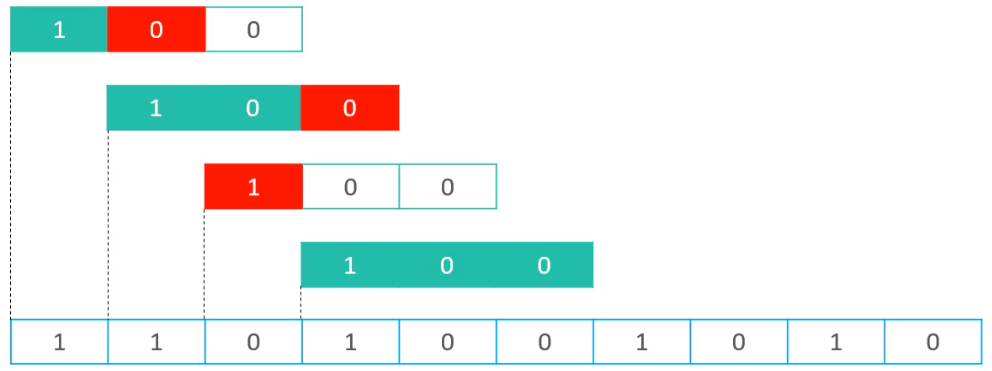
这种匹配算法,常见的实现方式有如下两种
方式一: 执行过程如下
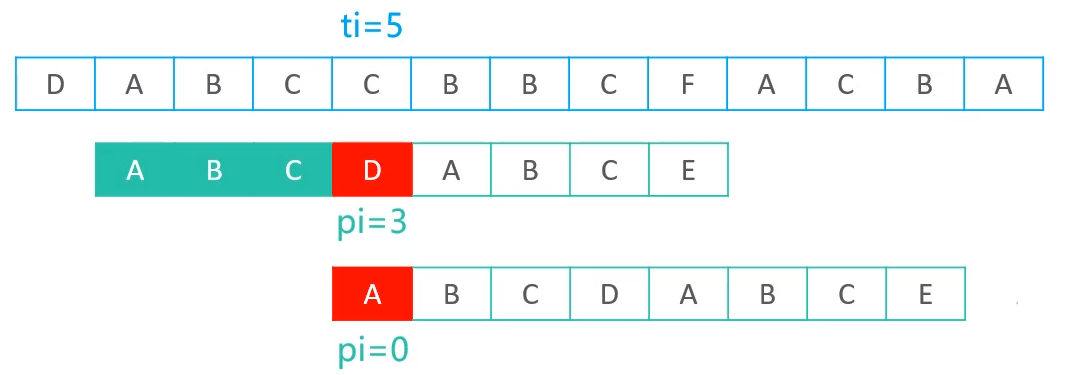
定义两个变量pi,ti,其中pi表示正在参与比较的模式串索引,ti表示正在参与比较的文本串索引,如下图

所以
- pi的取值范围为[0,plen)
- ti的取值范围为[0,tlen)
如果当前索引的文本匹配成功,则将两个索引往后移动1个位置,即
- pi++
- ti++

然后继续比较,发现当前索引的文本依然是成功的,所以会将两个索引往后移动1个位置,结果如下

发现在当前索引时,比较依然是成功的,所以会继续将两个索引往后移动1个位置,现在,将注意力放到pi和ti的下一个索引位置,当pi与ti都变为3时,匹配失败了

当匹配失败时,则将pi置为0,ti置为ti - pi + 1;重置了索引以后的结果如下

现在继续进行匹配,在当前索引时(pi = 0 ,ti = 1)时,就匹配失败了,因此再次重置pi与ti的值。
通过这样一直重复,当pi等于plen时,则说明最终匹配到了所有的文本
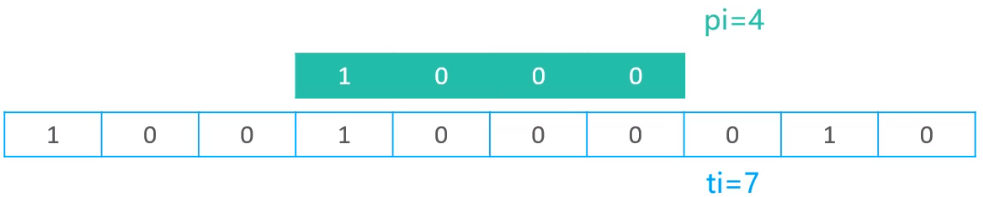
最终的返回的索引值为ti - pi
所以,根据上面的分析步骤,转换为代码的结果如下
public static int indexOf(String text, String pattern) {
if (text == null || pattern == null) return -1;
char[] textChars = text.toCharArray();
int tlen = textChars.length;
if (tlen == 0) return -1;
char[] patternChars = pattern.toCharArray();
int plen = patternChars.length;
if (plen == 0) return -1;
if (tlen < plen) return -1;
int pi = 0, ti = 0;
while (pi < plen && ti < tlen) {
if (textChars[ti] == patternChars[pi]) {
ti++;
pi++;
} else {
ti -= pi - 1;
pi = 0;
}
}
if (pi == plen) {
//说明找到了
return ti - pi;
}
return -1;
}
优化
前面这种实现方法,其实可以在恰当的时候提前退出,这样可以减少比较次数
例如在如下图所示的情况下

此时比较失败,所以pi和ti的值都会重置,终止后进行比较,最终的结果如下

在这种情况下, 模式串匹配的字符已经超过了文本串的索引,最终的结果一定是失败,所以在这种情况下,前面的3次比较结果都是无效的
所以,在这种情况下,可以将退出条件从ti < tlen修改为 ti - pi <= tlen - plen.其中ti - pi表示为每一轮比较中Text首个比较字符的位置,所以可以将while循环条件进行优化
了解了蛮力算法的第一种实现以后,继续研究这种算法的另外一种实现。
方式二:
首先,与前面的实现一样,定义两个变量pi与ti,分别记录当前正在比较的索引

当比较成功时,前面是pi与ti都进行+1操作,现在不使用这种方式,现在的做法是pi进行+1,文本串中进行比较的索引,利用pi + ti来进行表示;如下图所示

pi = 1时比较又是成功的,所以继续往后比较,结果如下

继续进行比较,结果如下

到这一步pi =3时,发现匹配失败,所以,则只需要将pi重置为0,ti执行+1操作即可,继续进行比较,结果如下

又比较失败,继续执行pi重置为0,ti +1的操作,一直重复上面的步骤,知道pi == plen时,最终匹配成功,结果如下
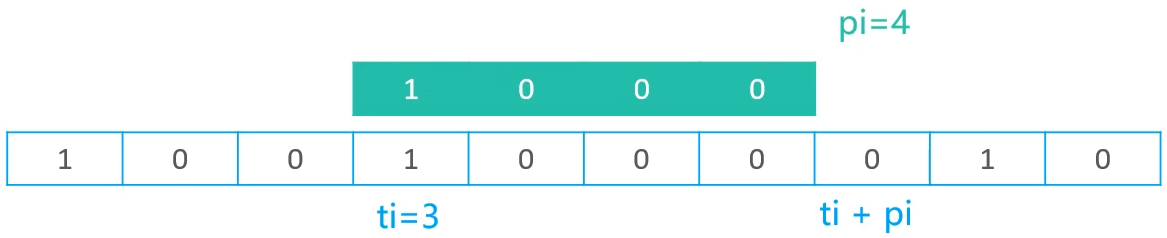
最终,如果采用这种做法来实现,pi与ti的取值范围分别如下
- pi 的取值范围为[0,plen)
- ti 的取值范围为[0,tlen - plen)
根据这种思路,实现的代码如下
public static int indexOf(String text, String pattern) {
if (text == null || pattern == null) return -1;
char[] textChars = text.toCharArray();
int tlen = textChars.length;
if (tlen == 0) return -1;
char[] patternChars = pattern.toCharArray();
int plen = patternChars.length;
if (plen == 0) return -1;
if (tlen < plen) return -1;
int tiMax = tlen - plen;
for (int ti = 0; ti <= tiMax ; ti++) {
int pi = 0;
for (; pi < plen; pi++) {
if (textChars[ti + pi] != patternChars[pi]) break;
}
if (pi == plen) return ti;
}
return -1;
}
蛮力算法-性能分析
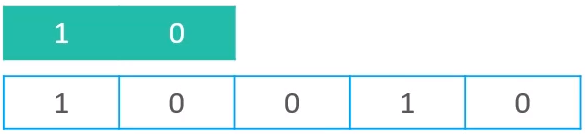
下图中长的部分表示文本串,短的部分表示模式串,模式串中,绿色表示匹配成功,红色表示匹配失败,空格表示还未匹配。一旦匹配失败,模式串会向右移动一个单位,所以在匹配的过程中,可能出现的情况如下
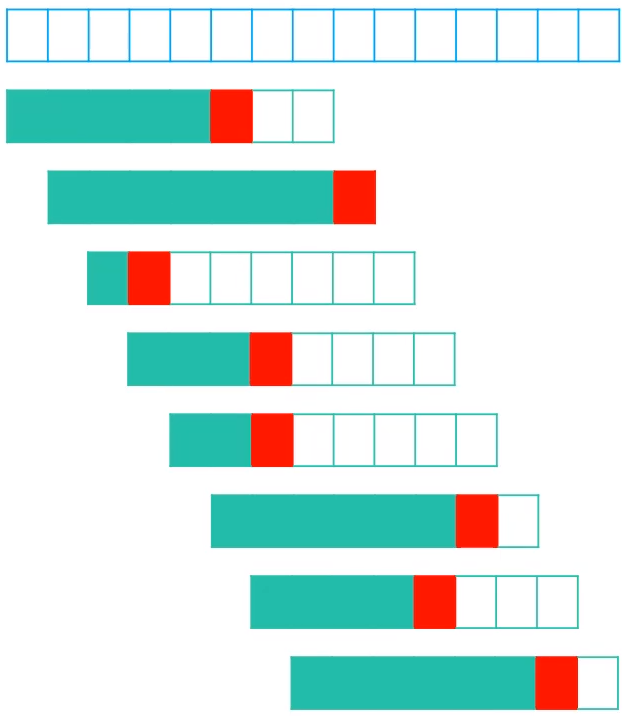
现假设n为文本串的长度,m为模式串的长度,所以
-
最坏的情况下,会比较n - m +1轮
-
最好的情况为只需要比较一轮就成功,在这种情况下,需要比较m次(m为模式串的长度),所以此时的时间复杂度为O(m)
-
最坏情况为执行了n - m + 1轮比较(n为文本串的长度),并且每一轮都要比较到模式串的末字符后,才失败(每一轮m - 1次成功,1次失败)

在这种情况下,时间复杂度为O(m*(n - m +1)),由于一般情况下m远小于n,所以时间复杂度为O(nm)
KMP
前面,通过蛮力算法,可以成功的获取到模式串是否在文本串中的正确结果,其时间复杂度为O(nm),通过蛮力算法,可以很清晰,简单的理解算法的整个执行过程。研究完蛮力算法以后,现在继续研究一个性能更优的模式匹配算法,KMP.
KMP 是Knuth-Morris-Pratt的简称(取名自3为发明人的名字),与1977年发布

蛮力 vs KMP
- 蛮力算法:是经过一系列比对以后,如果在某位置发现,比对失败,模式串则会从0开始,文本串从下一个位置开始,再次从头开始比较,一直重复,直到匹配成功或者全部匹配完。
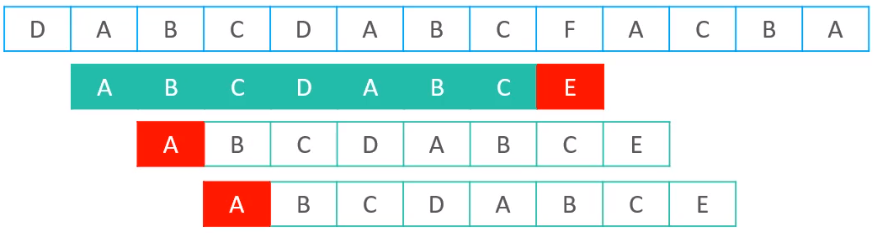
- KMP算法:KMP算法,在经过一系列比对以后,付过发现某个位置比对失败,会直接从文本串的开始位置,直接挪动到某一个位置,然后继续开始比较。
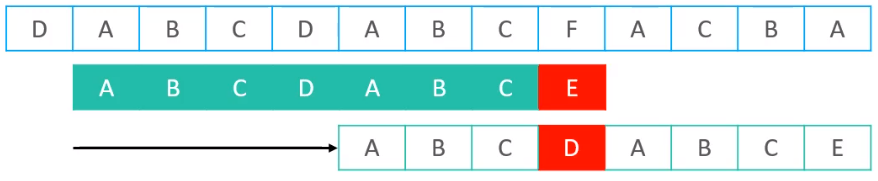
对比蛮力算法,可以发现KMP算法非常的聪明,蛮力算法匹配失败,一次只会挪动一个位置,但是KMP算法则会一次挪动多个位置,KMP算法可以非常聪明的知道,哪些位置是没有必要比较的,所以,在KMP看来,蛮力算法的中间三次比较是没有必要的。
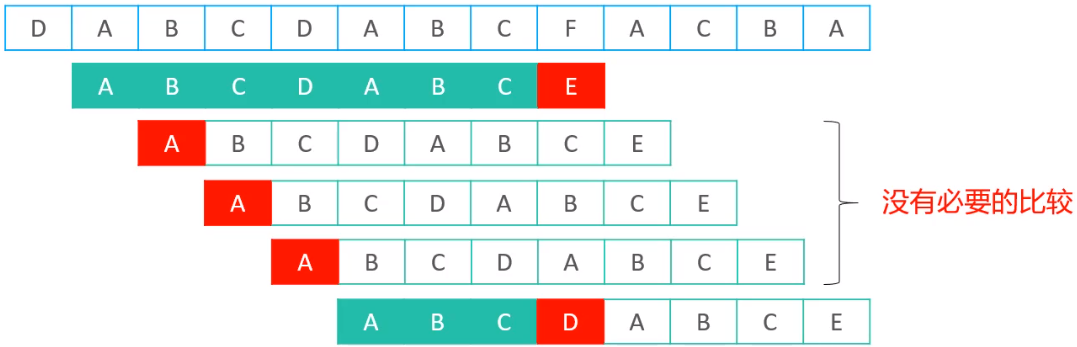
其实,KMP算法对比蛮力算法,其精妙之处在于:充分利用了此前比较过的内容,可以很聪明的跳过一些不必要的比较位置。
KMP中next表的使用
KMP会预先根据模式串的内容生成一张next表(一般是个数组);例如下图是模式串ABCDABCE的next表
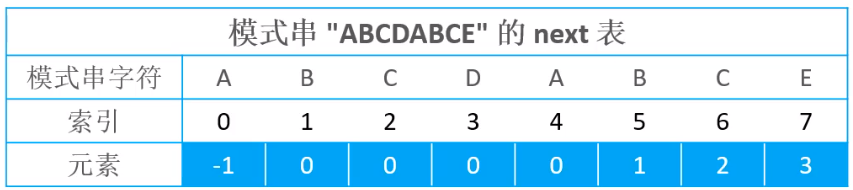
假设现在有下图所示的模式串与文本串,其中文本串已经比较到了ti = 8的位置,模式串比较到了pi = 7 的位置,现在比较失败了
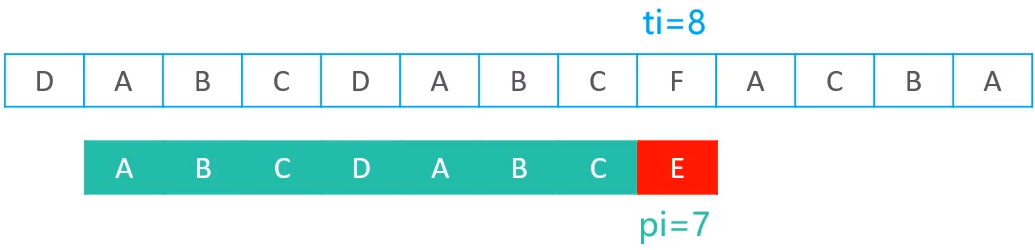
当比较失败以后,就会到next表中进行查询,根据pi失配的位置7,到next表中进行查询,得到的元素为3,所以现在就会利用现在pi的索引,去next表中取出对应的值,然后再赋值到pi,即pi = next[7],所以赋值以后,pi的值变为了3
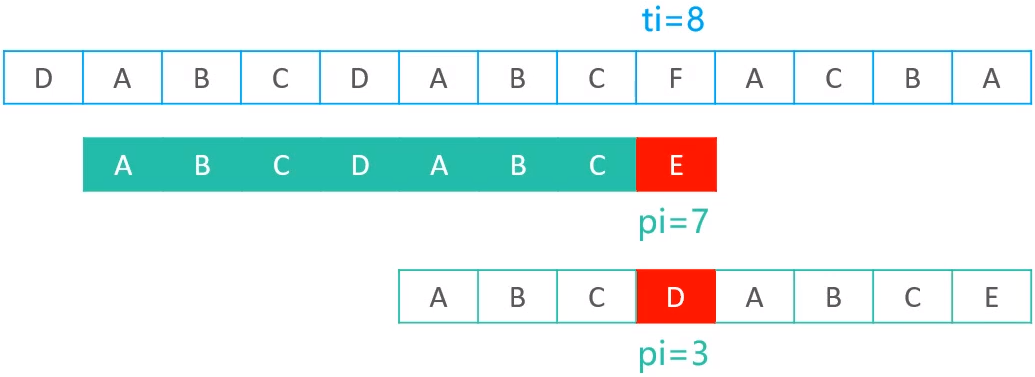
总结:一旦发现pi位置失配,就会将next[pi]中的值赋值给pi,所以赋值完成后,就将pi = 3位置的元素与ti = 8位置的元素记性比较,模式串就会瞬间往右移动一定的位置
向右移动的距离 = pi - next[pi]
为了加深KMP算法对next表的使用原理,结合前面的next表,再利用实例来进行理解
下图中在pi = 3,ti = 5 的位置失配了
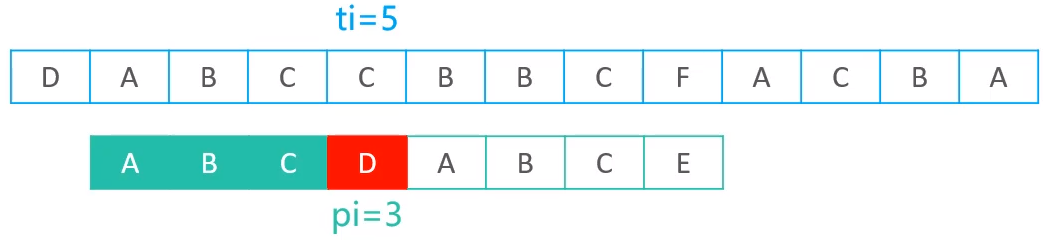
步骤如下:
- 向next表中查表,next[pi] ,即可以得到next[3]的值
- 查表后,得到next[3]的值为0,所以就会将pi的值更新为0
- 利用pi == 0的位置与现在的ti进行比较
KMP的核心原理
下图为两个不同的串,其中Text为文本串,Pattern为模式串
- A,B是个子串(两个子串相等)
- c,d,e是单个字符

现在两个串在进行比较,当Text中比较到字符d时,Pattern比较到字符e时,比较失败了。按照KMP算法的原理,可以让模式串快速的向右移动一段距离,所以当上面的文本串d与模式串e比较失败以后,就会向右移动一段距离,最终移动后的结果如下
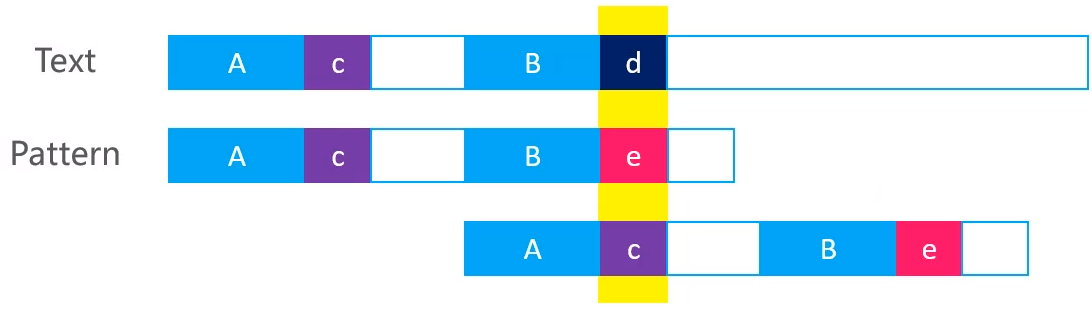
将模式串移动以后,就可以直接将模式串中的字符c与与文本串中的字符d进行比较,这样就直接跳过了前面的字符,而且由于子串A和子串B是相等的,所以A,B两个子串在移动后也不会再进行比较
所以,根据KMP算法的原理,当上图的d,e失配是,就会让模式串向右移动一段距离,最后直接从字符d,c进行比较
如果想实现这样的效果,需要具备的条件为:子串A与子串B相等
并且,如果要得知向右移动的距离,KMP就必须在失配字符e左边的子串中找出符合条件的A,B 其中,向右移动的距离为:e左边子串的长度 - A的长度,也等价于:e的索引 - c的索引 结合KMP的设想,也可以得到移动有c的索引;c的索引 == next[e的索引],所以,向右移动的距离 == e的索引 - next[e的索引]
所以,如果在pi位置失配的话,向右移动的距离即为pi - next[pi],并且如果next[pi]得到的值越小,向右移动的距离就会越大 其中next[pi]得到的值是pi左边子串的真前缀/真后缀的最大公共子串长度
真前缀/真后缀的最大公共子串
下图表示了不同模式串的真前缀/真后缀,及最大公共子串的长度
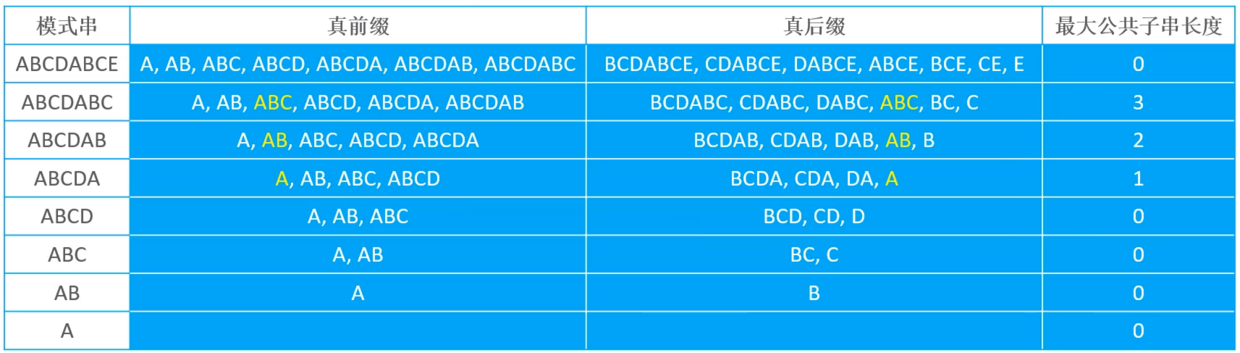
即找出模式串中的所有真前缀与真后缀,然后从真前缀/真后缀中找出最大公共子串的长度,然后就可以得到模式串中所有子串的最大公共子串长度,所以如果模式串为ABCDABCE的话,得到的最大公共子串长度结果如下

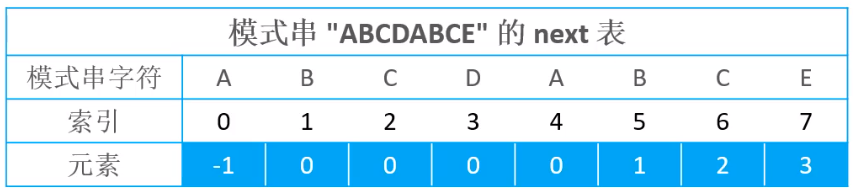
得到next表
得到最大公共子长度表以后,可以利用该表,得到next表
将最大公共子串长度的值,都向右移动1位,首位置位-1,就可以得到next表,所以利用上面的最大公子串长度表,就可以如下的next表
KMP主算法的实现
KMP主算法的实现,其实是基于前面蛮力算法的基础上,进行改进实现的
结合前面的思路,可以知道,只需要在失配时,将pi重新赋值即可。
但是需要考虑一个问题,就是在pi为0的时候就失配的情况,这种情况的话,只需要将ti进行++操作即可,但是由于在next表中,将next表的首元素值设置为-1,所以需要在首元素失配时,ti++后,又继续从pi为0的位置,继续进行比较,所以当pi == -1时,需要将pi进行++操作,巧妙的为下一次pi匹配做准备
最终,主算法的实现如下
public static int indexOf(String text, String pattern) {
if (text == null || pattern == null) return -1;
char[] textChars = text.toCharArray();
int tlen = textChars.length;
if (tlen == 0) return -1;
char[] patternChars = pattern.toCharArray();
int plen = patternChars.length;
if (plen == 0) return -1;
if (tlen < plen) return -1;
//定义一个next表
int[] next = next(pattern);
int pi = 0, ti = 0, lenDelta = tlen - plen;
while (pi < plen && ti - pi <= lenDelta) {
//pi小于0,说明是0号位置失配,如果进入if判断的话,就会执行++操作,巧妙的将-1变为了0
if (pi < 0 || textChars[ti] == patternChars[pi]) {
ti++;
pi++;
} else {
pi = next[pi];
}
}
if (pi == plen) {
//说明找到了
return ti - pi;
}
return -1;
}
KMP算法中,为什么选择的是最大公共子串长度
现在假设文本串是AAAAABCDEF,模式串为AAAAB,如果现在在模式串B位置产生失配的话,则需要看失配前的串中,真前缀真后缀的公共子串长度,所以在模式串B位置失配的话,真前缀分别有,A,AA,AAA,AAAA,所以这些真前缀也有自己的真前缀真后缀,所以这些真前缀作为模式串匹配时的真前缀真后缀如下

最终,在失配时,公共子串长度选择的是3,为什么选择的是3,而不是1呢?请继续看下面的解释
现有如下图所示的文本串和模式串在进行匹配
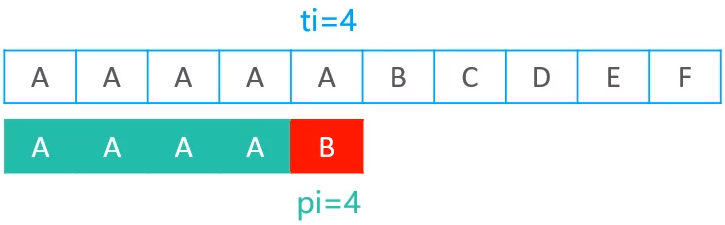
可以发现,当ti为4,pi为4时失配了,现在需要利用pi = 4这个值,到next表中进行查值,最终查到的是3,所以模式串最终会往右移动 4 - 3 = 1个位置,移动后的结果如下
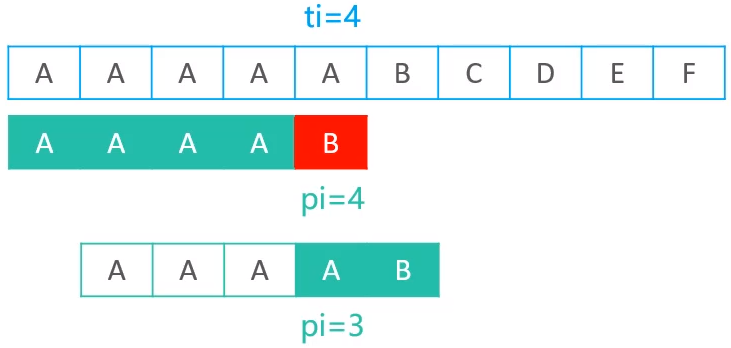
但是前面的表中可以看到,模式串为AAAA时,公共子串长度有3个,分别为1,2,3,假如现在将1赋值给pi的话,得到的结果如下
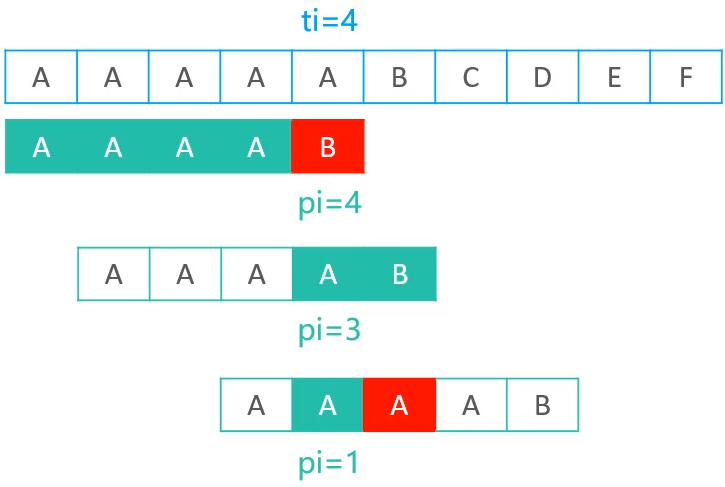
现在pi的值为1,就是将pi为1位置的值与现在ti为4位置的值进行比较,可以发现pi值越小,前面跳过的索引就会比较大,最终可能会导致再跳过的过程中,错过可能匹配的情况,因此有以下结论
- 公共子串长度越小,向右移动的距离会越大,越不安全
- 公共子串长度越大,向右移动的距离会越小,越安全
next表的构造思路
假设现在模式串的表示如下

绿色位置的字符,索引为n,黄色位置的字符,索引为i
再假设两个红色方框中的元素相等

这样就会得到 next[i] == n,即当i位置的字符失配时,i位置前面所有字符的最大公共子串的值,又因为两个红框中的值是相等的,所以最大公共子串的长度即为n,所以就有next[i] == n
现有如下假设情况
-
如果模式串的i位置与n位置是相等的,即Pattern[i] == Pattern[n]
- 那么nex[i + 1] == n+ 1(因为i + 1位置前面字符串的最大公共子串长度变为了n + 1)
-
如果模式串的i位置与n位置不相等,即Pattern[i] != Pattern[n] 找到前缀A中的下一位k为字符

-
如果现在模式串i位与k位是相等的,即Pattern[i] == Pattern[k]
-
那么说明下图红框中的部分子串是相等的

-
-
如果现在模式串i为与k为是不相等的,即即Pattern[i] != Pattern[k]
- 那么现在就要继续在模式串k位置前面的子串中,继续查找子串中真前缀真后缀的最大公共子串,然后将步骤2的n作为k的值,继续进行判断,重复执行即可。
-
结合构建思路,得到next表的实现如下
private static int[] next(String pattern) {
char[] chars = pattern.toCharArray();
int[] next = new int[chars.length];
next[0] = -1;
int i = 0;
int n = -1;
int iMax = chars.length - 1;
while (i < iMax) {//i < iMax 是因为后面会做++操作,操作完成后,就变为了i <= iMax
if (n < 0 || pattern.charAt(i) == pattern.charAt(n)) {
next[++i] = ++n;
} else {
//失配
n = next[n];
}
}
return next;
}
next表的不足之处
假设现在有文本串AAABAAAAB与模式串AAAAB
如果按照前面next表的实现进行计算你的话,生成的next表如下所示
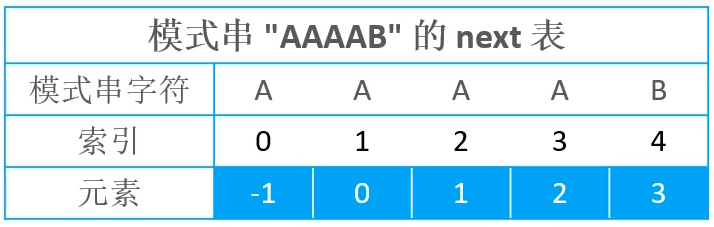
存在的问题在于,第一次出现失配以后,后面相同字符依然会进行重复判断
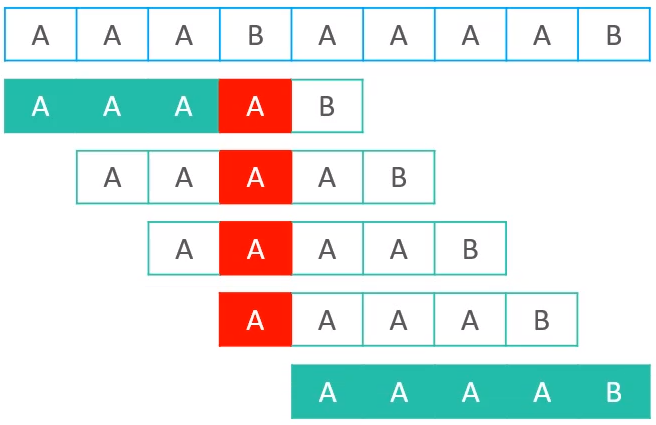
所以,可以知道,其实当第一次出现失配情况以后,后面所有有的A与B进行比较时,都会出现失配的情况,所以,中间的几次比较,其实是多余的
所以,如果出现这种情况的话,KMP会显得比较笨拙
next表的优化思路
现通过下图表示模式串文本串

并且现在已知next[i] == n,next[n] == k
如果现在文本串中的d位置与模式串i位置失配的话,结合下图比较
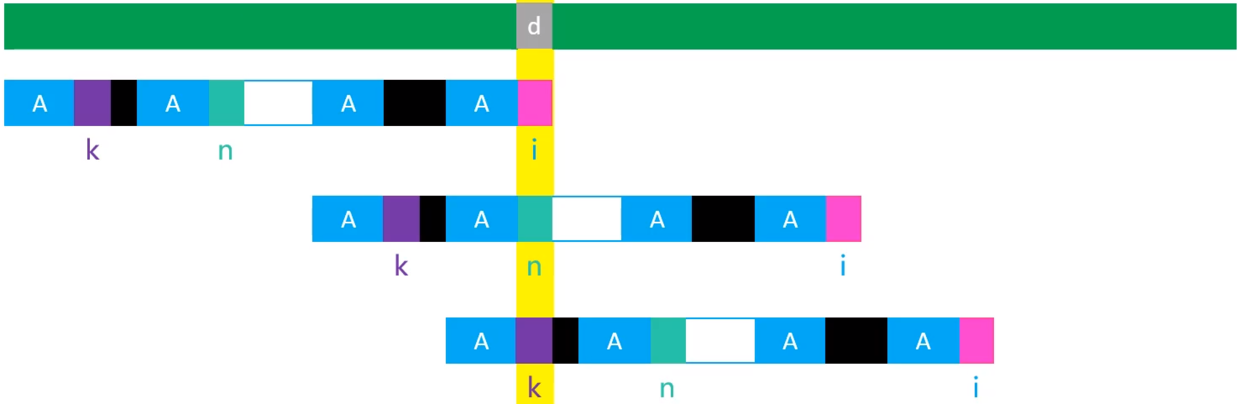
有以下的比较情况
- 如果Pattern[i] != d,就让模式串滑动到next[i](也就是n)位置与d进行比较
- 如果Pattern[n] != d,就让模式串滑动到next[n](也就是k)位置与d进行比较
- 如果Pattern[i] == Pattern[n],那么当i位置失配时,模式串最终必然会滑动到k位置与d 进行比较
- 在这种情况下,让next[i]直接存储next[i](也就是k)即可
通过分析,优化后的代码如下
private static int[] next(String pattern) {
char[] chars = pattern.toCharArray();
int[] next = new int[chars.length];
next[0] = -1;
int i = 0;
int n = -1;
int iMax = chars.length - 1;
while (i < iMax) {//i < iMax 是因为后面会做++操作,操作完成后,就变为了i <= iMax
if (n < 0 || pattern.charAt(i) == pattern.charAt(n)) {
++i;
++n;
if (pattern.charAt(i) == pattern.charAt(n)) {
next[i] = next[n];
} else {
next[i] = n;
}
} else {
//失配
n = next[n];
}
}
return next;
}
通过优化后,模式串AAAAB生成的next表如下
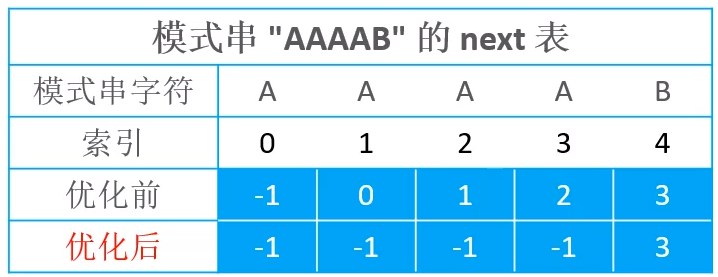
next值发生变化以后,发生了如下的效果
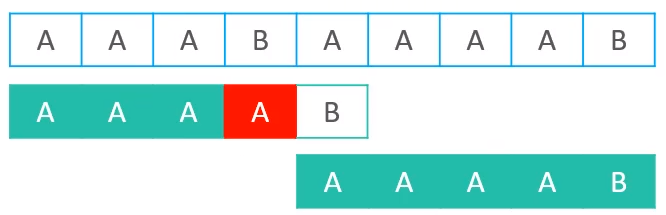
因为首先在3号位置失配,所以优化后找到的索引为-1,所以会直接向右移动4个位置
KMP性能分析
利用KMP算法进行串匹配时,可能出现的情况如下,其中绿色表示匹配成功,红色表示失配,白色表示没有匹配
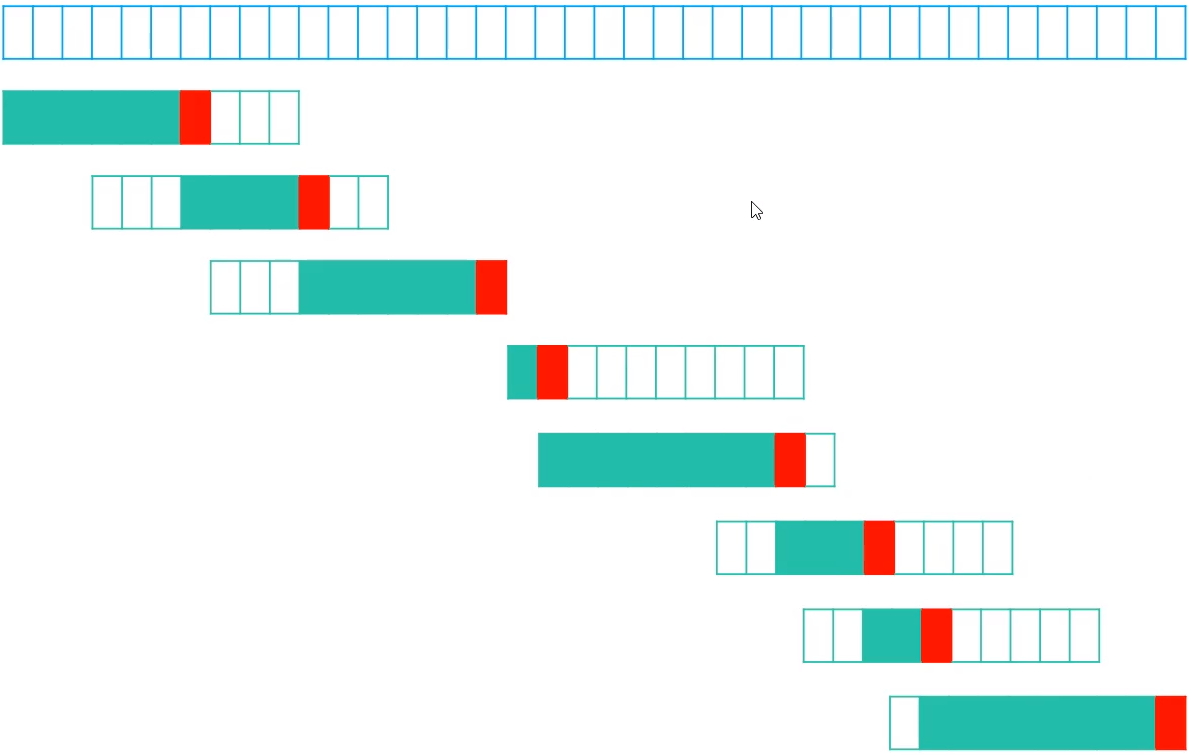
通过上图这种一般情况的分析,可以看出,KMP算法一共比较的次数大约为n(n为文本串长度)次
所以KMP算法主逻辑中
- 最好时间复杂度为:O(m),m为模式串的长度
- 最坏时间复杂度为:O(n),最多不超过O(2n)(因为有些地方可能会重叠)
其中next表的构造过程,与KMP主逻辑很类似,所以
- next表构建的时间复杂度为:O(n)
整体来讲,KMP刷反的复杂度为:
- 最好时间复杂度为:O(m)
- 最坏时间复杂度为:O(n+m)
- 空间复杂度为:O(m)
完!
