

本文经授权摘自杜军大佬的新书《Kubernetes 网络权威指南》,详情请看微信公众号。
当检查你的 Kubernetes 集群的节点时,在节点上执行 docker ps 命令,你可能会注意到一些被称为“暂停”(pause)的容器,例如:
🐳 → docker ps
CONTAINER ID IMAGE COMMAND ...
3b45e983c859 gcr.io/google_containers/pause-amd64:3.1 “/pause”
dbfc35b00062 gcr.io/google_containers/pause-amd64:3.1 “/pause”
c4e998ec4d5d gcr.io/google_containers/pause-amd64:3.1 “/pause”
508102acf1e7 gcr.io/google_containers/pause-amd64:3.1 “/pause”
你会疑惑这些容器并不是你创建的。是的,这些容器是 Kubernetes”免费赠送“的。
Kubernetes 中所谓的 pause 容器有时候也称为 infra 容器,它与用户容器”捆绑“运行在同一个 Pod 中,最大的作用是维护 Pod 网络协议栈(当然,也包括其他工作,下文会介绍)。
都说 Pod 是 Kubernetes 设计的精髓,而 pause 容器则是 Pod 网络模型的精髓,理解 pause 容器能够更好地帮助我们理解 Kubernetes Pod 的设计初衷。为什么这么说呢?还得从 Pod 沙箱(Pod Sandbox)说起。
Pod Sandbox 与 pause 容器
熟悉 Pod 生命周期的同学应该知道,创建 Pod 时 Kubelet 先调用 CRI 接口 RuntimeService.RunPodSandbox 来创建一个沙箱环境,为 Pod 设置网络(例如:分配 IP)等基础运行环境。当 Pod 沙箱(Pod Sandbox)建立起来后,Kubelet 就可以在里面创建用户容器。当到删除 Pod 时,Kubelet 会先移除 Pod Sandbox 然后再停止里面的所有容器。
可能有读者会疑惑,Pod Sandbox 是啥玩意儿啊?其实,这只是同一个事物通过不同角度看得到的不同称谓。从 Kubernetes 的底层容器运行时 CRI 看,Pod 这种在统一隔离环境里资源受限的一组容器,就叫 Sandbox。
Tips:一个隔离的应用运行时环境叫容器,一组共同被 Pod 约束的容器就叫 Pod Sandbox。她们同生共死,共享底层资源。
了解 KVM 底层的读者应该知道,虚拟机与容器一样底层都使用 cgroups 做资源配额,而且概念上都抽离出一个隔离的运行时环境,只是区别在于资源隔离的实现。因此,从字面是上看,虚拟机和容器还是有机会都用沙箱这个概念来“套“的。事实上,提出 Pod 沙箱概念就是为 Kubernetes 兼容不同运行时环境(甚至包括虚拟机!)预留空间,让运行时根据各自的实现来创建不同的 Pod Sandbox。对于基于 hypervisor 的运行时(KVM,kata 等),Pod Sandbox 就是虚拟机。对于 Linux 容器,Pod Sandbox 就是 Linux Namespace(Network Namespace 等)。
Pod Sandbox 与我们今天要聊的“主角”pause 容器有着千丝万缕的联系。在 Linux CRI 体系里,Pod Sandbox 其实就是 pause 容器。Kubelet 代码引用的 defaultSandboxImage 其实就是官方提供的 gcr.io/google_containers/pause-amd64 镜像。
我们知道 Kubernetes 的 Pod 抽象基于 Linux 的 namespace 和 cgroups,为一组容器共同提供了隔离的运行环境。从网络的角度看,同一个 Pod 中的不同容器犹如在运行在同一个专有主机上,可以通过 localhost 进行通信。
原则上,任何人都可以配置 Docker 来控制容器组之间的共享级别——你只需创建一个父容器,并创建与父容器共享资源的新容器,然后管理这些容器的生命周期。在 Kubernetes 中,pause 容器被当作 Pod 中所有容器的“父容器”并为每个业务容器提供以下功能:
- 在 Pod 中它作为共享 Linux Namespace(Network、UTS 等)的基础;
- 启用 PID Namespace 共享,它为每个 Pod 提供 1 号进程,并收集 Pod 内的僵尸进程。
pause 容器源码
Kubernetes 的 pause 容器没有复杂的逻辑,里面运行着一个非常简单的进程,它不执行任何功能,基本上是永远“睡觉”的,源代码在 kubernetes 项目的 build/pause/ 目录中。因为它比较简单,在这里便写下完整的源代码,如下所示:
#include <signal.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#define STRINGIFY(x) #x
#define VERSION_STRING(x) STRINGIFY(x)
#ifndef VERSION
#define VERSION HEAD
#endif
static void sigdown(int signo) {
psignal(signo, "Shutting down, got signal");
exit(0);
}
static void sigreap(int signo) {
while (waitpid(-1, NULL, WNOHANG) > 0)
;
}
int main(int argc, char **argv) {
int i;
for (i = 1; i < argc; ++i) {
if (!strcasecmp(argv[i], "-v")) {
printf("pause.c %s\n", VERSION_STRING(VERSION));
return 0;
}
}
if (getpid() != 1)
/* Not an error because pause sees use outside of infra containers. */
fprintf(stderr, "Warning: pause should be the first process\n");
if (sigaction(SIGINT, &(struct sigaction){.sa_handler = sigdown}, NULL) < 0)
return 1;
if (sigaction(SIGTERM, &(struct sigaction){.sa_handler = sigdown}, NULL) < 0)
return 2;
if (sigaction(SIGCHLD, &(struct sigaction){.sa_handler = sigreap,
.sa_flags = SA_NOCLDSTOP},
NULL) < 0)
return 3;
for (;;)
pause();
fprintf(stderr, "Error: infinite loop terminated\n");
return 42;
}
如上所示,这个“暂停”容器运行一个非常简单的进程,它不执行任何功能,一启动就永远把自己阻塞住了(见 pause() 系统调用)。正如你看到的,它当然不会只知道睡觉。它执行另一个重要的功能——即它扮演 PID 1 的角色,并在子进程成为孤儿进程的时候通过调用 wait() 收割这些僵尸子进程。这样我们就不用担心我们的 Pod 的 PID namespace 里会堆满僵尸进程了。这也是为什么 Kubernetes 不随便找个容器(例如:Nginx)作为父容器,然后让用户容器加入的原因了。
从 namespace 看 pause 容器
我们在第 1 章介绍过,在 Linux 系统中运行新进程时,该进程从父进程继承了其 namespace。在 namespace 中运行进程的方法是通过取消与父进程的共享 namespace,从而创建一个新的 namespace。以下是使用 unshare 工具在新的 PID、UTS、IPC 和 mount namespace 中运行 shell 的示例。
🐳 → unshare --pid --uts --ipc --mount -f chroot rootfs /bin/sh
一旦进程运行,你可以将其他进程添加到该进程的 namespace 中以形成一个 Pod,Pod 中的容器在其中共享 namespace。读者可以使用第 1 章提到的 setns 系统调用将新进程添加到现有命名空间,Docker 也提供命令行功能让你自动完成此过程。下面让我们来看一下如何使用 pause 容器和共享 namespace 从头开始创建 Pod。
首先,我们使用 Docker 启动 pause 容器,以便我们可以将其他容器添加到 Pod 中,如下所示:
🐳 → docker run -d --name pause gcr.io/google_containers/pause-amd64:3.0
然后,我们在 Pod 中运行其他容器,分别是 Nginx 代理和 ghost 博客应用。
Nginx 代理的后端配置成 http://127.0.0.1:2368,也就是 ghost 进程监听的地址,如下所示:
# cat <<EOF >> nginx.conf
> error_log stderr;
> events { worker_connections 1024; }
> http {
> access_log /dev/stdout combined;
> server {
> listen 80 default_server;
> server_name example.com www.example.com;
> location / {
> proxy_pass http://127.0.0.1:2368;
> }
> }
> }
> EOF
# docker run -d --name nginx -v `pwd`/nginx.conf:/etc/nginx/nginx.conf -p 8080:80 --net=container:pause --ipc=container:pause --pid=container:pause nginx
作为应用服务器的 ghost 博客应用程序创建另一个容器,如下所示:
🐳 → docker run -d --name ghost --net = container:pause --ipc = container:pause --pid = container:pause ghost
在我们这个例子中,我们将 pause 容器指定为我们要加入其 namespace 的容器。如果访问http://localhost:8080/ ,那么应该能够看到 ghost 通过 Nginx 代理运行,因为 pause、nginx 和 ghost 容器之间共享 Network namespace,如下图所示。
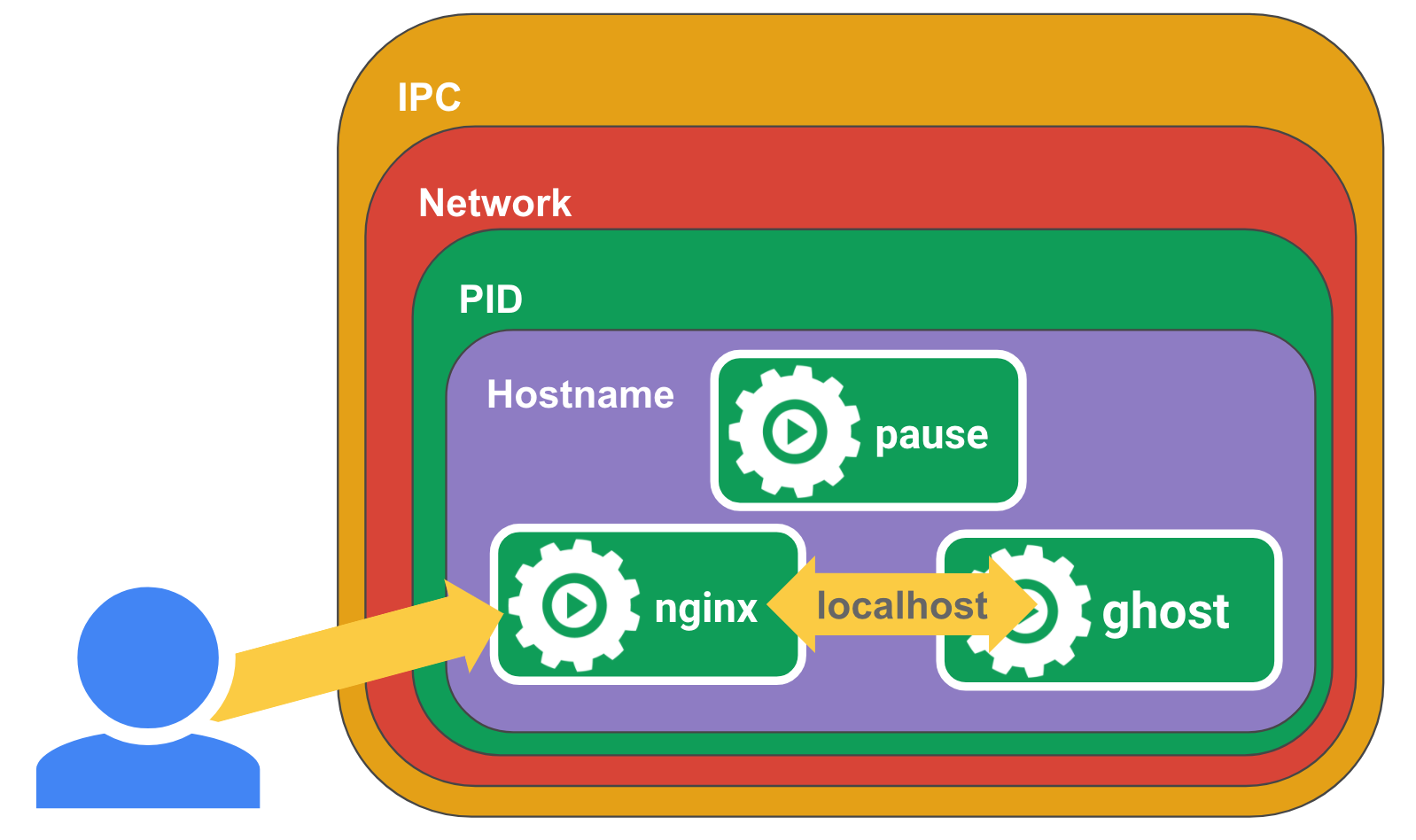
通过 Pod,Kubernetes 为你屏蔽了以上所有复杂度。
从 PID 看 pause 容器
在 UNIX 系统中,PID 为 1 的进程是 init 进程,即所有进程的父进程。init 进程比较特殊,它维护一张进程表并且不断地检查其他进程的状态。init 进程的其中一个作用是当某个子进程由于父进程的错误退出而变成了“孤儿进程”,便会被 init 进程收养并在该进程退出时回收资源。
进程可以使用 fork 和 exec 这两个系统调用启动其他进程。当启动了其他进程后,新进程的父进程就是调用 fork 系统调用的进程。fork 用于启动正在运行的进程的另一个副本,而 exec 则用于启动不同的进程。每个进程在操作系统进程表中都有一个条目。这将记录有关进程的状态和退出代码。当子进程运行完成后,它的进程表条目仍然将保留直到父进程使用 wait 系统调用获得其退出代码后才会清理进程条目。这被称为“收割”僵尸进程,并且僵尸进程无法通过 kill 命令来清除。
僵尸进程是已停止运行但进程表条目仍然存在的进程,因为父进程尚未通过 wait 系统调用进行检索。从技术层面来说,终止的每个进程都算是一个僵尸进程,尽管只是在很短的时间内发生的。当用户程序写得不好并且简单地省略 wait 系统调用,或者当父进程在子进程之前异常退出并且新的父进程没有调用 wait 去检索子进程时,会出现较长时间的僵尸进程。系统中存在过多僵尸进程将占用大量操作系统进程表资源。
当进程的父进程在子进程完成前退出时,OS 将子进程分配给 init 进程。init 进程“收养”子进程并成为其父进程。这意味着当子进程此时退出时,新的父进程(init 进程)必须调用 wait 获取其退出代码,否则其进程表项将一直保留,并且它也将成为一个僵尸进程。同时,init 进程必须拥有“信号屏蔽”功能,不能处理某个信号逻辑,从而防止 init 进程被误杀。所以不是随随便便一个进程都能当 init 进程的。
容器使用 PID namespace 对 pid 进行隔离,因此每个容器中均可以有独立的 init 进程。当在主机上发送 SIGKILL 或者 SIGSTOP(也就是 docker kill 或者 docker stop)强制终止容器的运行时,其实就是在终止容器内的 init 进程。一旦 init 进程被销毁,同一 PID namespace 下的进程也随之被销毁。
在容器中,必须要有一个进程充当每个 PID namespace 的 init 进程,使用 Docker 的话,ENTRYPOINT 进程是 init 进程。如果多个容器之间共享 PID namespace,那么拥有 PID namespace 的那个进程须承担 init 进程的角色,其他容器则作为 init 进程的子进程添加到 PID namespace 中。
为了给读者一个直观的印象,下面给出一个例子来说明用户容器和 pause 容器的 PID 关系。
先启动一个 pause 容器:
🐳 → docker run -idt --name pause gcr.io/google_containers/pause-amd64:3.0
7f6e459df5644a1db4bc9ad2206a0f99e40312de1892695f8a09d52faa9c1073
再运行一个 busybox 容器,加入 pause 容器的 namespace(network,PID,IPC)中:
🐳 → docker run -idt --name busybox --net=container:pause --pid=container:pause --ipc=container:pause busybox
ad3029c55476e431101473a34a71516949d1b7de3afe3d505b51d10c436b4b0f
上述这种加入 pause 容器的方式也是 Kubernetes 启动 Pod 的原理。
接下来,让我们进入 busybox 容器查看里面的进程,发现里面 PID=1 的进程是/pause:
🐳 → docker exec -it ad3029c55476 /bin/sh
/ # ps aux
PID USER TIME COMMAND
1 root 0:00 /pause
5 root 0:00 sh
9 root 0:00 /bin/sh
13 root 0:00 ps aux
我们完全可以在父容器中运行 Nginx,并将 ghost 添加到 Nginx 容器的 PID 命名空间。
🐳 → docker run -d --name nginx -v `pwd`/nginx.conf:/etc/nginx/nginx.conf -p 8080:80 nginx
🐳 → docker run -d --name ghost --net=container:nginx --ipc=container:nginx --pid=container:nginx ghost
在这种情况下,Nginx 将承担 PID 1 的作用,并将 ghost 添加为 Nginx 的子进程。虽然这样貌似不错,但从技术上看,Nginx 现在需要负责 ghost 进程的所有子进程。例如,如果 ghost 在其子进程完成之前异常退出了,那么这些子进程将被 Nginx 收养。但是,Nginx 并不是设计用来作为一个 init 进程运行并收割僵尸进程的。这意味着将会有很多这种僵尸进程,并且这种情况将持续整个容器的生命周期。
最后总结一句,Pod 的 init 进程,pause 容器舍他其谁?
Kubernetes 的 PID namespace 共享/隔离
关于共享/隔离 Pod 内容器的 PID namespace,就是一个见仁见智的问题了,支持共享的人觉得方便了进程间通信,例如可以在容器中给另外一个容器内的进程发送信号量,而且还不用担心僵尸进程回收问题。
在 Kubernetes 1.8 版本之前,默认是启用 PID namespace 共享的,除非使用 kubelet 标志 --docker-disable-shared-pid=true 禁用。然而在 Kubernetes 1.8 版本以后,情况刚好相反,默认情况下 kubelet 标志 --docker-disable-shared-pid=true,如果要开启,还要设置成 false。下面就来看看 Kubernetes 提供的关于是否共享 PID namespace 的 downward API。
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
shareProcessNamespace: true
containers:
- name: nginx
image: nginx
- name: shell
image: busybox
securityContext:
capabilities:
add:
- SYS_PTRACE
stdin: true
tty: true
如上所示,podSpec.shareProcessNamespace 指示了是否启用 PID namespace 共享。
通过前文的讨论,我们知道 Pod 内容器共享 PID namespace 是很有意义的,那为什么还要开放这个禁止 PID namesapce 共享的开关呢?那是因为当应用程序不会产生其他进程,而且僵尸进程带来的问题就可以忽略不计时,就用不到 PID namespace 的共享了。而且有些场景下,用户希望 Pod 内容器能够与其他容器隔离 PID namespace,例如下面两个场景:
(1)PID namespace 共享时,由于 pause 容器成了 PID =1,其他用户容器就没有 PID 1 了。但像 systemd 这类镜像要求获得 PID 1,否则无法正常启动。有些容器通过 kill -HUP 1 命令重启进程,然而在由 pause 托管 init 进程的 Pod 里,上面这条命令只会给 pause 发信号量。
(2)PID namespace 共享带来 Pod 内不同容器的进程对其他容器是可见的,这包括 /proc 中可见的所有信息,例如,作为参数或环境变量传递的密码,这将带来一定的安全风险。
微信公众号
扫一扫下面的二维码关注微信公众号,在公众号中回复◉加群◉即可加入我们的云原生交流群,和孙宏亮、张馆长、阳明等大佬一起探讨云原生技术

