


最近钉钉火了,因为疫情影响,钉钉被教育部选为给学生用来在线上网课的平台,本以为自己因为业务过硬得到官方的认可,是2020上天选中的宠鹅,万万没想到到由于小学生不爽被占用寒假时间上课,于是集体出征在各大应用商店给钉钉打低分⬇️
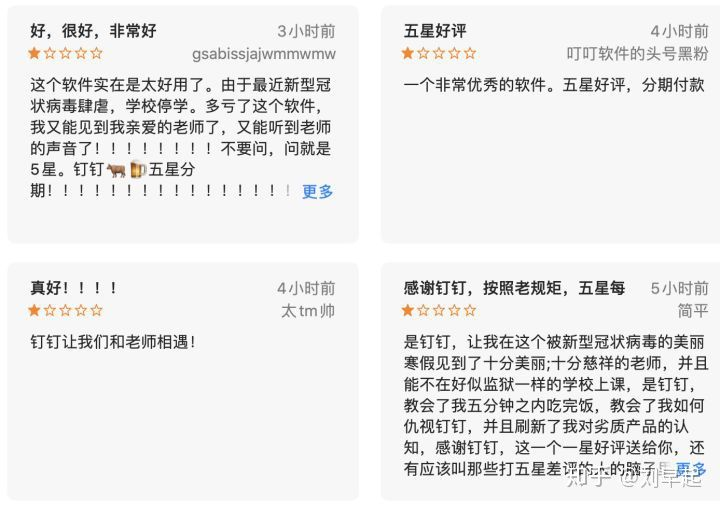
于是就出现了前几天的“钉钉十一亿下载量,整体评分只有一星”,真是好惨一软件。那么就跟随本文一起通过爬取钉钉在App Store的评分,看看用户的真实反应吧。
二、数据爬取
我们的目标就是从App Store官网拿下这些评论数据做分析⬇️
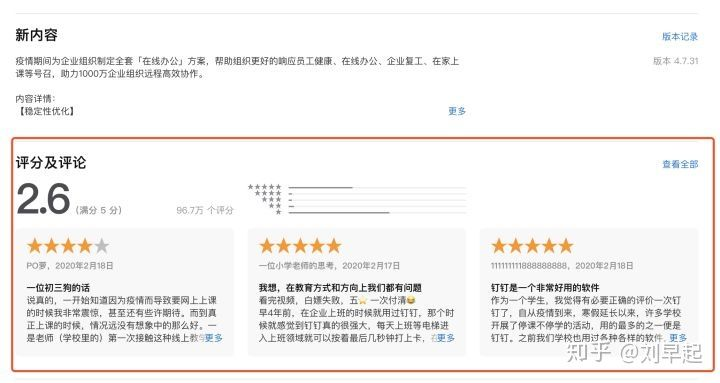
本来以为要写个爬虫在用正则表达式去提取,结果一搜发现有现成的App Store评论API⬇️
https://itunes.apple.com/rss/customerreviews/page=1/id=/sortby=mostrecent/json?l=en&&cc=cn只要将钉钉的id添加进去就OK,这就很简单了,连F12都不用⬇️
于是我们很轻松的就得到了钉钉在App Store的评论API
https://itunes.apple.com/rss/customerreviews/page=1/id=930368978/sortby=mostrecent/json?l=en&&cc=cn打开看看,OK就是这个⬇️,但是比较可惜的是App Store并没有提供评论时间,所以对我们有用的数据就只有用户评分、评论标题、评论内容。

注意到这仅仅是第一页的评论,而通过测试发现最多可以查看10页的评论,所以写一个简单的循环把我们需要的信息提取出来,具体代码⬇️
import requests
import pandas as pd
from pandas import DataFrame
flag = [1,2,3,4,5,6,7,8,9,10]
urllist = []
for i in flag:
url = f"https://itunes.apple.com/rss/customerreviews/page={i}/id=930368978/sortby=mostrecent/json?l=en&&cc=cn"
urllist.append(url)
rating = [] #评分
title = [] #标题
content = [] #内容
for url in urllist:
res = requests.get(url)
data = res.json()['feed']['entry']
for i in range(len(data)):
rating.append(data[i]['im:rating']['label'])
title.append(data[i]['title']['label'])
content.append(data[i]['content']['label'])
data = {'打分':rating,
'标题':title,
'内容':content
}
df = DataFrame(data)最终爬取的数据长这样⬇️
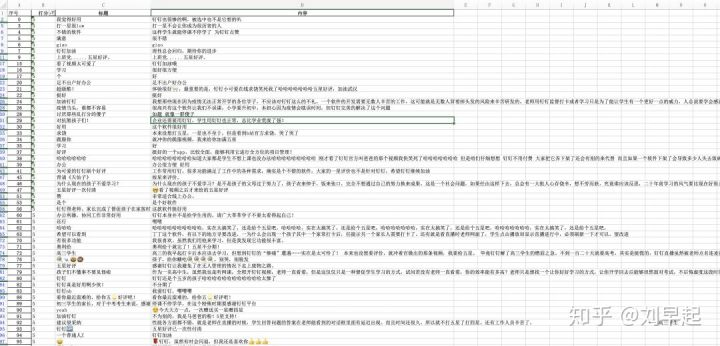
三、数据分析
我们首先看下这500条评分的分值分布
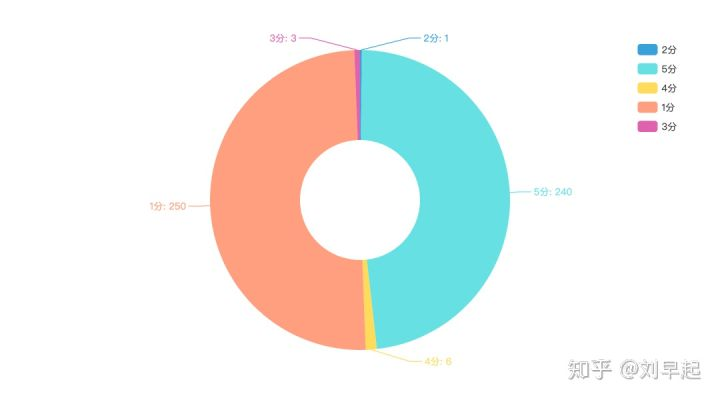
从图中可以看出一共500次评分,1分和5分占了490次,其中打一分的250人,5分的240人,而2分、3分、4分的人数则分别为1、3、6人。看来打分的各位还真是爱憎分明。
接着我们再从title和content中提取与学生相关的文字并统计⬇️
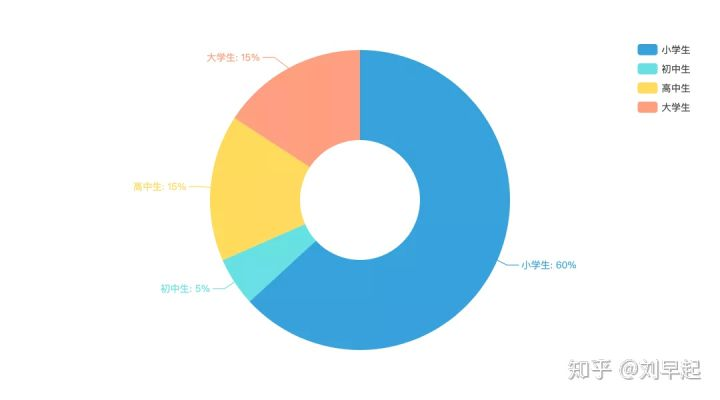
看来不管是不是评论者是不是小学生,都喜欢在评论里面聊小学生。
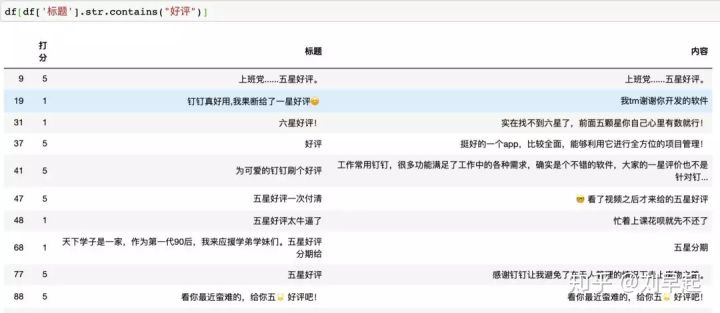
我们再统计一下标题和内容中出现最多的一些关键词。可以用pandas里面的.str.contains()方法⬇️
再可视化一下⬇️
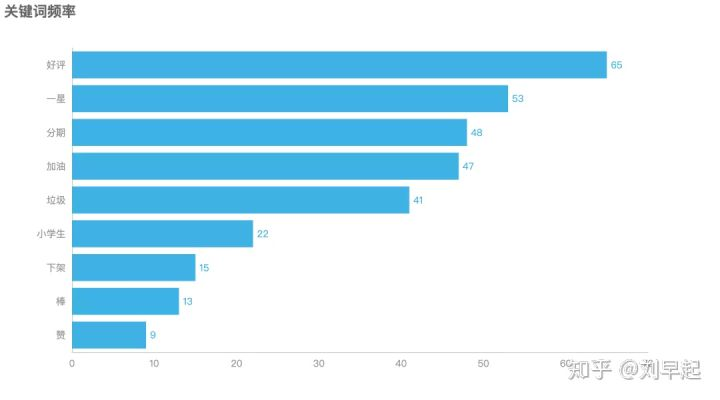
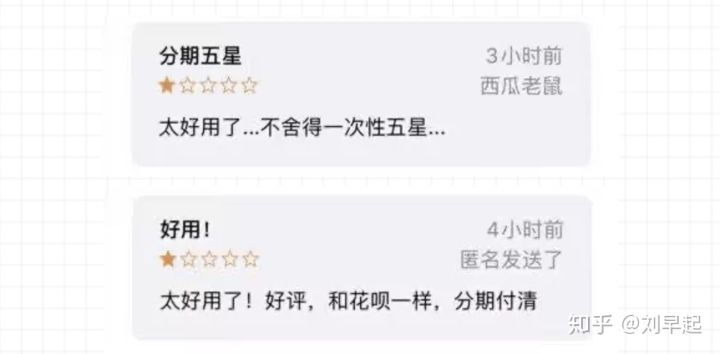
可以看到,给好评的人和给一星的人旗鼓相当,有骂钉钉吵着下架的,也有鼓励钉钉喊着加油的。但是唯一值得关注的是,有不少人想分期消费
好了,最后我们来制作下词云图,上面的可视化主要利用pyecharts,具体在我之前文章中有详细说明。而词云图的制作选择了python里的wordcloud库,具体使用方法就不细说,看代码⬇️
from wordcloud import WordCloud
import matplotlib.pyplot as plt #绘制图像的模块
import jieba #jieba分词
path_txt='content.txt'
f = open(path_txt,'r',encoding='UTF-8').read()
# 结巴分词,生成字符串,wordcloud无法直接生成正确的中文词云
cut_text = " ".join(jieba.cut(f))
wordcloud = WordCloud(
#设置字体,不然会出现口字乱码,文字的路径是电脑的字体一般路径,可以换成别的
font_path="msyh.ttc",
#设置了背景,宽高
background_color="white",width=2000,height=1880).generate(cut_text)
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()从标题生成的词云图来看,依旧是褒贬掺半

下面是由内容生成的词云图
四、结束语
以上就是本文的全部内容,笔者也是使用钉钉进行办公。而对于钉钉这波哭笑不得的热搜,我想钉钉官方鬼畜已经给出了答案


====================================================================
更多好玩有趣的python欢迎关注我的公-众-号:早起python

