

论文提出anchor-free和proposal-free的one-stage的目标检测算法FCOS,不再需要anchor相关的的超参数,在目前流行的逐像素(per-pixel)预测方法上进行目标检测,根据实验结果来看,FCOS能够与主流的检测算法相比较,达到SOTA,为后面的大热的anchor-free方法提供了很好的参考
来源:【晓飞的算法工程笔记】 公众号
论文: FCOS: Fully Convolutional One-Stage Object Detection

Introduction
大多目标检测网络都是anchor-based,虽然anchor能带来很大的准确率提升,但也会带来一些缺点:
- 准确率对anchor的尺寸、长宽比和数量较为敏感,这些超参都会人工细调
- anchor的尺寸和长宽是固定的,如果目标的相关属性相差较大,会比较难预测
- 为了高召回,通常会使用密集的anchor布满输入,大多为负样本,导致训练不平衡
- anchor需要如IOU的复杂计算

近期,FCNs在各视觉任务中都有不错的表现,但目标检测由于anchor的存在,不能进行纯逐像素预测,于是论文抛弃anchor,提出逐像素全卷积目标检测网络FCOS网络,总结如下:
- 效仿前期的FCNs-based网络,如DenseBox,每个像素回归一个4D向量指代预测框相对于当前像素位置的偏移,如图1左
- 为了预测不同尺寸的目标,DenseBox会缩放或剪裁生成图像金字塔进行预测,而且当目标重叠时,会出现像素不知道负责预测哪个目标的问题,如图1右。在对问题进行研究后,论文发现使用FPN能解决以上问题,后面会细讲
- 由于预测的结果会产生许多低质量的预测结果,论文采用center-ness分支来预测当前像素与对应目标中心点的偏离情况,用来去除低质量预测结果以及进行NMS
Our Approach
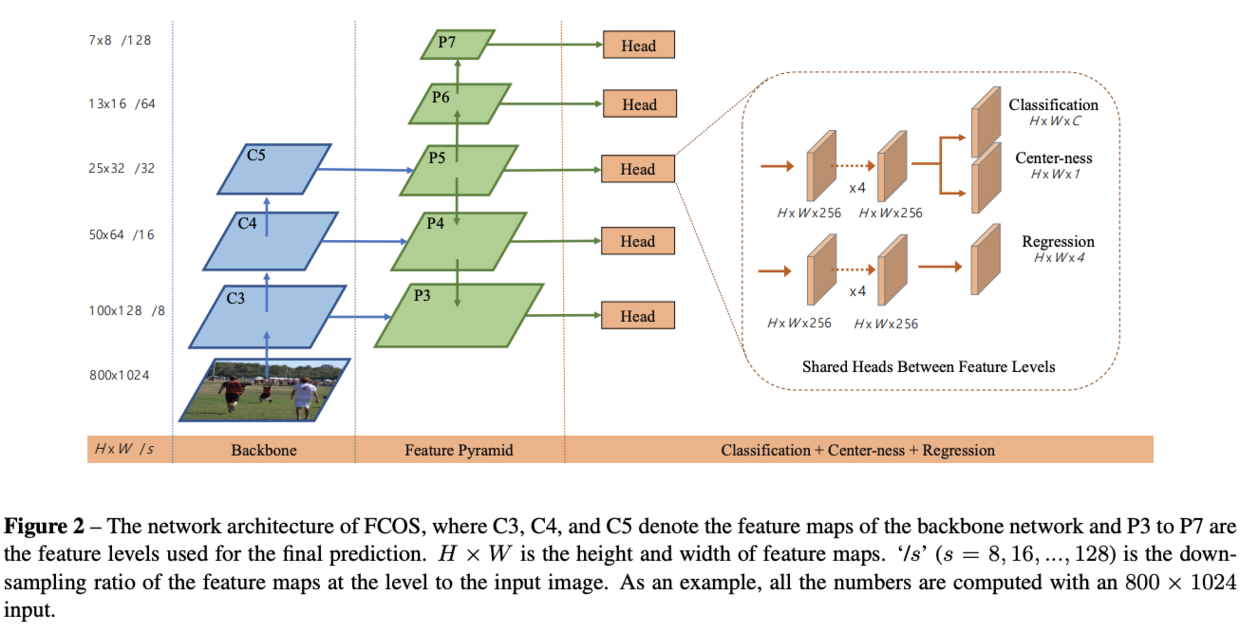
Fully Convolutional One-Stage Object Detector
让为层
的特征图,
为层的总stride,输入的GT为
,
分别为box的左上角和右下角坐标以及类别,
为类别数。特征图
的每个位置
,可以通过
映射回原图,FCOS直接预测相对于当前像素的box位置,而不是anchor的那样将像素作为中心再回归
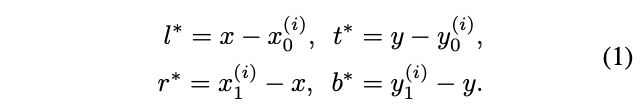
当像素落在GT中则认为是正样本,将类别
设置为目标类别,否则设置为0。除了类别,还有4D向量
作为回归目标,分别为box的四条边与像素的距离。当像素落在多个GT中时,直接选择区域最小的作为回归目标。相对于anchor-based的IOU判断,FCOS能生成更多的正样本来训练回归器
-
Network Outputs
网络最终输出80D分类标签向量和4D box坐标向量
,训练
个二分类器而不是多分类器,在最后特征后面分别接4个卷积层用于分类和定位分支,在定位分支使用
保证结果为正,整体输出比anchor-based少9x倍
-
Loss Function
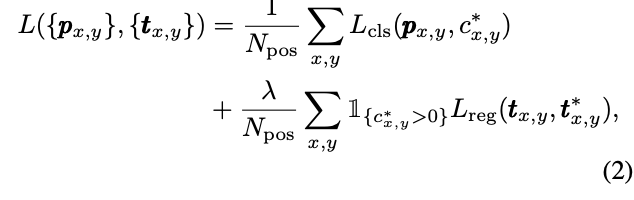
为focal loss,
为UnitBox中的IOU loss,
为正样本数,
为平衡权重,公式2计算特征图上的所有结果
-
Inference
对于输入图片,推理得到特征图的分类分数
以及回归预测
,然后取
的作为正样本,公共公式1得到预测框位置
Multi-level Prediction with FPN for FCOS
下面讲下FCOS如何使用FPN来解决之前提到的问题:
- 由于large stride,通常最后的特征图都会面临较低的最大可能召回(best possible recall, BPR)问题。在anchor based detector中,可以通过降低IOU阈值来弥补,而实验发现,FCN-based的FCOS本身就能在large stride情况下还有更好的BPR,加上FPN,BPR则会更高
- 目标框重叠会导致难解的歧义,例如不知道像素对应哪个回归目标,论文使用多层预测来解决这个问题,甚至FCN-based效果比anchor-based要好
如图2,FPN使用层特征,其中
、
和
分别通过
、
和
的
卷积以及top-down connection生成,
和
则是分别通过
和
进行stride为2的
卷积生成,各特征的stride分别为8,16,32,64和128
anchor-based方法对不同的层使用不同的大小,论文则直接限制每层的bbox回归范围。首先计算,
,
和
,如果满足
或
,则设为负样本,不需要进行bbox回归。
为层
的最大回归距离,
,
,
,
,
和
分别为0,64,128,256,512和
。如果在这样设置下,像素仍存在歧义,则选择区域最小的作为回归目标,从实验来看,这样设定的结果很好
最后,不同层间共享head,不仅减少参数,还能提高准确率。而由于不同的层负责不同的尺寸,所以不应该使用相同的head,因此,论文将改为
,添加可训练的标量
来自动调整不同层的指数基底
Center-ness for FCOS
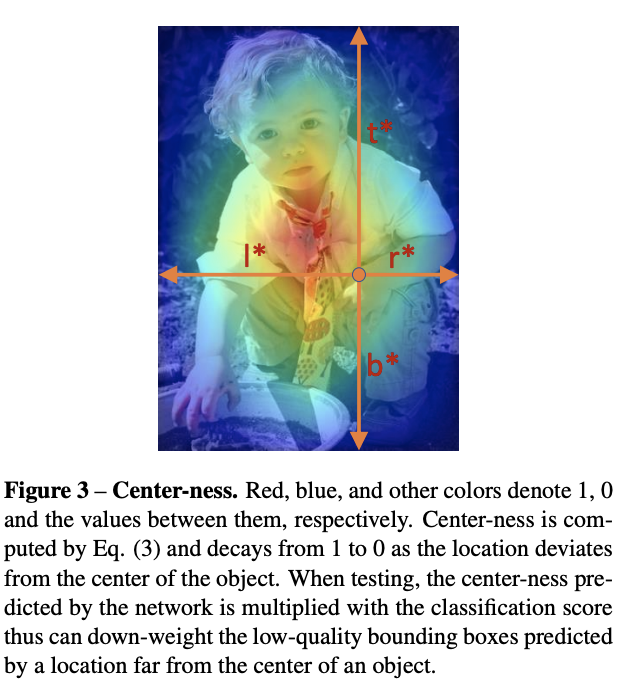
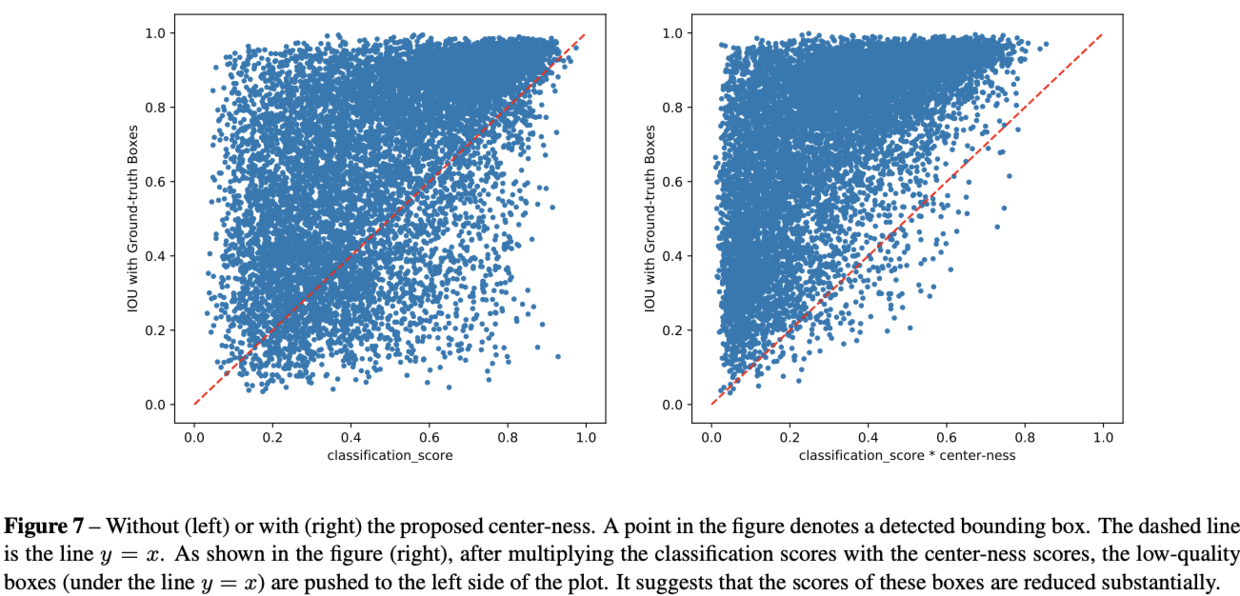
使用FPN后,FCOS与anchor-based detector仍然存在差距,主要来源于低质量的预测box,这些box的大多由距离目标中心点相当远的像素产生。因此,论文提出新的独立分支来预测像素的center-ness,用来评估像素与目标中心点的距离
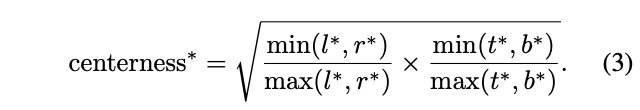
center-ness的gt计算如公式3,取值,使用二值交叉熵进行训练。在测试时,最终的分数是将分类分数与center-ness进行加权,低质量的box分数会降低,最后可能通过NMS进行过滤
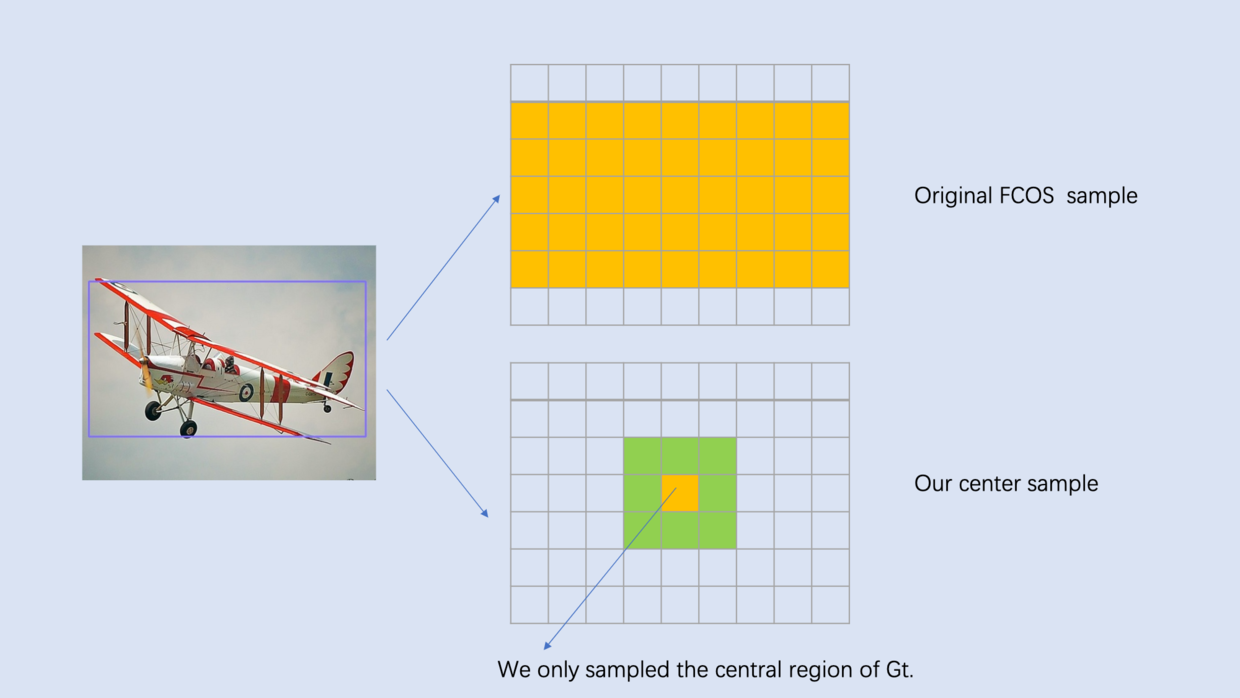
center-ness的另一种形式是在训练时仅用目标框的中心区域像素作为正样本,这会带来额外的超参数,目前已经验证性能会更好
Experiments
Ablation Study
-
Multi-level Prediction with FPN

best possible recall(BPR)定义为检测器能够回归的gt比例,如果gt被赋予某个预测结果,即为能够回归。从表1看来,不用FPN的FCOS直接有95.55%,而anchor-based的经典实现只有86.82%,加上FPN后就提高到98.40%

在原始FCOS中,正样本中歧义目标的比例为23.16%,使用FPN后能够降低到7.14%。这里论文提到,同类别目标的歧义是没关系的,因为不管预测为哪个目标,都是正确的,预测漏的目标可以由其它更靠近他的像素来预测。所以,只考虑不同类别的歧义比例大概为17.84%,使用FPN后可降为3.75%。而在最终结果中,仅2.3%的框来自于歧义像素,考虑不同类别的歧义,则仅有1.5%的,所以歧义不是FCN-based FCOS的问题
-
With or Without Center-ness
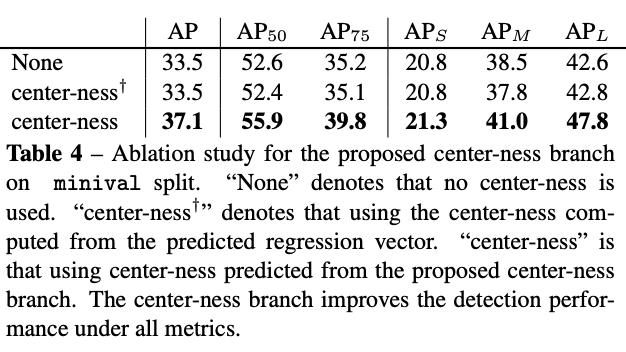
center-ness分支能够将AP从33.5%升为37.1%,比直接从回归结果中计算的方式要好
-
FCOS vs. Anchor-based Detectors
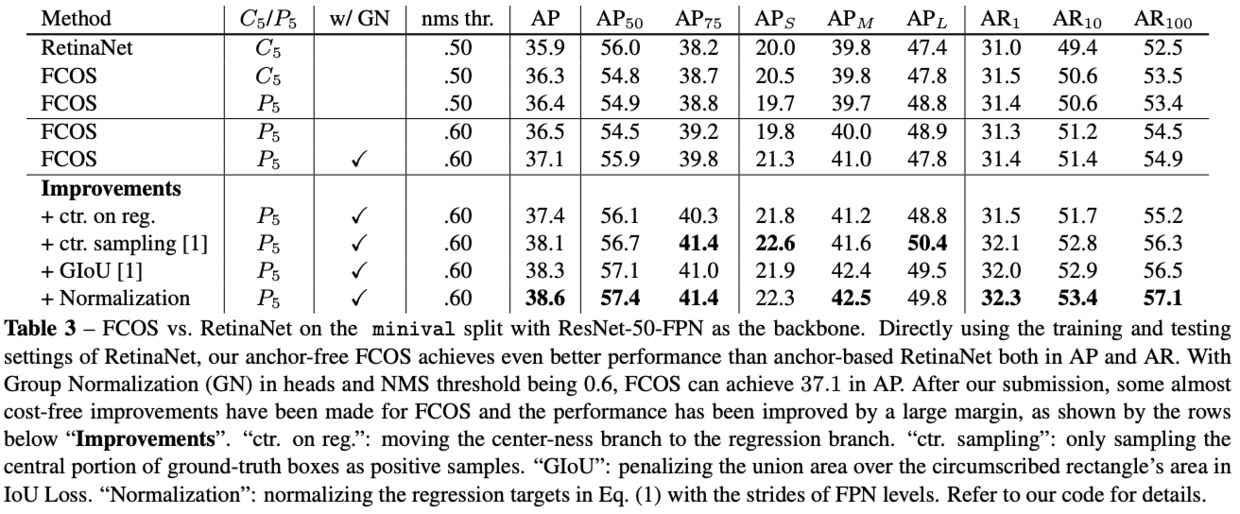
相对于RetinaNet,之前FCOS使用了分组卷积(GN)和使用来产生
和
,为了对比,去掉以上的改进进行实验,发现准确率依旧比anchor-based要好
-
Comparison with State-of-the-art Detectors
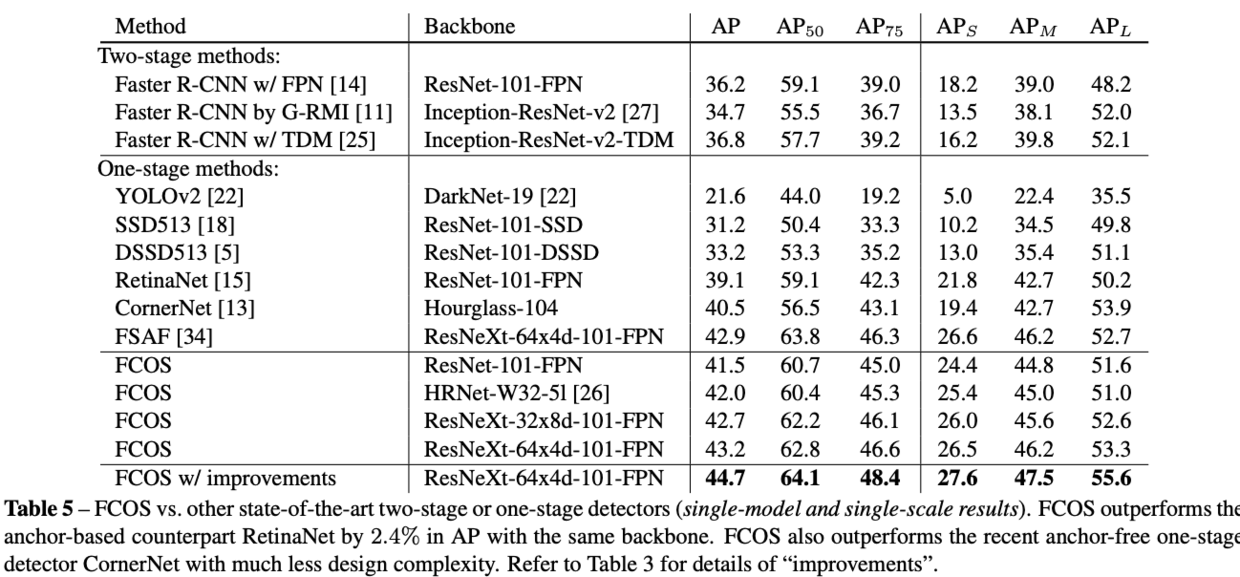
Extensions on Region Proposal Networks

将anchor-based的RPNs with FPN替换成FCOS,能够显著提高和
Class-agnostic Precision-recall Curves
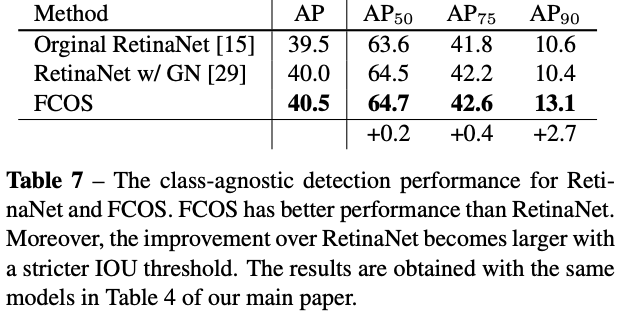
Visualization for Center-ness
CONCLUSION
论文提出anchor-free和proposal-free的one-stage的目标检测算法FCOS,不再需要anchor相关的的超参数,在目前流行的逐像素(per-pixel)预测方法上进行目标检测,根据实验结果来看,FCOS能够与主流的检测算法相比较,达到SOTA,为后面的大热的anchor-free方法提供了很好的参考
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

