

因为工作需要使用 HBase,因此调研了 HBase 相关的内容。本文的写作目的不仅仅是对前期工作的总结,也希望能帮助到工作繁忙但又想了解 HBase 的同学。在本文写作过程中,将穿插 MySQL 相关内容,希望能帮助理解 HBase 。
本文主要讨论以下几个问题,所述内容仅为个人思考,见解有限,有误之处还望批评指正。
- HBase 是什么?其架构是怎样的?
- HBase 如何管理数据?
- HBase 是分布式数据库,那数据怎么路由?
- HBase 的适用场景?
- HBase 和 MySQL 的主要区别?
- HBase 怎么用?如何实现 CREATE、INSERT、SELECT、UPDATE、DELETE、LIKE 操作?
1 HBase
1.1 HBase 架构
HBase 是什么?其架构是怎样的?
HBase(Hadoop DataBase),是一种非关系型分布式数据库(NoSQL),支持海量数据存储(官方:单表支持百亿行百万列)。HBase 采用经典的主从架构,底层依赖于 HDFS,并借助 ZooKeeper 作为协同服务,其架构大致如下:
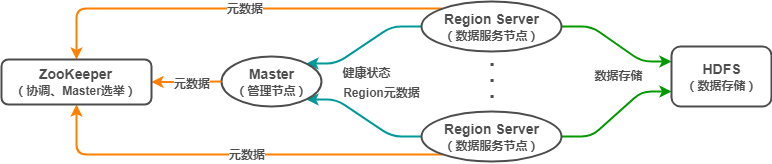
其中,
- Master:HBase 管理节点。管理 Region Server,分配 Region 到 Region Server,提供负载均衡能力;执行创建表等 DDL 操作。
- Region Server:HBase 数据节点。管理 Region,一个 Region Server 可包含多个 Region,Region 相当于表的分区。客户端可直接与 Region Server 通信,实现数据增删改查等 DML 操作。
- ZooKeeper:协调中心。负责 Master 选举,节点协调,存储 hbase:meta 等元数据。
- HDFS:底层存储系统。负责存储数据,Region 中的数据通过 HDFS 存储。
对 HBase 全局有了基本理解后,我认为有几个比较重要的点值得关注:HBase 数据模型、Region 的概念、数据路由。
1.2 HBase 数据模型
HBase 如何管理数据?(逻辑层)
HBase 的数据模型和 MySQL 等关系型数据库有比较大的区别,其是一种 ”Schema-Flexiable“ 的理念。
- 在表的维度,其包含若干行,每一行以 RowKey 来区分。
- 在行的维度,其包含若干列族,列族类似列的归类,但不只是逻辑概念,底层物理存储也是以列族来区分的(一个列族对应不同 Region 中的一个 Store)。
- 在列族的维度,其包含若干列,列是动态的。与其说是列,不如说是一个个键值对,Key 是列名,Value 是列值。
HBase 的表结构如下:
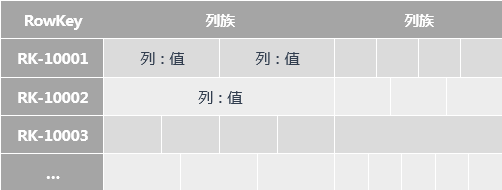
- RowKey(行键):RowKey 是字典有序的,HBase 基于 RowKey 实现索引;
- Column Family(列族):纵向切割,一行可有多个列族,一个列族可有任意个列;
- Key-Value(键值对):每一列存储的是一个键值对,Key 是列名,Value 是列值;
- Byte(数据类型):数据在 HBase 中以 Byte 存储,实际的数据类型交由用户转换;
- Version(多版本):每一列都可配置相应的版本,获取指定版本的数据(默认返回最新版本);
- 稀疏矩阵:行与行之间的列数可以不同,但只有实际的列才会占用存储空间。
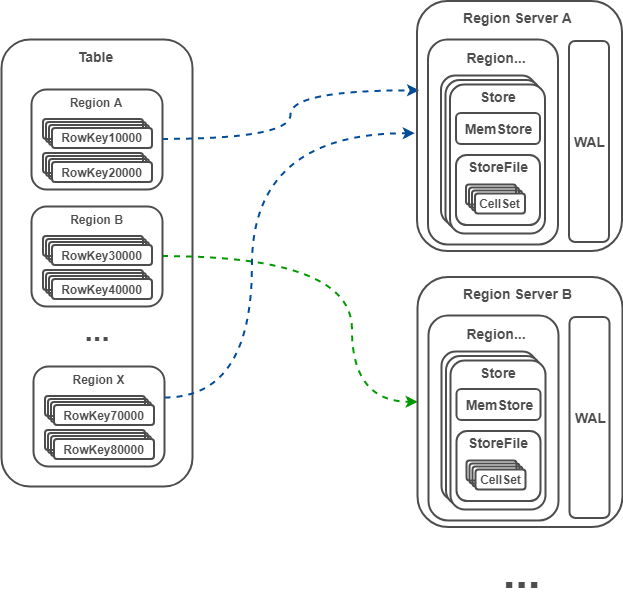
1.3 Region
HBase 如何管理数据?(物理层)
Region 是 HBase 中的概念,类似 RDBMS 中的分区。
- Region 是表的横向切割,一个表由一个或多个 Region 组成,Region 被分配到各个 Region Server;
- 一个 Region 根据列族分为多个 Store,每个 Store 由 MemStore 和 StoreFile 组成;数据写入 MemStore,MemStore 类似输入缓冲区,持久化后为 StoreFile;数据写入的同时会更新日志 WAL,WAL 用于发生故障后的恢复,保障数据读写安全;
- 一个 StoreFile 对应一个 HFile,HFile 存储在 HDFS 。
下面是我梳理的大致模型:
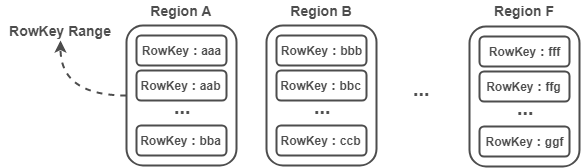
1)Region 是一个 RowKey Range
每个 Region 实际上是一个 RowKey Range,比如 Region A 存放的 RowKey 区间为 [aaa,bbb),Region B 存放的 RowKey 区间为 [bbb,ccc) ,以此类推。Region 在 Region Server 中存储也是有序的,Region A 必定在 Region B 前面。
注:这里将 RowKey 设计为 aaa,而不是 1001 这样的数字,是为了强调 RowKey 并非只能是数字,只要能进行字典排序的字符都是可以的,如:abc-123456 。
2)数据被路由到各个 Region
表由一个或多个 Region 组成(逻辑),Region Server 包含一个或多个 Region(物理)。数据的路由首先要定位数据存储在哪张表的哪个 Region,表的定位直接根据表名,Region 的定位则根据 RowKey(因为每个 Region 都是一个 RowKey Range,因此根据 RowKey 很容易知道其对应的 Region)。
注:Master 默认采用 DefaultLoadBalancer 策略分配 Region 给 Region Server,类似轮询方式,可保证每个 Region Server 拥有相同数量的 Region(这里只是 Region 的数量相同,但还是有可能出现热点聚集在某个 Region,从而导致热点聚集在某个 Region Server 的情况)。
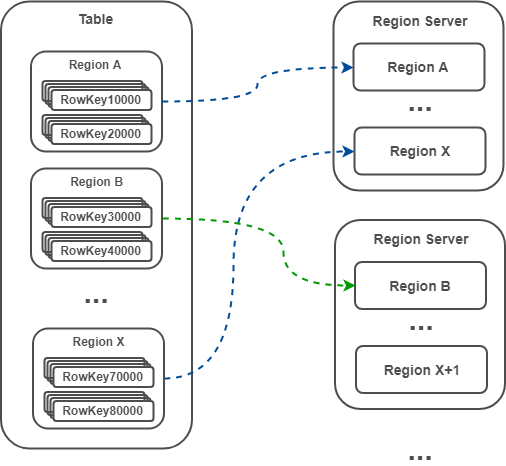
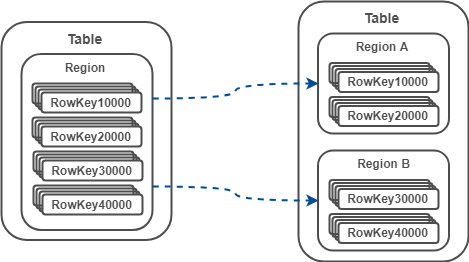
3)当一个表太大时,Region 将自动分裂
- 自动分裂
0.94 版本之前,Region 分裂策略为 ConstantSizeRegionSplitPolicy ,根据一个固定值触发分裂。
0.94 版本之后,分裂策略默认为 IncreasingToUpperBoundRegionSplitPolicy,该策略会根据 Region 数量和 StoreFile 的最大值决策。当 Region 的数量小于 9 且 StoreFile 的最大值小于某个值时,分裂 Region;当Region数量大于9 时,采用 ConstantSizeRegionSplitPolicy 。
- 手动分裂
在 ConstantSizeRegionSplitPolicy 下,通过设置 hbase.hregion.max.filesize 控制 Region 分裂。
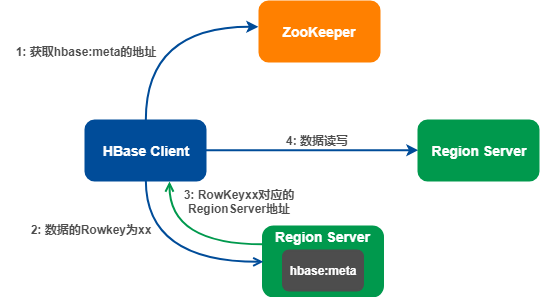
1.4 数据路由 hbase:meta
HBase 是分布式数据库,那数据怎么路由?
数据路由借助 hbase:meta 表完成,hbase:meta 记录的是所有 Region 的元数据信息,hbase:meta 的位置记录在 ZooKeeper 。
注:一些比较老的文章可能会提到 .root 和 .meta 两个表。事实上, .root 和 .meta 两个表是 HBase 0.96 版本之前的设计。在 0.96 版本后,.root 表已经被移除,.meta 表更名为 hbase:meta。
hbase:meta 表的格式如下:

其中,
- table:表名;
- region start key:Region 中的第一个 RowKey,如果 region start key 为空,表示该 Region 是第一个 Region;
- region id:Region 的 ID,通常是 Region 创建时的 timestamp;
- regioninfo:该 Region 的 HRegionInfo 的序列化值;
- server:该 Region 所在的 Region Server 的地址;
- serverstartcode:该 Region 所在的 Region Server 的启动时间。
一条数据的写入流程:
数据写入时需要指定表名、Rowkey、数据内容。
- HBase 客户端访问 ZooKeeper,获取 hbase:meta 的地址,并缓存该地址;
- 访问相应 Region Server 的 hbase:meta;
- 从 hbase:meta 表获取 RowKey 对应的 Region Server 地址,并缓存该地址;
- HBase 客户端根据地址直接请求 Region Server 完成数据读写。
注 1:数据路由并不涉及Master,也就是说 DML 操作不需要 Master 参与。借助 hbase:meta,客户端直接与 Region Server 通信,完成数据路由、读写。
注 2:客户端获取 hbase:meta 地址后,会缓存该地址信息,以此减少对 ZooKeeper 的访问。同时,客户端根据 RowKey 查找 hbase:meta,获取对应的 Region Server 地址后,也会缓存该地址,以此减少对 hbase:meta 的访问。因为 hbase:meta 是存放在 Region Server 的一张表,其大小可能很大,因此不会缓存 hbase:meta 的完整内容。
1.5 HBase 适用场景
- 不需要复杂查询的应用。HBase 原生只支持基于 RowKey 的索引,对于某些复杂查询(如模糊查询,多字段查询),HBase 可能需要全表扫描来获取结果。
- 写密集应用。HBase 是一个写快读慢(慢是相对的)的系统。HBase 是根据 Google 的 BigTable 设计的,典型应用就是不断插入新数据(如 Google 的网页信息)。
- 对事务要求不高的应用。HBase 只支持基于 RowKey 的事务。
- 对性能、可靠性要求高的应用。HBase 不存在单点故障,可用性高。
- 数据量特别大的应用。HBase 支持百亿行百万列的数据量,单个 Region 过大将自动触发分裂,具备较好的伸缩能力。
2 HBase 与 MySQL 的区别?
HBase 和 MySQL 的主要区别?
2.1 MySQL
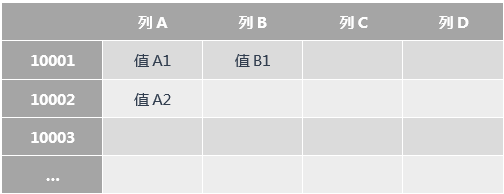
MySQL 表结构规整,每一行有固定的列。
- 创建表时,需要指定表名,预设字段(列)个数以及数据类型,Schema 是固定的。
- 插入数据时,只需根据表的 Schema 填充每个列的值即可。如果 Schema 没有该列,则无法插入。
2.2 HBase
HBase 支持动态列,不同行可拥有不同数量的列,可动态增加新的列。HBase 的表结构看起来杂乱无章,但却有利于存储稀疏数据。
- 创建表时,需指定表名、列族,无需指定列的个数、数据类型,Schema 是灵活的。
- 插入数据时,需要指定表名、列族、RowKey、若干个列(列名和列值),这里列的个数可以是一个或多个。
2.3 对比
进一步,假设 ct_account_info_demo 表中只有一条记录(account_id = 1,account_owner = Owner1,account_amount = 23.0,is_deleted = n),分别通过 MySQL 和 HBase 查找该记录。
MySQL 返回的结果:
mysql> select * from ct_account_info_demo;
+------------+---------------+----------------+------------+
| account_id | account_owner | account_amount | is_deleted |
+------------+---------------+----------------+------------+
| 1 | Owner1 | 23.0 | n |
+------------+---------------+----------------+------------+
1 rows in set (0.01 sec)
HBase 返回的结果:
hbase(main):001:0> scan 'ct_account_info_demo';
ROW COLUMN+CELL
1 column=CT:account_amount, timestamp=1532502487735, value=23.0
1 column=CT:account_id, timestamp=1532909576152, value=1
1 column=CT:account_owner, timestamp=1532502487528, value=Owner1
1 column=CT:is_deleted, timestamp=1532909576152, value=n
上述结果都表示一行数据,MySQL 的返回结果比较直观,容易理解。
HBase 返回的结果其实是多个键值对,ROW 表示数据的 RowKey,COLUMN+CELL 表示该 RowKey 对应的内容。
COLUMN+CELL 中又是多个键值对,如:
column=CT:account_amount, timestamp=1532502487735, value=23.0
表示列族 CT 的列 account_amount 的值为 23.0,时间戳为 1532502487735 。
注:ROW 为 1 是因为这里 RowKey = {account_id},CT 是提前定义的列族(HBase 在插入数据时需要指定 RowKey、Column Family)。
总的来说,
- HBase 比 MySQL 多了 RowKey 和 Column Family 的概念,这里的 RowKey 类似 MySQL 中的主键,Column Family 相当于多个列的“归类”。
- 列族只有一个的情况下,HBase 的 Schema 和 MySQL 可以保持一致,但 HBase 允许某些字段为空或动态增加某个列,而 MySQL 只可根据 Schema 填充相应的列,不能动态增减列。
- 因为 HBase 的 Schema 是不固定的,所以每次插入、查找数据不像 MySQL 那么简洁,HBase 需要指定行键、列族、列等信息。
更为详细的对比如下表(引自:HBase 深入浅出):
| RDBMS | HBase | |
|---|---|---|
| 硬件架构 | 传统的多核系统,硬件成本昂贵 | 类似于 Hadoop 的分布式集群,硬件成本低廉 |
| 容错性 | 一般需要额外硬件设备实现 HA 机制 | 由软件架构实现,因为多节点,所以不担心单点故障 |
| 数据库大小 | GB、TB | PB |
| 数据排布 | 以行和列组织 | 稀疏的、分布的、多维的 Map |
| 数据类型 | 丰富的数据类型 | Bytes |
| 事务支持 | 全面的 ACID 支持,支持 Row 和表 | ACID 只支持单个 Row 级别 |
| 查询语言 | SQL | 只支持 Java API (除非与其他框架一起使用,如 Phoenix、Hive) |
| 索引 | 支持 | 只支持 Row-key(除非与其他技术一起应用,如 Phoenix、Hive) |
| 吞吐量 | 数千查询/每秒 | 百万查询/每秒 |
3 HBase 相关操作(CRUD)
HBase 怎么用?如何实现 CREATE、INSERT、SELECT、UPDATE、DELETE、LIKE 操作?
为便于理解,结合 MySQL 说明 HBase 的 DML 操作,演示如何使用 HBase 来实现 MySQL 的 CREATE、 INSERT、SELECT、UPDATE、DELETE、LIKE 操作。
为方便代码复用,这里提前封装获取 HBase 连接的代码:
// 获取HBase连接
public Connection getHBaseConnect() throws IOException {
// 配置
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "127.0.0.1");
conf.set("hbase.zookeeper.property.clientPort", "2181");
conf.set("log4j.logger.org.apache.hadoop.hbase", "WARN");
// 创建连接
Connection connection = ConnectionFactory.createConnection(conf);
return connection;
}
3.0 CREATE
// 创建表
public void createTable (String tableName,String columnFamily) {
try {
// 获取连接,DDL操作需要获取Admin
Connection hbaseConnect = hbase.getHBaseConnect();
Admin admin = hbaseConnect.getAdmin();
// 设置表名
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf(tableName));
// 设置列族
tableDescriptor.addFamily(new HColumnDescriptor(columnFamily));
// 创建表
admin.createTable(tableDescriptor);
} catch (IOException e) {
e.printStackTrace();
}
}
3.1 INSERT
MySQL:
INSERT INTO ct_account_info_demo(account_id, account_owner , account_amount, is_deleted ) VALUES (?,?,?,?)
HBase 实现上述 SQL 语句的功能:
// 插入数据
public int insertAccount(Long accountId, String accountOwner, BigDecimal accountAmount) {
String tableName = "ct_account_info_demo"; // 表名
// 行键(为便于理解,这里将accountID作为RowKey,实际应用中RowKey的设计应该重点考虑)
String rowKey = String.valueOf(accountId);
String familyName = "account_info"; // 列族(在创建表时已定义)
Map<String,String> columns = new HashMap<>(); // 多个列
columns.put("account_id",String.valueOf(accountId));
columns.put("account_owner",accountOwner);
columns.put("account_amount",String.valueOf(accountAmount));
columns.put("is_deleted","n");
updateColumnHBase(tableName,rowKey,familyName,columns); // 更新HBase数据
return 0;
}
private void updateColumnHBase(String tableName, String rowKey, String familyColumn, Map<String,String> columns) {
try {
Connection hbaseConnect = hbase.getHBaseConnect(); // 获取HBase连接
Table table = hbaseConnect.getTable(TableName.valueOf(tableName)); // 获取相应的表
Put put = new Put(Bytes.toBytes(rowKey)); // 封装Put对象
for (Map.Entry<String, String> entry : columns.entrySet()) {
put.addColumn(Bytes.toBytes(familyColumn), Bytes.toBytes(entry.getKey()),
Bytes.toBytes(entry.getValue()));
}
table.put(put); // 提交数据
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
3.2 SELECT
MySQL:
SELECT * from ct_account_info_demo WHERE account_id = #{account_id}
HBase 实现上述 SQL 语句的功能:
// 读取数据
public Account getAccountInfoByID(Long accountId) {
Account account = new Account();
String tableName = "ct_account_info_demo"; // 表名
String familyName = "account_info"; // 列族
String rowKey = String.valueOf(accountId); // 行键
List<String> columns = new ArrayList<>(); // 设置需要返回哪些列
columns.add("account_id");
columns.add("account_owner");
columns.add("account_amount");
columns.add("is_deleted");
// 获取某一行指定列的数据
HashMap<String,String> accountRecord = getColumnHBase(tableName, rowKey,familyName,columns);
if (accountRecord.size()==0) {
return null;
}
// 根据查询结果,封装账户信息
account.setId( Long.valueOf(accountRecord.get("account_id")));
account.setOwner(accountRecord.get("account_owner"));
account.setBalance(new BigDecimal(accountRecord.get("account_amount")));
account.setDeleted(accountRecord.get("isDeleted"));
return account;
}
private HashMap<String, String> getColumnHBase(String tableName, String rowKey, String familyColumn, List<String> columns) {
HashMap<String,String> accountRecord = new HashMap<>(16);
try {
Connection hbaseConnect = hbase.getHBaseConnect(); // 获取HBase连接
Table table = hbaseConnect.getTable(TableName.valueOf(tableName)); // 获取相应的表
Get get = new Get(Bytes.toBytes(rowKey)); // 封装Get对象
for (String column:columns) {
get.addColumn(Bytes.toBytes(familyColumn), Bytes.toBytes(column));
}
Result result = table.get(get); // 获取数据
if (result.listCells() != null) {
for (Cell cell : result.listCells()) {
String k = Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength());
String v = Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength());
accountRecord.put(k,v); // 将结果存放在map中
}
}
table.close();
} catch (IOException e) {
e.printStackTrace();
}
return accountRecord; // 返回本次查询的结果
}
3.3 UPDATE
MySQL:
UPDATE ct_account_info_demo SET account_amount = account_amount + #{transAmount} WHERE account_id = #{fromAccountId}
HBase 实现上述 SQL 语句的功能:
// 更新数据
public void transIn(Long accountId, BigDecimal accountAmount) {
String tableName = "ct_account_info_demo"; // 表名
String rowKey = String.valueOf(accountId); // 行键
String familyName = "account_info"; // 列族
List<String> columns = new ArrayList<>(); // 获取账户信息
columns.add("account_amount");
HashMap<String,String> accountRecord = getColumnHBase(tableName, rowKey,familyName,columns);
// 增加账户余额
BigDecimal newAccountAmount = new BigDecimal(accountRecord.get("account_amount")).add(accountAmount);
// 更新账户的余额
Map<String,String> fromColumns = new HashMap<>(1);
fromColumns.put("account_amount",String.valueOf(newAccountAmount));
// 更新HBase数据
updateColumnHBase(tableName,rowKey,familyName,fromColumns);
}
3.4 DELETE
MySQL:
DELETE FROM ct_account_info_demo WHERE account_id = ?
通过 HBase 实现上述 SQL 语句的功能:
// 删除数据
public void deleteAccount (String tableName, Long accountId) {
try {
Connection hbaseConnect = hbase.getHBaseConnect();
// 行键
String rowKey = String.valueOf(accountId);
// 列族
String familyName = "account_info";
Table table = hbaseConnect.getTable(TableName.valueOf(tableName));
Delete delete = new Delete(Bytes.toBytes(rowKey));
// 删除该行指定列的数据
delete.deleteColumn(Bytes.toBytes(familyName), Bytes.toBytes("account_id"));
delete.deleteColumn(Bytes.toBytes(familyName), Bytes.toBytes("account_owner"));
delete.deleteColumn(Bytes.toBytes(familyName), Bytes.toBytes("account_amount"));
delete.deleteColumn(Bytes.toBytes(familyName), Bytes.toBytes("is_deleted"));
// 删除整个列族
//delete.deleteFamily(Bytes.toBytes(familyName));
table.delete(delete);
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
3.5 LIKE
MySQL:
SELECT * FROM ct_account_info_demo WHERE account_id = #{account_id} AND account_owner LIKE CONCAT('%', #{keyWord}, '%')
HBase 实现上述 SQL 语句的功能:
// 模糊查询
public Account getAccountInfoByKeyWord(Long accountId, String keyWord) {
Account account = new Account();
// 表名
String tableName = "ct_account_info_demo";
// 起始行键(闭区间)
String startRow = String.valueOf(accountId);
// 终止行键(开区间,结果不包含stopRow)
String stopRow = String.valueOf(accountId);
// 列族
String familyName = "account_info";
// 设置需要模糊查询的列
String targetColumn = "account_owner";
// 设置需要返回哪些列
List<String> columns = new ArrayList<>();
columns.add("account_id");
columns.add("account_owner");
columns.add("account_amount");
columns.add("is_deleted");
// 模糊查询
HashMap<String,String> accountRecord = singleColumnFilter(tableName, familyName, startRow, stopRow, targetColumn, keyWord, columns);
if (accountRecord.size()==0) {
return null;
}
// 根据查询结果,封装账户信息
account.setId( Long.valueOf(accountRecord.get("account_id")));
account.setOwner(accountRecord.get("account_owner"));
account.setBalance(new BigDecimal(accountRecord.get("account_amount")));
account.setDeleted(accountRecord.get("isDeleted"));
return account;
}
private HashMap<String,String> singleColumnFilter(String tableName, String familyColumn, String startRowKey, String stopRowKey, String targetColumn, String keyWord, List<String> columns) {
if (hbase == null) {
throw new NullPointerException("HBaseConfig");
}
if (familyColumn == null || columns.size() == 0) {
return null;
}
HashMap<String,String> accountRecord = new HashMap<>(8);
try {
// 获取HBase连接
Connection hbaseConnect = hbase.getHBaseConnect();
// 获取相应的表
Table table = hbaseConnect.getTable(TableName.valueOf(tableName));
// 封装Scan
Scan scan = new Scan();
scan.setStartRow(Bytes.toBytes(startRowKey));
scan.setStopRow(Bytes.toBytes(stopRowKey));
// 设置查询的列
for (String column:columns) {
scan.addColumn(Bytes.toBytes(familyColumn), Bytes.toBytes(column));
}
// 定义过滤器:某一列的值是否包含关键字
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(Bytes.toBytes(familyColumn),Bytes.toBytes(targetColumn),CompareFilter.CompareOp.EQUAL,new SubstringComparator(keyWord));
//ValueFilter filter = new ValueFilter(CompareFilter.CompareOp.EQUAL, new SubstringComparator(keyWord));
FilterList list = new FilterList(FilterList.Operator.MUST_PASS_ONE,singleColumnValueFilter);
// Scan添加过滤器
scan.setFilter(list);
// 获取数据
ResultScanner resultScanner = table.getScanner(scan);
for(Result result = resultScanner.next();result!=null;result = resultScanner.next()){
if (result.listCells() != null) {
for (Cell cell : result.listCells()) {
// 将结果存放在map中
String k = Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength());
String v = Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength());
accountRecord.put(k,v);
}
}
}
table.close();
} catch (IOException e) {
e.printStackTrace();
}
// 返回所有行数据
return accountRecord;
}
后话:
在学校时,我参与过 Elasticsearch 相关的项目。在理解 HBase 时,发现 HBase 的设计其实和 Elasticsearch 十分相似,如 HBase 的 Flush&Compact 机制等设计与 Elasticsearch 如出一辙,因此理解起来比较顺利。
从本质上来说,HBase 的定位是分布式存储系统,Elasticsearch 是分布式搜索引擎,两者并不等同,但两者是互补的。HBase 的搜索能力有限,只支持基于 RowKey 的索引,其它二级索引等高级特性需要自己开发。因此,有一些案例是结合 HBase 和 Elasticsearch 实现存储 + 搜索的能力。通过 HBase 弥补 Elasticsearch 存储能力的不足,通过 Elasticsearch 弥补 HBase 搜索能力的不足。
其实,不只是 HBase 和 Elasticsearch。任何一种分布式框架或系统,它们都有一定的共性,不同之处在于各自的关注点不同。我的感受是,在学习分布式中间件时,应先弄清其核心关注点,再对比其它中间件,提取共性和特性,进一步加深理解。
