


人生苦短,我用 Python
前文传送门:
小白学 Python 数据分析(2):Pandas (一)概述
小白学 Python 数据分析(3):Pandas (二)数据结构 Series
小白学 Python 数据分析(4):Pandas (三)数据结构 DataFrame
小白学 Python 数据分析(5):Pandas (四)基础操作(1)查看数据
小白学 Python 数据分析(6):Pandas (五)基础操作(2)数据选择
小白学 Python 数据分析(7):Pandas (六)数据导入
小白学 Python 数据分析(8):Pandas (七)数据预处理
引言
前一篇文章我们介绍了数据预处理中数据有问题的几种情况以及一般处理办法。
很经常,当我们拿到数据的时候,首先需要确定拿到的是正确类型的数据,如果数据类型不正确,一般通过数据类型的转化
数据类型转化
大家应该都知道 Excel 中数据类型比较多,常用的有文本、数字、货币、时间、日期等等,在 Pandas 中,相对而言数据类型就少了很多,常用的有 int64 , float64 , object , datetime64 等等。
还是使用前面的示例,我们先看下当前数据表中的数据类型,这里使用的 dtypes ,示例如下:
import pandas as pd
# 相对路径
df = pd.read_excel("result_data.xlsx")
print(df)
# 输出结果
plantform read_num fans_num rank_num like_num create_date
0 cnblog 215.0 0 118.0 0 2019-11-23 23:00:10
1 cnblog 215.0 0 118.0 0 2019-11-23 23:00:10
2 juejin NaN 0 -2.0 1 2019-11-23 23:00:03
3 csdn 1652.0 69 0.0 24 2019-11-23 23:00:02
4 cnblog 650.0 3 NaN 0 2019-11-22 23:00:15
.. ... ... ... ... ... ...
404 juejin 212.0 0 -1.0 2 2020-02-20 23:00:02
405 csdn 1602.0 1 0.0 1 2020-02-20 23:00:01
406 cnblog 19.0 0 41.0 0 2020-02-21 23:00:05
407 juejin 125.0 1 -4.0 0 2020-02-21 23:00:02
408 csdn 1475.0 8 0.0 3 2020-02-21 23:00:02
print(df.dtypes)
# 输出结果
plantform object
read_num float64
fans_num int64
rank_num float64
like_num int64
create_date datetime64[ns]
dtype: object当然,我们如果想单独知道某一列的数据类型,也可以这么用:
import pandas as pd
# 相对路径
df = pd.read_excel("result_data.xlsx")
print(df['read_num'].dtypes)
# 输出结果
float64当我们需要转换数据类型的时候,可以使用 astype() 这个方法,在使用的时候讲需要转化的目标类型写在 astype() 后面括号里即可:
import pandas as pd
# 相对路径
df = pd.read_excel("result_data.xlsx")
print(df['fans_num'].astype('float64'))
# 输出结果
0 0.0
1 0.0
2 0.0
3 69.0
4 3.0
...
404 0.0
405 1.0
406 0.0
407 1.0
408 8.0
Name: fans_num, Length: 409, dtype: float64添加索引
有些时候,我们拿到的数据表是没有索引的,如果没有索引, Pandas 会默认的为我们添加从 0 开始的自然数作为行索引。而列索引会默认取第一行。比如我们创建了一个没有表头的 Excel ,如下:
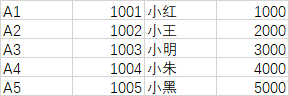
没有表头这样的数据看起来很难懂,我们先导入到 Pandas 中看下效果:
import pandas as pd
df1 = pd.read_excel("demo.xlsx")
print(df1)
# 输出结果
A1 1001 小红 1000
0 A2 1002 小王 2000
1 A3 1003 小明 3000
2 A4 1004 小朱 4000
3 A5 1005 小黑 5000这时,我们想给这个数据表加上列索引,这里可以使用 columns ,如下:
import pandas as pd
df1 = pd.read_excel("demo.xlsx")
df1.columns = ['编号', '序号', '姓名', '消费金额']
print(df1)
# 输出结果
编号 序号 姓名 消费金额
0 A2 1002 小王 2000
1 A3 1003 小明 3000
2 A4 1004 小朱 4000
3 A5 1005 小黑 5000现在我们有了列索引,但是如果这时我并不想用自动生成的自然数作为行索引,想替换成数据表中的序号,可以怎么做呢?
这里需要使用到的是 set_index() 这个方法,在括号中指明需要使用的列名即可:
import pandas as pd
df1 = pd.read_excel("demo.xlsx")
print(df1.set_index('编号'))
# 输出结果
序号 姓名 消费金额
编号
A2 1002 小王 2000
A3 1003 小明 3000
A4 1004 小朱 4000
A5 1005 小黑 5000本篇的内容就到这里结束了,今天的内容有点短,溜了溜了~~
示例代码
老规矩,所有的示例代码都会上传至代码管理仓库 Github 和 Gitee 上,方便大家取用。

