

前言
系列一和大家分享了 Node.js 可写流和可读流的基本使用。系列二将深入讲解在 Node.js 中可读流的流动模式(flowing)与暂停模式(paused)。
其实流动模式和暂停模式,对应的是,推模型与拉模型。
笔者在介绍 Node.js 流的这两种模式之前,这里也想展开聊聊我们已经认识的一些“推拉模型”(或者见过,却没有意识到的)。
“拉”模型的思考(Pull)
“拉”代表消费者主动去向生产者拉取数据。生产者当被请求时被动的产生数据,而消费者主动的决定何时请求数据。
从实际出发,可以从这几个角度理解。我们在开发中如果存在有生产者、消费者两种对象。当观察者主动从生产者中拉取数据的时候,其实就是符合“拉”模型的理念。如下图:
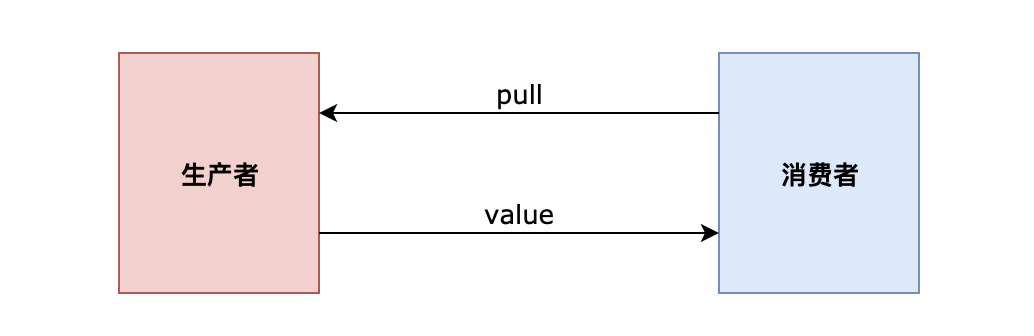
以下,我将列举几种“拉”模型。
Function
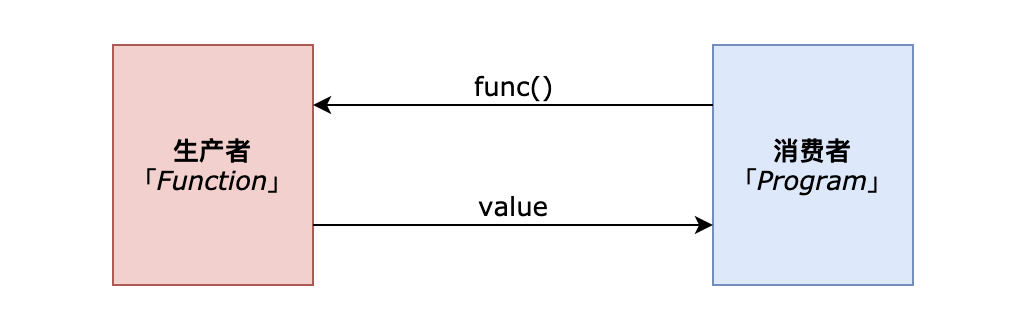
大家很熟悉的函数,当运行一个函数的时候,就是在获取一个值。如果你思维转换一下,就是“拉”模型!是不是很吃惊!比如如下函数:
function createID() {
return Math.random().toString(36).substr(2, 9);;
}
const id = createID(); // adb8d7xjm
此时函数本身相当于生产者,而执行函数的程序就相当于消费者。当程序(即消费者)运行这个函数的时候,即主动去向此函数要一个返回值,函数(生产者)被执行,因此返回了一个 ID 值给它。
补充,“拉”一般也意味着“阻塞”。当然,在单线程 JavaScript 场景下,这个“阻塞”的意思也很好理解。
Generator
在 ES6 中出现的 Generator 生成器也符合“拉”模型。但和 Function 不同的是,Function 只是拉取一个值(因为只有一个 return),而 Generator 是拉取多个值(甚至无限的值)
function* makeRangeIterator(start = 0, end = Infinity, step = 1) {
for (let i = start; i < end; i += step) {
yield i;
}
}
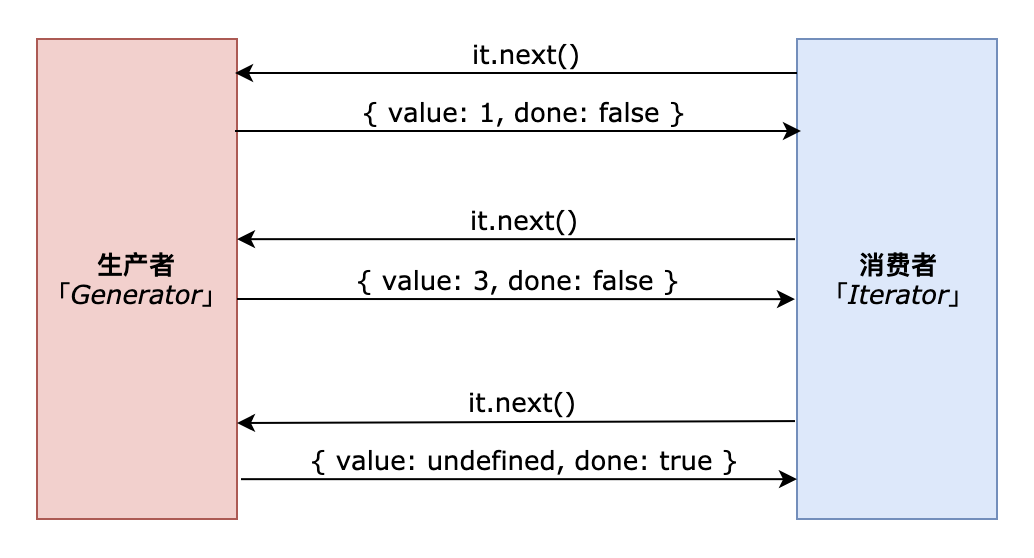
const it = makeRangeIterator(1, 5, 2);
it.next(); // {value: 1, done: false}
it.next(); // {value: 3, done: false}
it.next(); // {value: undefined, done: true}
在上述示例代码中,执行生成器函数后,创建了一个遍历器对象(it 即为消费者),由于生成器对象本身是个状态机,在此场景下,其实为生产者。此时,每调用一个 next() 去拉值后,生成器对象就会返回一个值。如图:
当然 Generator 不仅仅可以“拉”值,也可以“推”值。这也是它之所以如此强大而复杂的地方。为了向大家简单示意“推”值,笔者写了一个略有点智障的生成器函数如下:
function* getCudeSize() {
const width = 5;
const depth = 10;
const height = yield width;
return width * height * depth;
}
const getHeightByWidth = w => w * 1.6;
const it = getCudeSize();
const { value: width } = it.next();
const { value: size } = it.next(getHeightByWidth(width));
示意图如下:

遍历器对象向生成器对象,先拉了“width”值,然后推送了“height”值,最后又拉了“size”值。所以才说 Generator 整体上都符合拉、推的模型。
当然遍历器对象在推“height”值的时候,不得不提,此时彼此的身份发生了互换。
P.S. 对于 Iterator 也是同理,这里略过。
“推”模型的思考(Push)
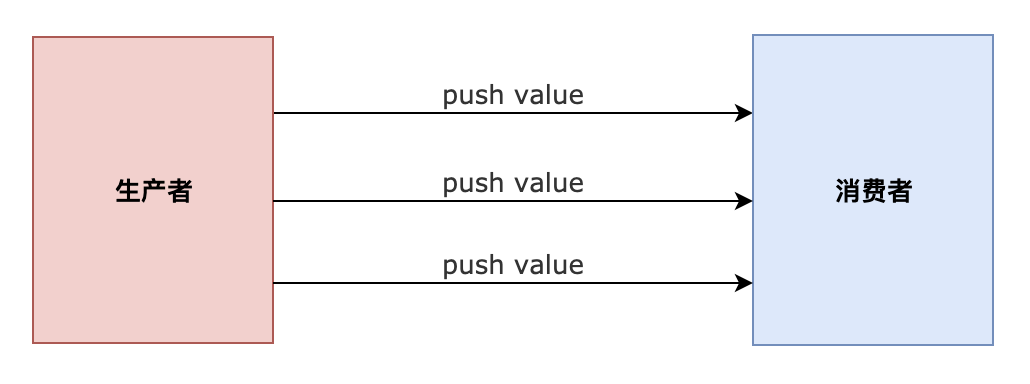
“推”代表生产者主动去产生数据推送给消费者。生产者主动的按自己的节奏产生数据,消费者被动的对收到的数据做出反应。
DOM Events
经典的推模型莫过于 DOM 事件了。DOM 中存在一大堆事件。比如鼠标事件、键盘事件、还有浏览器事件等等。就拿我们最熟悉的 click 事件来看。
document.addEventListener('click', event => {
const { x, y } = event;
console.log('Cursor coordinate: ', x, y);
});
我们注册了一个事件侦听器在 Document 对象的 click 事件上。于是当我们每点击一次 Document 的时候,浏览器就会调用执行我们指定的该事件侦听器,通过 event 参数发给我们事件描述信息。

如图所示。此时我们定义的事件侦听器作为消费者,订阅了生产者的 Document 的 click 事件,每当用户点击 Document 的时候,浏览器作为生产者就会推送事件数据给侦听器。
留意到了么,此时作为事件侦听器,本身是被动的接收数据的。生产者提供什么数据,消费者就消费什么数据。和我们之前提到了“拉”模型,是非常具有对称性的,因为“拉”模型是由消费者主动决定拉取数据的。
同样作为补充,“推”一般也意味着等待。订阅事件但并不会阻塞主线程,而是等待事件发生,触发自动执行对应的回调函数从而消费数据。
EventEmitter
那么 EventEmiter 也是一样,相信大家很了解了。就是经典的发布订阅模式,或也称为观察者模式。笔者认为大致原理和上述 DOM Events,十分类似。因此略过。
Promise
上述的 DOM Events 还是 EventEmitter,可以推送多个值。Promise 首先也符合推模型,但是它只能推送一个值。
Promise.resolve('Hi').then(value => {
console.log(value);
});
只有 Promise 本身决定 resolve 一个值的时候,才会通过 then 推送这个值给到消费者函数。如图:

社区中的 RxJS 库里有大量的相关拉取、推送概念。有兴趣的同学可以自行去了解哦~
其实在我们的日常开发中,还有很多很多符合“推”模型的对象。比如还有 SSE(Server-sent Events)、setInterval、XMLHttpRequest、Service Workers、Websocket 等等。这里我们只挑几个进行介绍。其他的同学们可自行对照理解。
当然,系列二到此为止花了不小的篇幅讲述“推”与“拉”,看似与 Node.js 流毫不相关,所以可能有些同学会有点迷惑。然而我相信是很有帮助的,因为只有理解了这种生产者、消费者机制,才能举一反三更好的理解 Node.js 中流的两种模式,因为笔者认为,二者理念也相差不远,只不过具体表现方式、API 使用方式上存在差异。当然,可能久而久之,你也会发现,这种推拉的思考学习说不定也帮助了理解在 JavaScript 中的异步编程思维。
“拉”模型 - 流的暂停模式(paused)
在暂停模型下的流,符合“拉”模型的大体框架。
所有的可读流都开始于暂停模式, 在暂停模式中,必须显式调用 stream.read() 读取数据。
根据我们上面积累的对“拉”模型的理解,暂停模式下,可读流是生产者,而程序本身是消费者。此时,流当被请求时被动的产生数据,而程序主动的决定何时请求数据。
假设我们读取这个文件(what-is-a-stream.txt),它有 150 个字节。
A stream is an abstract interface for working with streaming data in Node.js. The stream module provides an API for implementing the stream interface.
让我们在流的暂停模式下,读取此文件内容。
const stream = fs.createReadStream(files["what-is-a-stream"], {
highWaterMark: 50
});
stream.on("readable", () => {
console.log('stream is readable!');
let data;
while (null !== (data = stream.read())) {
console.log("Received:", data.toString());
}
});
这里我们使用了 'readable' 事件,当有数据可从流中读取时,就会触发 'readable' 事件。需要注意的是,为了让这个示例更加明显,笔者在 createReadStream 中第二个参数传入了 highWaterMark 选项为 50 用以设置可读缓冲区大小。对于普通的流, highWaterMark 指定了字节的总数。 对于对象模式的流, highWaterMark 指定了对象的总数。因此,在上述示例可读缓冲区为 50 个字节,150 字节大小的文件,会读取三次。
因此,触发了四次 'readable' 事件。(这里比预想中多触发一次,是因为当到达流数据的尽头时, 'readable' 事件也会触发,但是在 'end' 事件之前触发。)
stream is readable!
Received: A stream is an abstract interface for working with
stream is readable!
Received: streaming data in Node.js. The stream module prov
stream is readable!
Received: ides an API for implementing the stream interface.
stream is readable!
将上面的实例代码用图解表达出来,就是如下图这样:
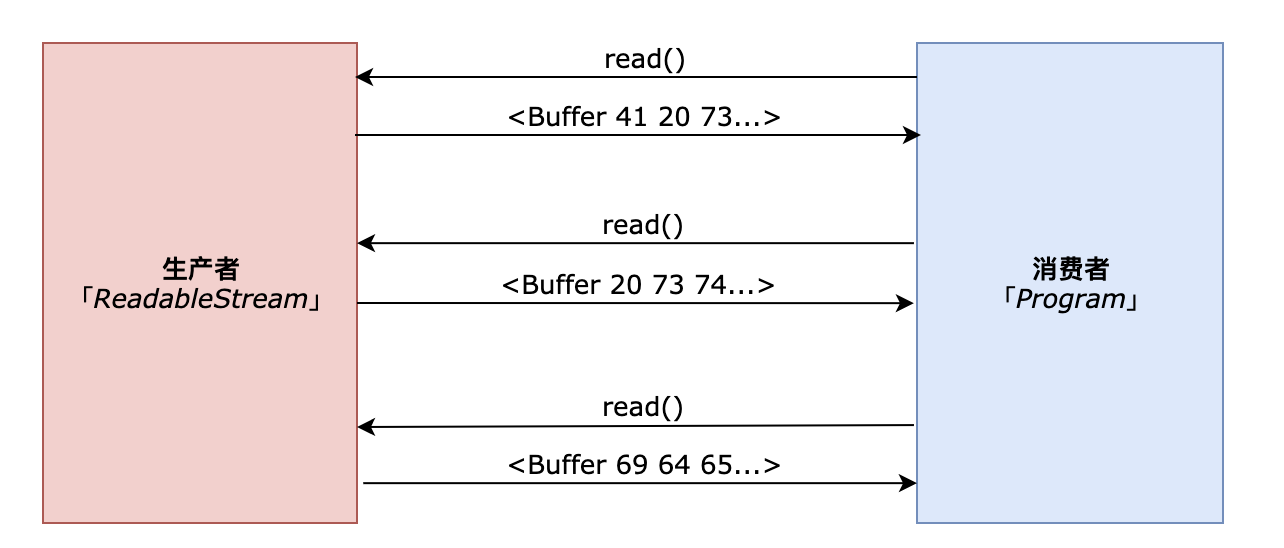
唯一不同的是,我们的程序订阅了生产者“流”的 'readable' 事件,这个相当于流主动推送了“我还有数据可读呀,快来消费我呀”的信号。此时程序就可以决定任意时机去消费流缓存区中数据。
比如说,你也完全可以定时器去读,一样也可以读取出来!(但是千万不要这么做)
setInterval(() => {
let data;
while (null !== (data = stream.read())) {
console.log("Received:", data.toString());
}
}, 30);
“推”模型 - 流的流动模式(flowing)
我们在系列一知道,可读流继承自 EventEmitter。因此在流动模式中,数据自动从底层系统读取,并通过 EventEmitter 接口的事件尽可能快地被提供给应用程序。
只用对流监听 'data' 事件,流就会切到流动模式,源源不断发送数据块给程序。
此时的流作为生产者,拥有了主动推送数据的权力,而我们的程序,或者说是事件监听句柄,就是我们的消费者,它会被动的接收数据。
const stream = fs.createReadStream(files["what-is-a-stream"], {
highWaterMark: 50,
});
stream.on("data", chunk => {
console.log("stream emit data");
console.log("Received:", chunk.toString());
});
因此,同样因为 highWaterMark 的关系,流触发了三次 'data' 事件。
stream emit data
Received: A stream is an abstract interface for working with
stream emit data
Received: streaming data in Node.js. The stream module prov
stream emit data
Received: ides an API for implementing the stream interface.
如果用推模型来描述这个过程,即如图:
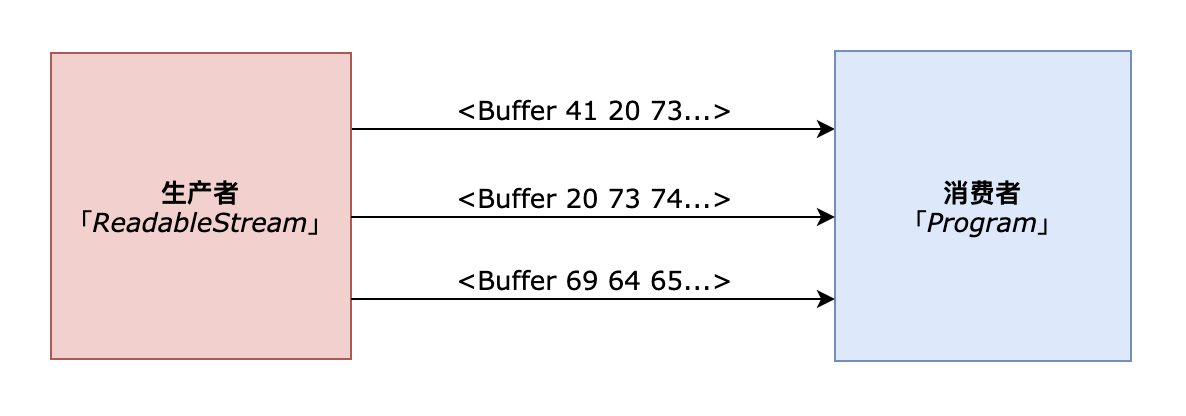
当然,还有一种更好更安全的方式,可以在流动模式下自动管理数据。(为什么说安全是因为可以自动处理目标可写流的超负荷、背压问题。)那就是:readableStream.pipe(writableStream)。
stream.pipe(process.stdout);
这种模式适合处理对流不需要细致控制的场景,简简单单一个 pipe 就可以达成我们的目标,十分简洁。
流模式的切换
可读流的两种模式是对发生在可读流中更加复杂的内部状态管理的一种简化的抽象。
当然,流的这两种模式,我们是可以通过以下几种方式进行切换。换而言之,也就是推和拉两种模型的切换。
从默认的暂停模式切换到流动模式(拉转推):
- 给流监听 'data' 事件:stream.on('data', handler)
- 调用 stream.resume() 方法
- 调用 stream.pipe() 方法将数据发送到可写流
从流动模式,切换回到暂停模式(推转拉):
- 如果没有管道目标,则调用 stream.pause()。
- 如果有管道目标,则移除所有管道目标。调用 stream.unpipe() 可以移除多个管道目标。
这些在官方文档都可以查到。笔者接下来会详细示例几种切换模式,以及其注意事项。
切换流动模式:stream.resume()
readable.resume() 方法将被暂停的可读流恢复触发 'data' 事件,并将流切换到流动模式。
我们知道上述给流监听 'data' 事件,流会切换到流动模式,同时开始触发发射所有数据。同样 resume 方法,也会切换流模式到流动模式,此时若尚未添加 'data' 事件监听,则有可能丢失数据。
考虑如下代码:
// 从默认的暂停模式,切换到流动模式
stream.resume();
// 3ms 后才监听 'data' 事件,在 3ms 期间可能已经丢失数据块
setTimeout(() => {
stream.on("data", chunk => {
console.log("stream emit data");
console.log("Received:", chunk.toString());
});
stream.on("end", () => {
console.log("stream emit end");
});
}, 3);
此时数据块可能会丢失,比如在笔者的电脑上,运行此代码,此时只打印了两个分块。
stream emit data
Received: streaming data in Node.js. The stream module prov
stream emit data
Received: ides an API for implementing the stream interface.
stream emit end
很明显,丢失了第一个分块。因此,此场景需要特别留意!
切换暂停模式:stream.pause()
readable.pause() 方法使流动模式的流停止触发 'data' 事件,并切换出流动模式。 任何可用的数据都会保留在内部缓存中。
比如在 3ms 后调用 pause 暂停这个流,则这里可能后面几个数据块来不及在 3ms 内输出,就会留在内部缓存中。
// 从默认的暂停模式,切换到流动模式
stream.on("data", chunk => {
console.log("Received:", chunk.toString());
});
// 3ms 后将流切换到暂停模式,流暂停触发 'emit' 事件
setTimeout(() => {
stream.pause();
}, 3);
比如我们先在 3ms 后暂停,然后在 2000 ms 后再继续,我们在数据分块之前,打印当前时间秒数。
// 从默认的暂停模式,切换到流动模式
stream.on("data", chunk => {
console.log(`Received at ${(new Date).getSeconds()}s: `, chunk.toString());
});
// 3ms 后将流切换到暂停模式,流暂停触发 'emit' 事件
setTimeout(() => {
stream.pause();
}, 3);
// 2000ms 后将流切换到流动模式,流继续触发 'emit' 事件
setTimeout(() => {
stream.resume();
}, 2000);
控制台打印如下:
Received at 42s: A stream is an abstract interface for working with
Received at 44s: streaming data in Node.js. The stream module prov
Received at 44s: ides an API for implementing the stream interface.
但是需要留意的是,如果流存在 'readable' 事件监听器或调用了 stream.read(),则 readable.pause() 方法不起作用。
切换暂停模式:stream.unpipe()
readable.unpipe() 方法解绑之前使用 stream.pipe() 方法绑定的可写流。
当存在 **readableStream.pipe(writableStream) **模式,即为此可读流有管道目标。
这里同样用例子说明,不过抱歉的是,这里笔者要调整一下 highWaterMark 为更小的值。(因为下述例子中的 pipe 方法会自动管理数据流,原有的可读缓存区较大 50 bytes 3 次读取,读取速度极快,难以在读取完成前 unpipe),改成 20 bytes 后,能读取差不多 6 次,会稍微慢一点。
const stream = fs.createReadStream(files["what-is-a-stream"], {
highWaterMark: 20
});
// 切换到流动模式
stream.pipe(process.stdout);
setTimeout(() => {
// 切换为暂停模式
stream.unpipe();
// 暂停模式下,读取数据
stream.on("readable", () => {
let data;
while (null !== (data = stream.read())) {
console.log("From paused mode:", data.toString());
}
});
}, 3);
运行上述代码,控制台打印如下:
A stream is an abstrFrom paused mode: act interface for wo
From paused mode: rking with streaming
From paused mode: data in Node.js. Th
From paused mode: e stream module prov
From paused mode: ides an API for impl
From paused mode: ementing the stream
From paused mode: interface.
两种模式并没有孰好孰坏,归根结底,它们都有各自的应用场景。但是对于开发者来说,大部分场景下,使用 pipe 就足够了。
可读流的状态
我们可以通过 readable.readableFlowing 来获取当前可读流的状态。在任意时刻可读流会处于以下三种状态之一:
- readable.readableFlowing === null
- readable.readableFlowing === false
- readable.readableFlowing === true
比如我们基于上述的代码打点看 readableFlowing 的状态值。
console.log('\nReadableFlowing [before pipe]:', stream.readableFlowing);
stream.pipe(process.stdout);
console.log('\nReadableFlowing [after pipe]:', stream.readableFlowing);
setTimeout(() => {
stream.unpipe();
console.log('\nReadableFlowing [after unpipe]:', stream.readableFlowing);
stream.on("readable", () => {
let data;
while (null !== (data = stream.read())) {
console.log("From paused mode:", data.toString());
}
});
console.log('\nReadableFlowing [after readable]:', stream.readableFlowing);
}, 3);
控制台打印如下:
ReadableFlowing [before pipe]: null
ReadableFlowing [after pipe]: true
A stream is an abstract interface for wo
ReadableFlowing [after unpipe]: false
ReadableFlowing [after readable]: false
From paused mode: rking with streaming
From paused mode: data in Node.js. Th
From paused mode: e stream module prov
From paused mode: ides an API for impl
From paused mode: ementing the stream
From paused mode: interface.
因此我们得知在没有提供消费流数据的机制,readable.readableFlowing 值为 null。之后 true 和 false 分别代表着是否处于流动模式。
小结
今天的系列二到此收尾了,相信同学们对流的两种模式也有了基本的了解~
前半篇中提到的推拉模型也是一个很有趣的话题,如果有同学很感兴趣,很推荐去看这个视频 Netflix JavaScript Talks - Version 7: The Evolution of JavaScript。推拉模型和流的暂停、流动模式,的确有很相似的设计理念,相信二者之间都肯定可以互相参考借鉴的地方。
所以笔者仍然和系列一的意思是一样的,对于学习任何技术来说,没有必要把自己局限在任何框框条条中,发挥自己的想象力,去实践、去验证,无论如何都会是一个有趣的学习过程。
欢呼~鼓掌~揉揉酸酸的手和眼睛 :)
下个系列见~
