

HiTop
Python爬取微博热榜,知乎,GIthub存入Mysql,Spring boot实现后台接口,Vue实现展示页面
项目地址: Hi热榜源码
访问
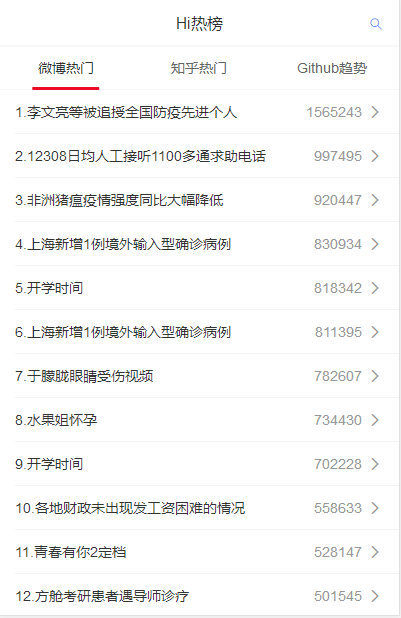
Hi热榜项目,灵感来源:
- 今日热榜tophubs/TopList: 一个获取各大热门网站热门头条的聚合网站,使用Go语言编写,多协程异步快速抓取信息
- 今日热榜LoseNine/TopList-python :今日热榜项目TopList的Python实现,异步爬取微博热榜,知乎,V2EX,GIthub,通过Flask展示。
数据库部署
CREATE TABLE `t_top` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`title` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '标题',
`url` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '跳转url',
`type` tinyint(5) NOT NULL COMMENT '1.微博热门 2.知乎热榜 3.github趋势',
`url_key` varchar(55) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT 'url md5值',
`feature` json DEFAULT NULL COMMENT '其他特殊字段',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `unique_index_key` (`url_key`) USING BTREE COMMENT '唯一索引url md5',
KEY `index_type_create_time` (`type`,`create_time`)
) ENGINE=InnoDB AUTO_INCREMENT=1195 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
爬虫部署
技术栈: python;连个数据库,加上定时器,后期加上知乎日报的爬虫
python实现的定时爬虫
- 编辑
MysqlModels.py修改数据库 - 运行
excute.py启动定时任务
服务端部署
技术栈: spring boot + druid + mybatis-plus + swagger2 + docker ,后期打算加入canal,rocketmq和es,做搜索和缓存,并加入用户系统及推荐系统
- 执行 mvn package docker:build 打包docker镜像
- 执行docker images查看刚刚打包的docker镜像
- 执行docker run --name top -p 8181:8181 -t top启动镜像
前端部署
技术栈: vue + axios + vant
- npm run build打包生成dist文件夹,拷贝到linux服务器
- 配置nginx和域名
server {
listen 80;
listen [::]:80;
server_name top.w77996.cn;
root /var/www/html;
index index.html;
location /api/ {
proxy_pass http://localhost:8181;
proxy_connect_timeout 6000;
proxy_read_timeout 6000;
}
}
