

一、享元模式的应用场景
在我们的日常生活中享元模式很常见,比如各种中介机构的房源共享,再比如全国社保联网。面向对象技术很好的解决一些灵活性或者扩展性问题,但是很多情况下需要在系统内增加对象的个数。当对象太多时,将导致运行代价过高,带来性能下降等问题。享元模式正式为解决这一类问题而诞生的。


享元模式(FlyWeight Pattern)又称为轻量级模式,是对象池的一种实现。类似线程池,线程池可以避免不停的创建和销毁对象,消耗性能。提供了减少对象数量从而改善应用所需的对象结构方式。其宗旨是共享细粒度对象,将多个多同一对象的访问集中起来,不必为每个访问者创建一个单独的对象,以此来降低内存的消耗。
享元模式把一个对象的状态分为内部状态和外部状态,内部状态是不变的,外部状态是变化的。 然后通过共享不变的部分,达到减少对象数量并节约内存的目的。享元模式的本质是缓存共享对象,降低内存消耗。
1.1 享元模式的角色
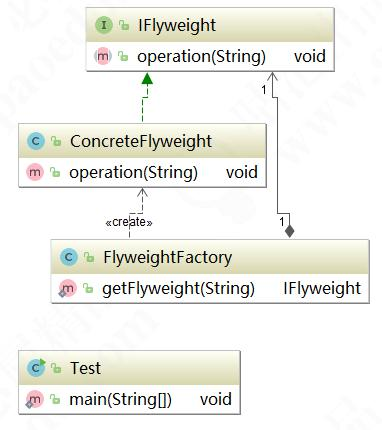
享元模式有三个参与角色:
- 抽象享元角色(Flyweight):享元对象抽象基类或者接口,同时定义出对象的外部状态和内部状态的接口或实现;
- 具体享元角色(ConcreteFlyweight):实现抽象角色定义的业务。该角色的内部状态处理应该与环境无关,不能出现会有一个操作改变内部状态,同时修改了外部状态;
- 享元工厂(FlyweightFactory):负责管理享元对象池和创建享元对象。
享元模式通用的UML图
享元模式有以下两个应用场景:
- 常常应用于系统底层的开发,以便解决系统的性能问题;
- 系统有大量的相似对象、需要缓冲池的场景。
1.2 刷火车票软件的享元模式应用
我们每年春节为了抢到一张回家的火车票都要大费周折,进而出现了很多刷票 软件,刷票软件会将我们填写的信息缓存起来,然后定时检查余票信息。抢票的时候,我们肯定是要查询下有没有我们需要的票信息,这里我们假设一张火车的信息包含:出发站,目的站,价格,座位类别。现在要求编写一个查询火车票查询伪代码,可以通过出发站,目的站查到相关票的信息。

比如要求通过出发站,目的站查询火车票的相关信息,只需要构建火车票对象,然后提供一个查询出发站、目的站的接口给客户进行查询即可,首先创建一个ITicket接口:
public interface ITicket {
void showInfo(String bunk);
}
然后创建TrainTicket 类:
public class TrainTicket implements ITicket {
private String from;
private String to;
private double price;
public TrainTicket(String from, String to) {
this.from = from;
this.to = to;
}
@Override
public void showInfo(String bunk) {
this.price = new Random().nextDouble();
System.out.println(String.format("%s->%s:%s 价格:%s 元", this.from, this.to, bunk, this.price));
}
}
最后创建TicketFactory 类:
public class TicketFacotry {
public static ITicket queryTicket(String from, String to) {
return new TrainTicket(from, to);
}
}
测试main方法:
public static void main(String[] args) {
ITicket ticket = TicketFacotry.queryTicket("北京西", "武汉");
ticket.showInfo("二等座");
}
分析上面的代码,我们发现客户端进行查询时,系统通过TicketFactory直接创建一个火车票对象,但是这样做的话,当某个瞬间如果有大量的用户请求同一张票的信息时,系统就会创建出大量该火车票对象,系统内存压力骤增。而其实更好的做法应该是缓存该票对象,然后复用提供给其他查询请求,这样一个对象就足以支撑数以千计的查询请求,对内存完全无压力,使用享元模式可以很好地解决这个问题。我们继续优化代码,只需在 TicketFactory 类中进行更改,增加缓存机制:
public class TicketFacotry {
private static Map<String, ITicket> ticketTool = new ConcurrentHashMap();
public static ITicket queryTicket(String from, String to) {
String key = from + "->" + to;
if(ticketTool.containsKey(key)) {
System.out.println("使用缓存" + key);
return ticketTool.get(key);
}
System.out.println("首次查询,创建对象: " + key);
ITicket ticket = new TrainTicket(from, to);
ticketTool.put(key, ticket);
return ticket;
}
}
修改main测试方法:
public static void main(String[] args) {
ITicket ticket = TicketFacotry.queryTicket("北京西", "武汉");
ticket.showInfo("二等座");
ITicket ticket1 = TicketFacotry.queryTicket("北京西", "武汉");
ticket1.showInfo("一等座");
}
运行效果:

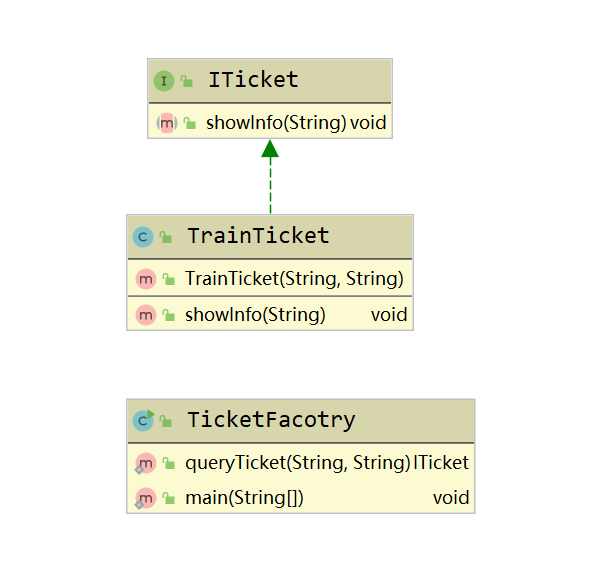
其中 ITicket 就是抽象享元角色,TrainTicket 就是具体享元角色,TicketFactory 就是享元工厂。有些小伙伴一定会有疑惑了,这不就是注册式单例模式吗?对,这就是注册式单例模式。虽然,结构上很像,但是享元模式的重点在结构上,而不是在创建对象上。
1.3 数据库连接池Connection对象
我们经常使用的数据库连接池,因为我们使用Connection对象时主要性能消耗在建立连接和关闭连接的时候,为了提高 Connection 在调用时的性能,我们和将 Connection 对象在调用前创建好缓存起来,用的时候从缓存中取值,用完再放回去,达到资源重复利用的目的。来看下面的代码:
public class ConnectionPool {
private Vector<Connection> pool;
private String url = "jdbc:mysql://localhost:3306/testDB";
private String username = "root";
private String password = "123456";
private String driverClassName = "com.mysql.jdbc.Driver";
private int poolSize = 100;
public ConnectionPool() {
pool = new Vector<Connection>(poolSize);
try{
Class.forName(driverClassName);
for (int i = 0; i < poolSize; i++) {
Connection conn = DriverManager.getConnection(url,username,password);
pool.add(conn);
}
}catch (Exception e){
e.printStackTrace();
}
}
public synchronized Connection getConnection(){
if(pool.size() > 0){
Connection conn = pool.get(0);
pool.remove(conn);
return conn;
}
return null;
}
public synchronized void release(Connection conn){
pool.add(conn);
}
}
这样的连接池,普遍应用于开源框架,有效提升底层的运行性能。
二、享元模式在源码中的体现
2.1 String中的享元模式
Java 中将 String 类定义为final(不可改变的),JVM中字符串一般保存在字符串常量池中,java会确保一个字符串在常量池中只有一个拷贝,这个字符串常量池在 JDK6.0 以前是位于常量池中,位于永久代,而在JDK7.0中,JVM将其从永久代拿出来放置于堆中。
关于String 的测试类:
public class StringTest {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "hello";
String s3 = "hell" + "o";
String s4 = "hello" + new String("o");
String s5 = new String("hello");
String s6 = s5.intern();
String s7 = "hell";
String s8 = "o";
String s9 = s7 + s8;
System.out.println(s1 == s2);//true
System.out.println(s1 == s3);//ture
System.out.println(s1 == s4);//false
System.out.println(s4 == s5);//false
System.out.println(s1 == s6);//true
System.out.println(s1 == s9);//false
}
}
String类是用final修饰的,以字面量的形式创建String变量时,JVM会在编译的时候把该字面的“hello”放到字符串常量池中,Java程序启动的时候就已经加载到内存里面了。这个字符串常量池的特点就是有且仅有一份相同的字面量,如果有其它相同的字面量,JVM则返回这个字面量的引用,如果没有相同的字面量,则在字符串常量池中创建字面量并返回它的引用。
- s2 指向的字面量"hello"在常量池中已经存在了(s1 先于 s2),于是 JVM 就返回这个字面量绑定的引用,所以 s1==s2。
- s3 中字面量的拼接其实就是"hello",JVM 在编译期间就已经对它进行优化,所以 s1 和 s3 也是相等的。
- s4 中的 new String("o")生成了两个对象,lo,new String("o"),o 存在字符串常量池,new String("o")存在堆中,String s4 = "hell" + new String("o")实质上是两个对象的相加,编译器不会进行优化,相加的结果存在堆中,而 s1 存在字符串常量池中,当然不相等。s1==s9 的原理一样。
- s4==s5 两个相加的结果都在堆中,不用说,肯定不相等。
- s1==s6 中,s5.intern()方法能使一个位于堆中的字符串在运行期间动态地加入到字符串常量池中(字符串常量池的内容是程序启动的时候就已经加载好了),如果字符串常量池中有该对象对应的字面量,则返回该字面量在字符串常量池中的引用,否则,创建复制一份该字面量到字符串常量池并返回它的引用。因此 s1==s6 输出 true。
2.2 Integer的享元模式
再举例一个大家都非常熟悉的对象Integer,也用到了享元模式,其中暗藏玄机,我们来看个例子:
public class IntegerTest {
public static void main(String[] args) {
Integer a = 100;
Integer b = Integer.valueOf(100);
Integer c = 1000;
Integer d = Integer.valueOf(1000);
System.out.println(a == b);
System.out.println(c == d);
}
}
我们跑完程序之后才发现总有些不对,得到了一个意向不到的结果,其运行结果如下:

之所以得到这样的结果,是因为 Integer 用到的享元模式,我们来看 Integer 的源码:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
我们发现 Integer 源码中的 valueOf()方法做了一个条件判断,如果目标值在-128 到 127 之间,则直接从缓存中取值,否则新建对象。那JDK为何要这样做呢?因为在-128 到 127 之间的数据在int范围内是使用最频繁的,为了节省频繁创建对象带来的内存消耗,这里就用到了享元模式,来提高性能。
2.3 Long的享元模式
public final class Long extends Number implements Comparable<Long> {
public static Long valueOf(long var0) {
return var0 >= -128L && var0 <= 127L ? Long.LongCache.cache[(int)var0 + 128] : new Long(var0);
}
private static class LongCache {
private LongCache(){}
static final Long cache[] = new Long[-(-128) + 127 + 1];
static {
for(int i = 0; i < cache.length; i++)
cache[i] = new Long(i - 128);
}
}
//...
}
同理,Long 中也有缓存,不过不能指定缓存最大值。
2.4 Apache Commons Pool2 中的享元模式
对象池化的基本思路:将用过的对象保存起来,等下次需要再次使用这种对象的时候,再拿出来重复使用,从一定程度上减少频繁创建对象所造成的开销。用于充当保存对象的“容器”的对象,被称之为对象池。(Object Pool,或简称Pool)。
- Apache Commons Pool
实现了对象池的功能。定义了对象的生成、销毁、激活、钝化等操作及其状态转换,并提供几个默认的对象池实现。有几个重要的对象:
- PooledObject(池对象)
用于封装对象(如:线程、数据库连接、TCP连接),将其包裹成可被池管理的对象。
-
PooledObjectFactory(池对象工厂): 定义了操作 PooledObject实例生命周期的一些方法,PooledObjectFactory必须实现线程安全。
-
ObjectPool (对象池)
ObjectPool 负责管理 PooledObject,如:借出对象,返回对象,校验对象,有多少激活对象,有多少空闲对象。
private final Map<IdentityWrapper<T>, PooledObject<T>> allObjects;
这里我们就不分析其具体源码了。
三、享元模式的内部状态和外部状态
享元模式的定义为我们提出了两个要求:细粒度和共享对象。因为要求细粒度对象,所以不可避免地会使对象数量多且性质相近,此时我们就将这些对象的信息分为两个部分:内部状态和外部状态。
内部状态指对象共享出来的信息,存储在享元对象内部并且不会随环境的改变而改变;外部状态指对象得以依赖的一个标记,是随环境改变而改变的、不可共享的状态。
比如,连接池中的连接对象,保存在连接对象中的用户名、密码、连接 url 等信息,在创建对象的时候就设置好了,不会随环境的改变而改变,这些为内部状态。而每个连接要回收利用时,我们需要给它标记为可用状态,这些为外部状态。
四、享元模式的优缺点
优点:
- 减少对象的创建,降低内存中对象的数量,降低系统的内存,提高效率;
- 减少内存之外的其他资源占用。
缺点:
- 关注内、外部状态、关注线程安全问题;
- 使系统、程序的逻辑复杂化。
