

前言
文本已收录至我的GitHub仓库,欢迎Star:github.com/bin39232820…
种一棵树最好的时间是十年前,其次是现在
我知道很多人不玩qq了,但是怀旧一下,欢迎加入六脉神剑Java菜鸟学习群,群聊号码:549684836 鼓励大家在技术的路上写博客
絮叨
其实前面我去年11月份,把Redis的很多基础知识写了一遍,虽然说没有啥深度,但是入门总是可以的,最近我去面试,竟然被问到了,还是自己平时没有用心准备,痛定思痛,我就得把Redis 分布式锁弄清楚点。所以有了今天的文章
🔥从零开始学Redis之金刚凡境
🔥从零开始学Redis之自在地境
🔥从零开始学Redis之逍遥天境
🔥从零开始学Redis之半步神游
🔥从零开始学Redis之神游玄境
引题
一般面试的时候,问完一些Redis的问题之后,有时候可能会问你分布式锁是怎么实现的,然后大家可能就搭用它的 set NX EX命令 然后用lua脚本做成一个原子性操作来实现分布式锁。其实这么搭也可以吧,然后我们一般在生产环境的话,可能会用一些开源框架,你不如说Redisson来实现分布式锁,那可能就会问到你Redisson是怎么实现的
我们先来看看下面几个简单的代码
RLock lock = redisson.getLock(LOCKER_PREFIX + resourceName);
success = lock.tryLock(100, lockTime, TimeUnit.SECONDS);
lock.unlock();
以上简单的代码就能实现分布式锁 是不是很简单,并且还支持分布式 主从 哨兵等模式
源码解析
通过 getLock 方法获取锁对象
@Override
public RLock getLock(String name) {
/**
* 构造并返回一个 RedissonLock 对象
* commandExecutor: 与 Redis 节点通信并发送指令的真正实现。需要说明一下,CommandExecutor 实现是通过 eval 命令来执行 Lua 脚本
* name: 锁的全局名称
* id: Redisson 客户端唯一标识,实际上就是一个 UUID.randomUUID()
*/
return new RedissonLock(connectionManager.getCommandExecutor(), name);
}
通过tryLock方法尝试获取锁
@Override
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {
//取得最大等待时间
long time = unit.toMillis(waitTime);
//记录下当前时间
long current = System.currentTimeMillis();
//取得当前线程id(判断是否可重入锁的关键)
final long threadId = Thread.currentThread().getId();
//1.尝试申请锁,返回还剩余的锁过期时间
Long ttl = tryAcquire(leaseTime, unit, threadId);
// lock acquired
//2.如果返回的锁的过期时间为空,表示申请锁成功
if (ttl == null) {
return true;
}
//3.申请锁的耗时如果大于等于最大等待时间,则申请锁失败
time -= (System.currentTimeMillis() - current);
if (time <= 0) {
acquireFailed(threadId);
return false;
}
//订阅锁释放事件,并通过await方法阻塞等待锁释放,有效的解决了无效的锁申请浪费资源的
//问题:基于信息量,当锁被其它资源占用时,当前线程通过 Redis 的 channel
//订阅锁的释放事件,一旦锁释放会发消息通知待等待的线程进行竞争
current = System.currentTimeMillis();
final RFuture<RedissonLockEntry> subscribeFuture = subscribe(threadId);
//await 方法内部是用CountDownLatch来实现阻塞,
if (!await(subscribeFuture, time, TimeUnit.MILLISECONDS)) {
if (!subscribeFuture.cancel(false)) {
subscribeFuture.addListener(new FutureListener<RedissonLockEntry>() {
@Override
public void operationComplete(Future<RedissonLockEntry> future) throws Exception {
if (subscribeFuture.isSuccess()) {
unsubscribe(subscribeFuture, threadId);
}
}
});
}
acquireFailed(threadId);
return false;
}
try {
//计算获取锁的总耗时,如果大于等于最大等待时间,则获取锁失败
time -= (System.currentTimeMillis() - current);
if (time <= 0) {
acquireFailed(threadId);
return false;
}
//收到锁释放的信号后,在最大等待时间之内,循环一次接着一次的尝试获取锁
//获取锁成功,则立马返回true
//若在最大等待时间之内还没获取到锁,则认为获取锁失败,返回false结束循环
while (true) {
long currentTime = System.currentTimeMillis();
// 再次尝试申请锁
ttl = tryAcquire(leaseTime, unit, threadId);
// lock acquired
// 成功获取锁则直接返回true结束循环
if (ttl == null) {
return true;
}
//超过最大等待时间则返回false结束循环,获取锁失败
time -= (System.currentTimeMillis() - currentTime);
if (time <= 0) {
acquireFailed(threadId);
return false;
}
// waiting for message
currentTime = System.currentTimeMillis();
if (ttl >= 0 && ttl < time) {
//如果剩余时间(ttl)小于wait time ,就时间内,
//从Entry的信号量获取一个许可(除非被中断或用的许可)。
getEntry(threadId).getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
} else {
//则就在wait time 时间范围内等待可以通过信号量
getEntry(threadId).getLatch().tryAcquire(time, TimeUnit.MILLISECONDS);
}
//7.更新剩余的等待时间(最大等待时间-已经消耗的阻塞时间)
time -= (System.currentTimeMillis() - currentTime);
if (time <= 0) {
acquireFailed(threadId);
return false;
}
}
} finally {
//7.无论是否获得锁,都要取消订阅解锁消息
unsubscribe(subscribeFuture, threadId);
}
// return get(tryLockAsync(waitTime, leaseTime, unit));
}
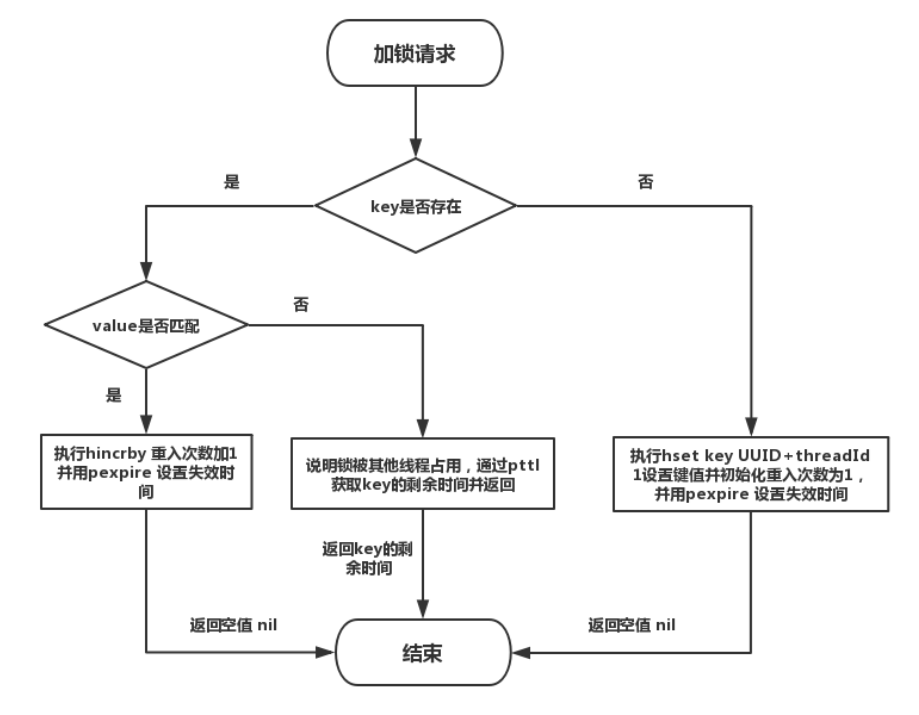
加锁的流程图
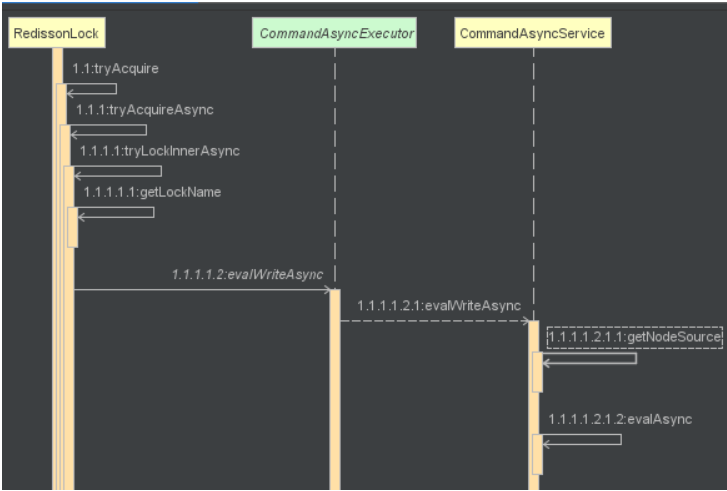
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
// * 通过 EVAL 命令执行 Lua 脚本获取锁,保证了原子性
internalLockLeaseTime = unit.toMillis(leaseTime);
// 1.如果缓存中的key不存在,则执行 hset 命令(hset key UUID+threadId 1),然后通过 pexpire 命令设置锁的过期时间(即锁的租约时间)
/ 返回空值 nil ,表示获取锁成功
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
// 如果key已经存在,并且value也匹配,表示是当前线程持有的锁,则执行 hincrby 命令,重入次数加1,并且设置失效时间
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
//如果key已经存在,但是value不匹配,说明锁已经被其他线程持有,通过 pttl 命令获取锁的剩余存活时间并返回,至此获取锁失败
"return redis.call('pttl', KEYS[1]);",
//这三个参数分别对应KEYS[1],ARGV[1]和ARGV[2]
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
}
LUA脚本
- KEYS[1]就是Collections.singletonList(getName()),表示分布式锁的key;
- ARGV[1]就是internalLockLeaseTime,即锁的租约时间(持有锁的有效时间),默认30s;
- ARGV[2]就是getLockName(threadId),是获取锁时set的唯一值 value,即UUID+threadId-
总结一下加锁的流程
- 第一步先尝试去加锁,返回过期时间,如果为空则可以获得锁 (返回获取锁成功)(,在lua脚本里面会判断你的key和value是不是已经持有锁了,如果是,就是给你重试次数加,然后获取锁也是失败)
- 如果第一次加锁失败之后,就会去判断你最大等待时间,如果走到这的时候已经超过最大等待时间(直接返回获取锁失败,)
- 接下来就是说我要去订阅redis解锁这个事件,一旦有人把锁释放就会继续通知所有的线程去竞争锁
- 然后是一个死循环的去获取锁,当时每次执行这个循环的时候,每次去获取锁之前都要去判断当前是否已经超过最大的等待时间,如果超过了就直接释放锁。只有当获得锁,或者是最大的等待时间超过之后才会返回是否成功获取锁的标志。
- 通过 Redisson 实现分布式可重入锁,比纯自己通过set key value px milliseconds nx +lua 实现(实现一)的效果更好些,虽然基本原理都一样,因为通过分析源码可知,RedissonLock 是可重入的,并且考虑了失败重试,可以设置锁的最大等待时间, 在实现上也做了一些优化,减少了无效的锁申请,提升了资源的利用率。
一个简单的小案例 业务代码
@Autowired
private RedissonClient redissonClient;
//商品秒杀核心业务逻辑的处理-redisson的分布式锁
@Override
public Boolean killItemV4(Integer killId, Integer userId) throws Exception {
Boolean result=false;
final String lockKey=new StringBuffer().append(killId).append(userId).append("-RedissonLock").toString();
RLock lock=redissonClient.getLock(lockKey);
try {
//TODO:第一个参数30s=表示尝试获取分布式锁,并且最大的等待获取锁的时间为30s
//TODO:第二个参数10s=表示上锁之后,10s内操作完毕将自动释放锁
Boolean cacheRes=lock.tryLock(30,10,TimeUnit.SECONDS);
if (cacheRes){
//TODO:核心业务逻辑的处理
if (itemKillSuccessMapper.countByKillUserId(killId,userId) <= 0){
ItemKill itemKill=itemKillMapper.selectByIdV2(killId);
if (itemKill!=null && 1==itemKill.getCanKill() && itemKill.getTotal()>0){
int res=itemKillMapper.updateKillItemV2(killId);
if (res>0){
commonRecordKillSuccessInfo(itemKill,userId); result=true;
}
}
}else{
throw new Exception("redisson-您已经抢购过该商品了!");
}
}
}finally {
//TODO:释放锁
lock.unlock();
}
return result;
}
redis的zSet
工作中其实也有用到这个数据结构,如果说用它来做一些用户排名统计啥的,但是呢,当面试官问到跳表的时候,我竟然没听过,这不得好好补补
底层数据结构
有序集合对象的编码可以是ziplist或者skiplist。同时满足以下条件时使用ziplist编码:
元素数量小于128个 所有member的长度都小于64字节 以上两个条件的上限值可通过zset-max-ziplist-entries和zset-max-ziplist-value来修改。
ziplist编码的有序集合使用紧挨在一起的压缩列表节点来保存,第一个节点保存member,第二个保存score。ziplist内的集合元素按score从小到大排序,score较小的排在表头位置。
skiplist编码的有序集合底层是一个命名为zset的结构体,而一个zset结构同时包含一个字典和一个跳跃表。跳跃表按score从小到大保存所有集合元素。而字典则保存着从member到score的映射,这样就可以用O(1)的复杂度来查找member对应的score值。虽然同时使用两种结构,但它们会通过指针来共享相同元素的member和score,因此不会浪费额外的内存。
skiplist介绍
跳表(skip List)是一种随机化的数据结构,基于并联的链表,实现简单,插入、删除、查找的复杂度均为O(logN)。简单说来跳表也是链表的一种,只不过它在链表的基础上增加了跳跃功能,正是这个跳跃的功能,使得在查找元素时,跳表能够提供O(logN)的时间复杂度。
先来看一个有序链表,如下图(最左侧的灰色节点表示一个空的头结点):

在这样一个链表中,如果我们要查找某个数据,那么需要从头开始逐个进行比较,直到找到包含数据的那个节点,或者找到第一个比给定数据大的节点为止(没找到)。也就是说,时间复杂度为O(n)。同样,当我们要插入新数据的时候,也要经历同样的查找过程,从而确定插入位置。
假如我们每相邻两个节点增加一个指针,让指针指向下下个节点,如下图:

这样所有新增加的指针连成了一个新的链表,但它包含的节点个数只有原来的一半(上图中是7, 19, 26)。现在当我们想查找数据的时候,可以先沿着这个新链表进行查找。当碰到比待查数据大的节点时,再回到原来的链表中进行查找。比如,我们想查找23,查找的路径是沿着下图中标红的指针所指向的方向进行的:

- 23首先和7比较,再和19比较,比它们都大,继续向后比较。
- 但23和26比较的时候,比26要小,因此回到下面的链表(原链表),与22比较。 23比22要大,沿下面的指针继续向后和26比较。23比26小,说明待查数据23在原链表中不存在,而且它-的插入位置应该在22和26之间。
在这个查找过程中,由于新增加的指针,我们不再需要与链表中每个节点逐个进行比较了。需要比较的节点数大概只有原来的一半。
利用同样的方式,我们可以在上层新产生的链表上,继续为每相邻的两个节点增加一个指针,从而产生第三层链表。如下图:

在这个新的三层链表结构上,如果我们还是查找23,那么沿着最上层链表首先要比较的是19,发现23比19大,接下来我们就知道只需要到19的后面去继续查找,从而一下子跳过了19前面的所有节点。可以想象,当链表足够长的时候,这种多层链表的查找方式能让我们跳过很多下层节点,大大加快查找的速度。
skiplist正是受这种多层链表的想法的启发而设计出来的。实际上,按照上面生成链表的方式,上面每一层链表的节点个数,是下面一层的节点个数的一半,这样查找过程就非常类似于一个二分查找,使得查找的时间复杂度可以降低到O(log n)。但是,这种方法在插入数据的时候有很大的问题。新插入一个节点之后,就会打乱上下相邻两层链表上节点个数严格的2:1的对应关系。如果要维持这种对应关系,就必须把新插入的节点后面的所有节点(也包括新插入的节点)重新进行调整,这会让时间复杂度重新蜕化成O(n)。删除数据也有同样的问题。
结尾
算是对redis知识的小小补充吧。
日常求赞
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是真粉。
创作不易,各位的支持和认可,就是我创作的最大动力,我们下篇文章见
六脉神剑 | 文 【原创】如果本篇博客有任何错误,请批评指教,不胜感激 !
