

01 深层网络诊断越深越好吗?
深度学习的概念源于人工神经网络,而之所以叫深度学习。我认为有 2 点,第一是网络很深,非常深,第二是学习,如何学习呢?通过数学建模,不断调整参数达到减少目标值和预测值之间的误差,从而可以拟合任意的曲线,达到准确预测的目的。
而今天我们就来谈谈深度学习的一个特点:深。
深层网络一般会比浅层网络效果好,包含的信息更多,因此,如果我们想要提升模型准确率,最直接的方法就是把网络设计的更深,这样模型的准确率会越来越准确。
但是,现实场景真是这样吗?我们先来看一组数据,下表是经典的图像识别深度学习模型。
| CV 模型 | 发布时间 | 层数 | 成就 |
|---|---|---|---|
| LeNet | 1998 | 5 | 经典手写数字识别模型 |
| AlexNet | 2012 | 8 | ILSVRC 2012 第一名 |
| VGG | 2014 | 19 | ILSVRC 2014 第二名 |
| GoogleNet | 2014 | 22 | ILSVRC 2014 第一名 |
这几个模型都是世界顶级比赛中获奖的著名模型,然而,这些模型的网络层数,少则 5 层,多也就 22 层。这些世界顶级比赛中的模型并非我们想象中的那么深,多则成百上千层。为什么会出现这种问题?
带着这个问题,我们先看一个实验,对于常规网络,直接堆叠很多层,经过图像识别检测,训练集,测试集和误差结果表现如图:
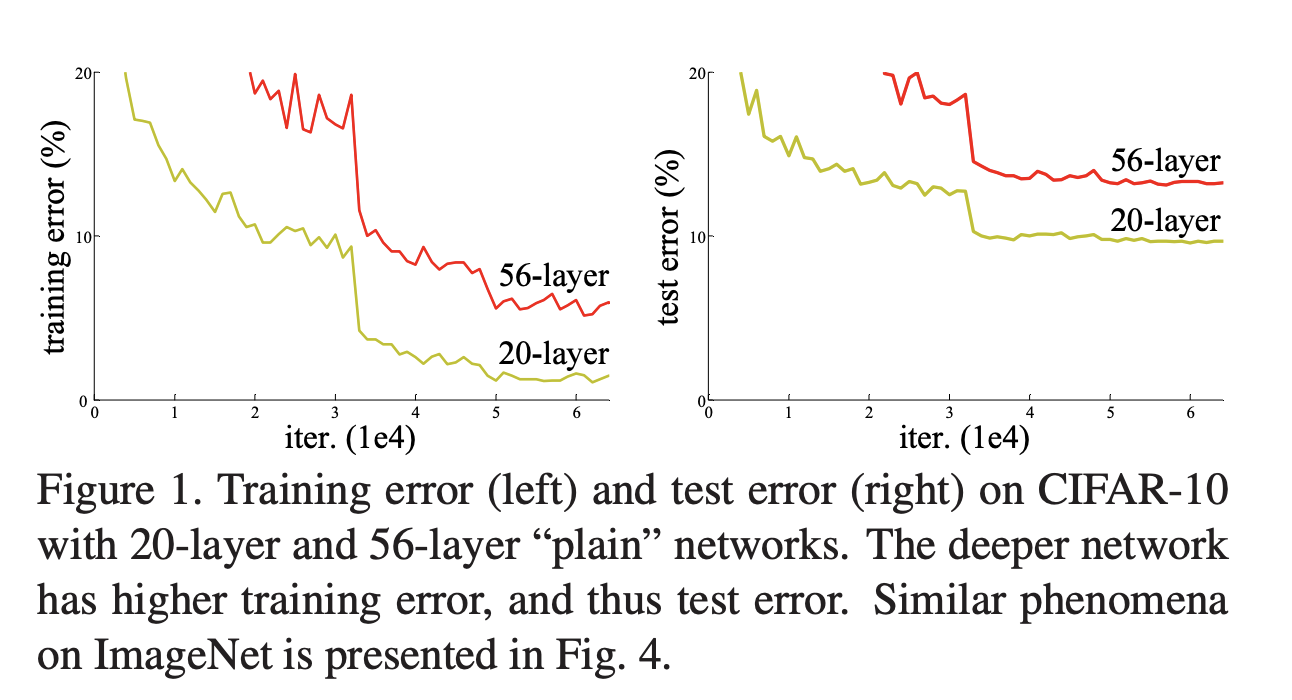
上图中,56 层 和 20 层相比,模型越深,训练集和测试集上误差越大,这也并不是过拟合,过拟合是训练集表现优秀,测试集表现一般。实验表明:随着网络层数增加,模型准确率会得到一定的提升,当网络层数增加到一定数量后,训练和测试误差会准会先饱和,之后急剧下降。
在深层网络训练中,我们都知道,随着层数增加,训练和优化会变得越来越难,一个很大的原因就是梯度消失和爆炸问题,也就是退化问题。
02 网络训练失败的罪魁祸首是退化问题
退化问题: 随着网络层数增加,错误率反而提高了。主要是因为当网络深度很深的时候,会出现梯度消失等问题。
假设你有这样一个神经网络,第一层是输入层,包含 2 个神经元 i1, i2,和截距项 b1;第二层是隐藏层,包含 2 个神经元 h1,h2 和截距项 b2,每条线上标的 wi 是层与层关系连接的权重,激活函数我们默认为 sigmoid 函数。
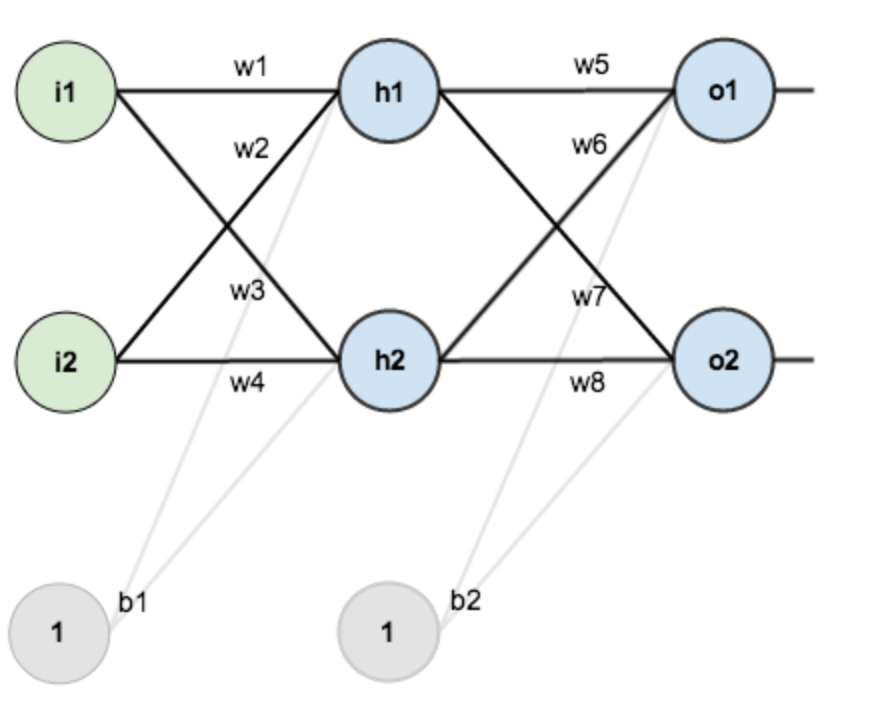
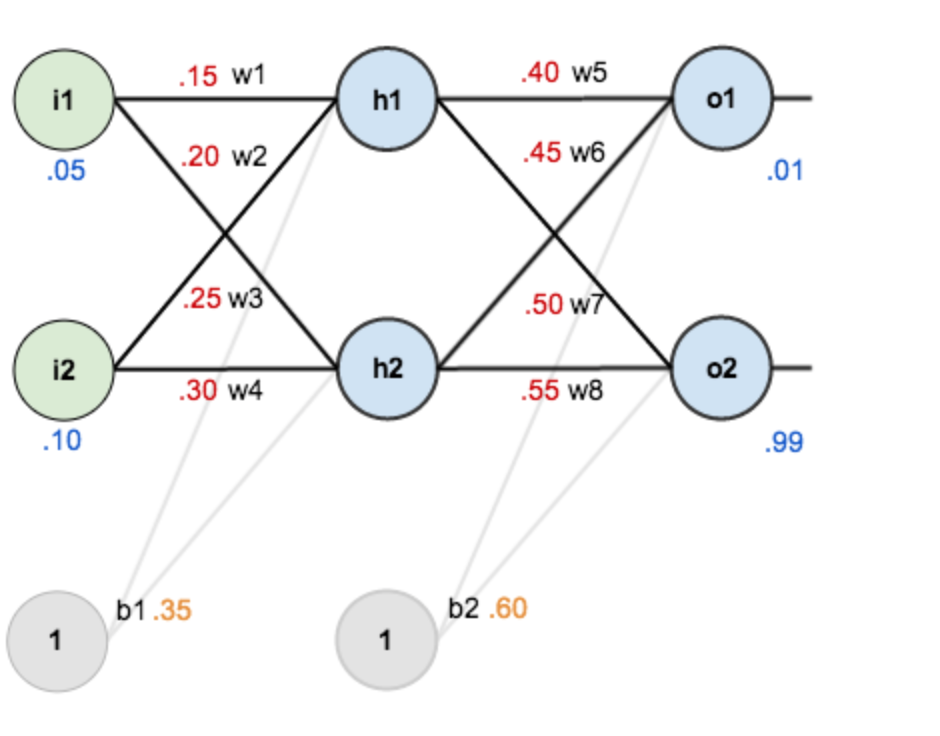
现对他们赋初始值。
-
输入数据:i1=0.05, i2=0.10
-
输出数据:o1=0.01, o2=0.99
-
初始权重:w1=0.15, w2=0.20, w3=0.25, w4=0.30;w5=0.40, w6=0.45, w7=0.50, w8=0.55
-
目标:给出输入数据,使得输出尽可能和原始输出接近。
回想一下神经网络的反向传播,先通过正向传播计算出结果,然后与样本比较得出误差值 Etotal。
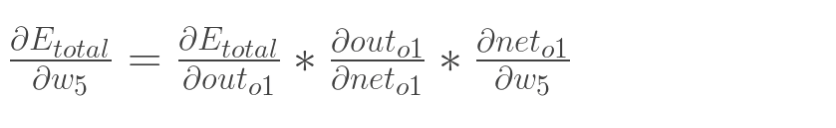
根据误差结果,利用链式法则求偏导,使得结果误差反向传播从而得出权重 w 调整梯度。下图是输出结果到隐含层的反向传播过程。
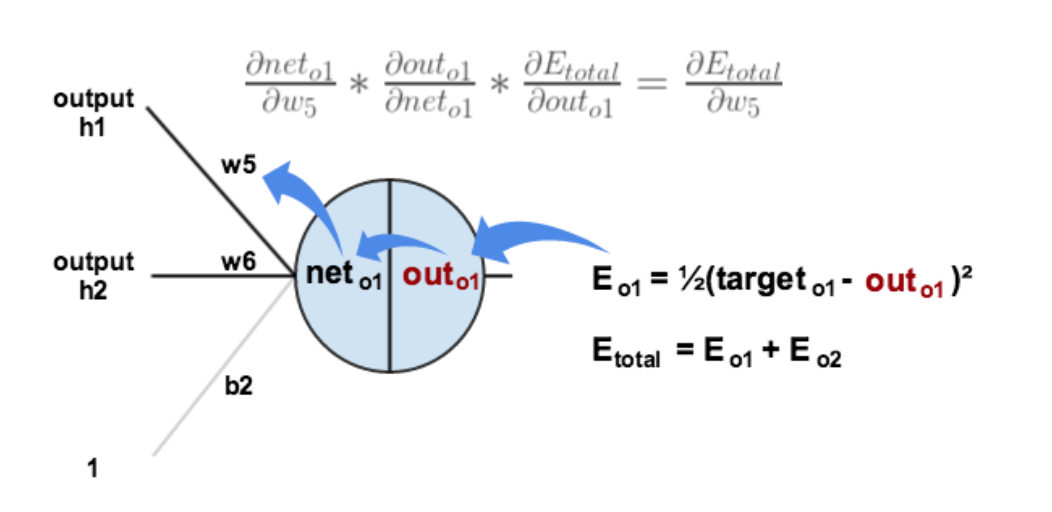
通过不断迭代,对参数矩阵进行不断调整,使得输出的误差值更小,使得输出结果与实际结果更接近。
从上面的过程可以看出,神经网络在反向传播过程中要不断传播梯度,而当层数加深,梯度在传播过程中逐渐消失,导致无法对前面网络的权重进行有效调整。
如何既能加深网络层数,又能解决梯度消失问题,从而提升模型精度呢?
03 ResNet 建立高速网络,输入与输出恒等映射
在 MobileNet V2 的论文中提到,由于非线性激活函数 Relu 的存在,每次输入到输出的过程几乎是不可逆的,这也造成很多不可逆的信息损失,那我们可以试想一下,一个特质的一些有用信息损失了,那他的表现还能持平吗?答案是显然的。
我们用一个直观的例子来感受一下深层网络与浅层网络持平的表现:
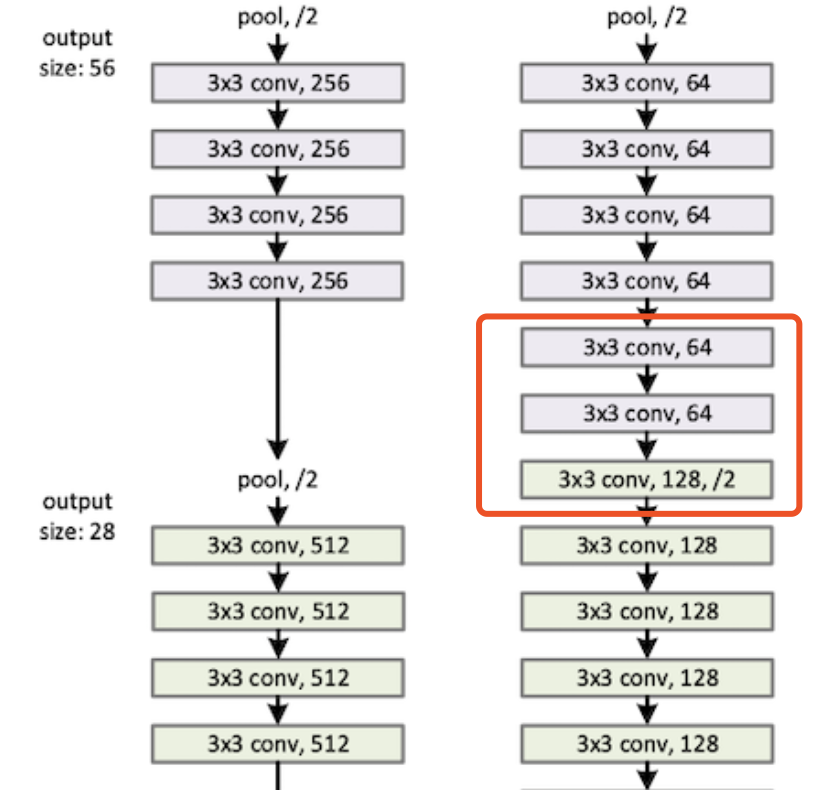
右边的网络可以理解为左边的浅层网络加深了 3 层,假设我们希望右边的深层网络与左边的浅层网络持平,即是可以理解为右边的 3 层网络相当于没增加 --- 输入等于输出。
03.1 恒等映射
所以,ResNet 的初衷,就是让网络拥有这种恒等映射能力,能在加深网络的时候,至少能保证深层网络和浅层网络持平。ResNet 引入了残差网络结构 (Residual Network),通过这种残差网络结构,可以把网络层弄得很深,甚至达到成百上千层。并且最终分类效果也非常好,残差网络基本结构如图:
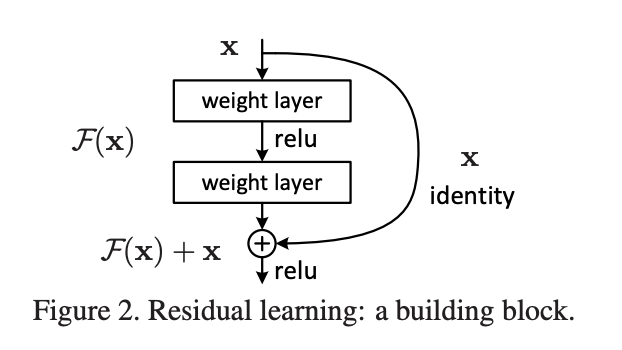
残差网络借鉴了高速网络 (Higeway Network) 的跨层连接思想,但与其有些许不同 (残差项本是带权值的,但 ResNet 用恒等映射代替之)。
在上图的残差网络结构图中,通过 “shortcut connections (捷径连接)” 的方式,直接把输入 x 传到输出作为初始结果,输出结果为 H(x)=F(x)+x,当 F(x)=0 时,那么 H(x)=x,也就是上面所提到的恒等映射。于是,ResNet 相当于将学习目标改变了,不再是学习一个完整的输出,而是目标值H(X) 和 x 的差值,也就是所谓的残差 F(x) := H(x)-x,因此,后面的训练目标就是要将残差结果逼近于 0,使到随着网络加深,准确率不下降。
这种残差跳跃式的结构,打破了传统的神经网络 n-1 层的输出只能给 n 层作为输入的惯例,使某一层的输出可以直接跨过几层作为后面某一层的输入,其意义在于为叠加多层网络而使得整个学习模型的错误率不降反升的难题提供了新的方向。
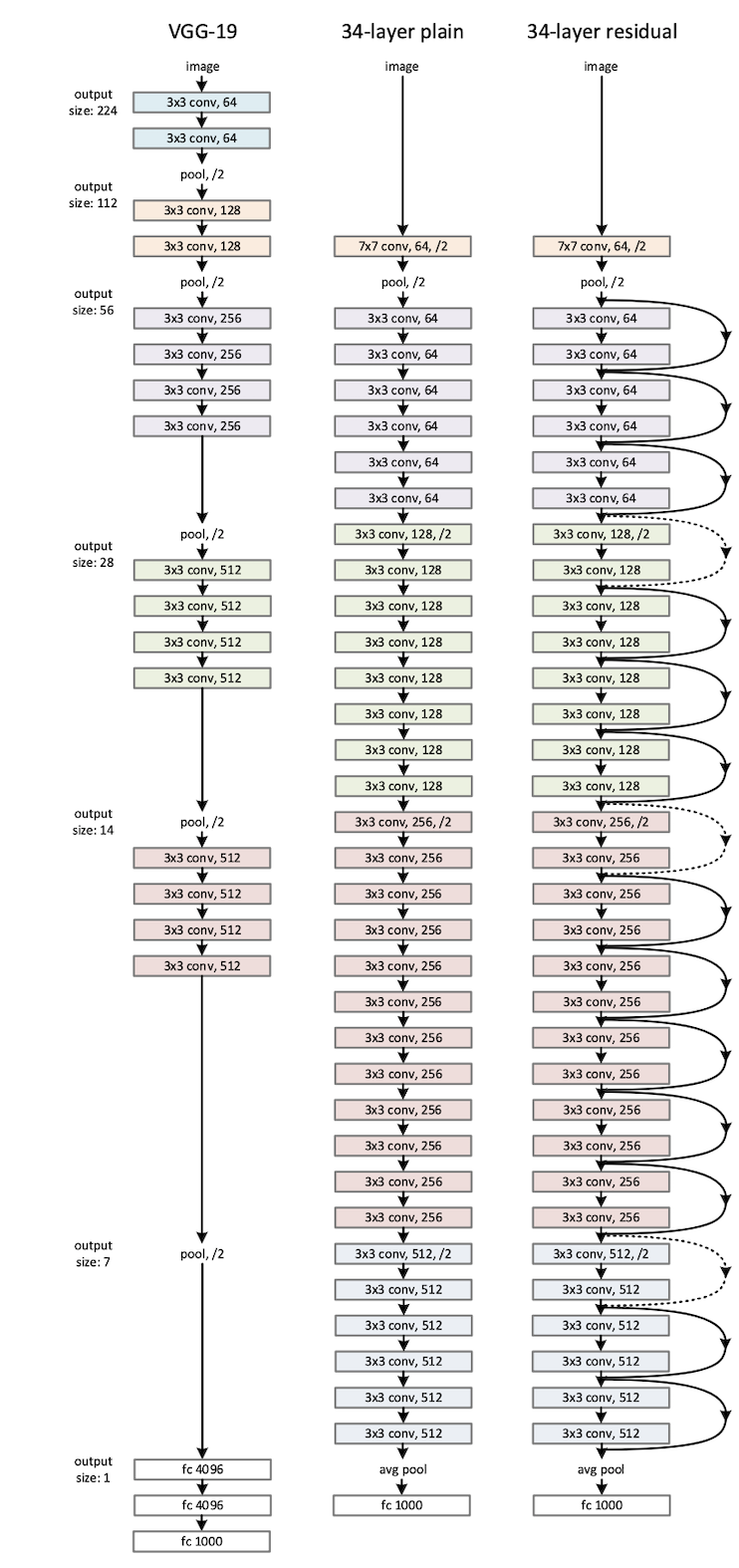
下图的网络结构图中,从左到右分别是 VGG,没有残差的 PlainNet,以及有残差的 ResNet,从这张图中可以感受到当年 ResNet 对 VGG 的统治力。
03.2 通道维度不同如何解决?
可以看到里面的残差网络结构有些是实线,有些是虚线,有何区别?因为经过 “shortcut connections (捷径连接)” 后,H(x)=F(x) + x,如果 F(x) 和 x 的通道相同,则可直接相加,那么通道不同怎么相加呢。上图中的实线、虚线就是为了区分这两种情况的:
- 实线的 Connection 部分,由于通道相同,所以计算方式是 H(x)=F(x)+x。
- 虚线的的 Connection 部分,由于通道不同,采用的计算方式为 H(x)=F(x)+Wx,其中 W 是卷积操作,用来调整 x 维度的。
03.3 两层残差结构和三层残差结构的不同
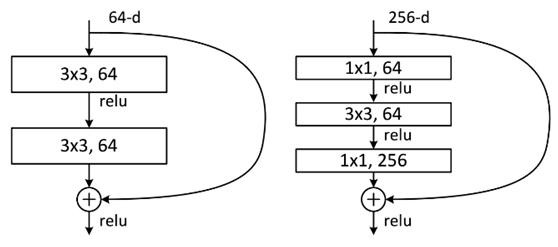
两种结构分别针对 ResNet34(左图)和 ResNet50/101/152(右图),其目的主要就是为了降低参数的数目。
左图是两个 3x3x256 的卷积,参数数目: 3x3x256x256x2 = 1179648,右图是第一个 1x1 的卷积把 256 维通道降到 64 维,然后在最后通过 1x1 卷积恢复,整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,右图的参数数量比左图减少了 16.94 倍,因此,右图的主要目的就是为了减少参数量,从而减少计算量。
对于常规的 ResNet,可以用于 34 层或者更少的网络中(左图);对于更深的网络(如101层),则使用右图,其目的是减少计算和参数量。
03.4 实验结果
作者对比了 18 层的神经网络和 34 层的神经网络,发现残差结构确实解决了网络退化问题:
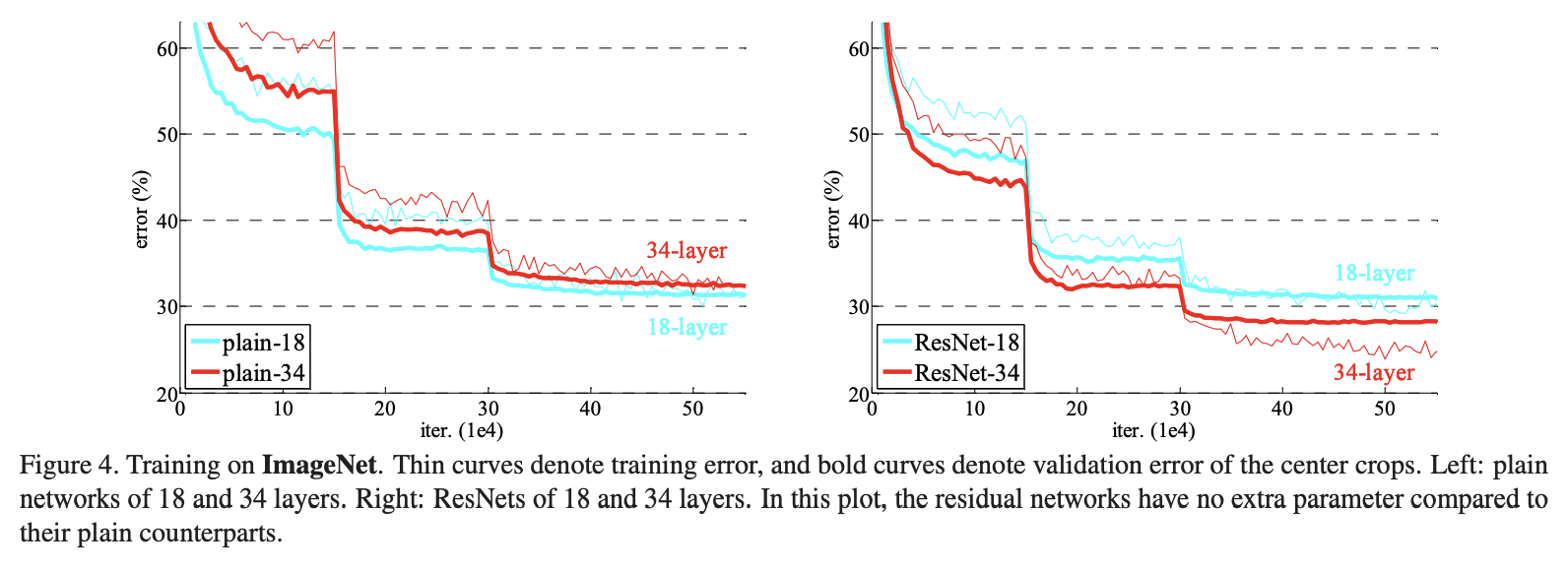
左图为平原网络,34 层的网络比 18 层的网络误差率更高;右图为残差网络结构模型,深层网络比浅层网络误差率更低。
04 总结
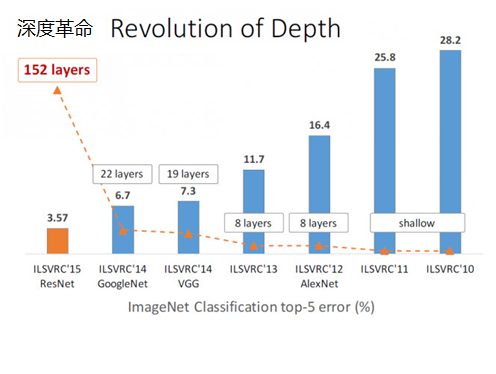
ResNet 在 ILSVRC 2015 竞赛中惊艳亮相,一下子将网络深度提升到 152 层,将错误率降到了3.57,在图像识别错误率和网络深度方面,比往届比赛有了非常大的提升,ResNet 毫无悬念地夺得了 ILSVRC 2015 的第一名。如下图所示:
在 ResNet 的作者的第二篇相关论文《Identity Mappings in Deep Residual Networks》中,提出了 ResNet V2。ResNet V2 和 ResNet V1 的主要区别在于,作者通过研究 ResNet 残差学习单元的传播公式,发现前馈和反馈信号可以直接传输,因此 “shortcut connection”(捷径连接)的非线性激活函数(如 ReLU)替换为 Identity Mappings。同时,ResNet V2 在每一层中都使用了 Batch Normalization。这样处理后,新的残差学习单元比以前更容易训练且泛化性更强。
如果您觉得文章对您有帮助,欢迎点赞,转发,评论,关注个人公众号。

