

背景
在公司大促预热期间,出现了一起dubbo服务provider丢失事故,主要的表现是支付链路上的6个应用的provider全部丢失,但公司其他服务的provider却是正常的,且问题应用可以正常连通zk。
几个疑问
发生这个问题后,我们团队产生了几个疑问,
- zookeeper恢复后,按理说dubbo服务会重新注册
- 为什么刚好是支付链路这条线出了问题,其他链路全部正常
- 生产环境都是多节点部署,为什么支付链路的所有节点都未正常注册,而其他链路应用的所有节点都正常
问题排查
初步排查
在初期排查过程中,发现如下问题:
- zookeeper在期间发生过连接不上、重新选举的过程,大概持续了3~4分钟左右
- 生产环境三台zookeeper节点有一台配置有问题,假设三台分别为zk1、zk2、zk3,那么zk1将集群配成了zk1、zk1、zk2,其余两台配置均正常
- 有个应用因为代码问题,产生了1000个左右的consumer
但从直觉上,我们团队一致认为,虽然2、3两点有问题,但是应该与本次事故无关。
疑问一
首先令我们非常困惑的就是疑问一,于是我打算先不考虑疑问二、疑问三,先排查疑问一的原因。
猜想
对于疑问一,由于对zookeeper和dubbo不是特别熟悉,期间做了很多试验,最终发现,但我们主动通过zkCli删除provider节点时,dubbo是不会重新注册的。
于是查看了zookeeper的事务操作日志,发现期间并没有provider节点的删除记录。那么猜想只能是zookeeper的自动删除。
于是做出了一个猜想,dubbo其实是重新注册了的,只是后来又被zookeeper给删除掉了。
问题复现
整个问题排查花费了很长时间,没有任何发现,直到发现公司内部有个3年前的wiki文档,记录了一次类似的测试环境的事故,感觉这次事故和wiki记录的大体相似,于是按照wiki的步骤进行了复现。
- 启动zk1,zk2,zk3,部署dubbo服务。服务注册成功
- 断开zk1,zk2,zk3之间的网络,zk集群不可用,dubbo服务报连接zk超时错误
- 等待4分钟
- 恢复zk1,zk2,zk3之间的网络,dubbo服务重新连接并注册服务
- 查看zookeeper节点,provider节点正常
- 等待1分钟
- provider节点消失
打开zk的日志,如下:
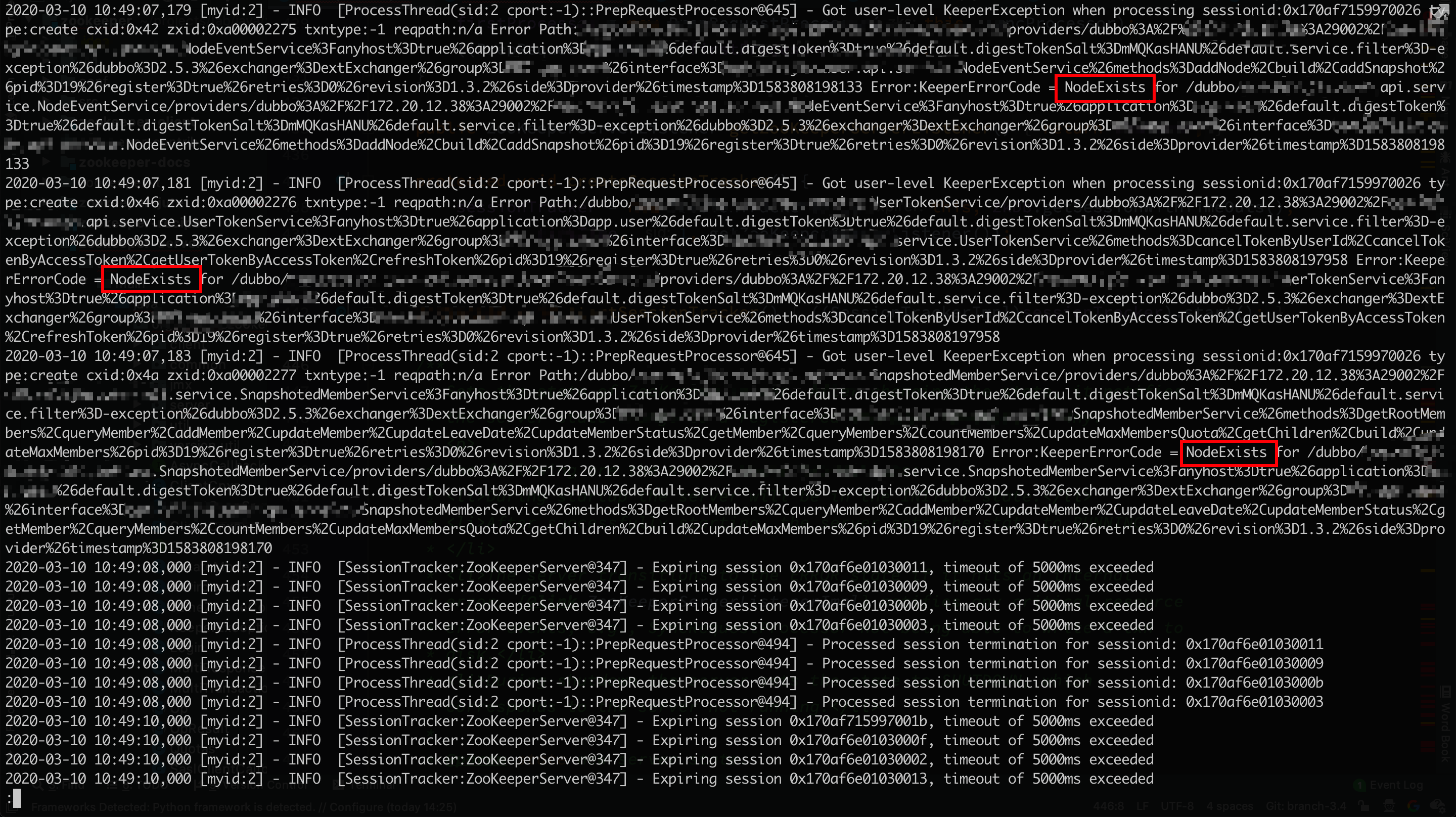
dubbo服务日志如下:
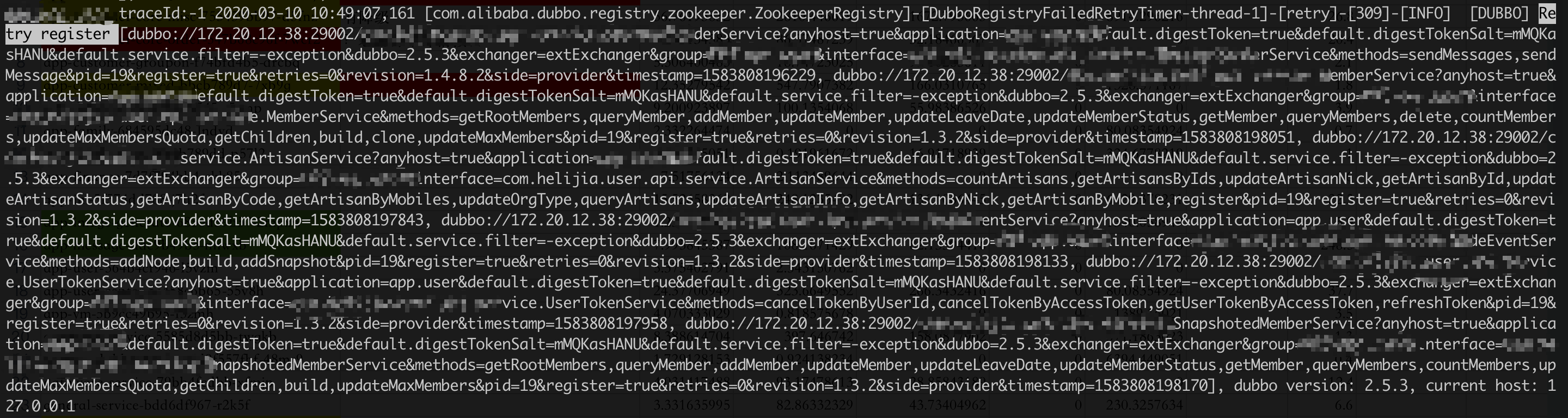
可以看到在dubbo是有在zookeeper恢复后进行重新注册的,但是在zookeeper端可以看到,重新注册的结果是NodeExists,并抛出异常。dubbo端却忽略了这个异常。之后过了一会儿,zookeeper端出现大量session超时,与此同时provider节点被删除。
到这里,我们已经基本上可以解释疑问一了:
1. 起初,dubbo与zk一切正常,并通过sessionA连接
2. 接下来zk集群网络断开,无法满足超过一半节点可用的条件,zk集群处于不可用状态,dubbo与zk断开连接
3. zk恢复正常,dubbo服务认为sessionA已断开,于是发起新的sessionB,并注册provider节点。而此时zk由于本地持久化的原因,使用原先数据恢复了正常,认为sessionA是正常的,并未删除sessionA注册的provider节点。于是sessionB注册失败,而dubbo忽略了这个异常,也同时认为一切ok
4. 过了一会儿,由于sessionA实际上已经断开,无法保持正常心跳,所以超时时间过后,zk断开了sessionA,并清除了sessionA对应的provider节点
到这里,就模拟了整个provider节点丢失的过程。
接下来我们可以通过源码来验证上述过程中的一些猜测点:
A. dubbo服务忽略NodeExists异常
package com.helijia.dubbox.remoting.zookeeper.curator;
public class CuratorZookeeperClient extends AbstractZookeeperClient<CuratorWatcher> {
... ...
public void createEphemeral(String path) {
try {
client.create().withMode(CreateMode.EPHEMERAL).forPath(path);
} catch (NodeExistsException ignored) {
} catch (Exception e) {
throw new IllegalStateException(e.getMessage(), e);
}
}
}
可以看到在创建临时节点的方法中忽略了NodeExistsException
B. zk对于sessionA的处理
package org.apache.zookeeper.server;
public class SessionTrackerImpl extends ZooKeeperCriticalThread implements SessionTracker {
... ...
@Override
synchronized public void run() {
try {
while (running) {
currentTime = Time.currentElapsedTime();
if (nextExpirationTime > currentTime) {
this.wait(nextExpirationTime - currentTime);
continue;
}
SessionSet set;
set = sessionSets.remove(nextExpirationTime);
if (set != null) {
for (SessionImpl s : set.sessions) {
setSessionClosing(s.sessionId);
expirer.expire(s);
}
}
nextExpirationTime += expirationInterval;
}
} catch (InterruptedException e) {
handleException(this.getName(), e);
}
LOG.info("SessionTrackerImpl exited loop!");
}
}
这段代码是用来处理过期session的,看到这里,你或许会问,这样子岂不是session会在zk选举期间就被杀掉,事实上并不是,一旦zk集群不可用,running变量就会变为false,而且sessionSets就会持久化到zk数据库(此段代码就不贴出来了)。这样循环就会结束,等到zk恢复正常后,再重新恢复原先的session。
接下来我们可以看一下,SessionTrackerImpl刚创建时nextExpirationTime是什么,
package org.apache.zookeeper.server;
public class SessionTrackerImpl extends ZooKeeperCriticalThread implements SessionTracker {
public SessionTrackerImpl(SessionExpirer expirer,
ConcurrentHashMap<Long, Integer> sessionsWithTimeout, int tickTime,
long sid, ZooKeeperServerListener listener)
{
super("SessionTracker", listener);
this.expirer = expirer;
this.expirationInterval = tickTime;
this.sessionsWithTimeout = sessionsWithTimeout;
nextExpirationTime = roundToInterval(Time.currentElapsedTime());
this.nextSessionId = initializeNextSession(sid);
for (Entry<Long, Integer> e : sessionsWithTimeout.entrySet()) {
addSession(e.getKey(), e.getValue());
}
}
private long roundToInterval(long time) {
// We give a one interval grace period
return (time / expirationInterval + 1) * expirationInterval;
}
}
从上面这段代码中可以看到初始时nextExpirationTime比currentTime多一个超时周期,也就是说一个zk恢复正常后还需要等待一个超时周期,才会清理原先的失效session。
至于上面说的老session持久化的问题,我们可以从session的创建过程得到证实,如下,从传入的第二个参数中可以知道session数据初始时是从zk的数据库中获取的。(当然,这里的证明并不充分,你可以尝试通过zkCli创建一个临时节点,然后迅速停掉zk,再启动zk,之后我们可以发现之前的临时节点在启动后一段时间内仍然存在)
package org.apache.zookeeper.server;
public class ZooKeeperServer implements SessionExpirer, ServerStats.Provider {
... ...
protected void createSessionTracker() {
// 第二个参数可以看出session数据初始时会从zk的数据库中进行获取
sessionTracker = new SessionTrackerImpl(this, zkDb.getSessionWithTimeOuts(),
tickTime, 1, getZooKeeperServerListener());
}
}
到这里,我们就可以完全解释第一个疑问了。
疑问二、疑问三
对于疑问二和疑问三,基本上可以断定这不是一个偶然事件,而是必然事件。因为所有应用都是使用的同一个zk,因此这个问题应该和zk无关,应该是dubbo服务这边的问题。那么大概可以猜测,和dubbo、zkCli、dubbox、curator这些三方库的版本有关。
但是即使有了这个猜测,仍然无从查起,因为没时间、也不可能将这些三方库的代码全部研究一遍。
根据日志进行分析
那这次仍然是通过复现现场的方式来进行排查,这次我选取了一个正常dubbo服务和一个问题dubbo服务进行观察,分别各自选取他们的一个provider的session进行追踪。同样进行断开zk之间网络的操作,断开时长2分钟左右。
正常dubbo服务的日志如下:
2020-03-11 10:23:56,975 [org.apache.zookeeper.ClientCnxn]-[localhost-startStop-1-SendThread(10.3.6.39:12181)]-[onConnected]-[1299]-[INFO] Session establishment complete on server 10.3.6.39/10.3.6.39:12181, sessionid = 0x170c26cf67a0011, negotiated timeout = 40000
2020-03-11 11:40:33,357 [org.apache.zookeeper.ClientCnxn]-[localhost-startStop-1-SendThread(10.3.6.39:12181)]-[run]-[1158]-[INFO] Unable to read additional data from server sessionid 0x170c26cf67a0011, likely server has closed socket, closing socket connection and attempting reconnect
2020-03-11 11:40:35,009 [org.apache.zookeeper.ClientCnxn]-[localhost-startStop-1-SendThread(10.3.6.39:12181)]-[run]-[1158]-[INFO] Unable to read additional data from server sessionid 0x170c26cf67a0011, likely server has closed socket, closing socket connection and attempting reconnect
... ...
2020-03-11 11:42:39,282 [org.apache.zookeeper.ClientCnxn]-[localhost-startStop-1-SendThread(10.3.6.39:12181)]-[run]-[1158]-[INFO] Unable to read additional data from server sessionid 0x170c26cf67a0011, likely server has closed socket, closing socket connection and attempting reconnect
2020-03-11 11:42:40,502 [org.apache.zookeeper.ClientCnxn]-[localhost-startStop-1-SendThread(10.3.6.39:12181)]-[run]-[1158]-[INFO] Unable to read additional data from server sessionid 0x170c26cf67a0011, likely server has closed socket, closing socket connection and attempting reconnect
2020-03-11 11:42:42,117 [org.apache.zookeeper.ClientCnxn]-[localhost-startStop-1-SendThread(10.3.6.39:12181)]-[onConnected]-[1299]-[INFO] Session establishment complete on server 10.3.6.39/10.3.6.39:12181, sessionid = 0x170c26cf67a0011, negotiated timeout = 40000
问题dubbo服务的日志如下:
2020-03-11 10:24:42,548 [org.apache.zookeeper.ClientCnxn]-[Curator-Framework-0-SendThread(10.3.6.39:12181)]-[onConnected]-[1299]-[INFO] Session establishment complete on server 10.3.6.39/10.3.6.39:12181, sessionid = 0x170c7688bbc0001, negotiated timeout = 40000
2020-03-11 11:41:24,733 [org.apache.zookeeper.ClientCnxn]-[Curator-Framework-0-SendThread(10.3.8.118:12181)]-[run]-[1158]-[INFO] Unable to read additional data from server sessionid 0x170c7688bbc0001, likely server has closed socket, closing socket connection and attempting reconnect
2020-03-11 11:41:25,400 [org.apache.zookeeper.ClientCnxn]-[Curator-Framework-0-SendThread(10.3.8.117:12181)]-[run]-[1158]-[INFO] Unable to read additional data from server sessionid 0x170c7688bbc0001, likely server has closed socket, closing socket connection and attempting reconnect
... ...
2020-03-11 11:42:23,802 [org.apache.zookeeper.ClientCnxn]-[Curator-Framework-0-SendThread(10.3.8.117:12181)]-[run]-[1158]-[INFO] Unable to read additional data from server sessionid 0x170c7688bbc0001, likely server has closed socket, closing socket connection and attempting reconnect
2020-03-11 11:42:23,972 [org.apache.zookeeper.ClientCnxn]-[Curator-Framework-0-SendThread(10.3.6.39:12181)]-[run]-[1158]-[INFO] Unable to read additional data from server sessionid 0x170c7688bbc0001, likely server has closed socket, closing socket connection and attempting reconnect
2020-03-11 11:42:24,841 [org.apache.curator.ConnectionState]-[DubboRegistryFailedRetryTimer-thread-1]-[checkTimeouts]-[191]-[WARN] Connection attempt unsuccessful after 60007 (greater than max timeout of 60000). Resetting connection and trying again with a new connection.
2020-03-11 11:42:25,277 [org.apache.zookeeper.ZooKeeper]-[DubboRegistryFailedRetryTimer-thread-1]-[close]-[684]-[INFO] Session: 0x170c7688bbc0001 closed
2020-03-11 11:42:25,277 [org.apache.zookeeper.ClientCnxn]-[Curator-Framework-0-EventThread]-[run]-[519]-[INFO] EventThread shut down for session: 0x170c7688bbc0001
从上面的日志可以发现,正常dubbo服务一直重试,直到session重新连接成功,而问题dubbo服务则会重试一分钟后,断开session,重新创建一个新的session。
查看生产环境的日志发现,原来不止支付链路的6个dubbo服务出现问题,总共受影响的应用为20多个,只是刚好只有支付链路的6个应用提供provider,其他应用都只有consumer。
从日志现象已经可以解释这个问题了,那接下来还差从源码中找到真实原因了。
从源码中查找原因
首先找到Connection attempt unsuccessful after 60007 (greater than max timeout of 60000). Resetting connection and trying again with a new connection.这段日志所在的代码位置,
package org.apache.curator;
class ConnectionState implements Watcher, Closeable {
... ...
private synchronized void checkTimeouts() throws Exception
{
int minTimeout = Math.min(sessionTimeoutMs, connectionTimeoutMs);
long elapsed = System.currentTimeMillis() - connectionStartMs;
if ( elapsed >= minTimeout )
{
if ( zooKeeper.hasNewConnectionString() )
{
handleNewConnectionString();
}
else
{
int maxTimeout = Math.max(sessionTimeoutMs, connectionTimeoutMs);
if ( elapsed > maxTimeout )
{
if ( !Boolean.getBoolean(DebugUtils.PROPERTY_DONT_LOG_CONNECTION_ISSUES) )
{
log.warn(String.format("Connection attempt unsuccessful after %d (greater than max timeout of %d). Resetting connection and trying again with a new connection.", elapsed, maxTimeout));
}
reset();
}
else
{
KeeperException.ConnectionLossException connectionLossException = new CuratorConnectionLossException();
if ( !Boolean.getBoolean(DebugUtils.PROPERTY_DONT_LOG_CONNECTION_ISSUES) )
{
log.error(String.format("Connection timed out for connection string (%s) and timeout (%d) / elapsed (%d)", zooKeeper.getConnectionString(), connectionTimeoutMs, elapsed), connectionLossException);
}
new EventTrace("connections-timed-out", tracer.get(), getSessionId()).commit();
throw connectionLossException;
}
}
}
}
}
一番调试,发现正常应用和问题应用的差别在这。如下图,正常应用会在elapsed>connectionTimeoutMs后阻塞在下图红色部分,而问题应用则会一直运行,直到elapsed > maxTimeout后重置session。
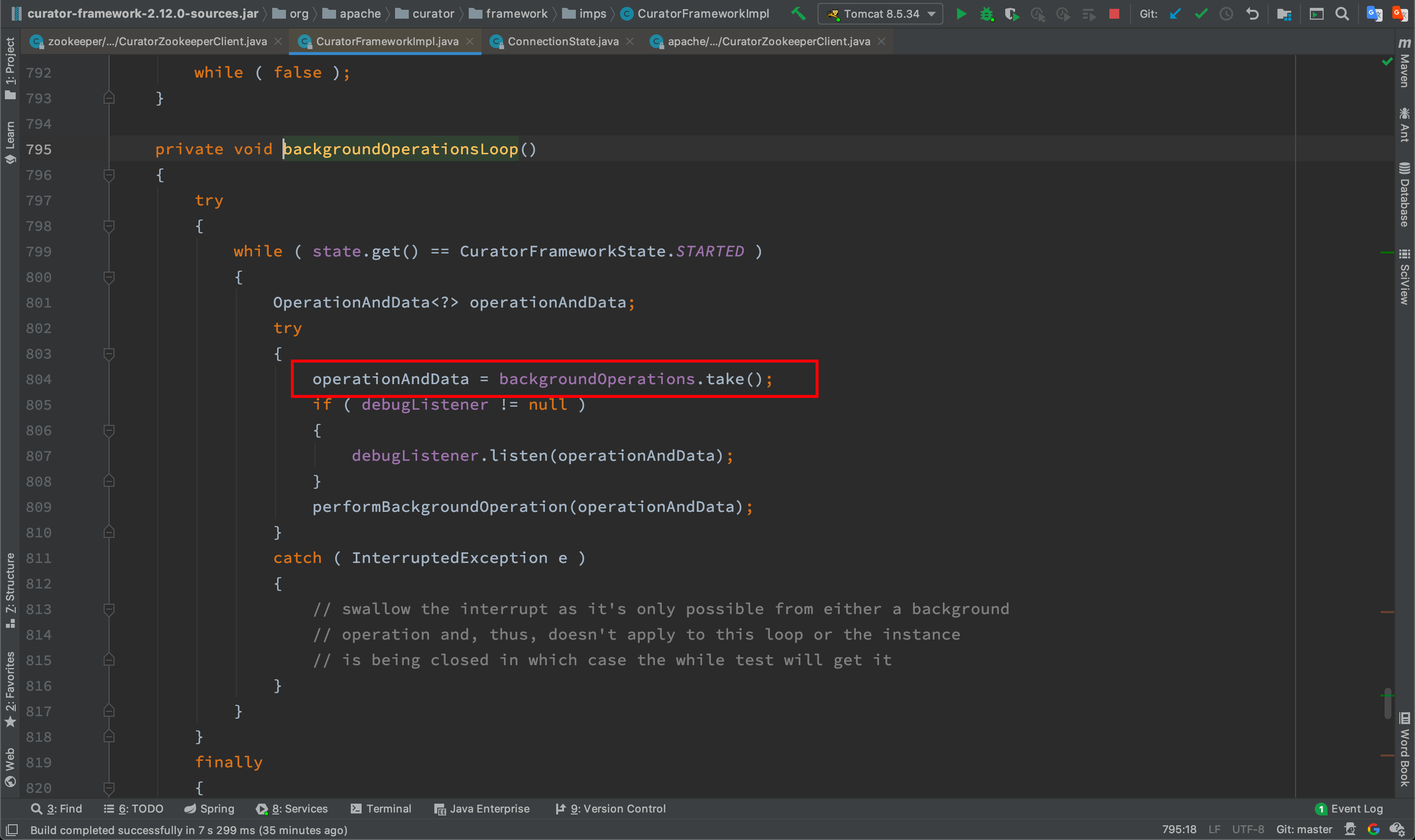
那为什么正常应用会阻塞,而问题应用不会阻塞呢,最终发现在下面这一步两者会走到不同分支,
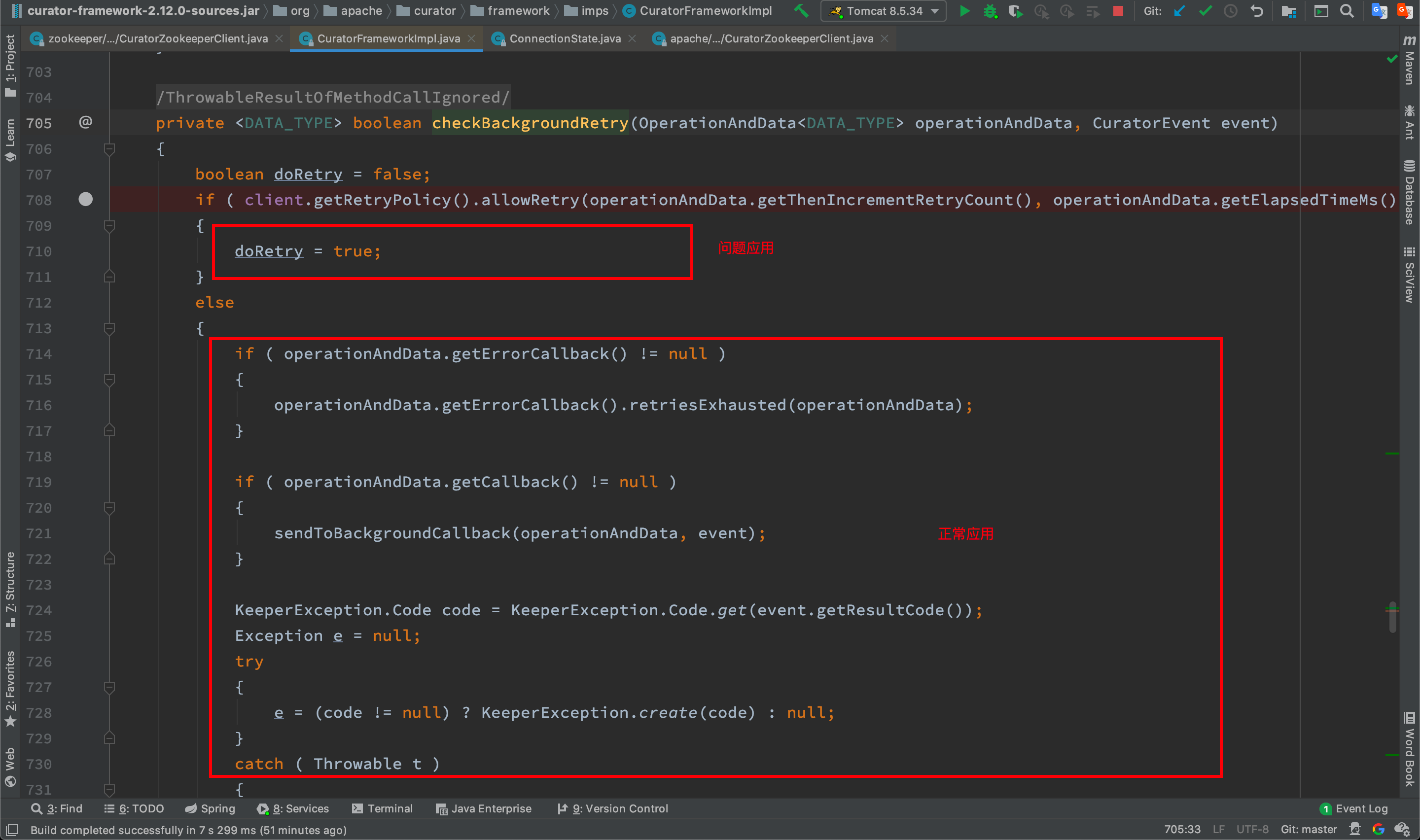
那么接下来比较吸引人注意的就是这个判断条件了,代码如下,两者的代码都是相同的,
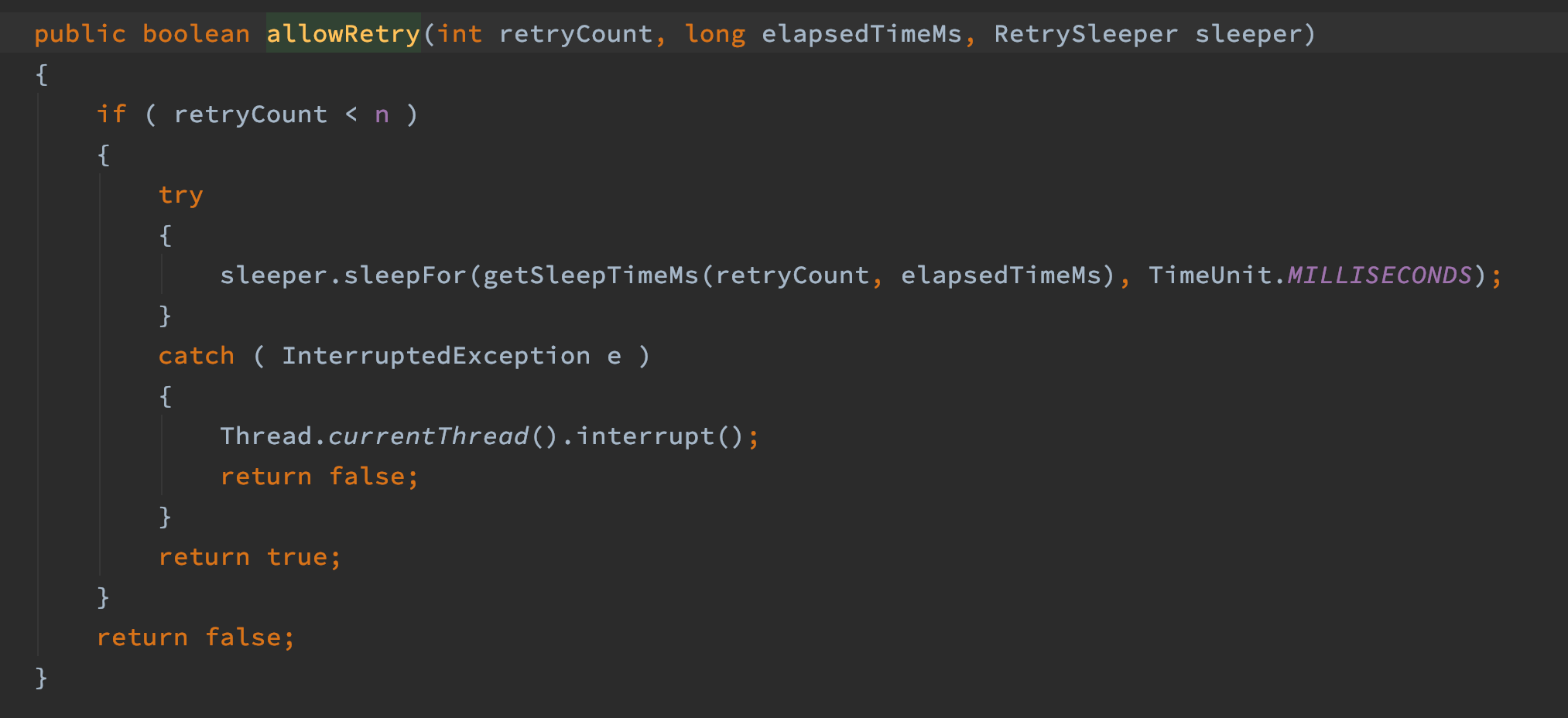
调试发现,两者的client.getRetryPolicy()返回的重试策略是不同的,正常应用返回n=1,问题应用返回n=Integer.MAX_VALUE。那么接下来就来查看两者的retryPolicy的初始化过程。
debug查找retryPolicy的注入方式
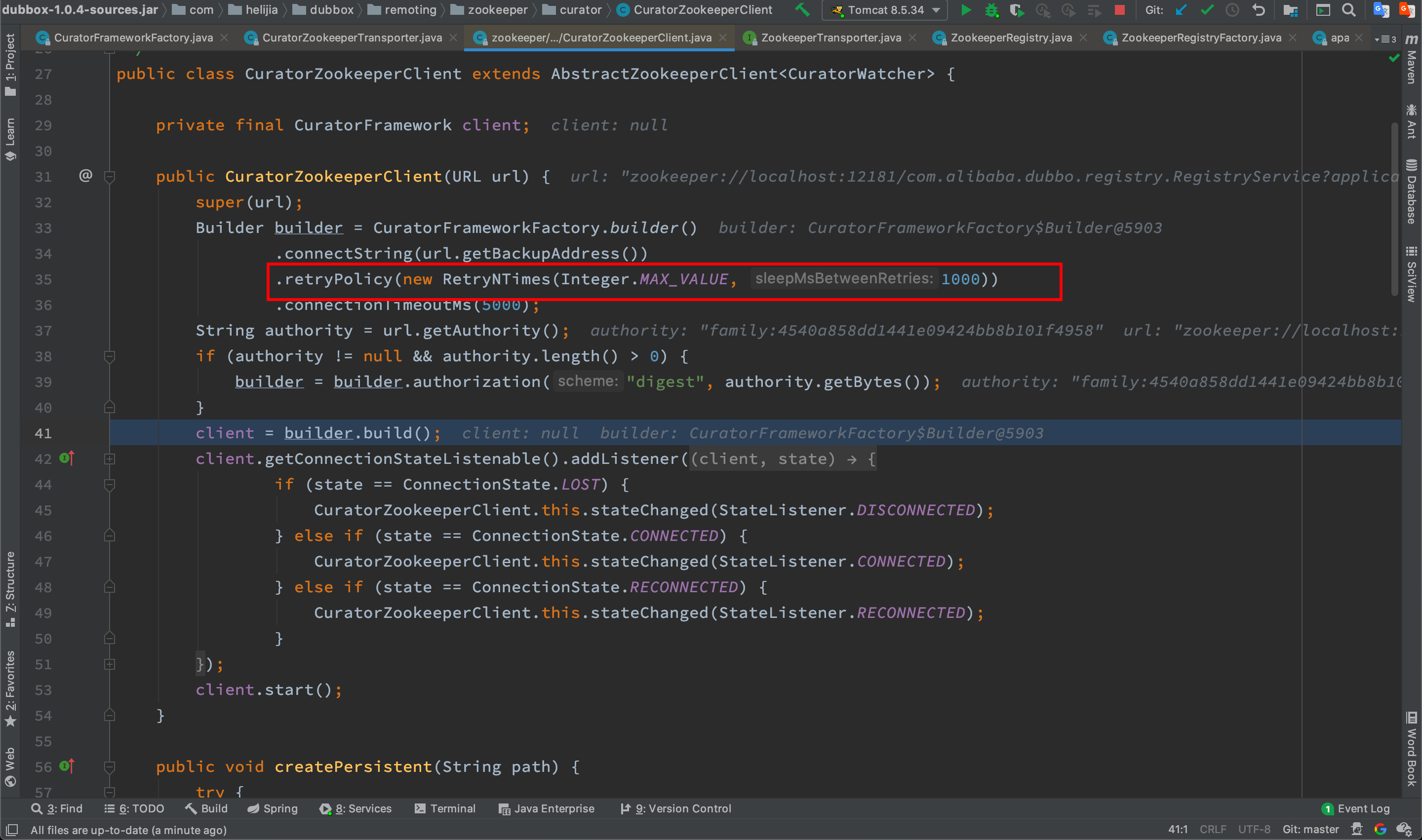
问题应用
对于问题应用,如下图,由于是老应用,CuratorZookeeperClient使用的是dubbox-1.0.4的,其中重试次数默认设为了无限次(Integer.MAX_VALUE)
正常应用
对于正常应用,如下图,CuratorZookeeperClient则加载的是dubbo-2.6.7的,其中重试次数默认设置为1
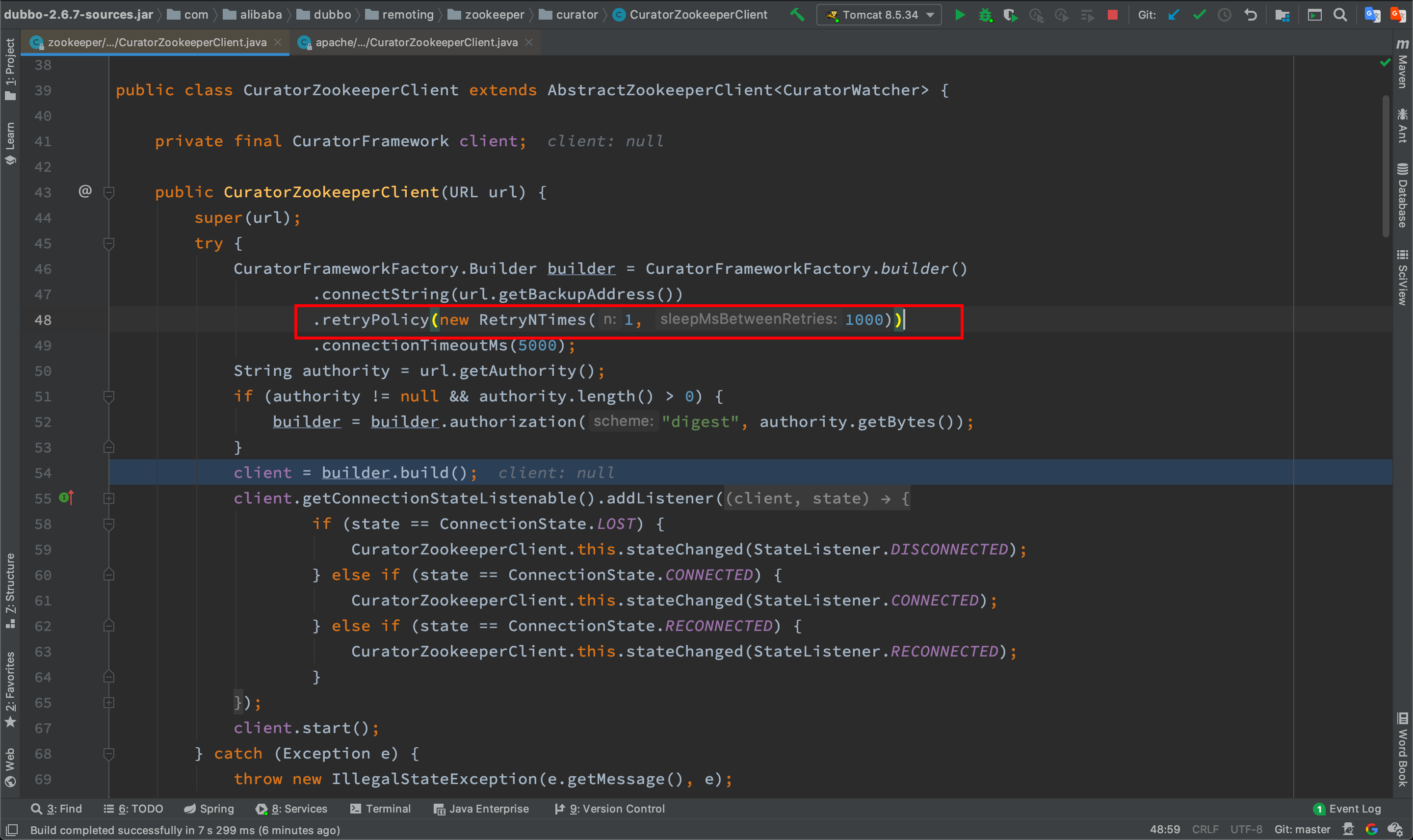
排查到这里,就可以得到结论了,这是两者使用的dubbo版本不同区别,其中dubbo-2.6.7不会出现这个问题,dubbox-1.0.4(dubbo-2.5.3)则会出现这个问题。
同dubbo版本(2.5.3),一个正常,一个有问题
但是故事到这里还没有结束。这件事比想象中更复杂,事实上,出问题的应用全部都使用了dubbo2.5.3,但并不是所有dubbo2.5.3的应用都有问题,也有部分dubbo2.5.3的应用其实是运行正常的。
找了一个正常的应用,调试发现,其根本没有加载Curator客户端,因此也就不会出现上文中重置session的问题。经过详细对比发现,问题应用的dubbo配置如下:
<dubbo:registry protocol="zookeeper" address="${user.dubbo.zk.servers}" client="curatorx" />
而正常应用的dubbo配置如下:
<dubbo:registry protocol="zookeeper" address="${dubbo.registry.address}" check="true" />
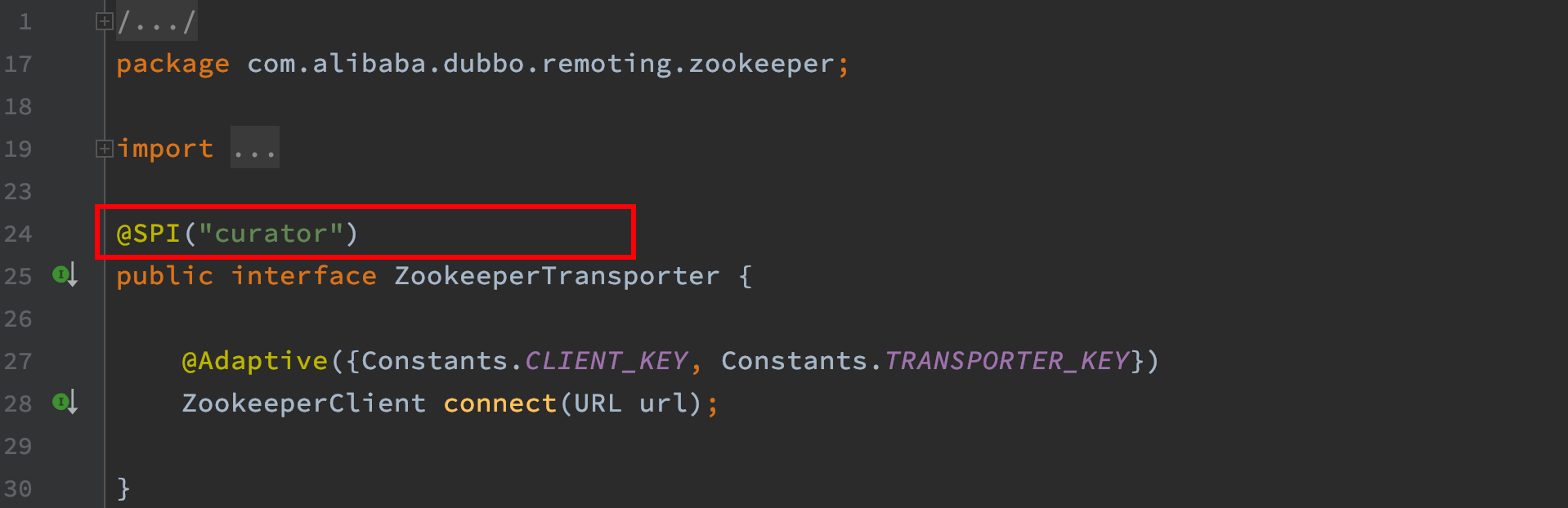
而对于dubbo2.5.3版本,默认使用zkclient,如下图。因此正常应用没有加载Curator客户端,而问题应用指定了使用curator作为客户端。
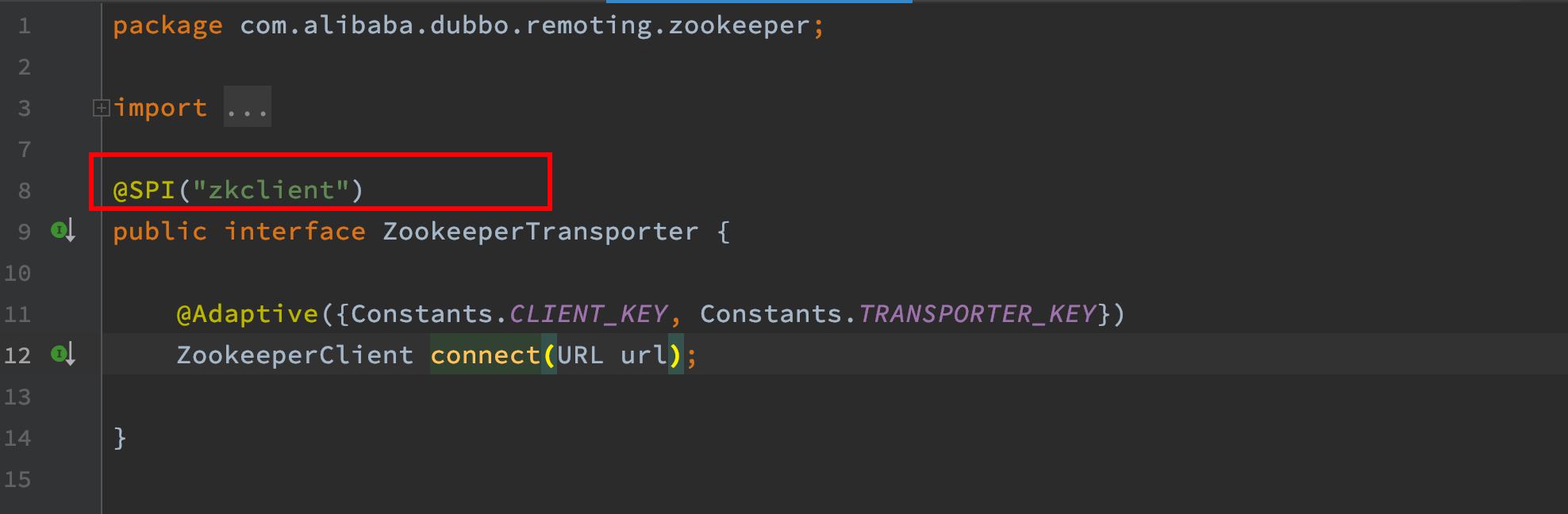
当然了,对于dubbo2.6.7,默认使用curator作为zk客户端
结论
在我的案例里面只涉及到了dubbo2.5.3和dubbo2.6.7,其他dubbo版本请自行排查
至此,上述的三个疑问都已经全部可以解释了。
综上,当使用dubbo2.5.3版本(其他低版本dubbo可能也有类似问题)且client指定为curator时,一定会出现zookeeper不可用状态超过一定时间后,provider消失的现象。
