

事情是怎么变复杂的
Redux 原本并不复杂,其基本理念可以概括为:通过 action 提交变更,经过 reducer 计算出新的 state。action 是一个约定含 type 字段的对象,reducer 是一个约定以 state 和 action 为参数、以新的 state 为返回值的纯函数。
state -> dispatch(action) -> reducer -> new State => new View
考虑最原始的情形,在业务代码中直接 dispatch action 对象,那么只需要定义三个文件就可以了:state.js、reducer.js、store.js,分别用于定义 state、reducer 和创建 store。
1、不要直接提交 action 对象
业务代码直接 dispatch action 对象并不好,一是重复,二是无类型校验。官方推荐用函数来创建 action,并且 action 的 type 最好用常量而不是字符串,同时还需保证 type 的全局唯一性。于是再加两个文件:actions.js、type.js,分别用于定义 action 函数和 type 常量。
这就形成了普遍遭受诟病的模板代码(常量还得全大写,害),于是出现了一些方案,来简化 action 与 type 的定义,比如 reduxsause、react-arc。
2、reducer 需要拆开
官方仅仅约定了 reducer 的 interface,但没有规定具体实现。原始案例中用 switch,每个 case 对应一个 action,当 action 增多时,一个超长的 reducer 显然是不利于维护的。官方提供了一种拆分思路,并提供了相应的辅助函数(combineReducers)。
function todoApp(state = {}, action) {
return {
visibilityFilter: visibilityFilter(state.visibilityFilter, action),
todos: todos(state.todos, action)
}
}
不过这种模式有很多问题,比如:每个字段都需要定义一个子 reducer;子 reducer 的 state 参数都不一样,并且不能忘了设置初始值;同一个 action 可能分布在不同的子 reducer 中,每新增一个 action,如果对应多个字段的变更,那么需要在多个 reducer 中新增 case 分支。
3、深层数据结构如何更新
redux 约定 state 必须是全局唯一并且是 immutable 的(约定,而非约束),reducer 每次都需要整个的返回一个新的 state。如果数据结构比较深,更新起来很麻烦。这个问题相对好解决,通常用 immutable-helper、seamless-immutable 之类的辅助库即可。
4、异步更新逻辑怎么办
好像所有介绍 Redux 的文章都会不约而同的宣称一个极具误导性的论断:Redux 不支持异步状态更新。
那是不是说,如果单纯用 Redux,应用里的异步逻辑就无法写了?显然没有这回事。
// 照常写异步逻辑,然后提交更新,有啥问题咩?
fetch().then(data => {
dispatch(updateAction(data))
})
不过有人会这么想:我就想提交一个 action,由这个 action 去完成异步逻辑,人家 vuex 和 mobX 都有相关的支持,redux 咋就不行?
于是官方通过 redux-thunk 提供了一个语法糖,让你可以 dispatch 一个封装了异步逻辑的 thunk 函数,使得代码在语义上能够实现“提交了一个异步 action”这么个事儿。
// 寥寥数行的 redux-thunk 中间件
function createThunkMiddleware() {
return ({ dispatch, getState }) => (next) => (action) => {
if (typeof action === 'function') { // 啊哈
return action(dispatch, getState)
}
return next(action)
};
}
看清本质你就会明白,哪里有“redux 不支持异步状态更新”这回事儿呢?只是代码逻辑聚合在哪里的区别而已,最终要触发 reducer 更新 state,还是得在 dispatch 一个对象的时候。所以根本不存在“非得引一个库 redux 才能支持异步”这回事儿,无论是 redux-thunk、redux-promise 还是 redux-saga,与其说在弥补 redux 的缺陷,倒不如说它们在解决自己额外创造出来的问题。
偏激的讲,【async action】 是一个与 redux 无关的概念陷阱。客观的说,【async action】是一种代码设计抽象。本来 action 就是一个纯对象而已,现在 action 还可以是一个函数,被称为异步 action。
const a = { type, payload } // 这是一个 reducer action
const b = payload => ({ type, payload }) // 这也是一个 reducer action
const c = dispatch => fetch().then(res => dispatch(xxx) // 这是一个 async action
任何状态管理库,提供的所谓异步状态更新功能,都只是一种 api 层面上的包装。这当然有好处,比如提供了额外的抽象约束,状态更新逻辑更加内聚,同时让业务逻辑更纯粹,组件只管发 action 和呈现数据。但不能认为“redux 不支持异步 action,所以必须加 thunk,必须加 saga”,这是站在抽象的高峰,被概念的云雾迷了眼。
小结
原本只是三个文件的事,最终扩展成了 redux + react-redux + action type 定义方案 + immutable 数据更新方案 + 异步过程封装方案。这下好了,要写一个最简单的“请求接口然后更新数据”的逻辑,往往需要改动 5、6 个文件。整个逻辑链路之长,不仅写起来费劲,看/找起来也费劲。
于是社区给出了整合、封装甚至重构过的相对完整的类 redux 方案,比如 rematch(Redesigning Redux)、dva。更激进的,有人不愿意受“只能通过 dispatch action 而不是直接调用 reducer 更新 state”的约束,搞出了【action reducer 化】的方案,比如 redux-zero、reduxless。
// redux
dispatch(action) => reducer => newState
// redux-zero
action(state, payload) => newState
围绕 redux,不仅有大量“修补型”方案,还有不少“整合型”、“重构型”和“替代型”方案,正面的说,这是生态繁荣的体现,负面的说,这是对 redux 作为事实上的【react 状态管理业界标准】的某种讽刺。这一切到底是证明 redux 本身不是一个好的设计,还是说使用者没用对,把事情搞复杂了?
一种自动生成 action 的简化方案
每一个 action,一定对应一个 reducer 处理逻辑,如果 reducer 函数按 action 粒度拆分,每个 action,对应一个 reducer 函数,而每个 action 拥有唯一的 type,那么可以得出:action、type 和 reducer 是一一对应的。
如果能保证 reducer 不重名,然后 action 和 type 直接复用 reducer 的名称,那么 action 就能根据 reducer 自动生成。
// reducer.js
// reducer 的拆分方式有很多
// 这里每个 reducer 对应一个 action
// 第一个参数是全局的 state,第二个参数对应 action 中的 payload
export const reducerA = (state, payload) => state
export const reducerB = (state, payload) => state
// action.js
// 期望根据 reducer 自动生成的 actions 对象
export const actions = {
reducerA: payload => ({ type: 'reducerA', payload }),
reducerB: payload => ({ type: 'reducerB', payload })
}
首先,按上述方式拆分的 reducer,需要按如下方式聚合:
// store.js
import initialState from './state.js'
import * as reducers from './reducer.js'
// 聚合 reducer
function reducer(state = initialState, { type, payload }) {
const fn = reducers[type];
return fn ? fn(state, payload) : state;
}
上述写法要求所有的 reducer 都聚合在 reducer.js 里,注意,不一定都定义在 reducer.js 里,可以分散定义在不同文件中,只是在 reducer.js 里统一导出,这样就保证了 reducer 不会重名。
有了 reducer 的 map 对象,很容易自动生成 actions 对象:
// action.js
import * as reducers from './reducer.js'
export const actions = Object.keys(reducers).reduce(
(prev, type) => {
prev[type] = payload => ({ type, payload })
return prev
},
{}
)
使用的时候,引入 actions 对象即可:
import { actions } from 'store/action.js'
dispatch(actions.reducerA(payload))
这样,action 和 type 就都不需要定义了。每次新增逻辑,状态部分就只需要写 state 和 reducer 即可。
不过上述方式仍然不够完美,因为没有类型。按常规的写法,action 是有类型定义的,既可以校验参数,又有自动补全提示,可丢不得。
// reducer.ts
export interface A {}
export const reducerA = (state: StateType, payload: A) => state
// action.ts
// 常规写法
import { A } from './reducer.ts'
export const actionA = (payload: A) => ({ type: TYPE, payload })
考虑到 action 函数的参数类型和对应 reducer 第二个参数的类型是一致的,那么能否既复用 reducer 的名称,又复用参数类型,在自动生成 actions 对象的同时,连类型也一起自动生成呢?
// 期望生成的 interface
// 关键是如何拿到 reducer 函数定义好的 payload 参数的类型,返回值类型其实不需要关心
interface Actions {
reducerA (payload: A): AnyAction
reducerB (payload: B): AnyAction
}
首先不考虑 payload 参数类型,先看如何自动生成 actions 对象的 interface:
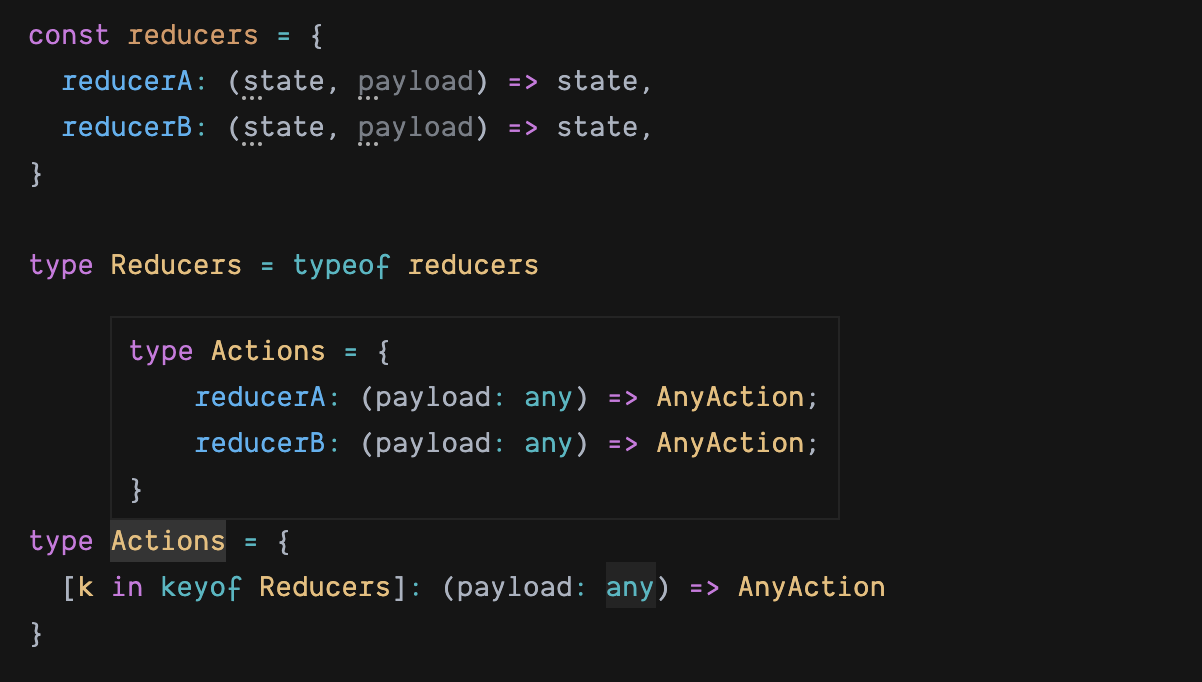
可见,通过 keyof 关键字,Actions 类型已经拿到了所有的键值。
接下来要设置 payload 参数类型,关键是如何拿到一个已知的函数类型定义中的第二个参数的类型。TS 里提供了 infer 关键字用于提取类型。
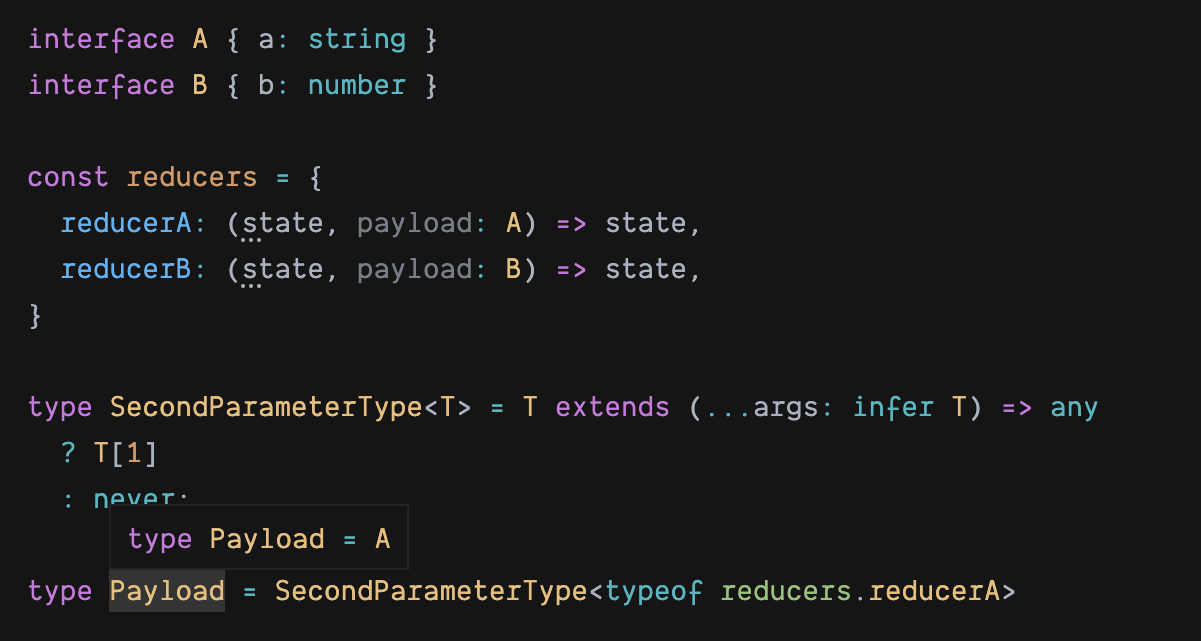
T 表示 args 的类型,是一个数组,T[1] 即第二个参数的类型。
搞定了以上两个关键步骤,剩下的事情就比较简单了:
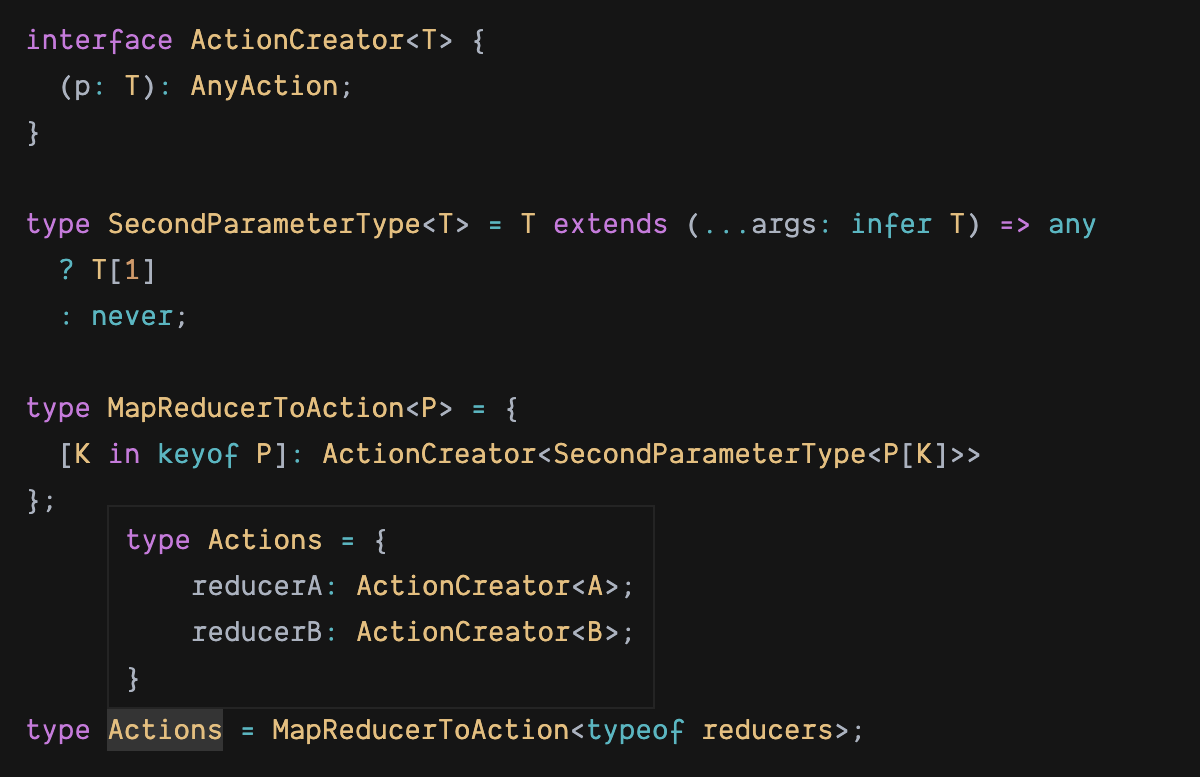
这样我们就有了类型,每次新增 reducer,都会自动生成最新的 actions 及其类型。
省略了 action 定义,也就省掉了模板代码中的一大半。其它减省代码的地方还有:mapDispatchToProps 使用官方推荐的简写形式、用 class 定义 state 以直接提取 StateType 类型、封装 store 定义等,细枝末节不多赘述。
完整案例可参见:codesandbox.io/s/clever-ra…
