

专注于大数据及容器云核心技术解密,可提供全栈的大数据+云原生平台咨询方案,请持续关注本套博客。如有任何学术交流,可随时联系。更多内容请关注《数据云技术社区》公众号。

1 三板斧kube-Scheduler的邻里关系
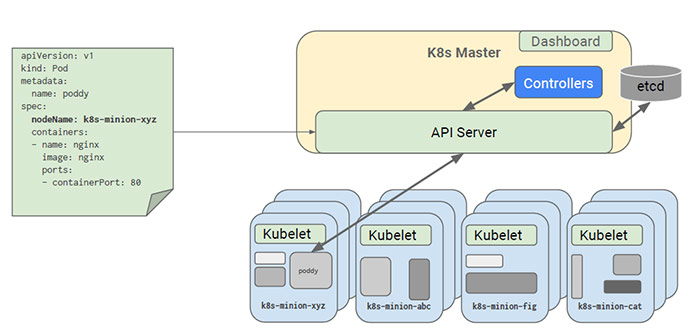
- kubectl 根据配置文件,向 APIServer 发送命令,在 Node 上面建立 Pod 和 Container。
- 在 APIServer,经过 API 调用,权限控制,调用资源和存储资源的过程。实际上还没有真正开始部署应用,还需要 Controller Manager,Scheduler 和 kubelet 的协助才能完成整个部署过程。
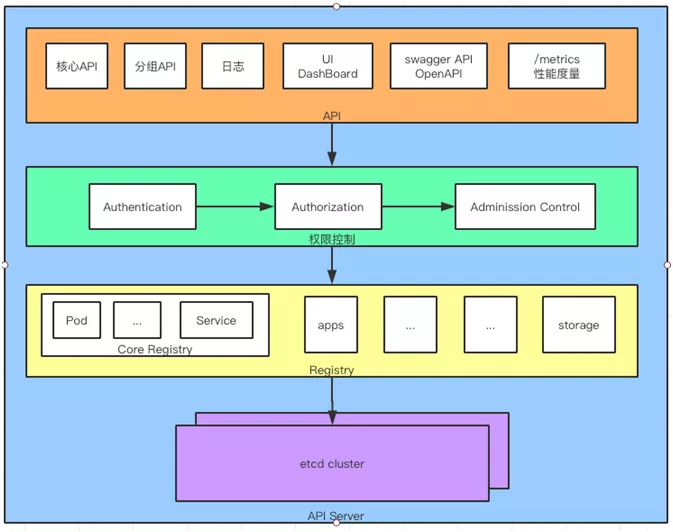
(1)API 层:主要以 REST 方式提供各种 API 接口,针对 Kubernetes 资源对象的 CRUD 和 Watch
等主要 API,还有健康检查、UI、日志、性能指标等运维监控相关的 API。
(2)访问控制层:负责身份鉴权,核准用户对资源的访问权限,设置访问逻辑(Admission Control)。
(3)注册表层:选择要访问的资源对象。PS:Kubernetes把所有资源对象都保存在注册表(Registry)中,
例如:Pod,Service,Deployment 等等。
(4)etcd 数据库:保存创建副本的信息。用来持久化 Kubernetes 资源对象的 Key-Value 数据库。
摘录:https://mp.weixin.qq.com/s/ieIALsPmy7I3vk3jiCI0YA
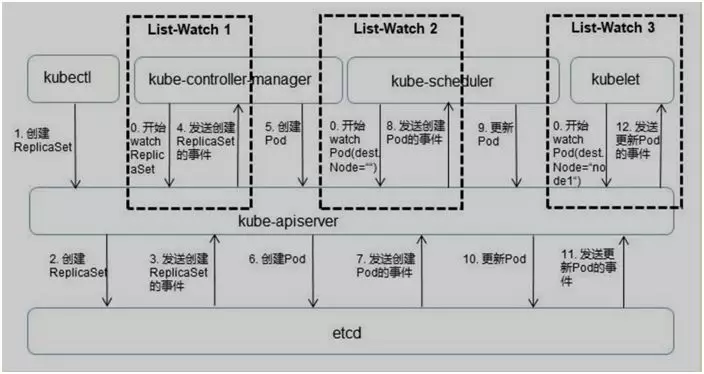
- 在介绍协同工作之前,要介绍一下在 Kubernetes 中的监听接口。从上面的操作知道,所有部署的信息都会写到 etcd 中保存。
实际上 etcd 在存储部署信息的时候,会发送 Create 事件给 APIServer,而 APIServer 会通过监听(Watch)etcd 发过来的事件。Controller Manager,Scheduler 和 kubelet 组件也会监听(Watch)APIServer 发出来的事件。
2 kube-Scheduler之预选算法
2.1 总体梳理
2.2 核心算法剖析
- 存储匹配相关
- Pode 和 Node 匹配相关
- Pod 和 Pod 匹配相关
- Pod 打散相关
2.2.1 存储相关
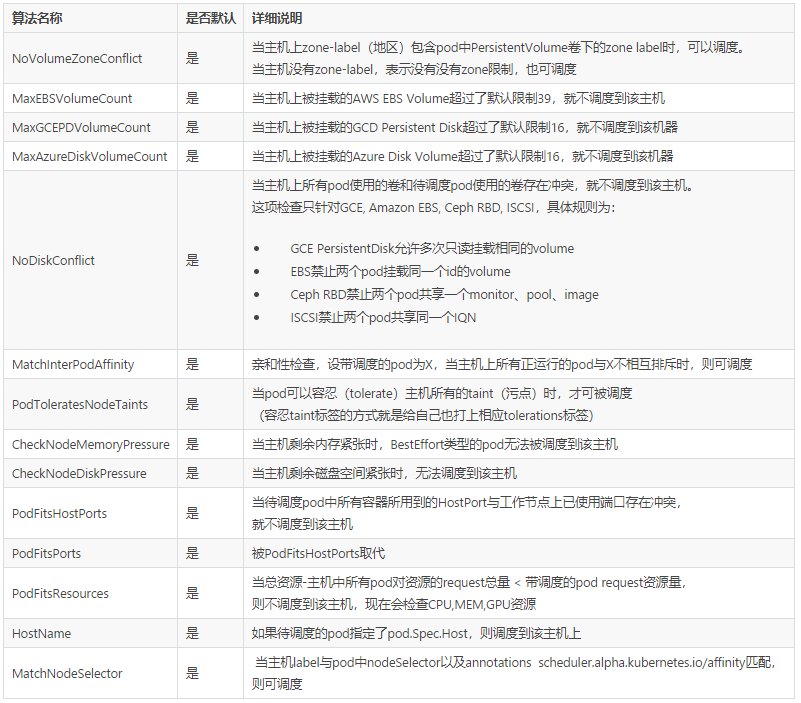
- NoVolumeZoneConflict,检查给定的zone限制前提下,检查如果在此主机上部署Pod是否存在卷冲突。假定一些volumes可能有zone调度约束, VolumeZonePredicate根据volumes自身需求来评估pod是否满足条件。必要条件就是任何volumes的zone-labels必须与节点上的zone-labels完全匹配。节点上可以有多个zone-labels的约束(比如一个假设的复制卷可能会允许进行区域范围内的访问)。目前,这个只对PersistentVolumeClaims支持,而且只在PersistentVolume的范围内查找标签。处理在Pod的属性中定义的volumes(即不使用PersistentVolume)有可能会变得更加困难,因为要在调度的过程中确定volume的zone,这很有可能会需要调用云提供商。
- MaxCSIVolumeCountPred,是用来校验 pvc 上指定的 Provision 在 CSI plugin 上的单机最大 pv 数限制;
- CheckVolumeBindingPred,在 pvc 和 pv 的 binding 过程中对其进行逻辑校验,里头的逻辑写的比较复杂,主要都是如何复用 pv;
- NoDiskConfict,SCSI 存储不会被重复的 volume, 检查在此主机上是否存在卷冲突。如果这个主机已经挂载了卷,其它同样使用这个卷的Pod不能调度到这个主机上,不同的存储后端具体规则不同
2.2.2 Pod 和 Node 匹配相关
- CheckNodeCondition:校验节点是否准备好被调度,校验node.condition的condition type :Ready为true和NetworkUnavailable为false以及Node.Spec.Unschedulable为false;
- CheckNodeUnschedulable:在 node 节点上有一个 NodeUnschedulable 的标记,我们可以通过 kube-controller 对这个节点直接标记为不可调度,那这个节点就不会被调度了。在 1.16 的版本里,这个 Unschedulable 已经变成了一个 Taints。也就是说需要校验一下 Pod 上打上的 Tolerates 是不是可以容忍这个 Taints;
- PodToleratesNodeTaints:校验 Node 的 Taints 是否被 Pod Tolerates 包含;
- PodFitsHostPorts:校验 Pod 上的 Container 声明的 Ports 是否正在被 Node 上已经分配的 Pod 使用;
- MatchNodeSelector: 校验 Pod.Spec.Affinity.NodeAffinity 和 Pod.Spec.NodeSelector 是否与 Node 的 Labels 匹配。
2.2.3 Pod 和 Pod 匹配相关
- MatchinterPodAffinity:主要是 PodAffinity 和 PodAntiAffinity 的校验逻辑,这里面最大的复杂度是在于 Affinity 里面的 PodAffinityTerm 描述支持的 TopologyKey(可以表示在 node/zone/az 等拓扑结构上),这个其实是一个性能杀手。
2.2.4 Pod 打散相关
- EvenPodsSpread:这是一个新的功能特性,首先来看一下 EvenPodsSpread 中 Spec 描述:描述符合条件的一组 Pod 在指定 TopologyKey 上的打散要求。下面我们来看一下怎么描述一组 Pod,如下图所示:
topologySpreadConstraints: 用于描述 Pod 要在什么拓扑结构上进行均衡打散,多个 topologySpreadConstraint 之间是 and 关系;
selector:用于描述需要满足的拓扑打散的一组 Pod 的列表;
topologyKey: 作用在什么拓扑结构上;
maxSkew: 最大允许的不均衡数量;
whenUnsatisfiable: 当不满足 topologySpreadConstraint 的时候的策略;
DoNotSchedule:表示作用于 filter 阶段;
ScheduleAnyway:作用于 score 阶段。
spec:
topologySpreadConstraints:
- maxSkew: 1
whenUnsatisfiable: DoNotSchedule
topologyKey: k8s.io/hostname
selector:
matchLabels:
app: foo
matchExpressions:
- key: app
operator: In
values: ['foo', 'foo2']
- CheckServiceAffinity:根据当前POD对象所属的service已有的其他POD对象所运行的节点进行调度,其目的在于将相同service的POD 对象放置与同一个或同一类节点上以提高效率,此预选此类试图将那些在其节点选择器中带有特定标签的POD资源调度至拥有同样标签的节点上,具体的标签则取决于用户的定义。默认没有启用。
3 kube-Scheduler之优选算法
3.1 总体梳理
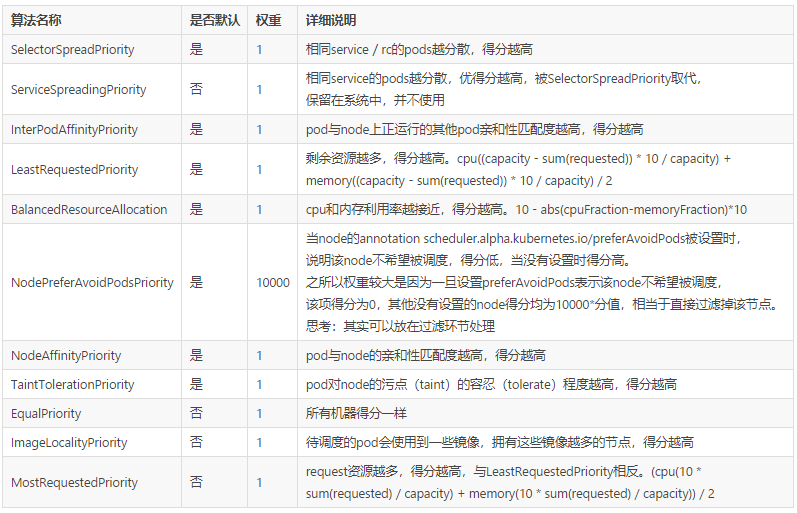
- Node 水位
- Pod 打散 (topp,service,controller) 分配到这个节点之后空闲的资源数,比如:Pod 打散为了解决的问题为:支持符合条件的一组 Pod 在不同 topology 上部署的 spread 需求。
- Node 亲和&反亲和
- Pod 亲和&反亲和
3.2 打分规则
- 资源水位公式的概念:Request:Node 已经分配的资源;Allocatable:Node 的可调度的资源。
- 优先打散:把 Pod 分到资源空闲率最高的节点上,而非空闲资源最大的节点,公式:资源空闲率 = (Allocatable - Request) / Allocatable,当这个值越大,表示分数越高,优先分配到高分数的节点。其中 (Allocatable - Request) 表示为 Pod 分配到这个节点之后空闲的资源数。
- 优先堆叠:把 Pod 分配到资源使用率最高的节点上,公式:资源使用率 = Request / Allocatable ,资源使用率越高,表示得分越高,会优先分配到高分数的节点。
- 碎片率:是指 Node 上的多种资源之间的资源使用率的差值,目前支持 CPU/Mem/Disk 三类资源, 假如仅考虑 CPU/Mem,那么碎片率的公式 = Abs[CPU(Request / Allocatable) - Mem(Request / Allocatable)] 。举一个例子,当 CPU 的分配率是 99%,内存的分配率是 50%,那么碎片率 = 99% - 50% = 50%,那么这个例子中剩余 1% CPU, 50% Mem,很难有这类规格的容器能用完 Mem。得分 = 1 - 碎片率,碎片率越高得分低。
- 指定比率:可以在 Scheduler 启动的时候,为每一个资源使用率设置得分,从而实现控制集群上 node 资源分配分布曲线。
3.2 核心算法剖析
3.2.1 Pod 打散
- SelectorSpreadPriority:用于实现 Pod 所属的 Controller 下所有的 Pod 在 Node 上打散的要求。实现方式是这样的:它会依据待分配的 Pod 所属的 controller,计算该 controller 下的所有 Pod,假设总数为 T,对这些 Pod 按照所在的 Node 分组统计;假设为 N (表示为某个 Node 上的统计值),那么对 Node上的分数统计为 (T-N)/T 的分数,值越大表示这个节点的 controller 部署的越少,分数越高,从而达到 workload 的 pod 打散需求。
- ServiceSpreadingPriority:官方注释上说大概率会用来替换 SelectorSpreadPriority,为什么呢?我个人理解:Service 代表一组服务,我们只要能做到服务的打散分配就足够了。
- EvenPodsSpreadPriority:用来指定一组符合条件的 Pod 在某个拓扑结构上的打散需求,这样是比较灵活、比较定制化的一种方式,使用起来也是比较复杂的一种方式。因为这个使用方式可能会一直变化,我们假设这个拓扑结构是这样的:Spec 是要求在 node 上进行分布的,我们就可以按照上图中的计算公式,计算一下在这个 node 上满足 Spec 指定 labelSelector 条件的 pod 数量,然后计算一下最大的差值,接着计算一下 Node 分配的权重,如果说这个值越大,表示这个值越优先。
3.2.2 Pod 亲和&反亲和
- NodeAffinityPriority,这个是为了满足 Pod 和 Node 的亲和 & 反亲和;
- ServiceAntiAffinity,是为了支持 Service 下的 Pod 的分布要按照 Node 的某个 label 的值进行均衡。比如:集群的节点有云上也有云下两组节点,我们要求服务在云上云下均衡去分布,假设 Node 上有某个 label,那我们就可以用这个 ServiceAntiAffinity 进行打散分布;
- NodeLabelPrioritizer,主要是为了实现对某些特定 label 的 Node 优先分配,算法很简单,启动时候依据调度策略 (SchedulerPolicy)配置的 label 值,判断 Node 上是否满足这个label条件,如果满足条件的节点优先分配;
- ImageLocalityPriority,节点亲和主要考虑的是镜像下载的速度。如果节点里面存在镜像的话,优先把 Pod 调度到这个节点上,这里还会去考虑镜像的大小,比如这个 Pod 有好几个镜像,镜像越大下载速度越慢,它会按照节点上已经存在的镜像大小优先级亲和。
3.2.3 Pod 亲和&反亲和
- InterPodAffinityPriority:先介绍一下使用场景:第一个例子,比如说应用 A 提供数据,应用 B 提供服务,A 和 B 部署在一起可以走本地网络,优化网络传输;第二个例子,如果应用 A 和应用 B 之间都是 CPU 密集型应用,而且证明它们之间是会互相干扰的,那么可以通过这个规则设置尽量让它们不在一个节点上。pod亲和性选择策略,类似NodeAffinityPriority,提供两种选择器支持:requiredDuringSchedulingIgnoredDuringExecution(保证所选的主机必须满足所有Pod对主机的规则要求)、preferresDuringSchedulingIgnoredDuringExecution(调度器会尽量但不保证满足NodeSelector的所有要求),两个子策略:podAffinity和podAntiAffinity
- NodePreferAvoidPodsPriority:用于实现某些 controller 尽量不分配到某些节点上的能力;通过在 node 上加 annotation 声明哪些 controller 不要分配到 Node 上,如果不满足就优先。
3.2.4 增强策略
- LeastRequestedPriority:如果新的pod要分配给一个节点,这个节点的优先级就由节点空闲的那部分与总容量的比值(即(总容量-节点上pod的容量总和-新pod的容量)/总容量)来决定。CPU和memory权重相当,比值最大的节点的得分最高。需要注意的是,这个优先级函数起到了按照资源消耗来跨节点分配pods的作用。计算公式如下: cpu((capacity – sum(requested)) * 10 / capacity) + memory((capacity – sum(requested)) * 10 / capacity) / 2
- BalancedResourceAllocation:尽量选择在部署Pod后各项资源更均衡的机器。BalancedResourceAllocation不能单独使用,而且必须和LeastRequestedPriority同时使用,它分别计算主机上的cpu和memory的比重,主机的分值由cpu比重和memory比重的“距离”决定。计算公式如下: score = 10 – abs(cpuFraction-memoryFraction)*10
- MostRequestedPriority:动态伸缩集群环境比较适用,会优先调度pod到使用率最高的主机节点,这样在伸缩集群时,就会腾出空闲机器,从而进行停机处理。
3.2.5 备注
已注册但默认不加载的Priorites策略有:
EqualPriority
ImageLocalityPriority
MostRequestedPriority
PS:此外还有个ServiceSpreadingPriority策略(计划停用),由SelectorSpreadPriority替代
3 总结
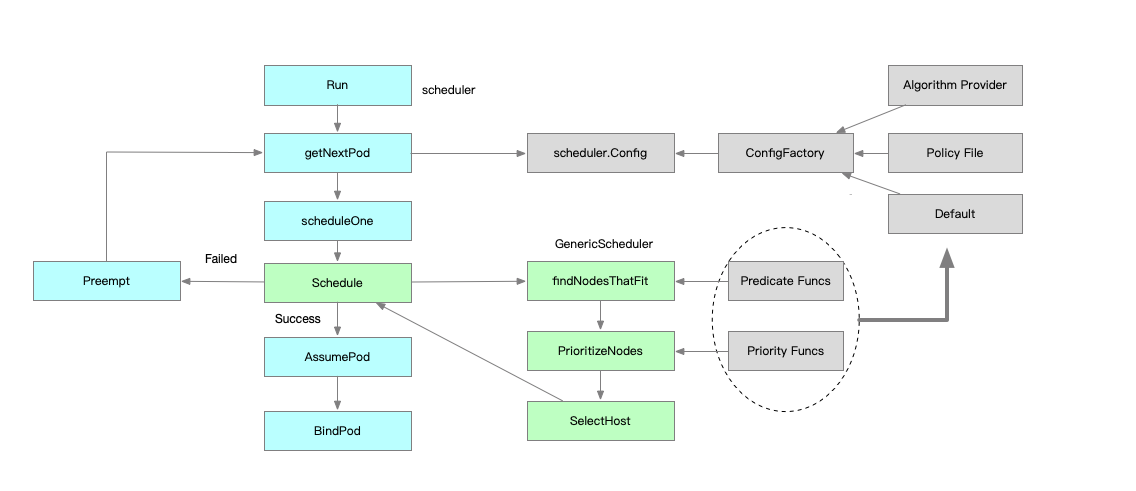
-
预选 Predicates,挑选出符合调度条件的 Node 列表
-
优选 Prioritizing,从已经选择出来的 Node 列表中按照一定的算法选择出最优匹配的 Node,设置 Pod 对应的 NodeN
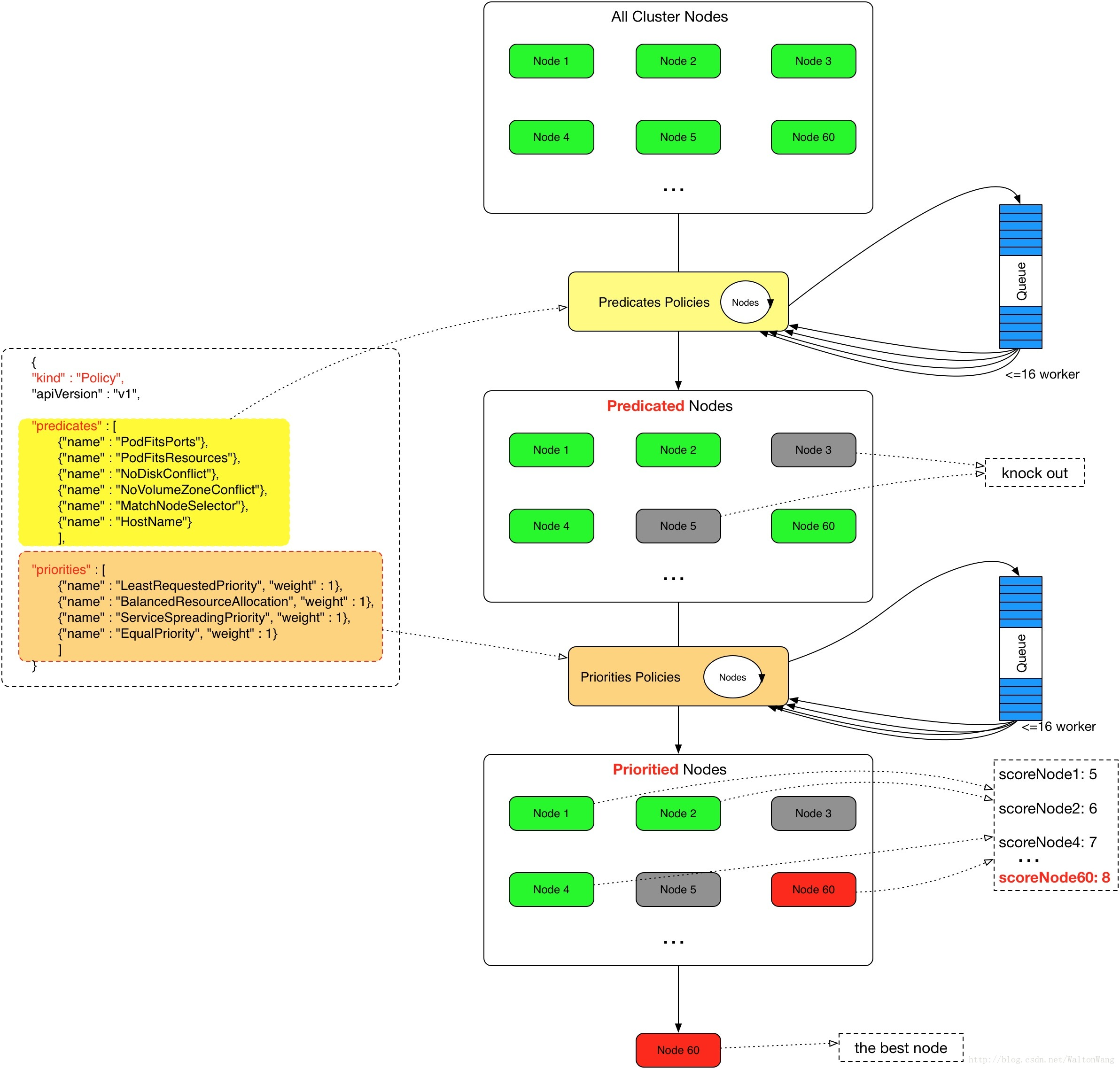
来源https://ggaaooppeenngg.github.io/zh-CN/2017/09/26/kubernetes-%E6%8C%87%E5%8C%97/Schedule.jpeg
专注于大数据及容器云核心技术解密,可提供全栈的大数据+云原生平台咨询方案,请持续关注本套博客。如有任何学术交流,可随时联系。更多内容请关注《数据云技术社区》公众号。
