

前言
今天天气不错,我怀着自信的笑容来到某个大厂的研发中心,开启面试的一天。首先我不是毫无准备的,什么java并发,多线程,jvm,分布式,数据库都准备的妥妥的,没想到今天的面试的主题是spring。不过还好,我也准备了...门开了,走来一位拿着mac本,戴眼镜的年轻的小伙子,跟我差不多大吧。然后他示意我坐下,礼貌的说:“欢迎来我们公司面试,今天我们就聊聊spring吧”...
面试环节
-
面试官:你说下什么是spring?
-
我:spring是一种轻量级开发框架,旨在提高开发人员的开发效率以及系统的可维护性。我们一般说的spring框架指的是Spring Framework,它是很多模块的集合,使用这些模块可以很方便的协助我们开发。这些模块是:核心容器、数据访问/集成、Web、AOP(面向切面编程)、工具、消息和测试模块。比如:Core Container中的Core组件是Spring所有组件的核心,Beans组件和Context组件是实现IOC和依赖注入的基础,AOP组件用来实现面向切面编程。
-
面试官:使用Spring框架有什么好处呢?
-
我:框架能更让我们高效的编程以及更方便的维护我们的系统。
- 轻量:Spring是轻量的,相对其他框架来说。
- 控制反转:Spring通过控制反转实现了松散耦合,对象给出他们的依赖,而不是创建或查找依赖的对象们。
- 面向切面编程(AOP):Spring支持面向切面编程,并且把业务逻辑和系统服务分开。
- 容器:Spring包含并管理应用中对象的生命周期和配置。
- MVC框架:Spring的WEB框架是个精心设计的框架,是WEB框架的一个很好的替代品。
- 事务管理:Spring提供一个持续的事务管理接口,提供声明式事务和编程式事务。
- 异常处理:Spring提供方便的API把具体技术相关的异常转化为一致的unchecked异常。
- 面试官:你第二点提到了spring的控制反转,能解释下吗?
- 我:首先来解释下控制反转。控制反转(Inversion Of Control,缩写为IOC)是一个重要的面向对象编程的法则来削减程序的耦合问题,也是spring框架的核心。应用控制反转,对象在被创建的时候,由一个调控系统内的所有对象的外界实体,将其所依赖的对象的引用,传递给它。也可以说,依赖被注入到对象中。所以,控制反转是关于一个对象如何获取他所依赖的对象的引用,这个责任的反转。另外,控制反转一般分为两种类型,依赖注入(Dependency Injection,简称DI)和依赖查找(Dependency Lookup)。依赖注入应用比较广泛。
还有几个常见的问题:
- 谁依赖谁-当然是应用程序依赖于IOC容器。
- 为什么需要依赖-应用程序需要IOC容器来提供对象需要的外部资源。
- 谁注入谁-很明显是IOC容器注入应用程序某个对象,应用程序依赖的对象
- 注入了什么-就是注入某个对象所需要的外部资源(包括对象、资源、常量数据)
-
面试官:那IOC与new对象有什么区别吗
-
我:这就是正转与反转的区别。传统应用程序是由我们自己在对象中主动控制去直接获取依赖对象,也就是正转。而反转则是容器来帮助我们创建并注入依赖对象。
-
面试官:好的,那IOC有什么优缺点吗?
-
我:优点:很明显,实现了组件之间的解耦,提高程序的灵活性和可维护性。缺点:对象生成因为是反射编程,在效率上有些损耗。但相对于IOC提高的维护性和灵活性来说,这点损耗是微不足道的,除非某对象的生成对效率要求特别高。
-
面试官:spring管理这么多对象,肯定需要一个容器吧。你能说下对IOC容器的理解吗?
-
我:首先来解释下容器:在每个框架中都有个容器的概念,所谓的容器就是将常用的服务封装起来,然后用户只需要遵循一定的规则就可以达到统一、灵活、安全、方便和快速的目的。
-
我:然后IOC容器是具有依赖注入功能的容器,负责实例化、定位、配置应用程序中的对象以及建立这些对象间的依赖。
-
面试官:那你能说下IOC容器是怎么工作的吗?
-
我:首先说下两个概念。
- Bean的概念:Bean就是由Spring容器初始化、装配及管理的对象,除此之外,bean就与应用程序中的其他对象没什么区别了。
- 元数据BeanDefinition:确定如何实例化Bean、管理bean之间的依赖关系以及管理bean,这就需要配置元数据,在spring中由BeanDefinition代表。
- 我:下面说下工作原理:
- 准备配置文件:配置文件中声明Bean定义也就是为Bean配置元数据。
- 由IOC容器进行解析元数据:IOC容器的Bean Reader读取并解析配置文件,根据定义生成BeanDefinition配置元数据对象,IOC容器根据BeanDefinition进行实例化、配置以及组装Bean。
- 实例化IOC容器:由客户端实例化容器,获取需要的Bean。
下面举个例子:
@Test
public void testHelloWorld() {
//1、读取配置文件实例化一个IoC容器
ApplicationContext context = new ClassPathXmlApplicationContext("helloworld.xml");
//2、从容器中获取Bean,注意此处完全“面向接口编程,而不是面向实现”
HelloApi helloApi = context.getBean("hello", HelloApi.class);
//3、执行业务逻辑
helloApi.sayHello();
}
- 面试官:那你知道BeanFactory和ApplicationContext的区别吗?
- 我:
- BeanFactory是spring中最基础的接口。它负责读取读取bean配置文档,管理bean的加载,实例化,维护bean之间的依赖关系,负责bean的生命周期。
- ApplicationContext是BeanFactory的子接口,除了提供上述BeanFactory的所有功能外,还提供了更完整的框架功能:如国际化支持,资源访问,事件传递等。常用的获取ApplicationContext的方法: 2.1 FileSystemXmlApplicationContext:从文件系统或者url指定的xml配置文件创建,参数为配置文件名或者文件名数组。 2.2 ClassPathXmlApplicationContext:从classpath的xml配置文件创建,可以从jar包中读取配置文件 2.3 WebApplicationContextUtils:从web应用的根目录读取配置文件,需要先在web.xml中配置,可以配置监听器或者servlet来实现。
- ApplicationContext的初始化和BeanFactory有一个重大区别:BeanFactory在初始化容器时,并未实例化Bean,知道第一次访问某个Bean时才实例化Bean;而ApplicationContext则在初始化应用上下文时就实例化所有的单例Bean,因此ApplicationContext的初始化时间会比BeanFactory稍长一些。
- 面试官:很好,看来对spring的IOC容器掌握的不错。那我们来聊聊spring的aop,你说下你对spring aop的了解。
- 我:Aop(面向切面编程)能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的扩展性和可维护性。这里聚个日志处理的栗子:
| 日志处理方式 | 实现方式 | 优缺点 |
|---|---|---|
| 硬代码编写 | ||
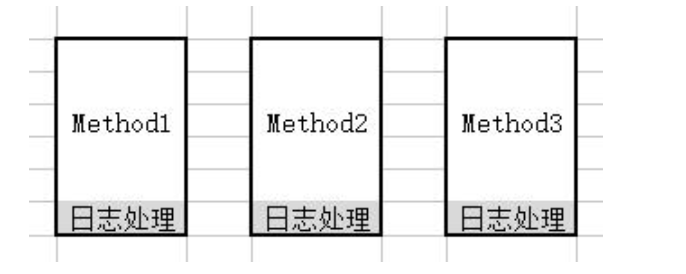 |
处理代码相同,代码强耦合 | |
| 抽离方法,代码复用 | ||
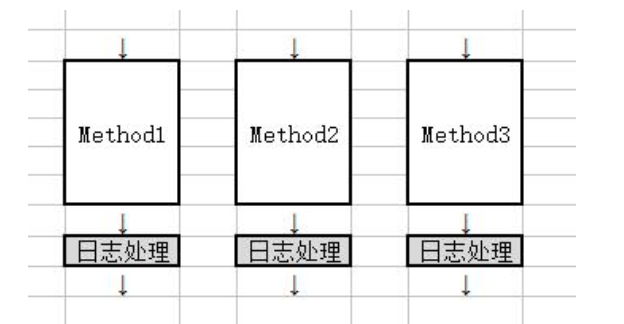 |
手动插入代码,代码强耦合 | |
| aop | ||
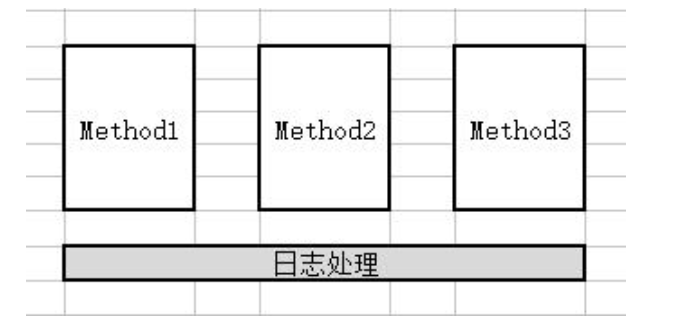 |
横向的功能抽离出来形成一个独立的模块,低耦合 |
-
面试官:那你知道spring aop的原理吗?
-
我:spring aop就是基于动态代理的,如果要代理的对象实现了某个接口,那么spring aop会使用jdk proxy,去创建代理对象,而对于没有实现接口的对象,就无法使用jdk的动态代理,这时spring aop会使用cglib动态代理,这时候spring aop会使用cglib生成一个被代理对象的子类作为代理。
-
我:关于动态代理的原理可以参考我的这篇文章:juejin.cn/post/684490…
-
面试官:那你知道Spring Aop和AspecJ Aop有什么区别吗?
-
我:Spring AOP属于运行时增强,而AspectJ是编译时增强。Spring Aop基于代理,而AspectJ基于字节码操作。Spring Aop已经集成了AspectJ,AspectJ应该算得上Java生态系统中最完整的AOP框架了。AspectJ相对于Spring Aop功能更加强大,但是Spring AOP相对来说更简单。如果我们的切面比较少,那么两者性能差异不大。但是,当且切面太多的话,最好选择AspectJ,它比Spring Aop快很多。
-
面试官:你对Spring中的bean了解吗?都有哪些作用域?
-
我:Spring中的Bean有五种作用域:
- singleton:唯一Bean实例,Spring中的Bean默认都是单例的。
- prototype:每次请求都会创建一个新的bean实例。
- request:每次HTTP请求都会产生一个新的Bean,该Bean仅在当前HTTP request内有效。
- session:每次HTTP请产生一个新的Bean,该Bean仅在当前HTTP session内有效。
- global-session:全局session作用域,仅仅在基于portlet的web应用中才有意义,Spring5已经没有了。
- 面试官:Spring中的单例Bean的线程安全问题了解吗?
- 我:大部分时候我们并没有在系统中使用多线程。单例Bean存在线程安全问题,主要是因为当多个线程操作同一个对象的时候,对这个对象的非静态成员变量的写操作会存在线程安全问题。常见的有两种解决方法:
- 在Bean中尽量避免定义可变的成员变量(不太现实)。
- 在类中定义一个ThreadLocal成员变量,将需要的可变成员变量保存在Threadlocal中。
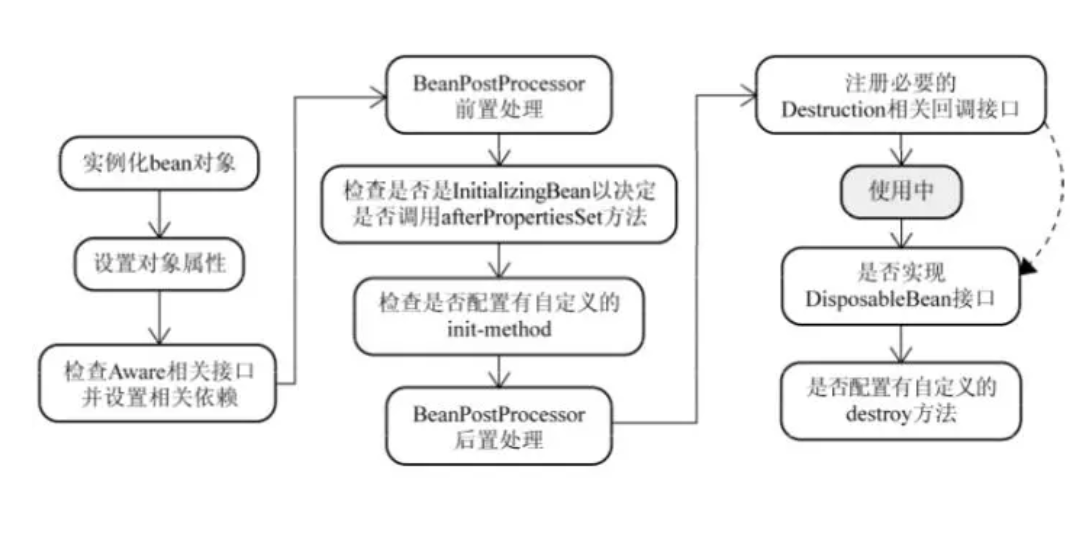
- 面试官:Spring中的Bean的生命周期你了解吗?
- (我心想,这个过程还挺复杂的,还好来之前小本本记了。)Spring中的Bean从创建到销毁大概会经过这些:
- Bean容器找到配置文件中Spring Bean的定义。
- Bean容器利用Java反射机制创建一个Bean的实例。
- 如果涉及一些属性值,利用set()方法设置一些属性值。
- 如果Bean实现了BeanNameAware接口,调用setBeanName()方法,传入Bean的名称。
- 如果Bean实现了BeanClassLoaderAware接口,调用setBeanClassLoader()方法,传入ClassLoader对象的实例。
- 如果Bean实现了BeanFactoryAware接口,调用setBeanClassLoader()方法,传入ClassLoader对象的实例。
- 与上面类似,如果实现了其他*.Aware接口,就调用相应的方法。
- 如果有和加载这个Bean的Spring容器相关的BeaPostProcessor对象,执行postProcessBeforeInitialization()方法
- 如果Bean实现了InitializingBean接口,执行afterPropertiesSet()方法
- 如果Bean在配置文件中的定义包含init-method属性,执行指定的方法。
- 如果有和加载这个 Bean的 Spring 容器相关的 BeanPostProcessor 对象,执行postProcessAfterInitialization() 方法
- 当要销毁Bean的时候,如果 Bean 实现了 DisposableBean 接口,执行 destroy() 方法。
- 当要销毁 Bean 的时候,如果 Bean 在配置文件中的定义包含 destroy-method 属性,执行指定的方法。
- 面试官:将一个类声明为Spring的Bean的注解有哪些你知道吗?
- 我:我们一般用@Autowried注解自动装配Bean,要想把类识别为可用于自动装配的Bean,采用以下注解可以实现:
- @Component:通用的注解,可标注任意类为spring组件。如果一个Bean不知道属于哪个层,可以使用@Component注解标注
- @Repository:对应持久层即Dao层,主要用于数据库的操作。
- @Service:对应服务层,主要涉及一些复杂的逻辑
- @Controller:对应Spring MVC控制层,主要用于接收用户请求并调用Service层返回数据给前端页面。
- 面试官:那@Component和@Bean有什么区别呢?
- 我:那我来总结下:
- 作用对象不同:@Component作用于类,@Bean作用于方法。
- @Component通常是通过类路径扫描来自动侦测以及自动装配到Spring容器中(使用@ComponentScan注解定义要扫描的路径从中找出识别了需要装配的类自动装配到spring的Bean容器中)。@Bean注解通常是在标有该注解的方法中定义产生这个bean,@Bean告诉Spring这是某个类的实例,当我需要用它的时候还给我。
- @Bean注解比@Component注解的自定义性更强,而且很多地方只能通过@Bean注解来注册Bean,比如第三方库中的类。
- 面试官:看来你对Spring的bean掌握的不错,那你能说下自己对于spring MVC的了解吗?
- 我:谈到这个问题,不得不说下Model1和Model2这两个没有spring MVC的时代。
- Model1时代:整个Web应用几乎都是JSP页面组成,只用少量的JavaBean来处理数据库连接,访问等操作。这个模式下JSP既是控制层又是表现层。显而易见这种模式存在很多问题:比如讲控制层和表现层逻辑混杂在一起,导致代码重用率极低;前后端相互依赖,难以进行测试并且开发效率极低。
- Model2时代:学过Servlet的朋友应该了解“Java Bean(Model)+JSP(VIEW)+Servlet(Controller)”这种开发模式就是早期的JavaWeb开发模式。Model2模式下还存在很多问题,抽象和封装程度还远远不够,使用Model2进行开发时不可避免的会重复造轮子。
- 我想了想,接着说:MVC是一种设计模式,Spring MVC是一款很优秀的MVC框架。Spring MVC可以帮助我们进行更简洁的Web层的开发,并且它天生与Spring框架集成。Spring MVC下我们一般把后端项目分为Service层(处理业务)、Dao层(数据库操作)、Entity层(实体类)、Controller层(控制层、返回数据给前端)。我画个Spring MVC的简单原理图:
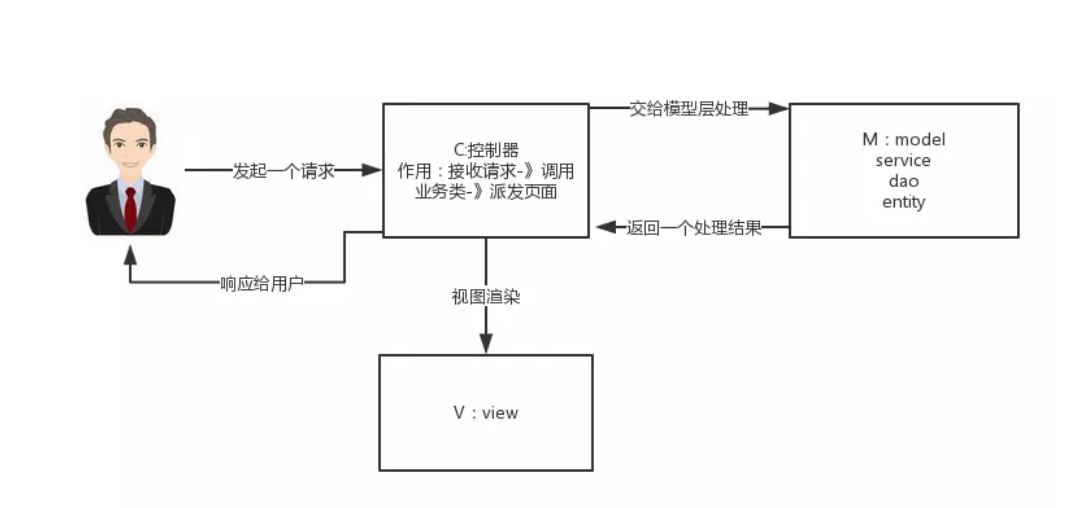
- 面试官:你能详细说下Spring MVC从接受请求到返回数据的整个流程吗?
- (我心想:幸好我还没忘)我:可以。这个流程虽然复杂,但是理解起来也不是很难。
- 客户端(浏览器)发送请求,直接请求到DispatcherServlet。
- DispatcherServlet根据请求细腻调用HandlerMapping,解析请求对应的Handler。
- 解析到对应的Handler(也就是Controller)后,开始由HandlerAdapter适配器处理。
- HandlerAdapter会根据Handler来调用真正的处理器来处理请求,并处理相应的业务逻辑。
- 处理器处理完业务后,会返回一个ModelAndView对象,Model是返回的数据对象,View是个逻辑上的View。
- ViewResolver会根据View查找实际的View。
- DispatcherServlet把返回的Model传给View(视图渲染)。
- 把View返回给请求者(浏览器)。
- 面试官:你知道Spring框架中用到了哪些设计模式吗?
- 我:那我来总结一下。
- 工厂设计模式:Spring使用工厂模式通过BeanFactory、ApplicationContext创建Bean对象。
- 代理设计模式:Spring AOP功能的实现。
- 单例设计模式:Spring中的Bean默认都是单例的。
- 模板方法模式:Spring中jdbcTemplate、hibernateTemplate等以Template结尾的对数据库操作的类,就是用到了模板模式。
- 包装器设计模式:我们的项目需要链接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户需求都太切换不同的数据源。
- 观察者模式:Spring事件驱动模型就是观察者模式很经典的一个应用。
- 适配器模式:Spring AOP的增强或通知使用到了适配器模式。SpringMVC中也是用到了适配器模式适配Controller。
- 面试官:你使用过Spring的事务吗?是怎么用的?
- 我:当然用过。Spring管理事务有两种方式:
- 编程式事务:在代码中硬编码(不推荐使用)
- 声明式事务:在配置文件中配置,声明式事务又分为两种:基于XML的方式和基于注解的方式(推荐使用) 在项目中使用Spring的事务只需要在你需要事务的方法上加上@Transaction注解,那么这个方法就加上了事务,如果遇到异常,整个方法中的数据修改的逻辑都会被回滚掉,避免造成数据的不一致性。
- 面试官:那Spring的事务有哪几种隔离级别?
- 我:TransactionDefinition接口中定义了五个隔离级别的常量:
- ISOLATION_DEFAULT:使用后端数据库默认的隔离级别(一般用这个就好了),MySQL默认采用的是REPEATABLE_READ隔离级别,Oracle默认采用的是READ_COMMITTED隔离级别。
- ISOLATION_READ_UNCOMMITTED:最低的隔离级别,允许读取尚未提交的数据,可能导致脏读、幻读或不可重复读。
- ISOLATION_READ_COMMITTED:允许读取并发事务以及提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
- ISOLATION_REPEATABLE_READ:对同一字段的多次读取结果都是一致的,除非数据是被事务自己修改的,可以阻止脏读和不可重复读,但幻读仍有可能发生。
- ISOLATION_SERIALIZABLE:最高的隔离级别,所有事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读和幻读。但是这将严重影响程序性能,通常也不会用到。
- 面试官:那你知道Spring事务有哪几种事务传播行为吗?(面试官露出神秘的一笑)
- 我:(心想:Spring事务中这里的坑踩的最多,怎么会不清楚呢)在TransactionDefinition中定义了7种事务传播行为: 支持当前事务的情况
- PROPAGATION_REQUIRED:如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
- PROPAGATION_SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
- PROPAGATION_MANDATORY:如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常(mandatory:强制) 不支持当前事务的情况
- PROPAGATION_REQUIRES_NEW:创建一个新的事务,如果当前存在事务,则把当前事务挂起。
- PROPAGATION_NOT_SUPPORTED:以非事务的方式运行,如果当前存在事务,则把当前事务挂起。
- PROPAGATION_NEVER:以非事务的方式运行,如果当前存在事务,则抛出异常。 其他情况
- PROPAGATION_NESTED:如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于PROPAGATION_REQUIRED。
- 我:一篇有价值的博客,列举了Spring事务不生效的几大原因https://blog.csdn.net/f641385712/article/details/80445933。这里我列举一下:
- 原因1:是否是数据库引擎设置不对造成的。比如我们常用的mysql,引擎MyISAM,是不支持事务操作的,需要改成InnoDB才能支持。
- 原因2:入口的方法必须是public,否则事务不起作用(这一点由Spring的AOP特性决定)private方法,final方法和static方法不能添加事务,加了也不生效。
- 原因3:Spring事务管理默认只对出现运行时异常(kava.lang.RuntimeException及其子类)进行回滚(至于Spring为什么这么设计:因为Spring认为Checked异常属于业务,程序员应该给出解决方案而不应该直接扔给框架)。
- 原因4:@EnableTransactionManagement // 启注解事务管理,等同于xml配置方式的 <tx:annotation-driven />。没有使用该注解开启事务。
- 原因5:请确认你的类是否被代理了。(因为Spring的事务实现原理是AOP,只有通过代理对象调用方法才能被拦截,事务才能生效)。
- 原因6:请确保你的业务和事务入口在同一个线程里,否则事务也是不生效的,比如下面的代码:
@Transactional
@Override
public void save(User user1, User user2) {
new Thread(() -> {
saveError(user1, user2);
System.out.println(1 / 0);
}).start();
}
- 原因7:同一个类中一个无事务的方法调用另一个有事务的方法,事务是不会起作用的。例如下面的代码:

- 面试官:看来你对spring框架的重点知识掌握的还不错,基础很扎实,今天我们就先聊到这里,希望明天你能表现的更好。
- 我微笑着说:(暗自庆幸:通过了一关是一关)嗯,我会好好准备的。
