

linux服务器性能调试命令
watch
命令格式
watch 参数
命令功能
可以将命令的输出结果输出到标准输出设备,多用于周期性执行命令/定时执行命令
命令参数
-n或--interval watch缺省每2秒运行一下程序,可以用-n或-interval来指定间隔的时间。
-d或--differences 用-d或--differences 选项watch 会高亮显示变化的区域。 而-d=cumulative选项会把变动过的地方(不管最近的那次有没有变动)都高亮显示出来。
-t 或-no-title 会关闭watch命令在顶部的时间间隔,命令,当前时间的输出。
案例
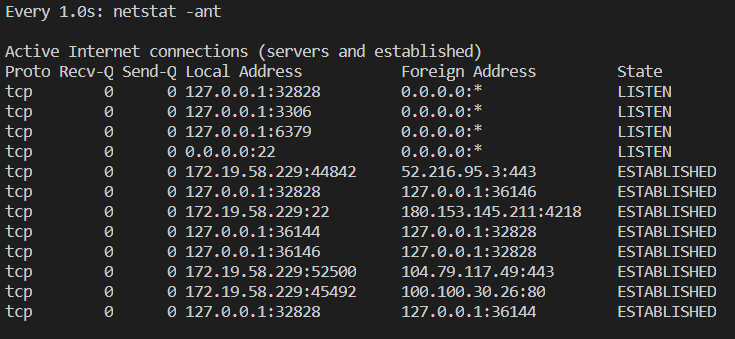
watch -n 1 -d netstat -ant 说明:每隔一秒高亮显示网络连接数的变化情况

htop
命令格式
htop [参数]
命令功能
htop 是 Linux 系统中的一个互动的进程查看器
命令参数
-C --no-color 使用一个单色的配色方案(设置界面为无颜色)
-d --delay=DELAY 设置延迟更新时间,单位秒(设置刷新时间,单位为秒)例如,htop -d 100 命令会使输出在1秒后才会刷新(参数 -d 的单位是10微秒)。
-h --help 显示htop 命令帮助信息
-u --user=USERNAME 只显示一个给定的用户的过程(显示指定用户的进程)例如,htop -u root 命令会只显示出用户名为 root 的相关进程。
-p --pid=PID,PID… 只显示给定的PIDs
-s --sort-key COLUMN 依此列来排序(以指定的列排序)。例如,htop -s PID 命令会按 PID 列的大小排序来显示。
-v –version 显示版本信息
案例
htop
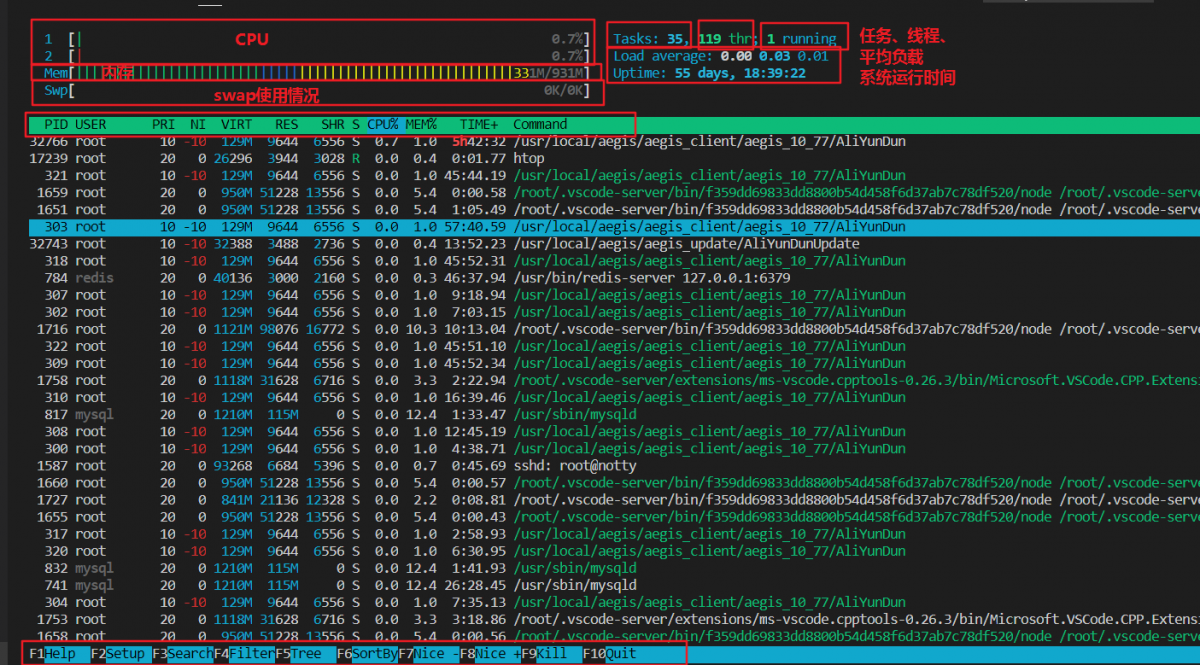
PID:进程标志号,是非零正整数USER:进程所有者的用户名PR:进程的优先级别NI:进程的优先级别数值VIRT:进程占用的虚拟内存值RES:进程占用的物理内存值SHR:进程使用的共享内存值S:进程的状态,其中S表示休眠,R表示正在运行,Z表示僵死状态,N表示该进程优先值是负数%CPU:该进程占用的CPU使用率%MEM:该进程占用的物理内存和总内存的百分比TIME+:该进程启动后占用的总的CPU时间COMMAND:进程启动的启动命令名称
stress
命令格式
stress <options>
命令功能
stress 命令主要用来模拟系统负载较高时的场景
命令参数
-c, --cpu N 产生 N 个进程,每个进程都反复不停的计算随机数的平方根-i, --io N 产生 N 个进程,每个进程反复调用 sync() 将内存上的内容写到硬盘上-m, --vm N 产生 N 个进程,每个进程不断分配和释放内存
--vm-bytes B 指定分配内存的大小 --vm-stride B 不断的给部分内存赋值,让 COW(Copy On Write)发生--vm-hang N 指示每个消耗内存的进程在分配到内存后转入睡眠状态 N 秒,然后释放内存,一直重复执行这个过程--vm-keep 一直占用内存,区别于不断的释放和重新分配(默认是不断释放并重新分配内存)-d, --hadd N 产生 N 个不断执行 write 和 unlink 函数的进程(创建文件,写入内容,删除文件)--hadd-bytes B 指定文件大小-t, --timeout N 在 N 秒后结束程序 --backoff N 等待N微妙后开始运行-q, --quiet 程序在运行的过程中不输出信息-n, --dry-run 输出程序会做什么而并不实际执行相关的操作--version 显示版本号-v, --verbose 显示详细的信息
案例
mpstat
命令格式
mpstat [-P {|ALL}] [internal [count]]命令功能
面向CPU,是实时系统监控工具。其报告与CPU的一些统计信息,这些信息存放在/proc/stat文件中。在多CPUs系统里,其不但能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息
命令参数
-P {|ALL} 表示监控哪个CPU, cpu在[0,cpu个数-1]中取值 internal 相邻的两次采样的间隔时间、 count 采样的次数,count只能和delay一起使用 当没有参数时,mpstat则显示系统启动以后所有信息的平均值。有interval时,第一行的信息自系统启动以来的平均信息。从第二行开始,输出为前一个interval时间段的平均信息。案例
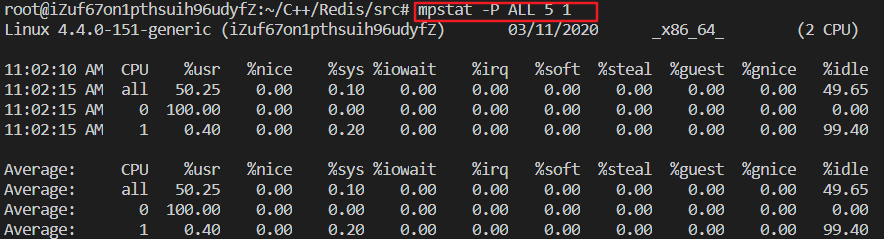
%user 在internal时间段里,用户态的CPU时间(%),不包含nice值为负进程 (usr/total)*100 %nice 在internal时间段里,nice值为负进程的CPU时间(%) (nice/total)*100 %sys 在internal时间段里,内核时间(%) (system/total)*100 %iowait 在internal时间段里,硬盘IO等待时间(%) (iowait/total)*100 %irq 在internal时间段里,硬中断时间(%) (irq/total)*100 %soft 在internal时间段里,软中断时间(%) (softirq/total)*100 %idle 在internal时间段里,CPU除去等待磁盘IO操作外的因为任何原因而空闲的时间闲置时间(%) (idle/total)*100
pidstat
命令格式
pidstat [参数] [时间] [次数]命令功能
用于监控全部或指定进程的CPU、内存、线程、设备IO等系统资源的占用情况
命令参数
-u 默认的参数,显示各个进程的CPU使用统计 -r 显示各个进程的内存使用统计 -d 显示各个进程的IO使用情况 -p 指定进程号 -w 显示每个进程的上下文切换情况 -t 显示选择任务的线程的统计信息外的额外信息案例
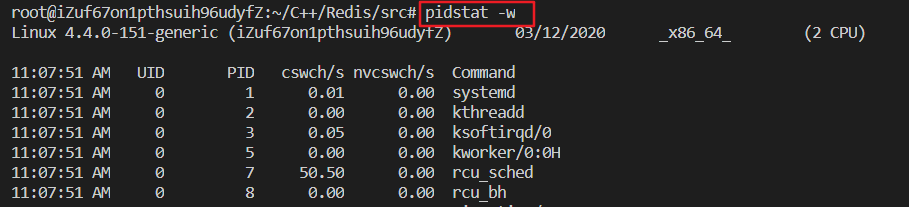
cswch:表示每秒自愿上下文切换(voluntary context switches)的次数,是指进程无法获取所需资源,导致的上下文切换。比如说, I/O、内存等系统资源不足时,就会发生自愿上下文切换。 nvcswch:表示每秒非自愿上下文切换(non voluntary context switches)的次数,是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换
`UID`:用户ID `PID`:进程ID `%usr`:进程在用户空间占用CPU的百分比 `%system`:进程在内核空间占用CPU的百分比 `%guest`:任务花费在虚拟机上的CPU使用率(运行在虚拟处理器) `%CPU`:任务总的CPU使用率 `CPU`:正在运行这个任务的处理器编号 `Command`:这个任务的命令名称
iostat
命令格式
iostat [参数] [时间] [次数]命令功能
iostat主要用于监控系统设备的IO负载情况
命令参数
-c 显示CPU使用情况 -d 显示磁盘使用情况 -k 以K为单位显示 -m 以M为单位显示 -N 显示磁盘阵列(LVM) 信息 -n 显示NFS使用情况 -p 可以报告出每块磁盘的每个分区的使用情况 -t 显示终端和CPU的信息 -x 显示详细信息案例

%user:CPU处在用户模式下的时间百分比 %nice:CPU处在带NICE值的用户模式下的时间百分比 %system:CPU处在系统模式下的时间百分比 %iowait:CPU等待输入输出完成时间的百分比 %steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比 %idle:CPU空闲时间百分比 Device:设备名称 rrqm/s:每秒合并到设备的读取请求数 wrqm/s:每秒合并到设备的写请求数 r/s:每秒向磁盘发起的读操作数 w/s:每秒向磁盘发起的写操作数 rkB/s:每秒读K字节数 wkB/s:每秒写K字节数 avgrq-sz:平均每次设备I/O操作的数据大小 avgqu-sz:平均I/O队列长度 await:平均每次设备I/O操作的等待时间 (毫秒),一般地,系统I/O响应时间应该低于5ms,如果大于 10ms就比较大了 r_await:每个读操作平均所需的时间;不仅包括硬盘设备读操作的时间,还包括了在kernel队列中等待的时间 w_await:每个写操作平均所需的时间;不仅包括硬盘设备写操作的时间,还包括了在kernel队列中等待的时间 svctm:平均每次设备I/O操作的服务时间 (毫秒)(这个数据不可信!) %util:一秒中有百分之多少的时间用于I/O操作,即被IO消耗的CPU百分比,一般地,如果该参数是100%表示设备已经接近满负荷运行了
vmstat
命令格式
vmstat 参数]
命令功能
Virtual Meomory Statistics(虚拟内存统计)的缩写,可对操作系统的虚拟内存、进程、CPU活动进行监控。是对系统的整体情况进行统计,对某个进程进行深入分析需要使用pidstat。
命令参数
-a:显示活跃和非活跃内存 -f:显示从系统启动至今的fork数量 。 -m:显示slabinfo -n:只在开始时显示一次各字段名称。 -s:显示内存相关统计信息及多种系统活动数量。 delay:刷新时间间隔。如果不指定,只显示一条结果。 count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。 -d:显示磁盘相关统计信息。 -p:显示指定磁盘分区统计信息 -S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes) -V:显示vmstat版本信息。案例

Procs(进程): r: 运行队列中进程数量 b: 等待IO的进程数量 Memory(内存): swpd: 使用虚拟内存大小 free: 可用内存大小 buff: 用作缓冲的内存大小 cache: 用作缓存的内存大小 Swap: si: 每秒从交换区写到内存的大小 so: 每秒写入交换区的内存大小 IO:(现在的Linux版本块的大小为1024bytes) bi: 每秒读取的块数 bo: 每秒写入的块数 系统: in: 每秒中断数,包括时钟中断。 cs: 每秒上下文切换数。 CPU(以百分比表示): us: 用户进程执行时间(user time) sy: 系统进程执行时间(system time) id: 空闲时间(包括IO等待时间),中央处理器的空闲时间 。以百分比表示。 wa: 等待IO时间 备注: 如果 r经常大于 4 ,且id经常少于40,表示cpu的负荷很重。 如果pi,po 长期不等于0,表示内存不足。 如果disk 经常不等于0, 且 在 b中的队列 大于3, 表示 io性能不好。
总结:以上命令一般分析CPU以及进程、磁盘IO等方面是非常有用的,而且很快找出性能问题;
几个概念:
平均负载:可运行状态+不可中断状态
CPU使用率:单位时间内CPU的使用情况
一般我们认为平均负载高于CPU数量的百分之70是属于高负载,有一定的性能问题存在;
想了解学习更多C++后台服务器方面的知识,请关注:微信公众号:====CPP后台服务器开发====





