

当前是一个流量为王的年代,优质内容成为各大内容供应方争抢流量的关键。因此,如何从每天发布的海量内容中,甄选识别出优质的潜力股,显得越来越重要。本文在微视冷启动这个场景下,对新上传短视频的潜力预测及相应的冷启流量配套做了一些初步工作和探索。
一、背景
在合适的时间把合适的内容推荐给合适的用户是推荐系统的重要目标,这个目标离不开推荐系统对用户和内容的充分理解。
但是,不可避免的,推荐系统总会迎来新用户和新内容。在没有数据积累的情况下进行推荐,就是冷启动。本文所讲的冷启动主要是指对微视新上传的短视频的冷启动。
作为一个内容分发平台,我们需要对内容保持敬畏之心,尊重和保护每一位内容生产者,让每一位用心的内容生产者都有被看见的机会,这样内容冷启动就显得至关重要。
通过冷启动,我们希望达到两个目标:
一是给予每一条内容一定数量的曝光,让创作者能够及时得到反馈,看到希望;
二是在冷启动曝光的过程中,快速定位目标用户,通过UserCF/LookaLike等推荐算法,将优质的内容投放给合适的用户。
随着用户发文量的逐渐上涨,冷启动阶段需要消耗的流量也越来越大。鉴于普通UGC内容的质量参差不齐,我们希望通过在冷启动之前对内容做一次初筛,将有限的流量向更好的内容倾斜,提升冷启动的性价比。
冷启动中的优质内容判断,涉及到对短视频的潜力预测,这是一个比较新也比较重要的问题。
当前有很多video popularity prediction相关的工作[1],这些工作多是基于外部数据和视频前期数据,预测视频的流行度趋势。由于微视冷启动的时效性要求,潜力预测需要在进入推荐池之前完成(实际使用中是对经过安审的所有短视频进行计算),此时可用的信息仅有视频本身以及上传者的一些信息。因此,短视频的潜力预测也是带有一定探索意义的工作。
二、模型方案
1. 总体结构
网络结构上,我们采用了Siamese networks[2]。Siamese网络结构拥有两条共享权值的并行输入线,训练时通过比较这两条输入线的运行结果,可以较好的利用样本之间的ranking信息。Siamese networks已经在图像相似性比较、目标检测等方面得到了较为广泛的应用。下图展现了Siamese networks的三种典型融合方式:
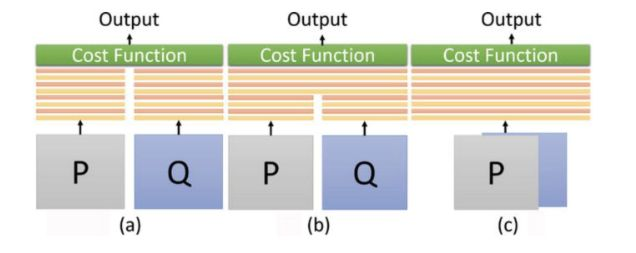
其中(a)、(b)和(c)分别表示late merge、 intermediate merge和early merge[2]。本文中,我们采用了late merge形式,优点是在单路输入的情况下可以将最后一层的输出作为视频的潜力值预测(HotValuePred),简要框架图如下:
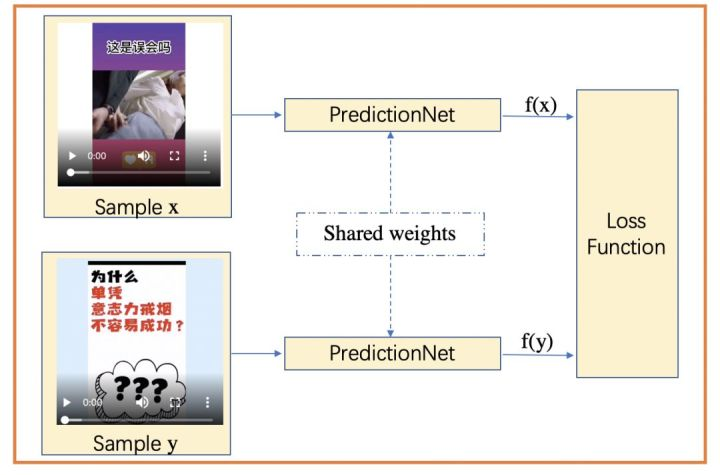
其中PredictionNet为预测子网络,f(x)、f(y)分别表示样本x、y的潜力预测值。损失函数由预测值的偏差与标签的偏差之间的关系来计算。
2. 预测子网络
如前所述,预测网络仅有视频本身以及用户的一些信息可用,因此,预测子网络的输入包括视频信息和用户信息两种。
视频信息包括图像信息和音频信息:图像信息(Image feature)的预处理模型为 efficientB3 [3]、音频信息(Audio feature)的预处理模型为vggish [4]。
上述信息经过NeXtVlad [5]后输出embedding以及微视分类的预测结果。
NeXtVlad是第2届YouTube 8M短视频分类大赛的获奖论文,相比于NetVlad,其重点压缩了编码过程中的参数量,并引入了attention和SE Context Gating等机制提高视频分类性能。
NeXtVlad基础结构如下:
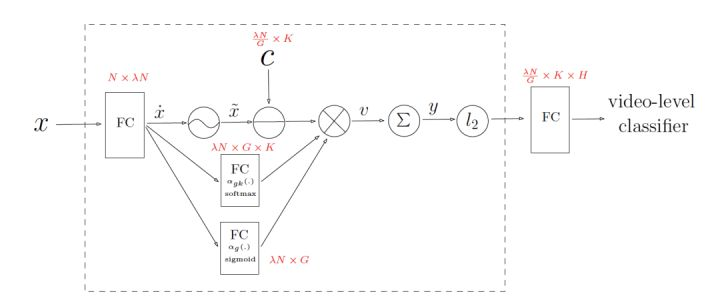
本文中视频信息部分的网络结构如下:
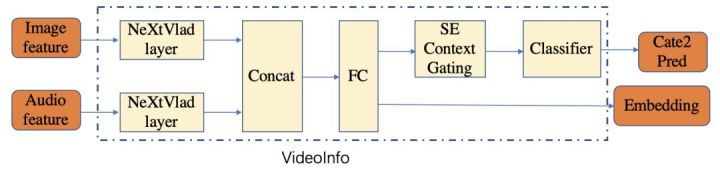
在训练的时候,我们加载了预训练好的微视短视频分类的模型,该模型由 [6]提供。
用户信息目前采用的是用户的粉丝数特征,具体包括四个维度:粉丝总数,活跃粉丝数,7日内新增粉丝数和潜在粉丝数。
结合视频信息和用户信息,预测子网络的结构表示如下:

3. 损失函数损失函数采用的是Margin loss,基本形式如下:
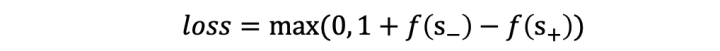
其中s+、s-分别表示正负样本。在训练过程中,我们尝试了三种形式:
- 1. 根据视频VV大小划分正负样本:负样本要求VV<Thres0,正样本要求VV>Thres1;
- 2. 根据样本对的VV比值定义正负样本,要求VV(s+)/VV(s-)>10;
- 3. 根据样本对的VV比值定义正负样本,要求VV(s+)/VV(s-)>10;同时将VV差距纳入loss计算中:
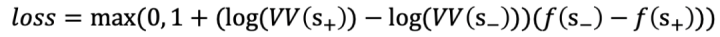
从同一批测试数据的实际结果上来看,第三种形式效果较好。
下表展示了基于三种loss训练的模型进行预测时,HotValuePred位于top20%的短视频的VV分布:
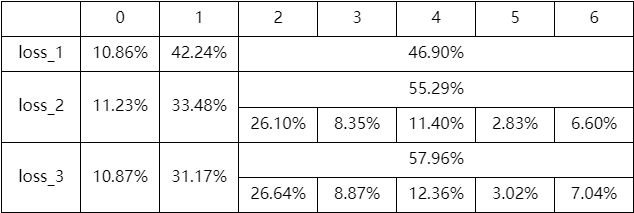
其中,第一行的0-6是基于短视频在冷启结束后的自然推荐情况下达到的VV的范围划定:数值越大,对应的VV越高。根据测试效果,线上模型采用了第三种loss。
三、应用方案
基于上述模型的预测结果,我们将短视频分成三种档位:
0档(HotValuePred位于底部40%)、2档(HotValuePred位于顶部20%)和1档(其他40%),并在三个方面进行了应用探索。
1. 优质内容发掘
微视冷启动的一个重要目标是挖掘优质视频,这可以通过给予2档更高的冷启VV来实现;同时,对预测不佳的短视频,适当减少其冷启VV,也可以节省一部分的冷启流量。
下表统计了不同档位视频经过冷启之后的自然推荐的VV分布情况:
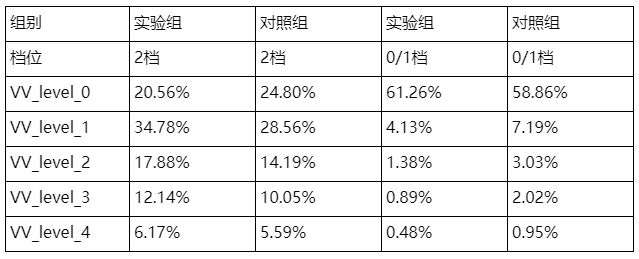
这里的VV_level_2及以上(VV_level_2+)被认为是高VV视频。
可以看出,实验组的2档视频出现优质视频(高VV视频)的比重均高于对照组,表明其发掘优质视频的能力更佳。
而实验组的0/1档视频出现高VV的几率均低于对照组,表明0/1档更难出现高VV视频,冷启性价比较低。
上述结论符合模型预期结果,也表明根据模型预测结果进行冷启效率更高。
2. 品类平衡
微视的短视频有多个品类,由于不同品类发文量不同、受众面不同等原因,这些品类的有效播放时长和消费数据等往往有着较大差异。
反映在模型中就表现为某些品类的HotValuePred整体较大,2档比例较高;某些品类预测值偏低,多为0档。
如果严格按照这个档位进行冷启,会造成品类内容头部聚集,内容池固化,不利于内容生态的多样性。为此,我们尝试将档位划定的阈值调整为:
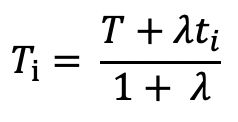
其中T是整体的阈值,ti是第i个品类内按照20%、40%、40%的比例得到的阈值,λ是参数,通过调整λ可以在整体分布和品类分布之间得到一定的平衡。
下表展示了某些品类的2档视频比重变化以及VV_level_2+优质视频比例:
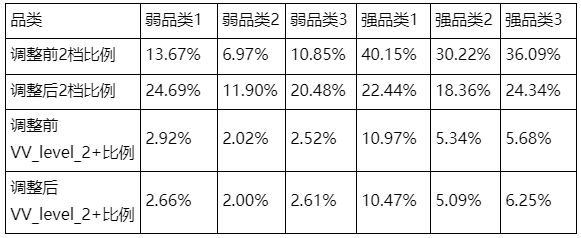
可以看到,这种方式确实可以让更多的弱品类视频进入2档得到扶持。
但从整个品类视频中出现优质视频(VV_level_2+)的比例来看,不同品类的变化情况不一。
我们将在进一步观察和优化之后扩大流量,更好地实现品类的平衡。
3. 辅助人工审核
在节假日时期尤其是即将到来的春节,微视的发文量将会引来巨量增长,这种增长会给人工审核和推荐系统带来很大的压力。
为了应对这种负载压力,更好更快地将优质视频优先分发出去,我们可以根据短视频的潜力预测结果来对发文视频采用不同的审核措施。
春节期间,我们将根据预测值对短视频进行人工审核辅助和过滤,从而有效降低系统负载,确保系统在节假日期间正常运行。
四、总结及展望
本文针对短视频的潜力预测做了一些探索性工作,并已应用在微视冷启动中,在优质视频发掘、提高冷启效率、品类平衡化和辅助人工审核等方面均有一些效果。
接下来我们会从两个方面进一步开展工作:一是拓宽输入特征,将文本特征、用户历史发文统计特征等纳入输入范围;二是探索更好的冷启动应用方式和优质账号的扶持方式。
参考文献:
[1] Y. Zhou, L. Chen, C. Yang, D. M. Chiu. Video Popularity Dynamics and Its Implication for Replication[J]. IEEE Trans. Multimedia 17(8): 1273-1285 (2015).
[2] M. Fiaz, A. Mahmood and S. K. Jung (May 13th 2019). Deep Siamese Networks toward Robust Visual Tracking [Online First], IntechOpen, DOI: 10.5772/intechopen.86235. Available from: www.intechopen.com/online-firs…。
[3] M. Tan and Q. V. Le. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks[C]. In ICML, 2019.
[5] R. Lin, J. Xiao, J. Fan. NeXtVLAD: An Efficient Neural Network to Aggregate Frame-level Features for Large-scale Video Classification[C]. In ECCV Workshops, 2018.
[6] 陈世哲. 视频embedding能力打榜方案分享,2019.
