


介绍
大家都知道,JS是一门单线程语言,所谓"单线程"就是一次只能完成一件任务。若是多个任务,就要排队执行,前面一个任务完成,后面一个任务再去执行。如果加入某个任务耗时过长,那么后面的任务就要一直等待下去,这样就会拖慢了整个程序,例如:一段死循环代码,就会使得进程卡在这。这就是同步的缺点。而解决这类问题就需要另一种任务处理方式: "异步",这种模式可以参考 ajax 、setTimeout 这类方法,调用方法后不会等到它执行完成,而是直接执行后续代码。 ajax 方法执行完成后通过状态通知主线程,或者通过回调处理 ajax 的执行结果。
背景
现在前端与后台通信,一般都是采用的异步请求的方式,这样接口互不干扰,页面各部分渲染自己的数据,就好比我们定时蒸米饭,蒸饭过程中去炒菜了,焖饭在进行,时间到了后,我们收到通知饭闷好了。目前前端主要使用 ES6 的 promise , ES7 中的 async await 去实现异步方法。
对于异步编程的核心思想,我们先了解下他的运行机制:
-
- 程序中所有同步任务都会在主线程上执行,形成一个执行栈。
-
- 在主线程之外存在一个"任务队列"。当我们的异步任务有了结果,他就会往"任务队列"中放一个事件。
-
- 当"执行栈"中的所有同步任务执行完成后,他会自动去读取"任务队列"中的事件,里面的这些事件都是等待状态的。取出对应的异步事件,结束等待状态,放入执行栈,开始执行。
-
- 主线程一直重复上面的第三步
在异步过程中有两个重要的要素,运行函数和回调函数,他们是分离的。工作线程在异步操作完成后需要通知主线程,意思大致是:工作线程将消息放到消息队列,主线程通过事件循环过程去取消息,只要主线程空了,就会去读取"任务队列"。
大家都知道异步是非阻塞模式,即发送方发出数据后,不等接收方发回响应,接着发送下个数据包的通讯方式。在目前的编程语言中,无论前端后台大数据都有异步的概念,而且你会发现他们的实现方式大同小异。借此机会,本文对 Java 、Koa 、Python 、Scala等编程语言中异步的应用做了一些理解分析,期望能够对大家理解异步思想有所帮助。
promise
看到 promise,首先想到是异步。就相对于以往简单的异步回调函数,如果多个函数存在依赖,层级多的话,我们通常可能就会写成下面的样子,这样会出现高耦合的情况,后期也很难维护。
ajax(url1, () => {
// 逻辑处理
ajax(url2, () => {
// 逻辑处理
ajax(url3, () => {
// 逻辑处理
})
})
})
Promise 相对于 Ajax 的应用,他把执行代码和处理结果的代码分离了,从而提高了代码的可读性;Promise 对于失败的任务不需要继续,直接执行错误处理函数。
但是如果使用 Promise 的话,代码就清晰了许多,Promise 译为中文是承诺的意思,所以这个承诺一旦从等待状态变成为其他状态就不能更改状态了( Pending、Fulfilled、Rejected )。
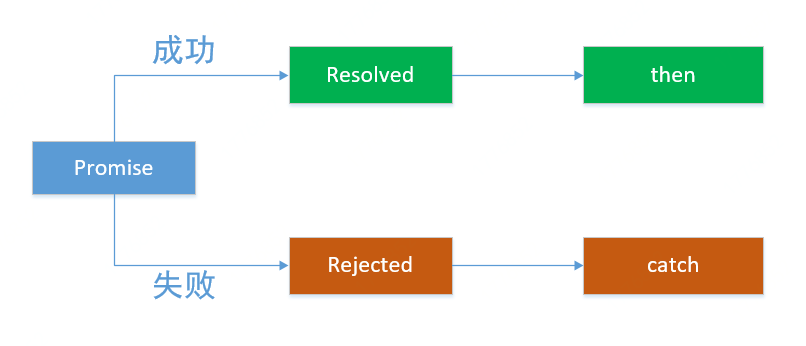
需要注意的是我们在构造 Promise 的时候,构造函数内部的代码是立即执行的。
虽然 Promise 的链式调用很爽,但是也要考虑他的弊端,就是他在执行过程中我们不能取消执行,也无法获取他的执行进度。
let demo = new Promise((resolve, reject) => {
resolve('success')
reject('reject')
})
demo.then(
value => {
console.log(value,'成功')
}
).catch(
reason => {
console.log(reason,'失败')
}
)
Promise 的方式虽然解决了回调地狱式的写法,但是代码中到处都是 then,所以执行流程不能很好的表达清楚。promise 的其他方法,如 race、all 大家应该也有用到,我在项目中使用异步加载会出现后台数据和前端渲染数据的结果,排序不一样,所以这个时候可以考虑使用Promise.all() 方法。
async/await

async ,翻译为中文是异步的意思,它是基于 Promise 实现的,使用它写出来的异步代码看起来像同步代码,这正是它的魅力所在。
async 它返回的是一个 promise 对象,所以它内部 return 语句返回的值,会成为 then 方法回调函数的参数。
async function asyncFun() {
return "I am jder"
}
asyncFun().then(r => {
console.log(r)
})
asyncFun()
我们都是把 async 和 await 一起使用,await 命令如果单独用在普通函数中会报错。async 的使用需要注意的就是它必须等到内部所有 await 命令后面的 Promise 对象执行完,才会发生状态改变,换言之就是 async 函数内部的所有异步操作都执行完成后才会执行 then 回调函数,如果遇到中途有 return 语句或者抛出错误他会终止执行函数。
是不是看完上面的一段话,会想到如果我有2个 await,如果第一个报错了,那我第二个就不能执行了啊。一般情况下,我们可以加上 try catch 防止影响后面程序的执行。
async function fn() {
try {
await Promise.reject('error');
} catch(e) {
}
return await Promise.resolve('hello jder');
}
fn().then(r => console.log(r))
// hello jder
对于这种容错处理,我们可以为 await 后面的 Promise 对象加一个 catch 方法。
async function fn() {
await Promise.reject('error').catch(e => console.log(e));
return await Promise.resolve('hello jder');
}
fn().then(r => console.log(r))
// error
// hello jder
async 函数的缺陷就是await关键字只能结合 Promise 控制异步;它无法在外面取消正在运行中的 async 函数;
说到这里,大家可能感觉这和题目没有什么联系啊,那我先给大家上个图。
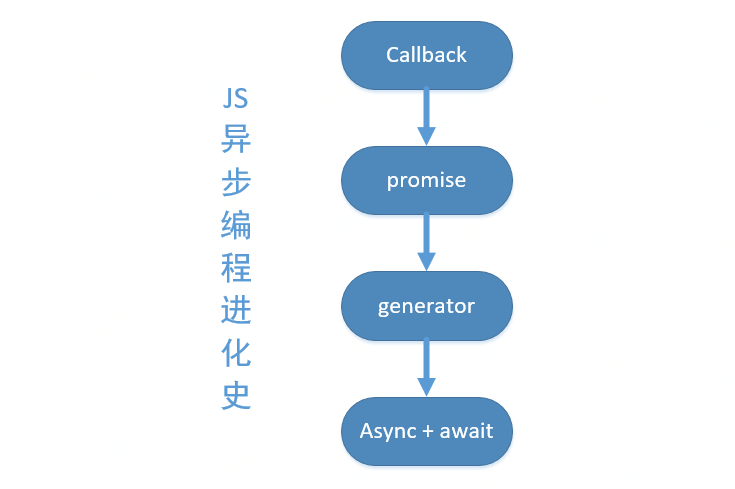
看到这个图可能会想既然 async 和 await 是目前异步编程的最新技术,那我用最新技术就好了,为何要看他上面的 generator 哪?其实 async 就是使用了 Generator 的语法糖。
Generator

在基于上面提到的 promise 的一些弊端的基础上,Generator [4] 诞生了,看过 Generator 代码的应该都有个感觉:他的异步代码看起来像是同步。我是这样理解的:它把我们的代码分成多个独立的部分,并且是可以同步的,但是这些同步不会影响函数中其他程序的运行。
在ES6中规定只要数据结构部署了 iterator 接口(迭代器),就可以完成遍历操作。即只要判断是否具有 Symbol.iterator 属性。Symbol.iterator 属性本身是函数,也是当前数据结构默认的遍历器函数(有兴趣的同学可自行查阅资料了解)。
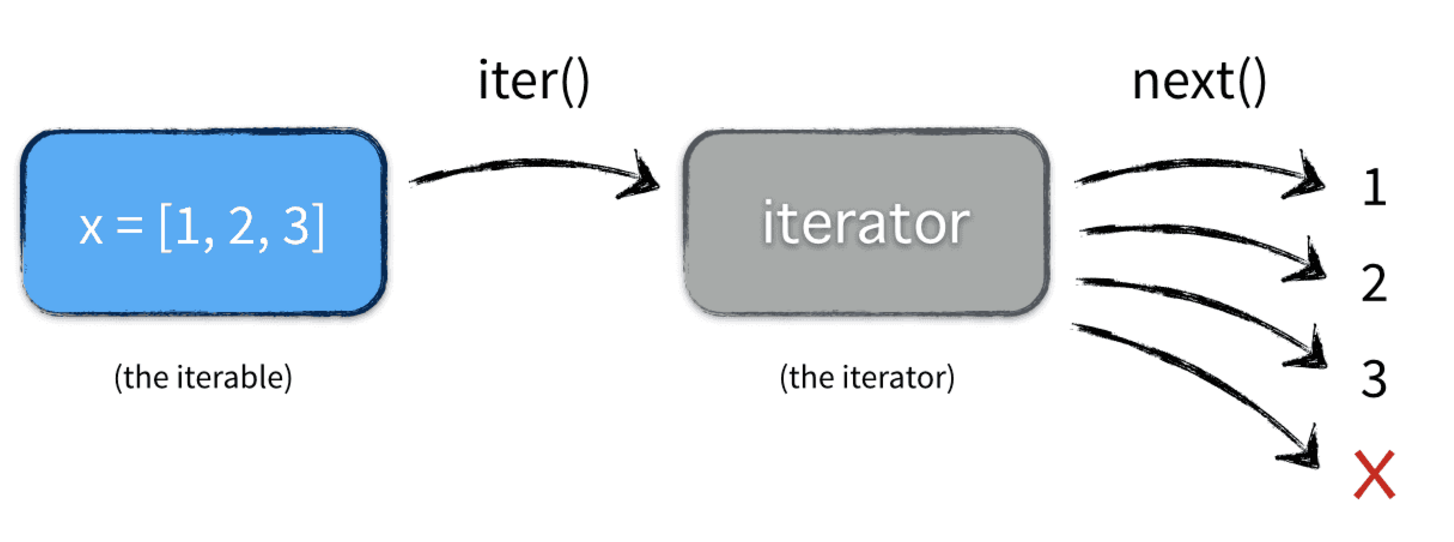
在使用 Generator 函数时,返回的是一个遍历器对象,也就是 Generator 函数的内部指针。每次调用遍历器对象的 next 方法,就会返回一个有着 value 和 done 两个属性的对象。value 属性表示当前的内部状态的值,是 yield 语句后面那个表达式的值;done 属性是布尔值,表示是否遍历结束。
function* fun() {
yield '111';
yield '222';
return 'end';
}
var gen = fun();
gen.next(); // { value: '111', done: false }
gen.next(); // { value: '222', done: false }
gen.next(); // { value: 'end', done: true }
gen.next(); // { value: undefined, done: true }
从中我们可以发现 generator 的特点,我们可以控制函数的暂停或者继续,可以返回多个值给外部,同时继续执行的时候可以传入参数。当然不好的一点就是不能自动执行,遇到 yield 会暂停。
正是这种特性,redux 的中间件 redux-saga 就利用了 generator,使用 generator 创建 saga,异步处理逻辑都放在 saga 中,使用 yield effects 来完成每一个任务。(可以关注了解redux-saga 的一些核心API)
对于 generator 中 yield,有时候我们会看到这种写法 yield* 。这种一般是在一个 generator中调用另一个 generator,可以称为 yield 委托。一般普通的 yield 使用我们在上面写过了,看到这个代码大家可能也就理解了一部分,yield* 后面接受一个 iterable Object,然后去迭代生成器。
function* fn() {
yield '1';
var n = yield* inner();
console.log(n)
yield '4';
}
function* inner() {
yield '2';
return '3';
}
var it = fn();
var v;
v = it.next().value;
console.log(v); // -> 输出:1
v = it.next().value;
console.log(v); // -> 输出:2 3
v = it.next().value;
console.log(v); // -> 输出:4
yield 委托的目的很大程度上是为了代码组织,而且这种方式是与普通函数调用对称的;将generator 分开可以增强程序的可读性,可维护性与可调试性。yield* 让出了迭代控制,不是generator 控制;当你调用* inner() generator 时,你就 yield 委托给它的迭代器。但你实际上可以 yield 委托给任何迭代器;yield * ['a','b','c']将会消费默认的['a','b','c']数组值迭代器。
提到yield*, 就说一下 co,co 我们可以理解为一个执行器,他可以让 generator 自动执行。co 函数返回一个 Promise 对象,可以用 then 方法添加回调函数。
var co = require('co');
var genFn = function* (){
var f1 = yield fn;
return f1;
};
function* fn() {
let promiseFn = new Promise(function(resolve, reject) {
if (true) {
resolve('Promise Success');
} else {
reject(error);
}
});
return promiseFn;
}
co(genFn).then(r => {
console.log(r)
})
使用 co 需要特别注意下,Generator 函数的 yield 后面,只能是 Thunk 函数或 Promise 对象。所以你也可以把 co 函数库理解成它是将两种自动执行器(Thunk 函数和 Promise 对象)包装成的一个库。
同时简单介绍下 Thunk:Thunk 函数真正的作用在于自动执行 Generator 函数。了解过的同学应该知道,他是根据编译器中的“传名调用“来实现的,Thunk 函数代替的是多参数函数,就是替换成单参数的函数,且只接受回调函数作为参数。
var useThunk = Thunk(name);
useThunk(callback);
var Thunk = function (name){
return function (callback){
return fn(name, callback);
};
};
对于Generator函数自动执行,并不是只有co、Thunk方案。对于自动执行的关键在于要有一种控制机制,它可以控制Generator函数的流程,接受传入的值,并且可以把执行的权力还给程序。
ES6 增加了 for..of 循环,这意味着一个标准的迭代器可以使用原生的循环语法来自动地被消费,我们可以使用 for...of 来遍历 Generator 函数运行时生成的 Iterator 对象,这时候就不需要调用 next 方法。当然我们可以通过使用 break 或者 return 暂停遍历。
function* fn() {
yield 1;
yield 2;
yield 3;
yield 4;
yield 5;
return 6;
}
for (let m of fn()) {
console.log(m);
}
// 1 2 3 4 5
我们在使用 Generator 函数的时候也可以在中间传值使用。 下面代码: 第一句 foo.next()执行了 yield 1; 第二句 foo.next(‘我是a’) 中的参数赋值给了第一个 yield 前面的变量,即a。然后再输出console.log(‘aaa’, a) // 此时的a值为'我是a'。 然后执行了 yield 2,再赋值给b='我是b', 最后执行了 yield 3,复制给c='我是c'。
function* fo() {
const a = yield 1
console.log('aaa', a) // aaa 我是a
const b = yield 2
console.log('bbb', b) // bbb 我是b
const c = yield 3
console.log('ccc', c) // ccc 我是c
}
const foo = fo()
foo.next() // value: 1, done: false
foo.next('我是a') // aaa 我是a value: 2, done: false
foo.next('我是b') // bbb 我是b value: 3, done: false
foo.next('我是c') //ccc 我是c value: undefined, done: true
我最近做的项目中有一些业务上就用到了 generator 的思想,有一个是抽奖活动,在每次点击按钮就调用一次 next 来实现次数的递减,在转盘转动抽奖的过程中, 让按钮禁止点击,等转盘结束转到后在进行 next 进行下一步操作,同时把按钮的开关打开。还有一些轮询的方法,比如支付等待的过程,之前是通过定时器来不断的访问给定的接口,现在可以使用 generator 实现一下。
function *pay() {
yield new Promise((resolve, reject) => {
resolve({msg: '支付成功', success: true});
})
}
function wePay() {
let money = pay();
let fn = money.next();
fn.value.then( res => {
if (!res.success) {
console.log(`还没到账`);
wePay();
} else {
console.log('到账了');
}
})
}
wePay();
generator [2]的主要应用场景就是他的同步式的异步表达,还有就是他的流程控制。我在思考是否可以使用 Generator + async 来定义一个异步函数,在 Generator 函数中就可以同时使用 await 和 yield,是不是效果上会优于前几种方式。

对于目前的异步方案来讲,对前端来说 promise 已将完全够用了。Generator 不止在前端得到应用,在服务器端也有广泛应用,JS中的 Generator 的实现就是借鉴了 Python Generator 的实现。
Generator in Python
因为JS是借鉴了 python 的 generator 实现的,所以在 python 中少不了 yield、next (写法上可能不太一样,另注意 python2 和 python3 的语法有些许不同)。在 python 的函数定义中,如果出现了 yield 表达式,那么我们可以认为它就是一个 generator function。

Python generator 的实现主要是对协程的支持。协程:他有自己的上下文和栈,当任务切换时,他会将当前的上下文和栈保存到其他地方,再被切回来的时候,恢复之前前保存的上下文和栈。所以协程能保留上一次调用时的状态,每次任务重新执行时就相当于进入上一次调用的状态,可以理解为进入上一次离开时所处逻辑流的位置。这种操作大都是用于非阻塞等待的场景,如游戏编程,异步IO,事件驱动等。
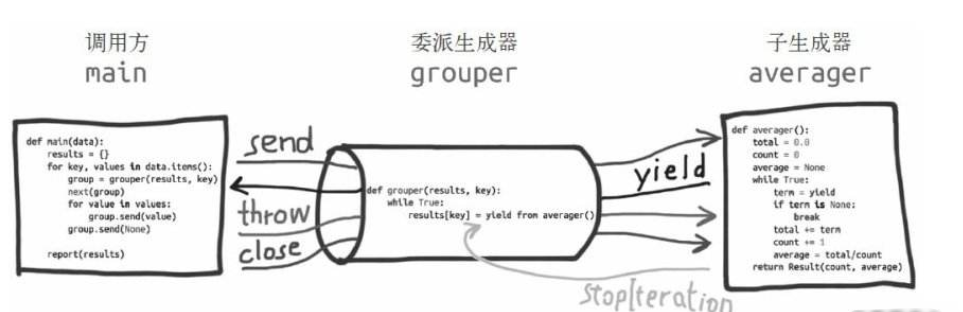
如果我们理解了 JS 中的 generator,现在来看 python 的 generator 应该很容易了。它同样遵循迭代器(iterator)原则,可以通过 next 多次进入、多次返回,可以暂停代码的执行。
def gen():
print ('1')
yield 'yield1'
print ('2')
yield 'yield2'
print ('null')
genDemo = gen()
genDemo.__next__()    # 第一次
# 1
# 'yield1'
genDemo.__next__()    # 第二次
# 2
# 'yield2'
genDemo.__next__()    # 第三次
# null
Traceback (most recent call last):
File "demo.py", line 17, in <module>
genDemo.__next__()
StopIteration
上面代码运行结果可以看出,中间的执行过程和之前说的 JS 是一样的,但是程序最后捕获了一个 StopIteration 异常,所以在 python 中使用 generator,一般在循环中使用比较常见。因为 for 语句能自动捕获 StopIteration 异常,这个原理和JS提到的使用 for..of..相似,就不用每次 next 执行了。
def example():
yield 'one'
yield 'two'
if __name__ == '__main__':
for k in example():
print (k)
# one two
python 中之所以使用 generator,最重要的原因是可以按需生成并“返回”结果,而不是一次性return所有的值。这样可以用来读取某个日志文件,如果文件过大,使用原来的方式可能会造成内存溢出的情况,因为使用 generator 可以一条条读取,不用构建整个列表。就好比生成器(generator)存储的是一个方法,而列表保存的是计算后的结果,所以相比较的情况下生成器占用内存小,而列表占用内存大。
#直接读取大文件,容易造成内存溢出。
def get_data_file(file_name):
with open(file_name,"r",encoding="utf8") as f:
data = f.read().split("\n")
return data
#利用generate方式不会造成内存溢出,一条一条读取比较大的文件。
def get_data_file_generate(file_name):
for line in open(file_name,"r",encoding="utf8"):
yield line
if __name__ == '__main__':
#结果 data count is 100001
#但是data.txt足够大的时候会出现内存溢出的问题。
count1 = 0
for line in get_data_file("data.txt"):
count1 += 1
print(f"data count is {count}")
#结果 data count is 100001 无论data.txt是多大的文件
#由于是使用generate它只会一条一条加载内存中而不是全部
#所以不会出现内存溢出的问题。
count2 = 0
for line in get_data_file_generate("data.txt"):
count2 += 1
print(f"data count is {count}")
当然,在使用的过程中,我们也可以往 yield 中传值,不同于 JS 中在 next 中传值,python 中使用 send,同样是给 yield 赋值,和 next 的效果是一样的,可以执行 generator 函数。
def foo():
a = yield 'start'
b = yield a
c = b
f = foo()
print(f.send(None))
print(f.send("jder"))
print(f.send("last-stop"))
// start
// jder
// last-stop
python 中对 generator 的使用主要是对内存空间的优化,不需要一次构造出整个结果列表,对于大数据量处理,将会非常有用。可以当成是延迟计算,同时生成器还能有效提高代码的可读性。
现在我们知道了 python 中的协程是通过 generator 实现的,可以理解他有四种状态:等待开始执行、解释器正在执行、yield 表达式处暂停、执行结束。除了 next 和 send 方法,generator 还提供了两个实用的方法,throw 和 close,这两个方法加强对 generator 的控制。send 方法可以传递一个值给 generator,throw 方法在 generator 挂起的地方抛出异常,close 方法让 generator 正常结束(这之后就不能再调用 next send 了)。
因为每一个生成器函数在调用之后,它的函数体并不执行,而是第一次调用 next() 的时候才会执行,仅在需要的时候产生对应的值,并不是一次性产生所有的值,这就节省了空间内存,提高了效率,理论上来讲,无限循环可能就不会产生导致内存不够用的情况,这个在读数据处理的时候尤为重要。所以在循环过程中依次处理一个任务的时候,用生成器是最好的。所以说生成器很大程度上提高了运行效率。
Generator in Koa
在 node 中使用 Generator 和 JS 中的使用基本是一样的,因为 node 也用 JS 写嘛,哈哈...我们来看看 nodejs 的一个框架 Koa 中的使用情况。
Koa v1 是基于 ES6 Generator 的,Koa v2 主打 async 函数,现在 Koa 都在用 V2 版本了,已经支持了 async 函数的。
目前 Koa 版本主要通过利用 async 函数,舍弃回调函数,并有力地增强错误处理。它并没有捆绑任何中间件,而是提供了一套优雅的方法,帮助我们快速地编写服务端应用程序。目前他的环境配置需要依赖 node v7.6.0 或 ES2015 及更高版本和 async 方法支持。
Koa V1
const koa = require('koa');
const app = koa();
app.use(function *(next){
console.log('first');
yield next;
console.log('1');
})
app.use(function *(next){
console.log('second');
yield next;
console.log('2');
})
app.use(function *(next){
console.log('third');
yield next;
console.log('3');
})
app.use(function *(){
this.body = 'Hello JDC';
});
app.listen(3000);
//输出结果为:
first
second
third
3
2
1
从上面的代码可以看出,他的执行顺序类似捕获和冒泡的过程。(PS:这里让我想到了 JS 的 eventLoop 事件循环机制,此刻又好好的复习了一波~)
Koa V2
const Koa = require('koa');
const app = new Koa();
app.use(async (ctx, next) => {
console.log(‘first');
await next();
console.log('1');
});
app.use(async (ctx, next) => {
console.log('second')
await next();
console.log('2')
});
app.use(async (ctx, next) => {
console.log('third')
await next();
console.log('3')
});
app.use(async ctx => {
ctx.body = 'Hello JDC';
});
app.listen(4000);
//输出结果为:
first
second
third
3
2
1
对于 Koa [3],比较重要的两点就是:context(上下文)的保存和传递,中间件的管理和 next 的实现,从上面代码可以看出 Koa 框架中间件的访问可以看出是自上而下的中间件流和自下而上的 response 数据流的形式,他就是一个标准的堆栈(先进后出)模型,Koa 官方称为洋葱模型。
注意:Koa v1 使用隐式的 this 作文上下文,而 Koa v2 则使用显式的 ctx 作为上下文,语义更清晰。
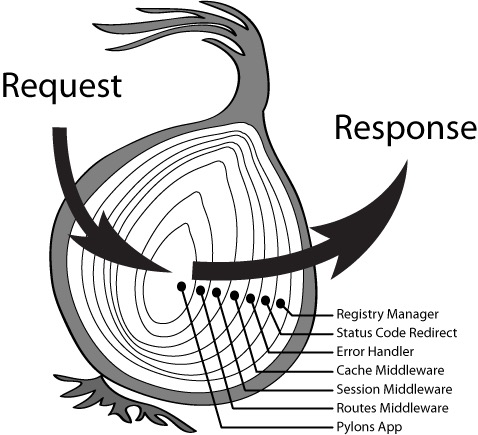
通过 v1 和 v2 的对比来看我可以发现,在使用koa的时候我们一个是直接执行了方法,另一个是通过new的方式执行,这就可以看出v1中是对外导出的函数,而 v2 是对外导出的类,需要通过 new 这个关键子来实例化。
根据 Koa 源码中的代码,实际上我们在 app.use 的时候我们是把一个中间件 push 到一个列表中了,然后在回调函数中通过 compose 来遍历了整个中间件,最终将 context 和 dispatch(i + 1) 传给 middleware 中的方法。(ps:大家稍微注意下调用 next 方法并不是说当前中间件函数执行完毕了,调用 next 之后仍可以继续执行其他代码,同时在一个中间件中不能调用两次 next(),否则会报错)
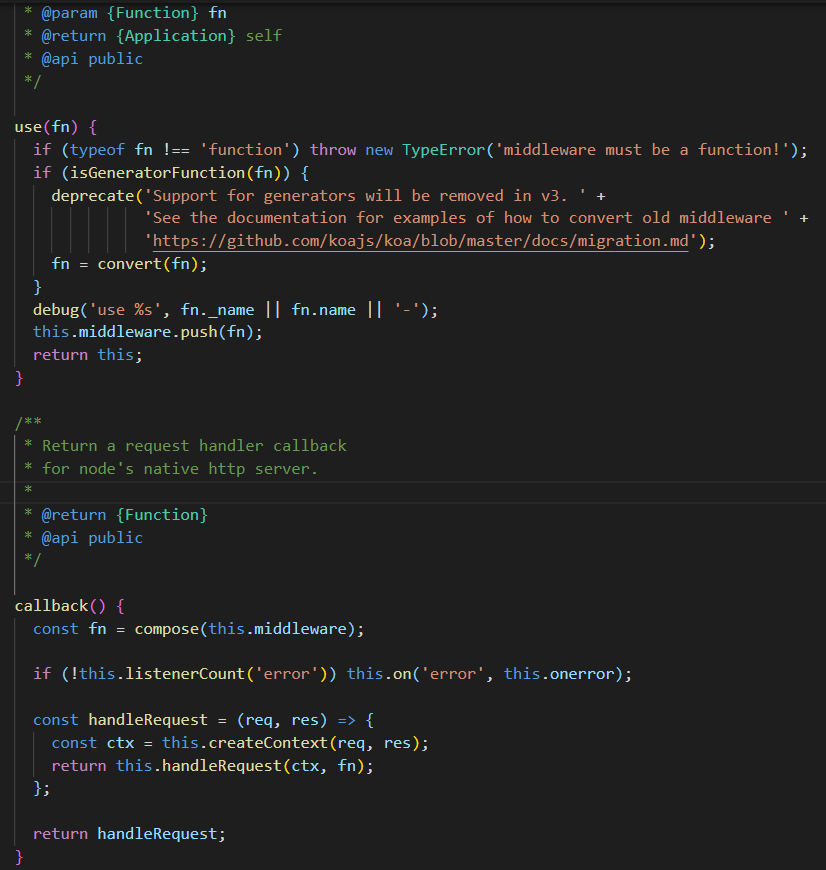
compose 来自 koa-compose 模块,它可以将多个中间件函数合并成一个大的中间件函数,然后调用这个中间件函数就可以依次执行添加的中间件函数,执行一系列的任务。
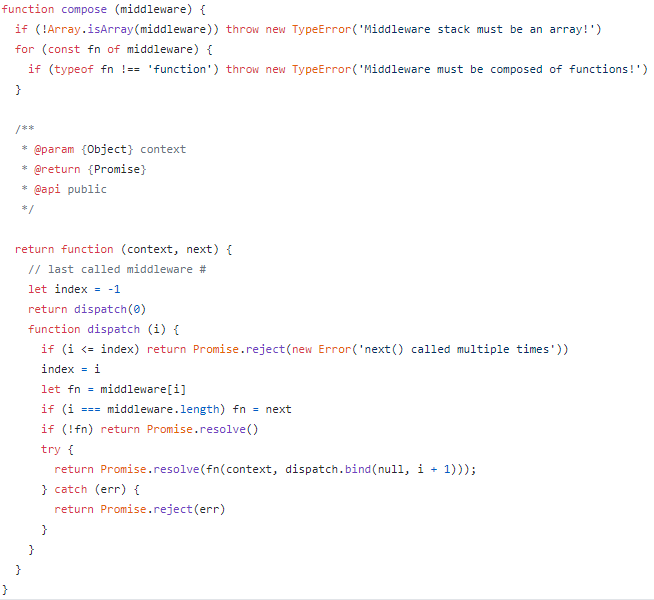
现在 Koa 正在被广泛的使用,它相对于 express 框架来说,最直观的就是不用写 callBack 了,哈哈~,他借助 promise 和 generator 的能力,丢掉了 callback,完美解决异步组合问题和异步异常捕获问题。但是他的一些其他功能还需要借助第三方来实现,当然这也给我们带来更大的发挥空间,可根据自己实际情况来选择使用 express 或者 Koa。
对于后台语言或者前端语言,开发模式都是一样的,所以无论是哪个方法或者模式,在其他的语言开发中都会有所涉及,比如 java、Scala 他们也用到了 generator(PS:不要嫌我话痨,我就说一丢丢~[捂脸.png])
Generator in Java
Java 标准库中并没有提供 Generator 接口及其实现,所以需要自己定义接口然后实现。
在 JAVA 中生成器( Generator )是一种专门用于创建对象的类,它实际上类似 JS 中的工厂模式,也是泛型应用于接口的一种。在这里暂且当成 TS 理解吧,将泛型应用于接口,接口必须有返回类型为泛型T的 next() 方法,是一种专门负责创建对象的类。比如 JS 的工厂模式,类似于Iterable 对象中使用使用 next() 不断获得下一个值,这里泛型接口中的 next() 方法返回创建对象。
使用生成器创建新对象时,不需要任何参数就可以创建对象,生成器只要定义一个产生新对象的方法。
// 定义一个生成器接口,提供一个next()方法,用来返回一个新的类对象
public interface Generator<T> {
/**
- 用以产生新对象
- @return
*/
public T next();
}
定义一个 CommonGenerator 类,对 Generator 接口进行实现,用以生成某个类的对象。 (这里使用了泛型参数)
class CommonGenerator<T> implements Generator<T> {
private Class<T> type;
public CommonGenerator(Class<T> type) {
this.type = type;
}
@Override //表示必须要重写这个类
public T next() {
return type.newInstance(); // 利用反射生成<T>对象
}
}
同时我们这里也要写好需要生成的类,这里就相当于我们在 JS 中结合函数的 prototype 定义方法的工厂模式。
class Person {
private int id;
private String name;
public void setId(int id) {
this.id = id;
}
public void setName(String name) {
this.name = name;
}
public void print(){
System.out.println("id:"+this.id+" ,name:"+this.name);
}
}

同时我们在这里定义主类,流程大致是这样的:首先通过 new 一个 CommonGenerator 类,并且将 Person 作为一个泛型传入,在 CommonGenerator 这个类中接收到泛型,并且他要实现 Generator 这个接口,所以 CommonGenerator(Person.class) 通过构造器将值赋给了类中的 type,然后通过重写类得到新的构造函数,在调用新的 next 方法就是一个新的 person 类。大家看到这里可能觉得前面的2个类定义的多余,哈哈~主要是想让大家更好的理解一下,如果单纯创建一个可以不用这么麻烦,如果我们在给 Person 类创建很多实例时在这样一个个通过 new 去创建就显得很麻烦了,使用 Generator 方便了许多,也提高了其通用性。
public class GeneratorDemo {
public static void main(String args[]) {
CommonGenerator<Person> personGenerator = new CommonGenerator<Person>(Person.class);
//利用生成器生成第一个对象
Person person1 = personGenerator.next();
//赋值
person1.setId(1);
person1.setName("Tom");
person1.print();
//利用生成器生成第二个对象。
Person person2 = personGenerator.next();
//赋值
person2.setId(2);
person2.setName("Json");
person2.print();
//利用生成器生成N个对象的话,就可以使用循环来操作
//示例
for (int i = 0; i < 5; i++) {
personGenerator.next();
}
}
}
说到这里,我们在来看一下他的生成器模式,也叫建造者模式,对于 Java 中生成器的理解就是将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。生成器模式利用一个导演者对象和具体建造者对象一个一个地建造出所有的零件,从而建造出完整的对象。
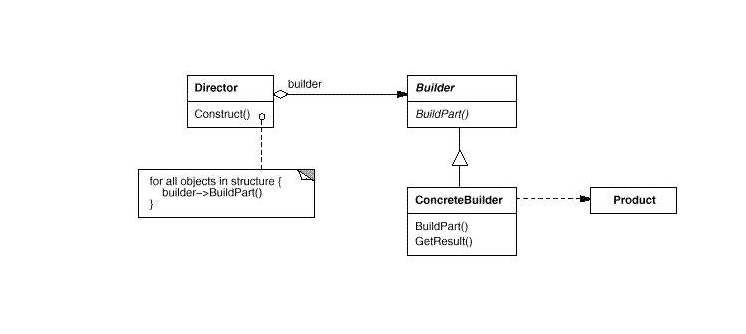
Java 生成器的理解,我们再来看个例子:比如需要建造一套房子,但是房子里有客厅、厨房、卫生间、卧室、餐厅等组成部分。
public class House{
public String livingroom;
public String bedroom;
public String kitchen;
public House(){
}
public String setLivingroom(String livingroom) {
this.livingroom = livingroom;
}
public void setBedroom(String bedroom) {
this.bedroom = bedroom;
}
public void setKitchen(String kitchen) {
this.kitchen = kitchen;
}
}
知道了所有组成部分后,就需要画图纸来建造房子了,定义一个建筑施工队的建造者接口。
public interface Builder {
String buildLivingroom();
String buildBedroom();
String buildKitchen();
}
把客户需求交个建筑设计院,开始让建筑设计师设计图纸
public class HouseBuilder implements Builder{
@Override
public String buildLivingroom() {
return "livingroom";
}
@Override
public String buildBedroom() {
return "bedroom";
}
@Override
public String buildKitchen() {
return "kitchen";
}
}
图纸出来后,交给施工单位,把建筑施工队分成几个小队,来负责建设自己对应的部分,并开始搬砖-_-
public class HouseBuilder {
HouseBuilder cb;
public HouseDirector(HouseBuilder cb){
this.cb=cb;
}
public House constructHouse(){
House house=new House();
house.setEngine(cb.buildLivingroom());
house.setTyre(cb.buildBedroom());
house.setSeat(cb.buildKitchen());
return house;
}
}
最终房子建好了
public class home {
public static void main(String[] args) {
HouseDirector houseDirector=new HouseDirector(new HouseBuilder());
House house=houseDirector.constructHouse();
System.out.println(house.setLivingroom()+house.setBedroom()+house.setKitchen());
}
}
通过上述例子,可以看出 Java 生成器的设计模式可以使客户端不必知道内部组成的细节;具体的建造者类之间是相互独立的,对系统的扩展非常有利;由于具体的建造者是独立的,因此可以对建造过程逐步细化,而不对其他的模块产生任何影响。
Generator in Scala
可能一说到 Scala [1] 都会想到大数据。Scala 是一种多范式的编程语言,他的设计初衷是要集成面向对象编程和函数式编程的。Scala 语言表达能力强,开发速度快;可能你写一行 Scala 就可以顶替几行 Java 代码,因为 Scala 是静态编译的,所以速度会快。他既可以用于大规模应用程序开发,也可用于脚本编程,当然他是可以运行在 Java 平台的。

《PROGRAMMING IN SCALA》一书,他对 generator 的定义是:生成器在 for 表达式中定义一个命名的val变量并赋予其一系列值。比如:for(i <- 1 to 10)的生成器是”i <- 1 to 10“,<-右边的值是生成器表达式。yield 表达式可以产生结果,yield 关键字指定了 for 推解式的结果。
class Person {
//定义私有的变量,并对外提供赋值的方法。
private var myid = 0
private var myname = ""
private var myage = 0
def id: Int = myid
def id_=(id: Int) = myid = id
def name: String = myname
def name_=(name: String) = myname = name
def print(): Unit = {
println("id:" + id + " ,name:" + name)
}
}
trait Generator[T] {
def next: T
}
class CommonGenerator[T](common: Class[T]) extends Generator[T] {
override def next: T = {
return common.newInstance()
}
}
object GeneratorDemo {
def main(args: Array[String]): Unit = {
//自己实现生成器
var personGenerator = new CommonGenerator[Person](classOf[Person])
//生成person1对象
var person1 = personGenerator.next
//scala风格的参数赋值
person1.id = 1
person1.name = "Tom"
person1.print()
//生成person2对象
var person2 = personGenerator.next
person2.id = 2
person2.name = "Json"
person2.print()
//自带生成器类似于python
//这里就使用yield关键字生成了一个新的集合。
val number = for (i <- 1 to 10; if i % 2 == 0) yield i
println(number)
}
}
正如上方代码最后2行所示,根据条件过滤元素,生成新的集合,其中如i <- 1 to 10的语法结构,在 Scala 中称为“生成器 ( generator )”,比如你不想枚举集合中的每个元素,而是只迭代某些符合条件的元素,在 Scala 中,你可以为 for 表达式添加一个过滤器–在 for 的括号内添加一个if语句。
for 表达式可以用来生产新的集合,这是 Scala 的 for 表达式比 Java 的 for 语句功能强大的地方。 比如#1,关键字 yield 放在 person 的前面,for 每迭代一次就产生一个 person,yield 收集所有的 person 结果,返回一个 person 类型的集合。比如#2,前面列出所有.html文件,返回这些文件的集合。
#1
for clauses yield person
#2
def htmlFiles =
for {
file if file.getName.endsWith(".html")
} yield file
对于 Scala 和 Java 他们来说更是一种竞争关系,他们都可以用来处理大数据的,都可以写 Spark。Scala 他有自己的优点就是他有比较强的集合处理能力,有一些完整的集合类库,但是就性能而言,Scala的基准性能很接近Java,但确实没有Java好。就从最常用的for循环比较来说,Java 的速度要比 Scala 的速度快好几倍,因为 Scala 的运行依赖 Java,所以预启动会快一些。 (PS:scala之前有一点点了解,写错了还望大神指正[皱眉.png])
// Scala
object TestScalaClass {
var maxNum = 100000
def testTime(): Unit ={
var begintime = System.currentTimeMillis()
var sum = 0
for (i <- 0 to maxNum) {
sum += i
}
println("value1 " + sum + " 用时: " + (System.currentTimeMillis() - begintime))
}
def main (args: Array[String]) {
testTime()
}
}
// Java
long begintime = System.currentTimeMillis();
int i = 0;
int sum = 0;
for (i = 0 ; i <= 100000; i++)
sum += i;
long endtime = System.currentTimeMillis();
System.out.println("value2 " + sum + "用时: " + (endtime - begintime) );
value1 705982704 用时: 271
value2 705082704 用时: 1
(PS:多次运行的情况下,时间耗时可能会有差异)
总结
目前在项目中使用的都是异步请求的方式,通过 promise 封装一些后台请求的方法或者使用封装的 axios 已经足够用。这边文章的启发主要来自项目中的异步加载导致的排序出错,所以想到了是否可以控制他的流程。这种异步操作在很多业务中都有应用,语言的逻辑都是互通的,就好比英语和汉语,虽然有时候听不懂看不懂(哈哈~),但是2种语言可以互译。此文通过查阅资料和调研,询问同事等方法,自己收获良多。其实感觉有时候重要的不是结论,而是发掘的过程。欢迎大家指出文章有问题的地方,并希望此文对大家有所帮助^_^。
文章参考链接:
[1] scala官网:docs.scala-lang.org/zh-cn/
[2] 异步与性能:www.jianshu.com/p/d6ac6b0b4…
[3] koa-Compose源码分析:segmentfault.com/a/119000001…
[4] Generator函数语法解析: juejin.cn/post/684490…
