

微信公众号:房东的小黑黑
路途随遥远,将来更美好
学海无涯,大家一起加油!
MapReduce是一种分布式计算框架,以一种可靠的,具有容错能力的方式并行地处理TB数据级别的海量数据集。MapReduce主要有两个阶段组成:Map和Reduce;用户只需实现map()和reduce()函数,就可实现分布式计算。
MapReduce的核心思想是分治法。将复杂的、运行于大规模集群上的并行计算过程高度抽象了两个函数:Map和Reduce函数。将一个存储在分布式文件系统中的大规模数据集,切分成很多分片,一个分片对应一个map处理。MapReduce框架采用了Master//slave架构,包括一个Master和若干个slave, master上运行了JobTracker,slave上运行了TaskTracker。
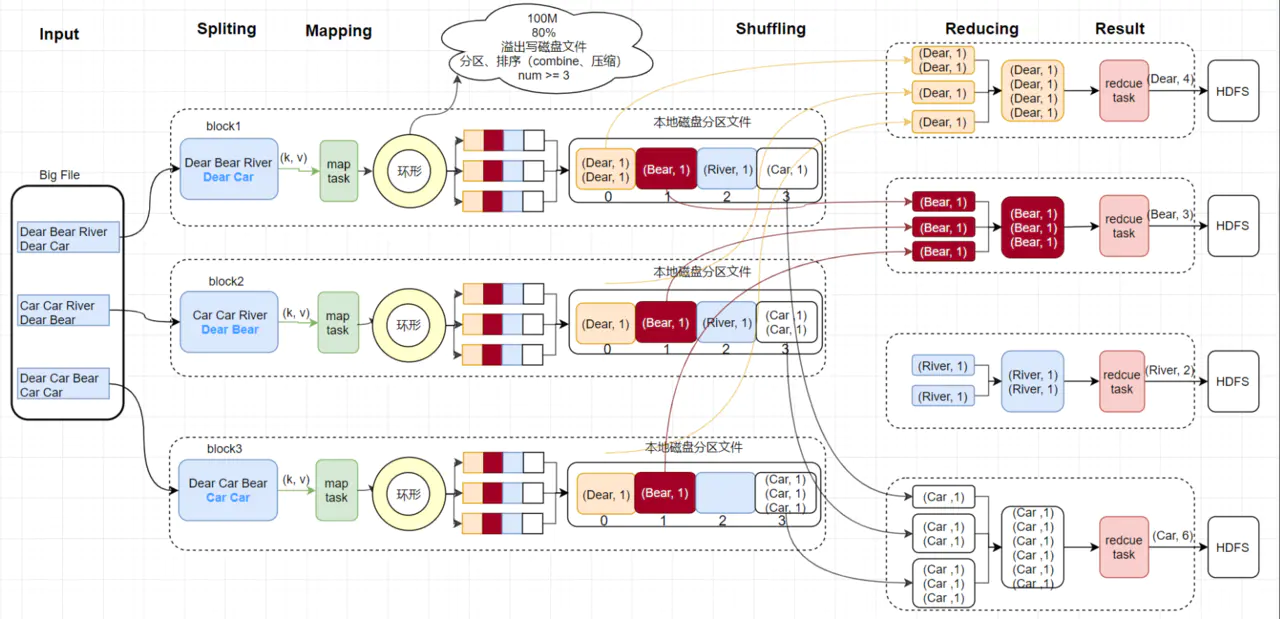
Map阶段
首先InputFormat会将我们指定的输入路径中的文件按照block切分成若干个分片。默认情况下分片的大小与HDFS中block的大小一致,Hadoop1.x是64M,Hadoop2.x是128M。每一个分片对应一个map来进行处理。 Map函数,一行一行的处理输入的数据,将每一行数据封装成键值对。
产出的键值对会暂存在内存中的一块环形缓冲区,每个缓冲区默认是100M,当超过80%时,后台会开启一个进程,锁住80M的空间,将数据写入到剩余的20M空间,同时将80M的数据溢写磁盘。在溢写前,会先根据分区排序,相同分区的数据,排在一起,再根据map的key排序(快排)。如果配置了combiner,还会将相同分区号和key的数据进行排序。最后将所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终产生一个中间数据文件。
MapReduce缺省的Partitioner用key的哈希值对reduce任务数量进行取模,相同的key一定会落在相同的reduce任务id上,具体的逻辑很简单:
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K2 key, V2 value, int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
在上面中讲到了combine,这里再仔细讲一下。
它实际上在MapTask本地中的reduce聚合操作,无论运行多少次combiner操作,都不会影响最终的结果。但是并不是所有的操作都适合这个过程,在求平均操作就不可以,可能会出错。
Reduce阶段
ReduceTask从各个MapTask上远程拷贝一份数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阈值的时候,就会将数据写到本地的数据文件进行合并排序。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现了对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。然后Reduce函数会依次将相同key的数据集进行处理,并将结果写入到HDFS中。
整体流程分析
1) JobClient类中会把用户应用程序的Mapper类、Reducer类以及配置文件JobConf打包成一个JAR文件保存到HDFS中,JobClient在提交作业的同时把这个JAR文件的路径一起提交到JobTracker的master服务(作业调度器)
2) JobClient提交Job后,JobTracker会创建一个JobInProcess来跟踪和调度这个Job作业,并将其添加到调度器的作业队列中。
3) JobInProgress根据输入数据分片数目(通常是数据块的数据)和设置的reduce数据创建相应数量的TaskInProcess。
4) TaskTracker进程和JobTracker进程进行定时通信。
5) 如果TaskTracker有空闲的计算资源,JobTracker就会给他分配任务。
6) TashRunner收到任务后会根据任务类型(map还是reduce),任务参数启动相应的map或者reduce进程。
7) map或者reduce程序启动后,检查本地是否有要执行任务的jar文件,如果没有,就去HDFS上下载,然后加载map或者reduce代码开始执行。
8) 如果是map进程,从HDFS中读取数据。如果是Reduce进程,将结果数据写出到HDFS中。

