其他更多java基础文章:
java基础学习(目录)
学习资料:
CXY的大数据实践田
Spark的Shuffle(一) - SortShuffleWriter
SparkContext初始化流程
Spark-Job执行流程分析
Spark源码之Executor&CoarseGrainedExecutorBackend
Spark源码分析小结
Spark源码系列
Spark专栏 Spark Scheduler内部原理剖析
ExternalSorter 在Spark Shuffle过程中的设计思路剖析
Spark商业环境实战源码深入解析目录
Spark Shuffle/Map/Reduce部分详解
spark shuffle读操作(这一系列都值得看)
Spark 内核源码重点 **
能力有限,目前还是个学习者的姿态,所以只是记录一下spark计算模块源码的学习过程。在学习的过程中发现上面几个是不错的学习资料,推荐给大家,带*号表示值得优先查看学习的资料。
计算模块这一部分是Spark重点,建议都看。
因为每个资料都各有侧重点,所以可能在看的时候对一些没有细讲的类和架构不了解。下面我对上面的资料进行了总结,可以在学习的过程中对照的来看。
重要概念
- RDD:RDD全称Resilient Distributed Dataset,即分布式弹性数据集。它是Spark的基本抽象,代表不可变的可分区的可并行计算的数据集。
- Stage:Stage是一组并行任务,它们都计算需要作为Spark作业的一部分运行的相同功能,其中所有任务具有相同的shuffle依赖。由调度程序运行的每个DAG任务在发生shuffle的边界处被分成多个阶段,然后DAGScheduler以拓扑顺序运行这些阶段。每个Stage都可以是一个shuffle map阶段,在这种情况下,其任务的结果是为其他阶段或结果阶段输入的,在这种情况下,其任务在RDD上运行函数直接计算Spark action(例如count(),save()等)。对于shuffle map阶段,我们还跟踪每个输出分区所在的节点。每个stage还有一个firstJobId,用于识别首次提交stage的作业。使用FIFO调度时,这允许首先计算先前作业的阶段,或者在失败时更快地恢复。最后,由于故障恢复,可以在多次尝试中重新执行单个stage。在这种情况下,Stage对象将跟踪多个StageInfo对象以传递给listener 或Web UI。最近的一个将通过latestInfo访问。
- ResultStage:ResultStage在RDD的某些分区上应用函数来计算action操作的结果。对于诸如first()和lookup()之类的操作,某些stage可能无法在RDD的所有分区上运行。简言之,ResultStage是应用action操作在action上进而得出计算结果。
- ShuffleMapStage:ShuffleMapStage 是中间的stage,为shuffle生产数据。它们在shuffle之前出现。当执行完毕之后,结果数据被保存,以便reduce 任务可以获取到。
- DAGScheduler:DAGScheduler将应用的DAG划分成不同的Stage,每个Stage由并发执行的一组Task构成,Task的执行逻辑完全相同,只是作用于不同数据。
- TaskScheduler:任务调度,TaskScheduler给Task分配集群资源实际是通过SchedulerBackend完成的
- TaskSchedulerImpl:任务调度实现类
- SchedulerBackend:用于调度系统的后端接口,为应用程序分配资源,并可以在其上启动任务。
- CoarseGrainedSchedulerBackend:CoarseGrainedSchedulerBackend是一个阻塞等待coarse-grained executors来连接的SchedulerBackend。该SchedulerBackend会在整个spark-job期间持有每个executor,而不是一个task结束后再为下一个task向Scheduler申请新的executor。executor可以通过多种方式建立,具体的方式由继承CoarseGrainedSchedulerBackend的类实现。CoarseGrainedSchedulerBackend向ExecutorBackend端发送的消息主要如下:
- registeredExecutor:回复ExecutorBackend注册功能,ExecutorBackend接到后会创建Executor。
- LaunchTask:通知Executor启动一个task,消息中包含序列化的task信息,Executor通过该信息启动task。
- Task:Task任务
- ResultTask:作业的最后一个阶段由多个resulttask组成,而早期阶段由shufflemaptask组成。ResultTask执行任务并将任务输出发送回驱动程序应用程序。ShuffleMapTask执行任务并将任务输出划分为多个bucket(基于任务的分区器)。
- ShuffleMapTask
- Executor:Executor对象是Spark Executor的抽象,它背后有一个线程池用来执行任务。
- TaskMemoryManager:用于管理每个task分配的内存
- CoarseGrainedExecutorBackend:CoarseGrainedExecutorBackend比较直观因为我们在启动Spark集群运行任务通过JPS命令,可以看到有一个CoarseGrainedExecutorBackend这样的进程,其实CoarseGrainedExecutorBackend就是一个进程,而Executor则是一个实例对象,并且Executor是运行在CoarseGrainedExecutorBackend进程中的;再者CoarseGrainedExecutorBackend和Executor是一一对应的。
- ShuffleBlockResolver:主要是负责根据逻辑的shuffle的标识(比如mapId、reduceId或shuffleId)来获取shuffle的block。shuffle数据一般都被File或FileSegment包装。
- IndexShuffleBlockResolver:这个类负责shuffle数据的获取和删除,以及shuffle索引数据的更新和删除。
- getDataFile:获取shuffle数据文件
- getIndexFile:获取shuffle索引文件
- removeDataByMap:根据mapId将shuffle数据移除
- checkIndexAndDataFile:校验shuffle所以和数据
- writeIndexFileAndCommit:写索引文件,首先先获取shuffle的数据文件并创建索引的临时文件。获取索引文件的每一个block 的大小。如果索引存在,则更新新的索引数组,删除临时数据文件,返回。若索引不存在,将新的数据的索引数据写入临时索引文件,最终删除历史数据文件和历史索引文件,然后临时数据文件和临时数据索引文件重命名为新的数据和索引文件。
- getBlockData:根据shuffleId获取block数据,先获取shuffle数据的索引数据,然后调用position位上,获取block 的大小,然后初始化FileSegmentManagedBuffer,读取文件的对应segment的数据。可以看出 reduceId就是block物理文件中的小的block(segment)的索引。
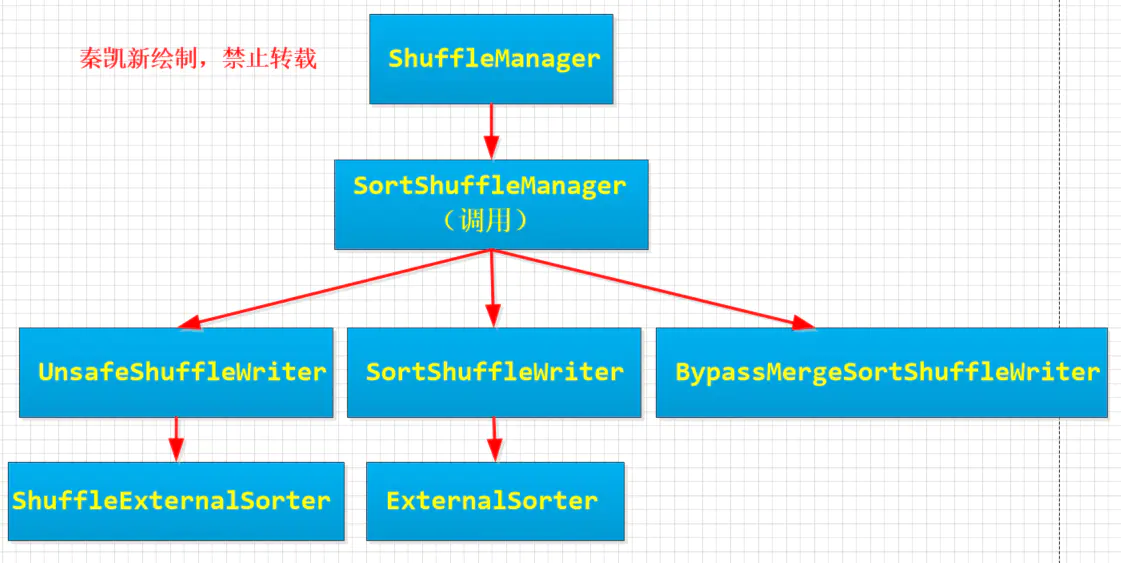
- ShuffeManager:目前只有一个实现 SortShuffleManager。SortShuffleManager依赖于ShuffleWriter提供服务,通过ShuffleWriter定义的规范,可以将MapTask的任务中间结果按照约束的规范持久化到磁盘。SortShuffleManager总共有三个子类, UnsafeShuffleWriter,SortShuffleWriter ,BypassMergeSortShuffleWriter用于Shuffle的写。 SortShuffleManager使用BlockStoreShuffleReader用于Shuffle的读。SortShuffleManager依赖于ShuffleHandle样例类,主要还是负责向Task传递Shuffle信息。一个是序列化,一个是确定何时绕开合并和排序的Shuffle路径。
- BlockStoreShuffleReader:主要从MapTask输出的正式的唯一的Block文件中读取由起始分区和结束分区指定范围内的数据。
- ExternalSorter: ExternalSorter 是SortShuffleManage的底层组件之一,用于SortShuffleWriter
- ShuffleExternalSorter: ShuffleExternalSorter 是SortShuffleManage的底层组件之一,用于UnsafeShuffleWriter
Job的执行流程
- 只有在Action的方法中才会调用
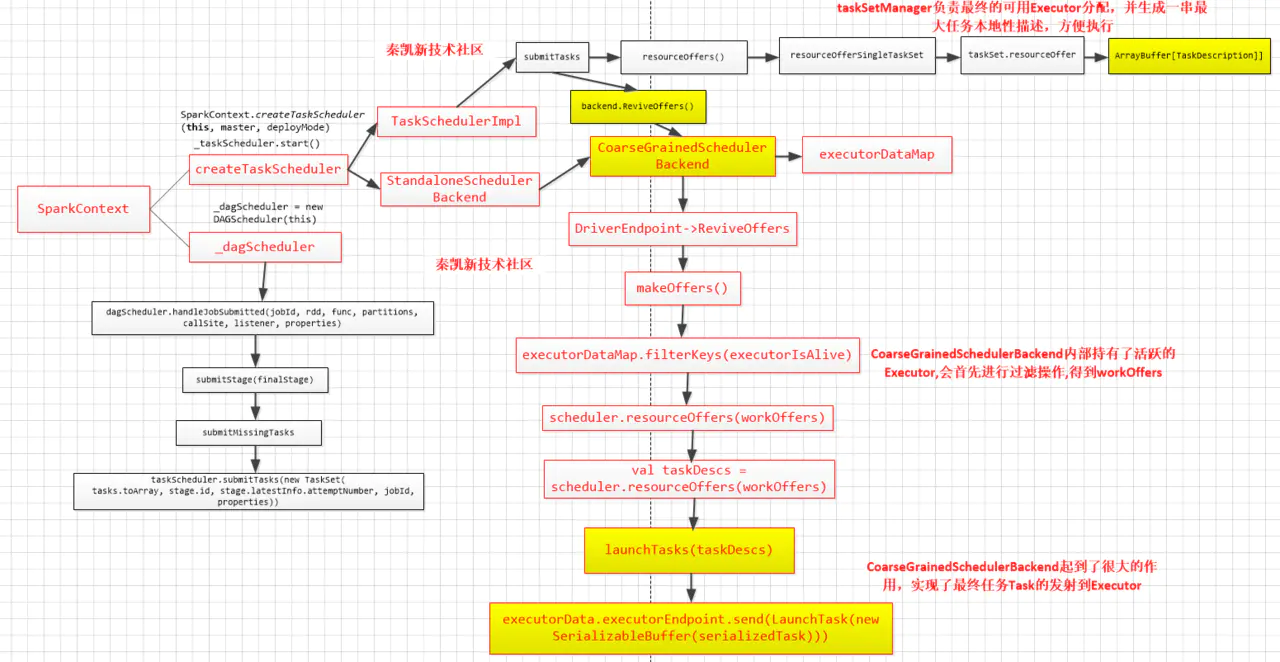
org.apache.spark.SparkContext#runJob方法来提交Job DAGScheduler#runJob,调用org.apache.spark.scheduler.DAGScheduler#submitJob方法得到JobWaiter对象,然后等待Job处理完毕,进行进一步处理DAGScheduler#submitJob,检查RDD的分区信息,然后创建JobWaiter对象,向DAGSchedulerEventProcessLoop发送JobSubmitted事件,把事件放入队列,等待处理线程处理EventLoop#post,Job提交之后就返回了,这时只是将JobSubmitted提交至org.apache.spark.util.EventLoop#eventQueue队列中暂存,eventQueue是一个LinkedBlockingDeque的阻塞队列。DAGSchedulerEventProcessLoop是DAGScheduler内部的事件循环处理器,用于处理DAGSchedulerEvent类型的事件。eventProcessLoop是DAGScheduler中定义的属性,将在DAGScheduler初始化时进行初始化。EventLoop启动时会启动事件处理线程。事件处理线程是一个简单的循环,从队列中取出事件,然后交给onReceive方法进行处理。onReceive方法可以认为代理了dagScheduler,针对不同的事件,调用dagScheduler中对应的方法,针对JobSubmitted事件,则调用了org.apache.spark.scheduler.DAGScheduler#handleJobSubmitted进行处理。DAGScheduler#handleJobSubmittedDAGScheduler#createResultStage用来创建ResultStageorg.apache.spark.scheduler.DAGScheduler#getOrCreateParentStages,对于给定的RDD,获取或创建父Stage列表,从当前的RDD向前探索,找到宽依赖处划分出parentStage,并用提供的firstJobId创建新Stageorg.apache.spark.scheduler.DAGScheduler#getShuffleDependencies,返回给定的直接父RDD的shuffle依赖,该功能不会返回更早的祖先。org.apache.spark.scheduler.DAGScheduler#getOrCreateShuffleMapStage,首先根据当前ShuffleDep的shuffle依赖id判断是否创建了Stage,如果创建了返回该Stage,如果没有创建的话调用DAGScheduler#getMissingAncestorShuffleDependencies方法寻找shuffleDep的父RDD前面所有的Shuffle依赖org.apache.spark.scheduler.DAGScheduler#getMissingAncestorShuffleDependencies,查找尚未在shuffleIdToMap中注册的祖先Shuffle依赖关系org.apache.spark.scheduler.DAGScheduler#submitStage,第6步handleJobSubmitted方法的最后一步是调用submitStage提交Stage,判断当前Stage的父Stage是否完成,如果有未完成的,则递归的提交父Stageorg.apache.spark.scheduler.DAGScheduler#getMissingParentStages,获取当前Stage所有未提交的父Stage- 在Stage没有不可用的父Stage时,提交当前Stage中还未提交的Task,提交Task的入口是
org.apache.spark.scheduler.DAGScheduler#submitMissingTasks,第12步submitStage方法的最后一步是提交Task,在Stage没有不可用的父Stage时,提交当前Stage中还未提交的Task taskScheduler#submitTasks,DAGScheduler#submitMissingTasks方法会调用该方法提交未计算的TaskSchedulableBuilder#addTaskSetManager,将当前的TaskSetManager提交到调度器的调度池中,TaskScheduler会先把DAGScheduler给过来的TaskSet封装成TaskSetManager扔到任务队列里,然后再从任务队列里按照一定的规则把它们取出来在SchedulerBackend给过来的Executor上运行。关于调度器相关请看Spark 内核的P126-P128org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend#reviveOffers,在15步taskScheduler#submitTasks的最后会调用reviveOffers方法,申请资源。进入CoarseGrainedSchedulerBackend的reviveOffers方法,可以看到在方法里面driverEndpoint向自己发送了一个ReviveOffers消息,而这个driverEndpoint我们前面也讲过,就是当前应用程序的Driver。org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend.DriverEndpoint#receive,通过netty发送一个请求资源的消息后,CoarseGrainedSchedulerBackend的receive方法则会接收17步发送的消息。在该方法中,由于接收到的是ReviveOffers,会调用makeOffers方法开始分配资源。org.apache.spark.scheduler.TaskSchedulerImpl#resourceOffers,为每一个Task具体分配计算资源,输入时ExecutorBackend以及可用的Cores,输出是TaskDescription的二维数组,在其中确定了每个task具体运行在哪个ExecutorBackend;在方法内部先将可用的executors添加到数据结构中,然后在将可用的executors进行shuffle以便做到负载均衡,为每个executor创建一个task数组用于存放TaskDescription,最后遍历调度策略中的TaskSet,使用就近原则为task分配executor,在这里需要强调一点的是DAGScheduler.submitMissingTasks()方法中我们是获取了每个task的对应数据的位置,而在本方法中的taskSet.myLocalityLevels是为了获取Task对应数据位置的级别TaskSchedulerImpl#resourceOfferSingleTaskSet,接着进入resourceOfferSingleTaskSet方法,遍历所有的executor的索引地址,以便作为tasks的索引,将每个task分配给相应的executor,并填充tasks;TaskSetManager#resourceOffer,为taskSet中的task分配executor,并将信息存储在tasks中- 再到DriverEndPoint的makeOffers方法中,scheduler.resourceOffers(workOffers)已经执行完毕,taskSet已经分配完毕,接着执行
launchTasks()方法,该方法遍历每个task,并向每个task所对应的executor发送launchTask消息; org.apache.spark.executor.CoarseGrainedExecutorBackend#receive,收到launchTask消息,执行org.apache.spark.executor.Executor#launchTask- 我们进入Executor的launchTask方法,在该方法内实例化出了
TaskRunner对象,而TaskRunner对象是一个线程,通过线程池threadPool来运行; - 执行
TaskRunner#run方法 - 执行
Task#run方法,然后执行Task#runTask方法,这个方法在ShuffleMapTask和ResultTask中有重写 - 在
ShuffleMapTask中,根据在manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)中的dep.shuffleHandle由ShuffleManager来决定选使用哪种ShuffleWriter。具体如何把数据写入到磁盘, 是由ShuffleWriter.write方法来完成。ShuffleManager从2.0开始就只有一个实现类了:SortShuffleManager。ShuffleWriter有3个子类:UnsafeShuffleWriter、BypassMergeSortShuffleWriter、SortShuffleWriter。 - 拉取数据具体查看Spark2.3源码分析——Shuffle的原理与实现、P129 Spark内核Shuffle流程解析
总结
DAGScheduler划分好stage,并将生成的TaskSet提交给TaskScheduler,TaskScheduler向Driver请求分配资源,Driver将可用的ExecutorBackend资源发给TaskScheduler,在TaskScheduler中将Task分配给ExecutorBackend,最后向ExecutorBackend发送launchTask请求,在ExecutorBackend中调executor对象的launchTask,在Executor对象的launchTask方法中启动TaskRunner线程并用线程池去执行TaskRunner线程;
总结2
- 在sparkContext实例化的时候通过createTaskScheduler来创建TaskSchedulerImpl和SparkDeploySchedulerBackend,在TaskScheduler的initialize方法中把SparkDeploySchedulerBackend传进来从而给TaskSchedulerImpl的backend赋值;在TaskScheduler调用start方法的时候会调用backend.start方法,在start方法中会注册当前应用程序;
- DAGScheler在提交TaskSet给底层调度器的时候是面向接口TaskScheduler,这符合面向对象中依赖抽象而不依赖实体的原则,带来底层资源调度器的可插拔性,导致spark可运行众多的资源调度器模式上,如:Standalone,Yarn,Mesos,Local,EC2等,其他自定的资源调度器;
- TaskScheduler的核心任务是提交TaskSet到集群运算并汇报结果;TaskScheduler内部握有SchedulerBackend,从Standalone的模式来讲具体实现是SparkDeploySchedulerBackend;
- SparkDeploySchedulerBackend在启动的时候构造了APPClient实例,而appclient实例start的时候启动了ClientEndPoint这个消息循环体,ClientEndPoint在启动的时候会向Master注册当前程序,而SparkDeploySchedulerBackend的父类CoarseGrainedshedulerBackend在启动的时候会实例化类型为DriverEndPoint(这就是我们程序运行时的Driver)的消息循环体;SparkDeploySchedulerBackend 专门负责收集Worker上的资源信息,当ExecutorBackend启动的时候会发送RegisterExecutor向DriverEndPoint注册,这样SparkDeploySchedulerBackend就掌握了当前应用程序的计算资源,TaskScheduler就是通过SparkDeploySchedulerBackend拥有的计算资源来具体运行Task的;
- SparkContext,DAGScheduler,TaskSchedulerImpl,SparkDeploySchedulerBackend在应用程序启动的时候只实例化一次,应用程序存在期间始终存在这些对象;
重要图例
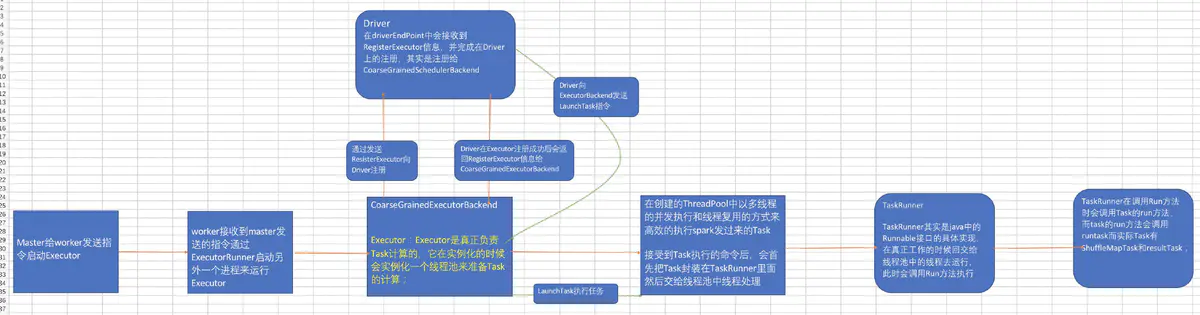
StandAlone模式CoarseGrainedExecutorBackend进程的产生和Executor对象的实例化
SparkContext到Task执行流程
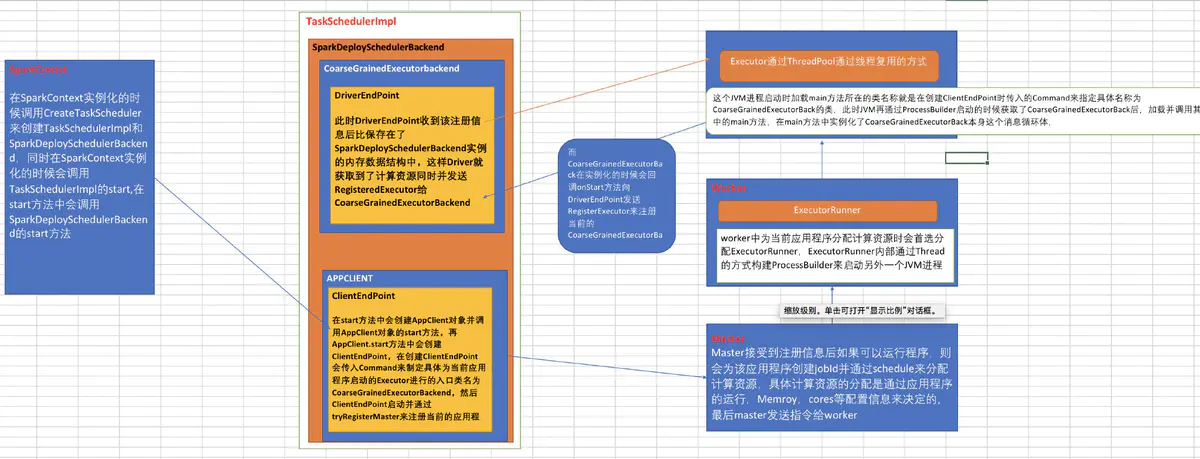
在SparkContext实例化的时候调用CreateTaskScheduler来创建TaskSchedulerImpl和SparkDeploySchedulerBackend,同时在SparkContext实例化的时候会调用TaskSchedulerImpl的start,在start方法中会调用SparkDeploySchedulerBackend的start方法,在start方法中会创建AppClient对象并调用AppClient对象的start方法,再AppClient.start方法中会创建ClientEndPoint,在创建ClientEndPoint会传入Command来制定具体为当前应用程序启动的Executor进行的入口类名CoarseGrainedExecutorBackend,然后ClientEndPoint启动并通过tryRegisterMaster来注册当前的应用程序到Master中,Master接受到注册信息后如果可以运行程序,则会为该应用程序创建jobId并通过schedule来分配计算资源,具体计算资源的分配是 通过应用程序的运行,Memroy,cores等配置信息来决定的,最后master发送指令worker,worker中为当前应用程序分配计算资源时会首先分配ExecutorRunner,ExecutorRunner内部通过Thread的方式构建ProcessBuilder来启动另外一个JVM进程,这个JVM进程启动时加载main方法所在的类名称就是在创建ClientEndPoint时传入的Command来指定具体名称为 CoarseGrainedExecutorBackend的类,此时JVM再通过ProcessBuilder启动的时候获取了CoarseGrainedExecutorBackend后,加载并调用其中的main方法,在main方法中实例化了CoarseGrainedExecutorBackend本身这个消息循环体,而CoarseGrainedExecutorBackend在实例化的时候会回调onStart方法向DriverEndPoint发送RegisterExecutor来注册当前的 CoarseGrainedExecutorBackend,此时DriverEndPoint收到该注册信息后比保存在了SparkDeploySchedulerBackend实例的内存数据结构中,这样Driver就获取到了计算资源,同时并发送RegisteredExecutor给CoarseGrainedExecutorBackend;
ShuffleManager和ShuffleWriter和ExternalSort关系
Task生成与提交架构图