

本文始发于个人公众号:TechFlow,原创不易,求个关注
今天是分布式专题的第10篇文章,我们继续来聊聊LSMT这个数据结构。
LSMT是一个在分布式系统当中应用非常广泛,并且原理直观简单的数据结构。在上一篇文章当中我们进行了详细的讨论,有所遗忘或者是新关注的同学可以点击下方的链接回顾一下上一讲的内容。
leveldb简介
上一篇的内容我们介绍的算是最基础版本的LSMT,在这一篇当中,我们来具体看下levelDB这个经典的KV数据库引擎当中LSMT的使用以及优化。
leveldb,既然是叫做db,显然和数据库有关。和一般的关系型数据库不同,它内部的数据全部以KV也就是key-value形式存储,并且不支持结构化的SQL进行数据查询,只支持api调用。也就是说它就是一个典型的我们常说的noSQL数据引擎库。它最早由google开发并且开源,Facebook在此基础上进行优化,推出了更普及的RocksDB,后来包括TiDB等多种分布式noSQL数据库的底层都是基于leveldb。
如果上面这些名词你都没听说过,也没有关系,对于这些库而言,上手去用容易,但是了解原理难。搞懂了原理再实际上手去用,除了更加简单之外,也会有更多的体会。
leveldb架构
这是一张leveldb的架构图,比之前介绍的裸的LSMT的架构图要复杂一些,但是核心本质是一样的,我们一个一个来看。
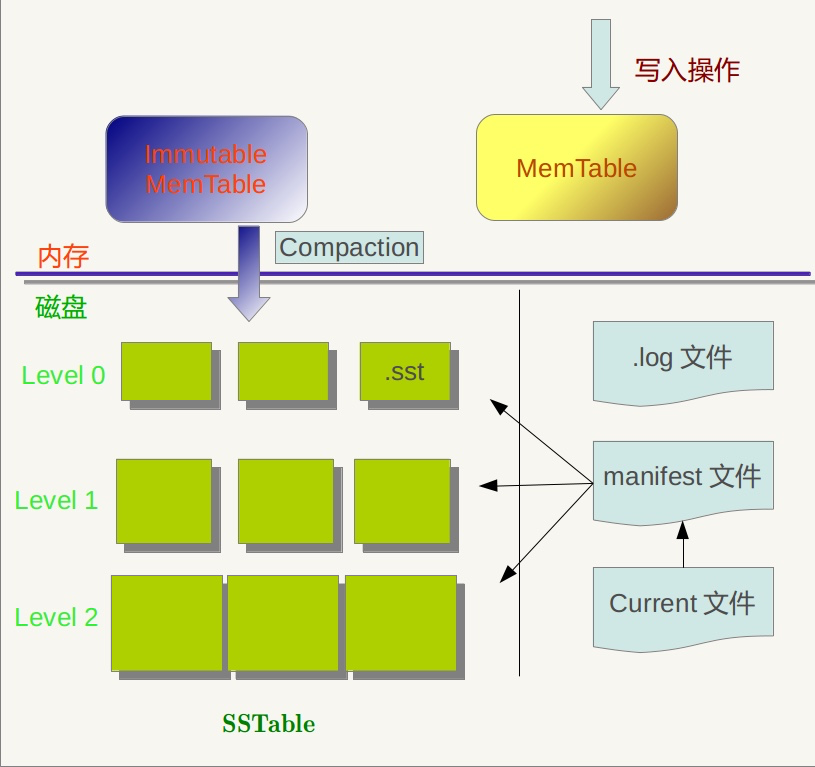
首先上层是MemTable,和Immutable MemTable。MemTable我们都知道,其实本质上就是一个存放在内存当中的数据结构。可以是SkipList也可以是红黑树或者是其他的平衡树(在leveldb当中,使用的是SkipList),我们只需要确定,它是存储在内存当中的。Immutable MemTable其实也是MemTable,前面的Immutable是不可修改的意思。之前我们说过,当MemTable当中的内容超过某个阈值的时候,我们需要将其中的内容写成一个SSTable的文件。这个ImmuTable MemTable就是在这个时候用的。
当一个MemTable在开始执行持久化之前,会先转化成ImmuTable MemTable,可以认为是加上了不可修改的限制。另外,会再新建一个新的MemTable,用于维持服务。之后再将ImmuTable MemTable写入进SSTable文件。
打个比方,MemTable就好像是收银台里的收银柜,当我们一个门店开张,显然需要有收银柜存放顾客付的钱。当收银柜快满的时候,我们需要将里面的钱存入银行。但是里面的钱不少,并且还有顾客在源源不断地付钱,我们让它停一会会带来损失。所以我们把整个收银柜一起拿走,为了安全,我们在外面加上一把锁,锁起来连同收银柜送到银行。但是收银台不能没有收银柜啊,所以我们还需要拿出一个新的收银柜给收银台去收钱。
在这个例子当中,一开始负责收钱的收银柜就是MemTable,加了锁之后变成了Immutable MemTable。也许不是非常恰当,但是对照一下,应该很容易理解。
其次是.log文件,这个很好理解,之前的LSMT当中也有这个文件,用来存储发生变更的数据。类似于数据库当中的binlog,用来在系统发生故障重启时恢复数据。
接着我们来看SSTable,在原始的LSMT当中SSTable是顺序存储的,所以我们在查询数据的时候才是依次查询,当发现第一个SSTable当中没有我们要查询的内容的时候,就往下查询下一个文件。而在leveldb当中,SSTable是按照层级存储的,第一层是level0,第二层是level1,以此类推,层级逐渐增高。这也是leveldb得名的原因。
我们之前介绍过SSTable的本质是一个key-value的序列表,并且其中的key是有序的。既然SSTable当中的key是有序的,那么显然就有最大值和最小值。我们把最大值和最小值记录下来就可以在查询的时候快速判断,我们要查询的key它可能在哪些SSTable当中,从而节省时间,加快效率。

这个记录SSTable文件当中的最小key和最大key的文件就是manifest,除了最小最大key之外,还会记录SSTable属于哪个level,文件名称等信息。我们可以对照下下图当做一个参考:

最后是Current文件,从名字上来看,Current像是一个指针的名字。的确,Current是一个指针。因为在实际运行当中manifest文件不止一个,因为伴随着我们的压缩等操作,都会产生新的manifest。我们需要一个指针记录下来当前最新的manifest文件是哪一个,方便查找。而且manifest当中的数据量并不小,所以我们不能全部都存放在内存当中,放在文件里用一个指针引用是最佳选择。
leveldb的增删改查
leveldb的写入
leveldb当中的写、删、改操作和裸的LSMT基本一样,分成以下几个步骤。
首先,会将变更的数据写入.log文件当中。这是为了持久化数据,放置系统宕机导致数据丢失。
当写入.log文件成功之后,写入MemTable。由于leveldb中的MemTable采用SkipList实现,所以写入速度也会很快,大约是的复杂度。如果MemTable容量达到或者超过阈值,会触发进一步写入SSTable的操作。在这个写入当中,首先会将MemTable转化成Immutable MemTable,之后会新建一个空的MemTable应对后续的请求,当dump指令下达之后,会将Immutable MemTable写入成SSTable文件进行存储。
以上的流程和LSMT大同小异,只有一些细微的区别。另外严格说起来leveldb不支持修改操作,可以转化成插入一条新数据,或者是先删除旧数据再插入,这两者本质上是一样的,会在后续数据压缩的过程当中进行合并。
leveldb的读取
leveldb的读操作和LSMT稍稍有所区别,我们结合下面这张图来详细看下。
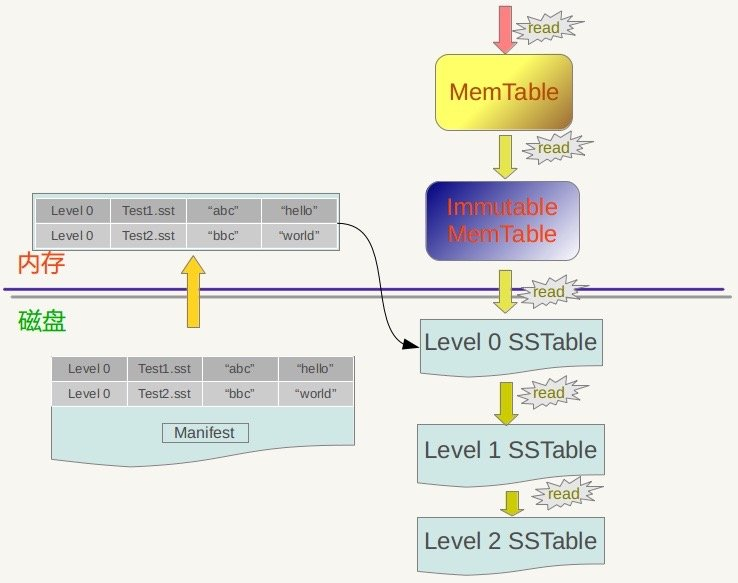
首先,当我们执行查找指令的时候,我们首先会在MemTable和Immutable MemTable当中进行查找。这一点很容易理解,因为MemTable和Immutable MemTable都是完善的数据结构,支持快速查找。有些同学可能会觉得奇怪,Immutable MemTable不是写入文件当中了么,怎么还能进行查找。这是因为当MemTable转化成Immutable MemTable之后到写入磁盘会有一个等待时间,并不是立即执行的。在执行写入之前,Immutable MemTable当中可能都会有数据残留,需要进行查找是必要的。
如果在MemTable和Immutable MemTable当中都没有找到,那么我们则会读取磁盘中的数据进行查找。
和裸的LSMT按照顺序一个一个查找SSTable不同,leveldb会首先读取manifest文件,根据manifest文件当中记录的key的范围来找到可能出现的SSTable文件。
对于同一个key来说,可能同时出现在不同level的SSTable当中,但是由于leveldb在写入SSTable的时候遵循越晚写入的数据越新的原则。也就是说level序号越小的数据越新,所以如果找到了多个值,那么优先返回上层的结果。
整个leveldb的读写可以看得出来是在原本LSMT的基本上加入的优化,并没有太多难以理解的东西,还是比较简明直接的。在一些场景当中,我们的内存资源比较充足,并且对于查找有一定的要求,我们可以将manifest缓存在内存当中,这样可以减少读取manifest文件的时间,起到加速的作用。但是同时,也带来了维护缓存的成本,这一点会在之后介绍缓存的文章当中详细介绍。
leveldb的压缩策略
最后,我们来看下leveldb的压缩策略,这也是leveldb的精髓。
Google有一篇Bigtable: A Distributed Storage System for Structured Data的论文, 这一篇论文可以认为是leveldb的理论基础。在BigTable的论文当中,提到了三种压缩策略。
第一种策略叫做minor Compaction,这一种策略非常简单,就是简单地把MemTable中的数据导入到SSTable。
第二种策略叫做major Compaction,这种策略中会合并不同层级的SSTable文件,也就是说major Compaction会减少level的数量。
最后一种策略叫做full Compaction,这一种策略会将所有的SSTable文件合并。
在leveldb当中,实现了前面两种压缩策略,minor Compaction和major Compaction,下面我们来详细研究一下。
minor Compaction
minor Compaction很简单,刚才说过了其实就是将MemTable也就是SkipList当中的数据写入到磁盘生成SSTable文件。

我们之前的文章当中介绍过SkipList,它的本质是一个有序的链表。而我们想要生成的SSTable也刚好是有序的。所以我们只需要依次遍历写入即可。对SkipList感兴趣或者是想要复习的同学可以点击下方的链接回顾一下:
根据越晚生成的SSTable level序号越小,层级越高的原则,我们最新生成的SSTable是level0。之后我们要记录这个新生成的SSTable当中的索引,完成写入操作。需要注意的是,在这个过程当中,我们不会对数据进行删除操作。原因也很简单,因为我们并不知道要删除的数据究竟在哪个level下的SSTable里,找到并删除会带来大量的耗时。所以我们依旧会原封不动地记录下来,等待后续的合并再处理这些删除。
另外,在文件的末尾部分会将key值的信息以索引的形式存储。由于我们读取文件的时候是倒序读取的,所以优先会读取到这些索引信息。我们就可以根据读取到的索引信息快速锁定SSTable当中的数据而不用读取整个文件了。
major Compaction
接下来我们来看major Compaction。这也是leveldb分层机制的核心,不然的话插入SSTable也只会都是level0,层次结构就无从谈起了。
在详细介绍之前,我们需要先弄清楚一个洞见。对于leveldb当中其他level的SSTable文件而言,都是通过major Compaction生成的。我们可以保证同一层的SSTable没有重叠的元素,但是level0不同,level0当中的SSTable是通过minor Compaction生成的,所以是可能会有重叠的。
leveldb当中触发major Compaction的情况并不止一种,除了最常提到的Size Compaction之外还有两种,一种是manual Compaction,还有一种是seek Compaction。下面来简单介绍一下。
manual Compaction很好理解,就是人工手动触发,通过接口调用人为地去触发它执行Compaction。size Compaction相当于平衡操作,当系统发现某一层的SSTable数量超过阈值的时候会触发。最后一种是seek Compaction,这一种比较机智,leveldb会记录每一层level中每一个SSTable文件的miss rate。就是当发现某一个文件当中的数据总是miss,而在下一层的文件当中查找到了值,这个时候leveldb就会认为这个文件不配待在这一层,将它和下一层的数据进行合并,以减少IO消耗。
当然以上三种触发Compaction的情况当中,最常出现的还是size Compaction,就是当leveldb发现某一层的SSTable数据或者是大小超过阈值的时候,会执行Compaction操作。
在major Compaction当中,假设leveldb选择的是level i的文件进行合并。这个时候需要分情况讨论,如果i=0,也就是说我们要合并的是level 0的数据。由于刚才提到的,level 0当中不同文件的数据是存在重叠的,这个时候需要将所有key值有重叠的文件都纳入到待合并的集合当中来。在挑选待合并集合的时候,leveldb会记录上一次触发压缩时的最大key值,这一次会选择大于这个key值的文件开始执行压缩。
也就是说leveldb设计了一种轮流机制,保证level当中的每一个文件都有被合并的机会。
当我们level i的文件选择结束之后,接下来就要从level i+1当中选择文件进行合并了。选择的标准也很简单,我们会将所有和待合并集合中key值有重叠的文件全部挑选出来进行合并。
合并的过程本质上是一个多路归并的过程,如下图所示:
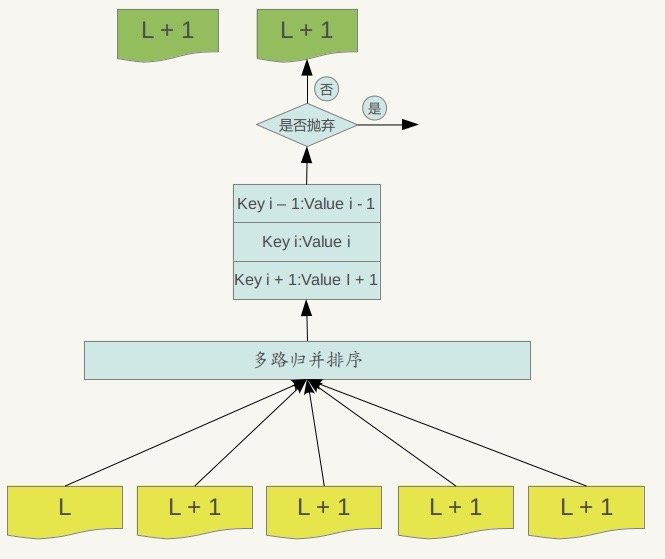
由于所有文件当中的key值都是有序的,我们都从它们的头部开始。对于每一个key我们都会进行判断,是应该保留还是丢弃。判断的逻辑也很简单,对于某一个key而言,如果这个key在更低级的level中出现过,那么说明有更新的value存在,我们需要进行抛弃。
当Compaction完成之后,所有参与归并的文件都已经没有用处了,可以进行删除。
从本质上来说这个归并过程和裸的LSMT原理是一样的,只是增加了层次结构而已。
到这里还没有结束,还记得我们有一个记录所有SSTable索引的manifest文件吗?不论哪一种Compaction的发生,都会改变整个level的结构,所以我们需要在每一次Compaction之后,都会生成一个新的manifest文件,然后将此次Compaction带来的文件变动记录进去。最后,将Current指向新生成的manifest。
这样,我们整个过程就串起来了。
总结
我们回顾一下整个流程,会发现虽然增删改查以及Compaction的操作增加了许多细节,但是底层的框架其实还是LSMT那一套。因为核心的原理是一样的,所以和纯LSMT一样,leveldb当中的SSTable同样可以使用布隆过滤器来进行优化,除此之外,还有cache的灵活使用,可以进一步提升查询的效率。
另外,需要注意的是,leveldb严格说起来只是数据库引擎,并不是真正的数据库系统。基于leveldb我们可以开发出比较完善的数据库系统,但它本身只提供底层最核心增删改查服务的基础。除了基础功能之外,一个成熟的数据库系统还需要开发大量的细节以及做大量的优化。目前为止基于leveldb开发的数据库引擎很多,但完整的数据库系统非常少,毕竟这需要长久时间开发和积累。
如果我们简单把分布式系统分成分布式计算系统和分布式存储系统的话,会发现分布式存储系统的精华占了大半。而分布式存储系统又可以简单认为是底层的数据结构加上上层解决分布式带来的一致性等问题的共识协议。而分布式存储系统当中常用的底层数据结构无非也就那么几种,所以说我们对于这些数据结构的了解和学习是以后深入理解分布式系统的基础。而一个合格且优秀的系统架构师,解决业务场景当中的分布式问题是常态,而解决问题的能力的核心,其实就在于对这些底层基础知识的理解和运用。
今天的文章就是这些,如果觉得有所收获,请顺手点个关注或者转发吧,你们的举手之劳对我来说很重要。

