

为什么要学习这个算法
我们公司一直都有的一个敏感词检测服务,前一段时间遇到了瓶颈,因为词库太多了导致会有一些速度过慢,而且一个正则表达式已经放不下了,需要进行拆分正则才可以。
正好我以前看过有关 dfa 的介绍,但是并没有深入的进行研究,所以就趁着周末好好的了解一下这个东西。跟 php 的正则进行一下对比,看看速度如何,如果表现较好,说不定还能用得上。
什么是 dfa
通过百度可以知道 dfa 是 确定有穷自动机 的缩写。
应该还会见到类似下面图的说明
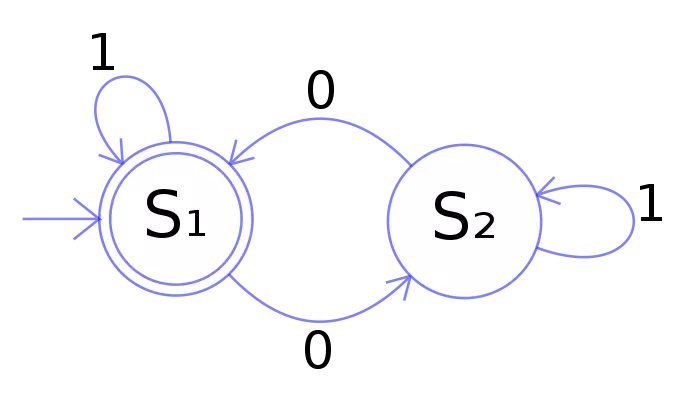
我的理解
说明之前,我们先看看做检测需要准备的东西
- 一个组织好的关键词树
- 待检测的字符串
什么是组织好的关键词树
我们一批需要检测词库,比如下面这些
日本人,日本鬼子,日本人傻,破解*版
先做个解释,前三个大家都能看懂,那么 * 是什么,这个是我定义的通配符,代表着 * 可以是 0 - n 个占位符用来替代在关键词中间插入混淆字符。至于可以替换几个我们可以在代码中进行定义,需要注意 n 越大,速度就会越慢。
说明完了,来看看构造好的树是什么一样的,应该是跟下图差不多的。
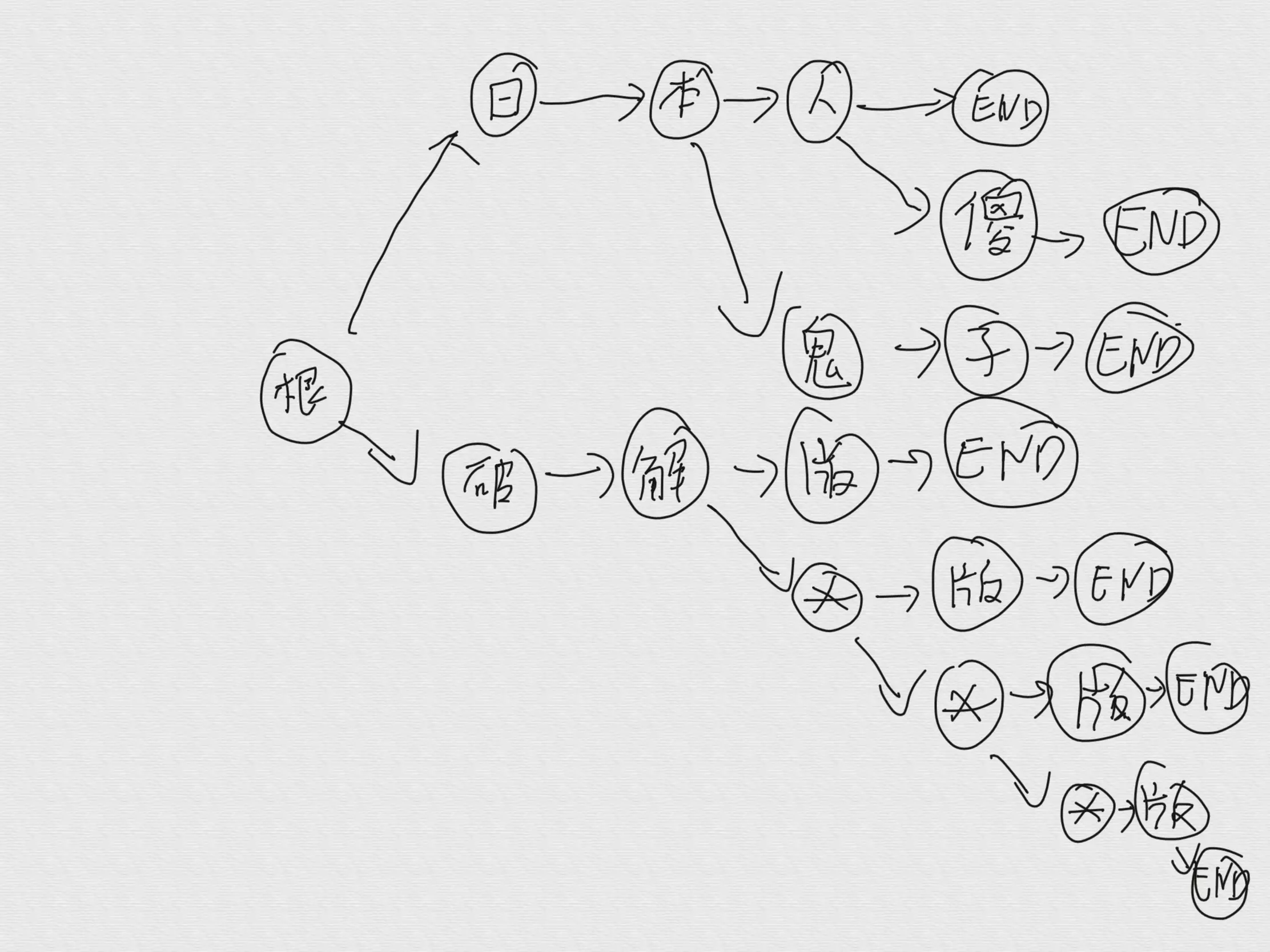

待检测的字符串
这个就很容易理解了,就是我们需要检测的字符串。
为什么要组织好那样的一棵树(算法思路)
这块需要先说一个概念
它是是通过event和当前的state得到下一个state,即event+state=nextstate
这句话,或者类似的话你会在绝大多数的解释文章里面看到。而我的理解就是,一个字符一个字符的检测,如果检测的字符在我们的树种,就进入命中的树,看下一个字在不在树里面,如果持续的命中就持续进入,最后完全命中了,也就是那个字的子树只有一个元素,并且元素的键是 end (这里是在我们的这个例子中,看图就明白了)。就是完全命中了关键词,就可以记录命中,或者准备替换了。
这里说一个可以优化的点,看我们的例子有两个词 日本人,日本鬼子 这两个,如果为了快,完全可以去掉第二个词,质保流一个就行了,这样当检测到 end 就可以直接屏蔽或者记录了,而在我们的例子中,还需要判断元素数量,不是 1 的情况下还得继续深入,看看是不是命中了长尾。
这样的长尾检测会引发一个问题,那就是 回滚,当我们命中了前置的词,后续的没有命中的时候就得记录并且回滚,这个回滚的长度是是多少呢?其实不仅仅是没有命中长尾的回滚,还有一个 回滚 操作,就是检测率几个字之后就没命中率额,就得回顾,这个回滚的长度是,已检测字符长度 - 1 的长度 。那么没有命中长尾的长度我们就知道了,已检测字符长度 - 上次命中的长度 就可以了。
下面我们来看看代码实现。
// 通配符的数量
$maskMin = 0;
$maskMax = 3;
// 关键词词典字符串,这个部分的处理自己可以替换
$dict = "傻瓜";
$checkDfaTree = [];
$dictArr = explode(',', $dict);
// 重组一下带有 * 通配符的数组
$fullDictArr = [];
foreach ($dictArr as $word) {
if (mb_strpos($word, '*') !== false) {
// 带有通配符就把通配符去掉
for ($maskIndex = $maskMin; $maskIndex <= $maskMax; $maskIndex++) {
$maskString = str_pad('', $maskIndex, '*');
$inputWord = str_replace('*', $maskString, $word);
$fullDictArr[] = $inputWord;
}
} else {
$fullDictArr[] = $word;
}
}
foreach ($fullDictArr as $word) {
// 每次开始新词都要回到树的根部
$treeStart = &$checkDfaTree;
$wordLen = mb_strlen($word);
for ($i = 0; $i < $wordLen; $i++) {
$char = mb_substr($word, $i, 1);
$treeStart[$char] = isset($treeStart[$char]) ? $treeStart[$char] : [];
if ($i + 1 == $wordLen) {
// 如果已经是次的结尾了就设置null
$treeStart[$char]['end'] = true;
}
// 移动指针到下一个
$treeStart = &$treeStart[$char];
}
}
// 遍历str
$start = microtime(true);
$checkMessageLen = mb_strlen($checkMessage);
$wordArr = [];
$checkTreeStart = &$checkDfaTree;
$hasPrefixLength = 0;
$targetWord = '';
for ($i = 0; $i < $checkMessageLen; $i++) {
// 获取一个字符
$char = mb_substr($checkMessage, $i, 1);
if (isset($checkTreeStart[$char])) {
// 如果有这个字就进入子树里面
if (isset($checkTreeStart[$char]['end']) && $checkTreeStart[$char]['end'] === true) {
// 如果包含这个标识,就记录标识
$hasPrefixLength = mb_strlen($targetWord);
}
$checkTreeStart = &$checkTreeStart[$char];
$targetWord .= $char;
} else if (isset($checkTreeStart['*'])) {
// 如果有通配符就进入子树
$checkTreeStart = &$checkTreeStart['*'];
$targetWord .= $char;
} else {
if ($hasPrefixLength) {
$wordArr[] = mb_substr($targetWord, 0, $hasPrefixLength + 1);
// 回滚
$i -= mb_strlen($targetWord) - $hasPrefixLength;
} else {
// 回滚
$i -= mb_strlen($targetWord);
}
// 回到头部
$checkTreeStart = &$checkDfaTree;
$targetWord = '';
$hasPrefixLength = 0;
}
if (count($checkTreeStart) == 1 && isset($checkTreeStart['end']) && $checkTreeStart['end'] === true) {
// 子树只有一个并且是end 就说明是命中了
// 赋值
$wordArr[] = $targetWord;
// 清空
$targetWord = '';
// 回到头部
$checkTreeStart = &$checkDfaTree;
$hasPrefixLength = 0;
}
}
var_dump($wordArr);
echo "<br /> useTime:" . (microtime(true) - $start) * 1000;
下面这个就是匹配加测试了,目前我能想到的都测试通过了,如果有问题,可以回复我。
结论
目前来看,效率是比正则要好一些,命中的情况下速度差不多,没命中的情况下表现要优于正则。
