

- 本文首发自公众号:RAIS
前言
本系列文章为 《Deep Learning》 读书笔记,可以参看原书一起阅读,效果更佳。
超参数
- 参数:网络模型在训练过程中不断学习自动调节的变量,比如网络的权重和偏差;
- 超参数:控制模型、算法的参数,是架构层面的参数,一般不是通过算法学习出来的,比如学习率、迭代次数、激活函数和层数等。
与超参数对比的概念是参数,我们平时训练网络所说的调参,指的是调节 超参数。超参数的确定方法一般是凭借经验,或者类似问题的参数迁移。
问题来了,为啥超参数不通过学习确定?这是因为这个参数不那么好优化,并且稍不留神通过学习方法去优化就可能导致过拟合。你可能认为模拟人的调参过程,进行超参数的调节不就好了,当然这是可以的,超参数也不是完全不可以用程序优化的,但是现有的理论还不成熟,还没有理论去有效的指导实践,这还是一个新兴领域,因此还有许多工作要做,很多情况下是凭经验,凭直觉进行优化的,算法表现并不好。
我们知道,更高次的多项式和权重衰减参数设定 λ=0 总是能更好的拟合,会过拟合,对于这个问题,我们会考虑用验证集的方法,验证集在我们前文《人工智能二分类问题》中提到过。
验证集
验证集是用来训练超参数的,是用来给网络提供反馈的。我们用训练集去训练一个网络模型,训练出的参数固定下来,然后将验证集的数据应用到这个模型上,会得到偏差,我们根据这个偏差,调整超参数,然后重新去训练网络,重复迭代一定的次数,会调节出一个超参数还不错的网络,基于这个超参数训练出的模型,可以最终到测试集合上验证,最终确定在测试集上表现如何。下面举个例子:
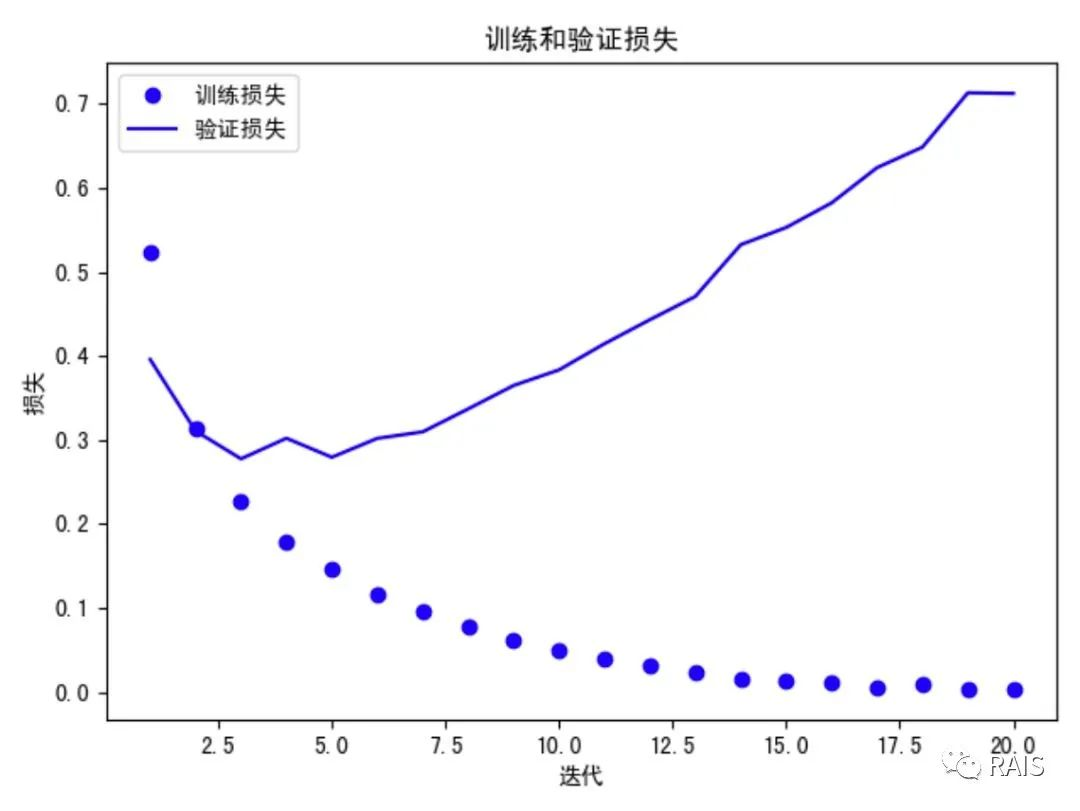
这是之前在《人工智能二分类问题》中的一张图,我们看到验证损失在迭代 4 次之后大幅上升,这就是由于我们训练次数迭代过多导致的,迭代次数这个超参数设置的不合理,因此我们更改迭代次数为 4 次。这就是根据验证集调节超参数的一个例子。
数据量小,训练集:验证集:测试集=6:2:2,数据量足够大,训练集:验证集:测试集=98:1:1。这算是一个经验值吧。
K-折交叉验证
我们在之前的 《预测房价》 问题中有提到过交叉验证这个方法,这个方法用于解决的问题就是数据量太小的问题,而导致的对网络测试误差估计不准的问题,K-折交叉验证 是其中最常见的。
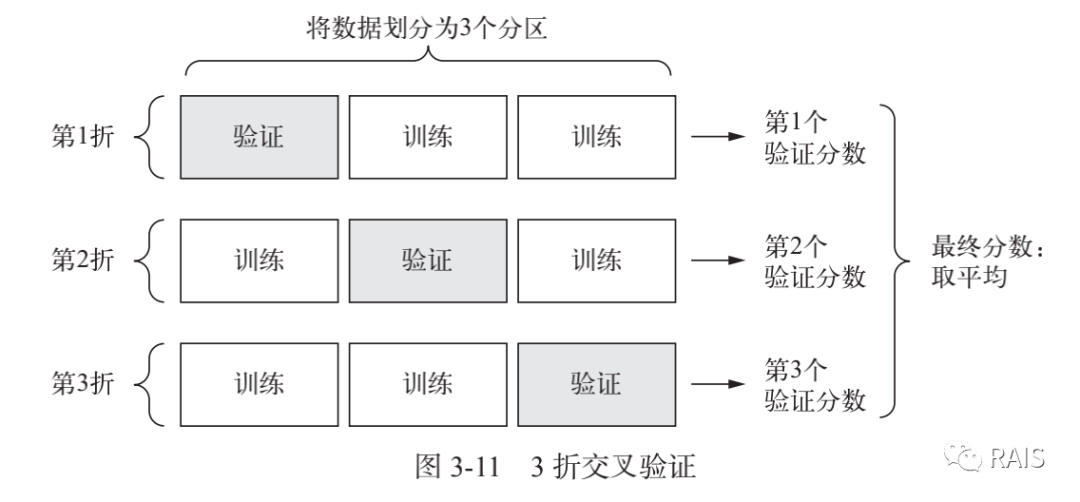
从上图中,我们可以清楚的看到K-折交叉验证的方法具体是怎么做的。由于数据量不够大,因此我们把数据分为 K 份,循环 K 次,每次分别选取其中的一份作为测试集,这样根据我们训练出的网络,我们可以分别求出每一次的测试误差,用这 K 个测试误差求其平均值,我们就估计其为这个网络的测试误差。
总结
我们本篇文章介绍了参数和超参数的区别,调参指的是调节超参数,并且介绍了在数据量较小的情况下如何如何去估计测试误差。

- 本文首发自公众号:RAIS
