


1. ObjectDecoder和ObjectEncoder 编解码器
1. ObjectEncoder
An encoder which serializes a Java object into a {@link ByteBuf}.
将一个java对象序列化成一个 ByteBuf 对象 , 注意Java对象需要实现java.io.Serializable 接口
2. ObjectDecoder
A decoder which deserializes the received {@link ByteBuf}s into Java objects.
将一个 ByteBuf 反序列成一个java对象 , 注意Java对象需要实现
java.io.Serializable接口
3. 快速开始
第一步一个java对象 必须是实现Serializable接口
public class OPack implements Serializable {
private static final long serialVersionUID = -5734509523963527363L;
String name;
String msg;
.... 其他省略 , get , set方法之类的
}
客户端服务器都添加这两个 编码器和解码器
ch.pipeline().addLast(new ObjectEncoder());
ch.pipeline().addLast(new ObjectDecoder(1004, new ClassResolver() {
@Override
public Class<?> resolve(String className) throws ClassNotFoundException {
return OPack.class;
}
}));
自己写一个 ChannelInboundHandlerAdapter实现channelRead() 方法就可以了 , 很简单 , 或者 SimpleChannelInboundHandler<T> 的 channelRead0() 方法,
4. 编解码器源码分析
1. ObjectEncoder 编码器
public class ObjectEncoder extends MessageToByteEncoder<Serializable> {
// 这是一个int 的 byte数组 , 因为int是四个字节
private static final byte[] LENGTH_PLACEHOLDER = new byte[4];
@Override
protected void encode(ChannelHandlerContext ctx, Serializable msg, ByteBuf out) throws Exception {
// 写指针
int startIdx = out.writerIndex();
//
ByteBufOutputStream bout = new ByteBufOutputStream(out);
//
ObjectOutputStream oout = null;
try {
// 首先写入一个4字节的数组
bout.write(LENGTH_PLACEHOLDER);
oout = new CompactObjectOutputStream(bout);
// 其次再写入一个对象
oout.writeObject(msg);
oout.flush();
} finally {
....
}
// 获取写指针
int endIdx = out.writerIndex();
// 设置长度值
out.setInt(startIdx, endIdx - startIdx - 4);
}
}
自己玩一玩 ........
ByteBuf out = Unpooled.buffer(1024);
// w指针位置
int start = out.writerIndex();
// 设置一个输出流
ByteBufOutputStream bbos = new ByteBufOutputStream(out);
// 首先写一个 4个字节长度的数组
bbos.write(new byte[4]);
// 对象流
ObjectOutputStream objectOutputStream = new ObjectOutputStream(bbos);
// 写一个obj
objectOutputStream.writeObject(new OPack("hhh", "hhh"));
// W 最终位置
int end = out.writerIndex();
// 在buf对象的 start 位置 设置一个 int值为 end-start-4 就是对象的长度 ,所以对象长度就算出来了
out.setInt(start, end - start - 4);
System.out.println("out = " + out);
System.out.println("out.readInt() = " + out.readInt());
// 看看计数引用
System.out.println("out.refCnt() = " + out.refCnt());
输出
out = UnpooledByteBufAllocator$InstrumentedUnpooledUnsafeHeapByteBuf(ridx: 0, widx: 117, cap: 1024)
out.readInt() = 113
out.refCnt() = 1
2. ObjectDecoder 解码器
public class ObjectDecoder extends LengthFieldBasedFrameDecoder {
private final ClassResolver classResolver;
public ObjectDecoder(ClassResolver classResolver) {
this(1048576, classResolver);
}
// 这个意思每帧 1048576 长度
// 长度的偏移量为0 , 占用 4个字节 , 最后去掉前面的4个字节
public ObjectDecoder(int maxObjectSize, ClassResolver classResolver) {
super(maxObjectSize, 0, 4, 0, 4);
this.classResolver = classResolver;
}
@Override
protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {
// 直接调用父类的decode() 方法 , 返回的是已经扣除了我们4个字节长度的 ByteBuf方法
ByteBuf frame = (ByteBuf) super.decode(ctx, in);
if (frame == null) {
return null;
}
// 这个代码有两处 一处是释放ByteBuf , 一处是转成一个ObjectInputStream对象
ObjectInputStream ois = new CompactObjectInputStream(new ByteBufInputStream(frame, true), classResolver);
try {
// 最后读取就行了
return ois.readObject();
} finally {
ois.close();
}
}
}
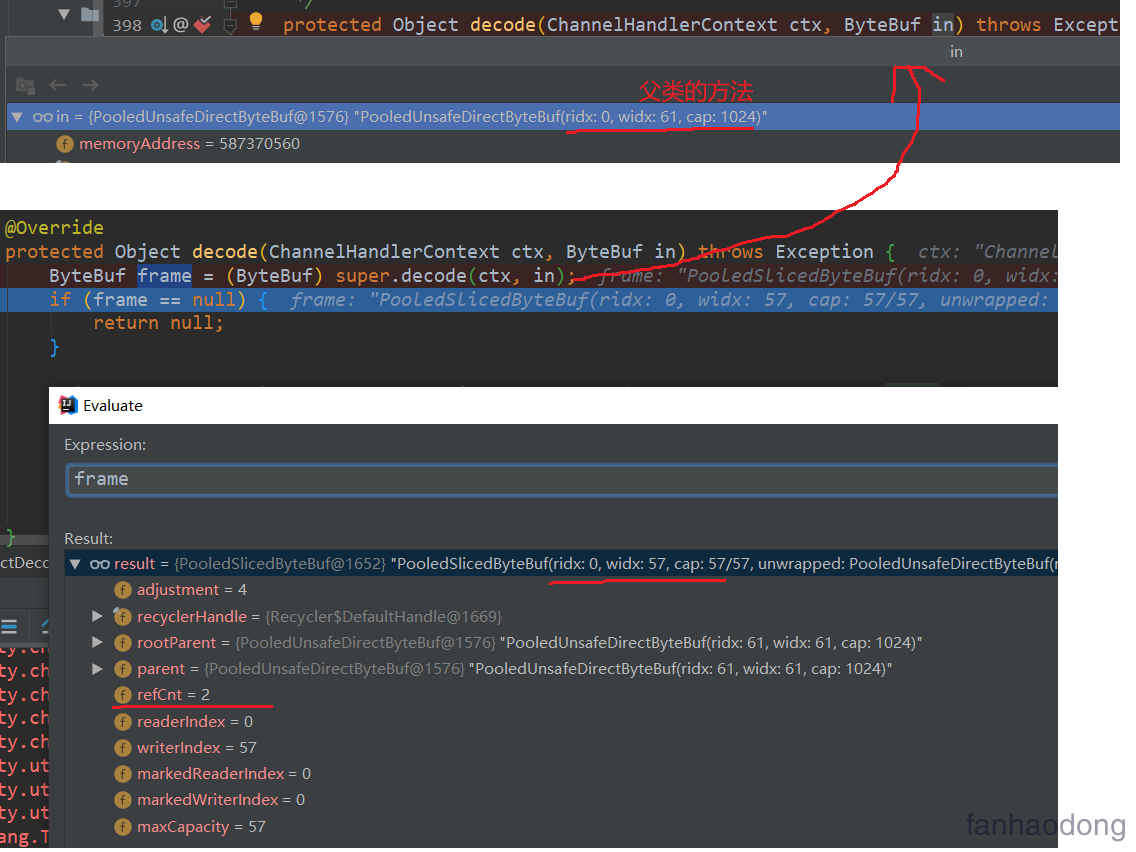
我这里有一张图 , 可以清晰的看到前面变化 , 变化点就是我上面提到的 , 我会在下面讲解LengthFieldBasedFrameDecoder 源码的时候对其分析 , 还要注意一点就是你获取的计数引用此时是2 ,这个需要手动释放 , 上面注释我已经提到了 ....netty已经帮我们释放了 ,但是我debug 发现并没有释放,而是后面有一处进行了一次release .
2. StringEncoder和StringDecoder - 字符串编解码器
这俩实现了
MessageToMessageEncoder<I>和MessageToMessageDecoder<I>实现还是蛮简单的 StringDecoder 就是将ByteBuf转换成了 String ,调用的是
ByteBuf.toString(charset)方法 , StringEncoder 就是将 String转换成了 ByteBuf , 调用的是
ByteBufUtil.encodeString(ctx.alloc(), CharBuffer.wrap(msg), charset)这个方法
服务器端 :
final StringServerHandler stringServerHandler = new StringServerHandler();
// 管道中添加处理器
ChannelPipeline pipeline = ch.pipeline();
// 添加 字符串编解码器 ,
pipeline.addLast(new StringEncoder(CharsetUtil.UTF_8));
pipeline.addLast(new StringDecoder(CharsetUtil.UTF_8));
// 自己实现的
pipeline.addLast("serverHandler", stringServerHandler);
我们的处理器StringServerHandler 实现了 SimpleChannelInboundHandler<String> ,
private static class StringServerHandler extends SimpleChannelInboundHandler<String> {
@Override
protected void channelRead0(ChannelHandlerContext ctx, String msg) throws Exception {
logger.info("[服务器] 接收到信息 : {}", msg);
ctx.writeAndFlush("服务器收到信息");
}
}
测试用例 : 发现OK
io.netty.handler.codec.string.StringEncoder 基本实现代码
@Override
protected void encode(ChannelHandlerContext ctx, CharSequence msg, List<Object> out) throws Exception {
if (msg.length() == 0) {
return;
}
out.add(ByteBufUtil.encodeString(ctx.alloc(), CharBuffer.wrap(msg), charset));
}
io.netty.handler.codec.string.StringDecoder 基本实现
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf msg, List<Object> out) throws Exception {
out.add(msg.toString(charset));
}
3. FixedLengthFrameDecoder - 定长解码器
1. 源码
public class FixedLengthFrameDecoder extends ByteToMessageDecoder {
// 定长
private final int frameLength;
public FixedLengthFrameDecoder(int frameLength) {
checkPositive(frameLength, "frameLength");
this.frameLength = frameLength;
}
// ByteToMessageDecoder 的实现方法
@Override
protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
// 先去执行这个方法 -- >
Object decoded = decode(ctx, in);
// null 直接不管了 , 直接丢入缓冲区了
if (decoded != null) {
// 不为空就添加进去
out.add(decoded);
}
}
// -- > 到这里
protected Object decode(
@SuppressWarnings("UnusedParameters") ChannelHandlerContext ctx, ByteBuf in) throws Exception {
// 小于直接返回null
if (in.readableBytes() < frameLength) {
return null;
} else {
// 等于或者等于就截取固定长度
return in.readRetainedSlice(frameLength);
}
}
}
2. 基本使用
ByteBuf buf = Unpooled.buffer(8);
// 0000 0000 , 0000 0000 , 0010 0111 , 0001 0000
/ 0 0 39 16
buf.writeInt(10000);
//0000 0000 , 0000 0000 , 0000 0000 , 0110 0100
// 0 0 0 100
buf.writeInt(100);
// 我们将服务器端 new FixedLengthFrameDecoder(6) 长度调整为6个字节
// 然后客户端发送两次给服务器 -> 连续发两次buf对象
结果 :
第一次 : 0 0 39 16 0 0
第二次 : 0 100 0 0 39 16
我们发现第一次发送过去的数据 , 后两个字节在第二次发送的前面两个字节 , 此时 我们就肯定了 , 第一次发送过去没有收到的在缓冲区里面 , 这个缓冲区是每一个客户端与服务器连接都会有一个与这个客户端想对应的缓冲区 , 不是共同缓冲区 ...
4. LengthFieldBasedFrameDecoder - 自定义解码器
1. 构造方法
new LengthFieldBasedFrameDecoder(ByteOrder byteOrder, int maxFrameLength, int lengthFieldOffset, int lengthFieldLength,int lengthAdjustment, int initialBytesToStrip, boolean failFast);
// byteOrder : 大端\小端
// maxFrameLength : 帧指的意思就是每次一客户端像服务器发送的数据包接收的缓冲区最大值 ,
// lengthFieldOffset : 数据包长度的偏移量
// lengthFieldLength : 数据包长度的长度 ,比如short就是2个字节 , int 就是4个字节
// lengthAdjustment : 比如我们输入的是(10, 0, 2,-2,0), 传入入的数据是[10(short),100(int),1000(int)], 那么我们就需要调整一下,就是-2 , 让长度-2,就是我们实际的数据长度为8 , 数据为(100,10000),此时才能正常读取
// initialBytesToStrip : 返回的ByteBuf的时候跳过的字节数
// failFast : 快速失败
2. 简单使用
1. 第一种简单情况(10, 0, 2,0,0)
1. 服务器中添加进去 , 然后添加自己的Handler
ch.pipeline().addLast(new LengthFieldBasedFrameDecoder(8, 0, 2,0,0));
2. 客户端发送数据
// 客户端发送给服务器的数据
ByteBuf buf = Unpooled.buffer(10);
// 长度为8
buf.writeShort(8);
buf.writeInt(10000);
buf.writeInt(100);
3. 服务器端代码
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
if (msg instanceof ByteBuf) {
ByteBuf messages = (ByteBuf) msg;
System.out.println("数据长度 = " + messages.readShort());
System.out.println("数据1 = " + messages.readInt());
System.out.println("数据2 = " + messages.readInt());
} else {
super.channelRead(ctx, msg);
}
}
输出
数据长度 = 8
数据1 = 10000
数据2 = 100
一切OK ,
2. 第二种情况(10, 0, 2,-2,0)
ByteBuf buf = Unpooled.buffer(10);
// 长度为10 ,包含长度字段 ,所以调整为 -2
buf.writeShort(10);
buf.writeInt(10000);
buf.writeInt(100);
服务器端代码不变
输出 , 输出数据一致
数据长度 = 10
数据1 = 10000
数据2 = 100
3. 第三种情况 (10, 0, 2,-2,2)
ByteBuf buf = Unpooled.buffer(10);
// 长度为10 ,包含长度字段 ,所以调整为 -2
buf.writeShort(10);
buf.writeInt(10000);
buf.writeInt(100);
服务器端代码只是去掉长度
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
if (msg instanceof ByteBuf) {
ByteBuf messages = (ByteBuf) msg;
System.out.println("数据1 = " + messages.readInt());
System.out.println("数据2 = " + messages.readInt());
} else {
super.channelRead(ctx, msg);
}
}
输出 , 结果一致 ,很正确 ,是不是会玩了 .........
数据1 = 10000
数据2 = 100
3. 源码分析 :
// 注意 in 直接内存
protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {
// 太长丢弃 , 一开始是false
if (discardingTooLongFrame) {
discardingTooLongFrame(in);
}
// lengthFieldEndOffset = lengthFieldOffset + lengthFieldLength;
// 可读长度小于长度末端的偏移量 ,直接返回空
if (in.readableBytes() < lengthFieldEndOffset) {
return null;
}
// 长度的真实偏移量 = r指针+长度偏移量
int actualLengthFieldOffset = in.readerIndex() + lengthFieldOffset;
// 每一帧的长度 ,其实这个方法就是switch语句1 2 4 8 那种的根据你长度占的字节数进行读取数据长度
long frameLength = getUnadjustedFrameLength(in, actualLengthFieldOffset, lengthFieldLength, byteOrder);
// 长度小于0
if (frameLength < 0) {
failOnNegativeLengthField(in, frameLength, lengthFieldEndOffset);
}
// 比如我的长度包含了长度的字节, 此时就需要调整去处长度所占的字节
// 数据包真实长度 = frameLength + 调整的长度 + 长度末端偏移量
frameLength += lengthAdjustment + lengthFieldEndOffset;
// 长度小于
if (frameLength < lengthFieldEndOffset) {
failOnFrameLengthLessThanLengthFieldEndOffset(in, frameLength, lengthFieldEndOffset);
}
// 数据包长度如果大于maxFrameLength 直接抛出异常了其实
if (frameLength > maxFrameLength) {
exceededFrameLength(in, frameLength);
return null;
}
....
// 跳过初始化的initialBytesToStrip
in.skipBytes(initialBytesToStrip);
// r 指针
int readerIndex = in.readerIndex();
// 真实长度 = 长度-initialBytesToStrip
int actualFrameLength = frameLengthInt - initialBytesToStrip;
// 这里也是切片 , 会计数+1 ,后面会讲到
ByteBuf frame = extractFrame(ctx, in, readerIndex, actualFrameLength);
// 修改reader指针 位置
in.readerIndex(readerIndex + actualFrameLength);
return frame;
}
5. DelimiterBasedFrameDecoder - 自定义分隔符解码器
自定义分隔符 解码器
1. 构造方法
new DelimiterBasedFrameDecoder(50, false, true, Unpooled.copiedBuffer("a", CharsetUtil.UTF_8))
// maxFrameLength 每一次的数据包最大多少
// stripDelimiter 是够去除分隔符
// failFast 如果异常快速抛出
// delimiter 分隔符
2. 简单使用
// 1. 服务器端 , 添加解码器
// 分隔符解码器
ch.pipeline().addLast(new DelimiterBasedFrameDecoder(50, false, true, Unpooled.copiedBuffer("a", CharsetUtil.UTF_8)));
// 字符串解码器
ch.pipeline().addLast(new StringDecoder());
// 自己的解码器
ch.pipeline().addLast(new MyDecoder());
// channelRead() 方法
if (msg instanceof String) {
System.out.println(msg);
}
// 2. 我们在客户端注册的是否发送了 :
run.channel().writeAndFlush(Unpooled.copiedBuffer("你好a你真的很棒", CharsetUtil.UTF_8));
run.channel().writeAndFlush(Unpooled.copiedBuffer("啊a", CharsetUtil.UTF_8));
输出结果 :
服务器端输出结果 :
你好a
你真的很棒啊a
我们发现 分隔符是在句尾分割 , 如果没有分隔符另外一部分就放入缓冲区了,等待下一次读取后一起放入进去.
6. LineBasedFrameDecoder - 按行解码器
1. 构造方法
LineBasedFrameDecoder(final int maxLength, final boolean stripDelimiter, final boolean failFast)
// maxLength : 最大帧
// failFast : 快速抛出异常
// stripDelimiter : 去除分隔符
2. 快速使用
// 1.换行符解码器
ch.pipeline().addLast(new LineBasedFrameDecoder(1000, true, true));
// 2. 字符串解码器
ch.pipeline().addLast(new StringDecoder());
// 3. 自己的处理器
ch.pipeline().addLast(new MyHandler());
服务器端发送 :
ctx.writeAndFlush(Unpooled.copiedBuffer("HELLO,我是服务器\n", CharsetUtil.UTF_8));
客户端发送 :
run.channel().writeAndFlush(Unpooled.copiedBuffer("你好,你真的很棒", CharsetUtil.UTF_8))
run.channel().writeAndFlush(Unpooled.copiedBuffer("啊,\n", CharsetUtil.UTF_8))
输出结果 :
服务器端 :
你好,你真的很棒啊,
客户端:
HELLO,我是服务器
3. 分析 - buf.forEachByte()方法的使用
ByteBuf buf = Unpooled.buffer(10);
buf.writeCharSequence("hell\n", CharsetUtil.UTF_8);
byte x = '\n';
//ByteProcessor.FIND_LF
int i = buf.forEachByte(0, 10, new ByteProcessor() {
@Override
public boolean process(byte value) throws Exception {
//不想循环 返回 false
if (value == x) {
return false;
}
// 想继续循环返回 true
return true;
}
});
System.out.println("index : "+i);
输出 :
index : 4
所以很简单就能发现换行符在哪里,然后切割就行了 .......
7. IdleStateHandler - 心跳检测处理器
Triggers an IdleStateEvent when a Channel has not performed read, write, or both operation for a while.
触发一个 IdleStateEvent 事件 ,当一个channel在一段时间内没有执行 read write 或者两者 , 所以他属于一个事件流
官方源码中的推荐用法 , 其实一般使用也是如此 ,
第一个参数是 : (READER_IDLE) No data was received for a while.
第一个参数是 : (WRITER_IDLE) No data was sent for a while.
第一个参数是 : (ALL_IDLE) No data was either received or sent for a while.
public class MyChannelInitializer extends ChannelInitializer<Channel> {
@Override
public void initChannel(Channel channel) {
channel.pipeline().addLast("idleStateHandler", new IdleStateHandler(60, 30, 0));
channel.pipeline().addLast("myHandler", new MyHandler());
}
}
// Handler should handle the IdleStateEvent triggered by IdleStateHandler.
public class MyHandler extends ChannelDuplexHandler {
@Override
public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
if (evt instanceof IdleStateEvent) {
IdleStateEvent e = (IdleStateEvent) evt;
if (e.state() == IdleState.READER_IDLE) {
} else if (e.state() == IdleState.WRITER_IDLE) {
}
}
}
}
1. 如何去设计一个合理心跳检测
文章也找不到了, 我是参考一篇阿里Dubbo的文章的 , 他的思想就是 主在于客户端, 从在于服务器端 ,因为我们的思想一般是让服务器端发送心跳包,定时去检测,如果累计达到几次没有的话,那么直接out掉, 这样给我们带来的不好处就是逻辑复杂 ,考虑情况太多 , 所以改成客主服从,特别适用于客户端开发的 .
思路大致就是客户端和服务器端 , 客户端当60S没有收到服务器端发来的消息,会主动给服务器端发送一个心跳包, 此时,当服务器端没有收到和发送给客户端的时长超过120S我们就断开与客户端的连接 , 所以服务器端很简单,客户端也很简单
1. 服务器端代码
@Override
protected void initChannel(SocketChannel socketChannel) throws Exception {
ChannelPipeline pipeline = socketChannel.pipeline();
// 心跳检测 , 读写超时时间是120S , 没有收到也没有发送消息
pipeline.addLast("idleStateHandler", new IdleStateHandler(0, 0, 120));
// 心跳检测处理器
pipeline.addLast("serverHeartBeatHandler", new ServerHeartBeatHandler(listener));
}
// 处理器逻辑
public class ServerHeartBeatHandler extends ChannelDuplexHandler {
@Override
public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
// 判断是否是IdleStateEvent
if (evt instanceof IdleStateEvent) {
// 心跳检测服务器端 超时直接关闭
// 交给 handlerremove处理
ctx.close();
} else {
//否则不做处理
super.userEventTriggered(ctx, evt);
}
}
}
2. 客户端代码
@Override
protected void initChannel(SocketChannel socketChannel) throws Exception {
ChannelPipeline pipeline = socketChannel.pipeline();
// 心跳检测 , 如果60S我们没有收到服务器信息,我们就发送一个心跳包
pipeline.addLast("nettyHeartBeatHandler", new IdleStateHandler(60, 0 , 0)
pipeline.addLast("heartBeatHandler", new ClientHeartBeatHandler(listener));
}
//处理器
public class ClientHeartBeatHandler extends ChannelDuplexHandler {
private ChatBootListener listener;
public ClientHeartBeatHandler(ChatBootListener listener) {
this.listener = listener;
}
@Override
public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
if (evt instanceof IdleStateEvent) {
// 发送一个心跳包
ctx.channel().writeAndFlush(Constants.HEART_BEAT_NPACK).addListener(new GenericFutureListener<Future<? super Void>>() {
@Override
public void operationComplete(Future<? super Void> future) throws Exception {
if (future.isSuccess()) {
// 成功一般是发送到了缓冲区 , 但是并不是代表服务器端收到了请求
} else {
// TODO: 2019/11/16 失败 ........... 看需求
}
}
});
} else {
// 交给父类处理
super.userEventTriggered(ctx, evt);
}
}
}
2. 基本原理

就是 ChannelHandlerContext 的 EventExecutor 定期去执行一个任务 ,需要传入一个runnable对象和一个延迟时间 ,人后一直定期执行 ..........
