

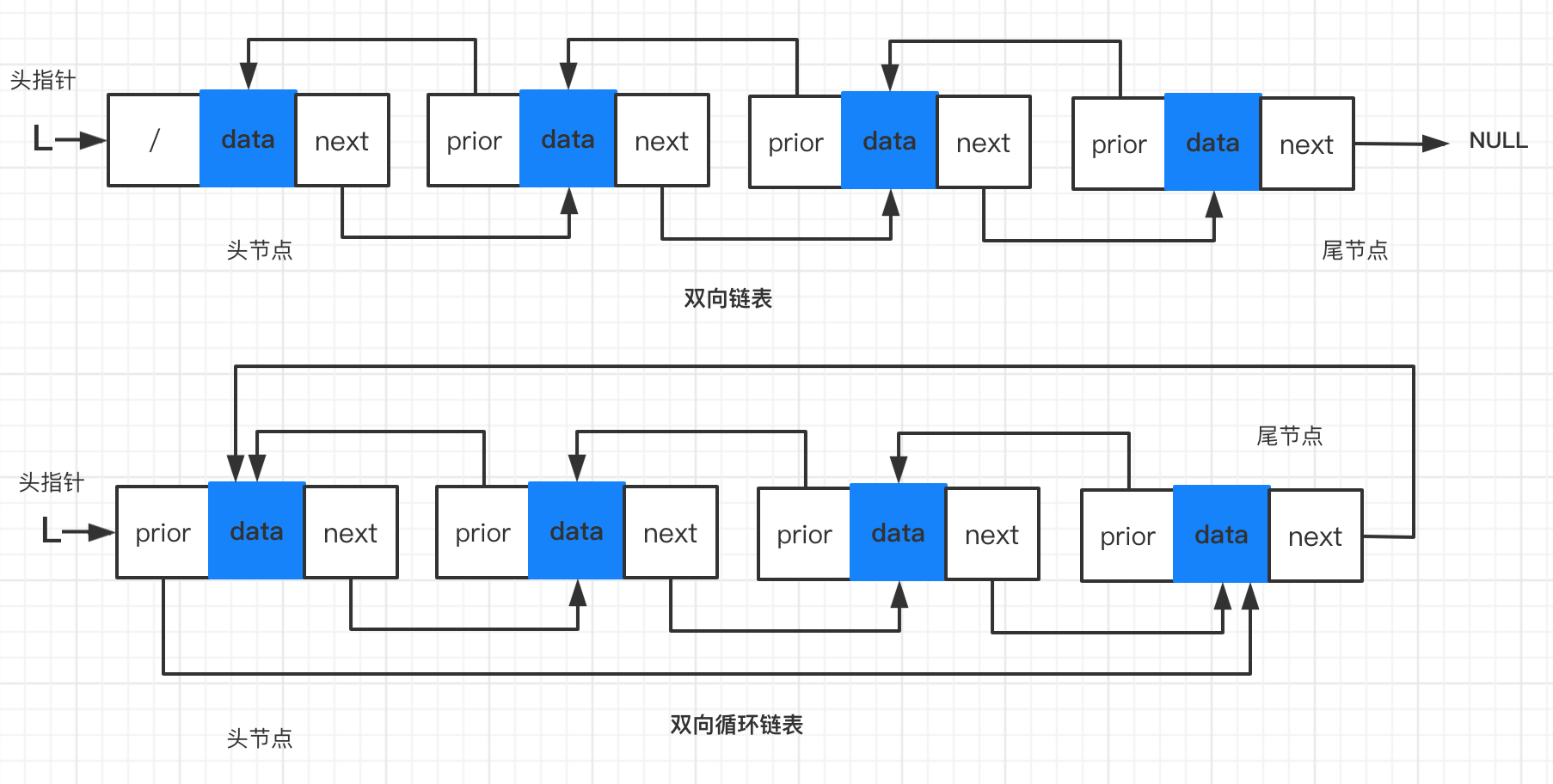
链表结构对比
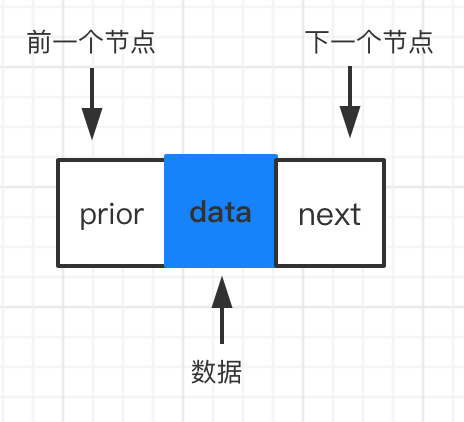
节点相同
创建方式对比
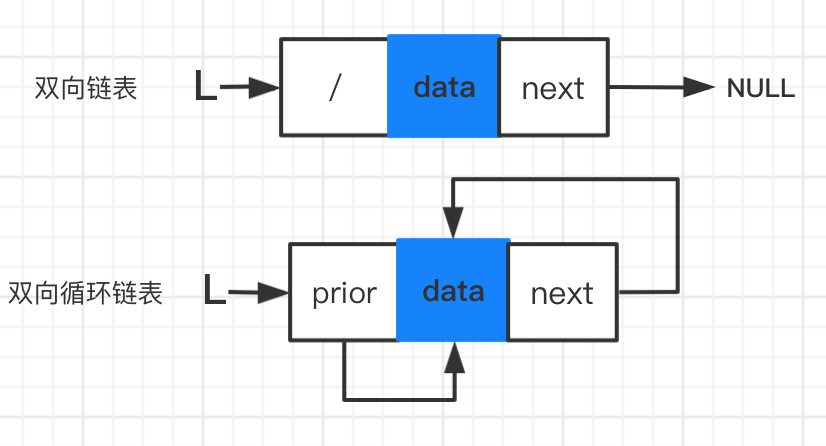
创建双向链表
/// 创建链表
Status CreateList(LinkList *L)
{
*L = (LinkList)malloc(sizeof(Node));
if ((*L) == NULL) return ERROR;
(*L)->prior = NULL;
(*L)->next = NULL;
return OK;
}
创建双向循环链表
/// 创建链表
Status CreateList(LinkList *L)
{
*L = (LinkList)malloc(sizeof(Node));
if ((*L) == NULL) return ERROR;
(*L)->prior = *L; // 这里和上面不一样,指向自己,
(*L)->next = *L; // 这里和上面不一样,指向自己
/*
* 和双链表的稍微差异处理之后,只有头节点自己也可以是一个循环
*/
return OK;
}
插入节点对比
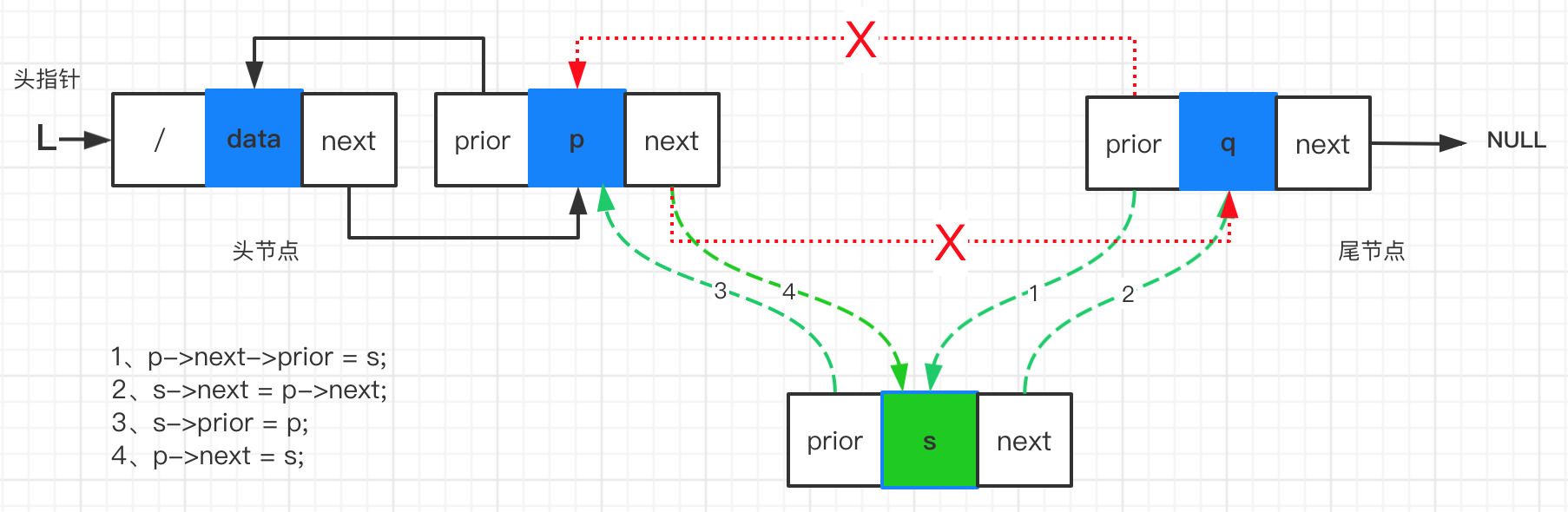
双链表的插入
p:插入位置前的节点 q:插入位置后的节点 s:新节点
- 创建新节点s
- 找到插入位置前的一个节点p
- 判断是不是插入在尾节点之后
- 是,新节点s的prior指向尾节点p,尾节点p的next指向新节点s
- 不是插入在尾节点之后,
- p的next节点q的prior 指向新节点s
- 新节点s的next指向q
- 新节点s的prior指向p
- p的next指向s
- over
Status ListInsert(LinkList *L, int place , ElemType v)
{
// 有头节点 所以插入位置不能是<1
if (place < 1) return ERROR;
// 新节点
LinkList temp = (LinkList)malloc(sizeof(Node));
if (temp == NULL) return ERROR;
temp->data = v;
temp->prior = NULL;
temp->next = NULL;
// 找到插入前的节点
LinkList p = *L;
// 找到插入位置 (place 位置的前一个结点)
for (int i = 1; i < place; i++) {
if (p->next == NULL) break;
p = p->next;
}
// 注意:因为有头节点,所有新节点一定是在头节点之后,所以头指针L,一定指向头节点
if (p->next == NULL)
{
p->next = temp;
temp->prior = p;
}
else
{
// 1、p的后一个节点的prior指向新节点temp
p->next->prior = temp;
// 2、新节点temp的next指向p的后一个节点
temp->next = p->next;
// 3、新节点temp的prior指向p
temp->prior = p;
// 4、p的next指向新节点temp
p->next = temp;
}
return 1;
}
双向循环链表的插入
p:插入位置前的节点 q:插入位置后的节点 s:新节点
- 创建新节点s
- 找到插入位置前的一个节点p
- 判断是不是插入在尾节点之后
- p的next节点q的prior 指向新节点s
- 新节点s的next指向q
- 新节点s的prior指向p
- p的next指向s
- over
为什么比双链表少判断是不是尾节点? 因为有头节点的存在,并且是个循环,即使插入在尾节点,也和任意位置插入一样
Status ListInsert(LinkList *L, int place , ElemType v)
{
// 有头节点 所以插入位置不能是<1
if (place < 1) return ERROR;
// 新节点
LinkList temp = (LinkList)malloc(sizeof(Node));
if (temp == NULL) return ERROR;
temp->data = v;
temp->prior = NULL;
temp->next = NULL;
// 找到插入前的节点
// 这里为什么和下面删除、替换的p=*L->next不同,而是p=*L:我们要找到place位置的前一个节点,所以要默认从头节点开始
LinkList p = *L;
// 找到插入位置 (place 位置的前一个结点)
for (int i = 1; i < place; i++) {
if (p->next == (*L))
break; // 说明此时P已经是尾节点
p = p->next;
}
temp->next = p->next;
temp->next->prior = temp;
p->next = temp;
temp->prior = p;
return OK;
}
区别:双向链表多了尾节点后插入操作
删除节点对比
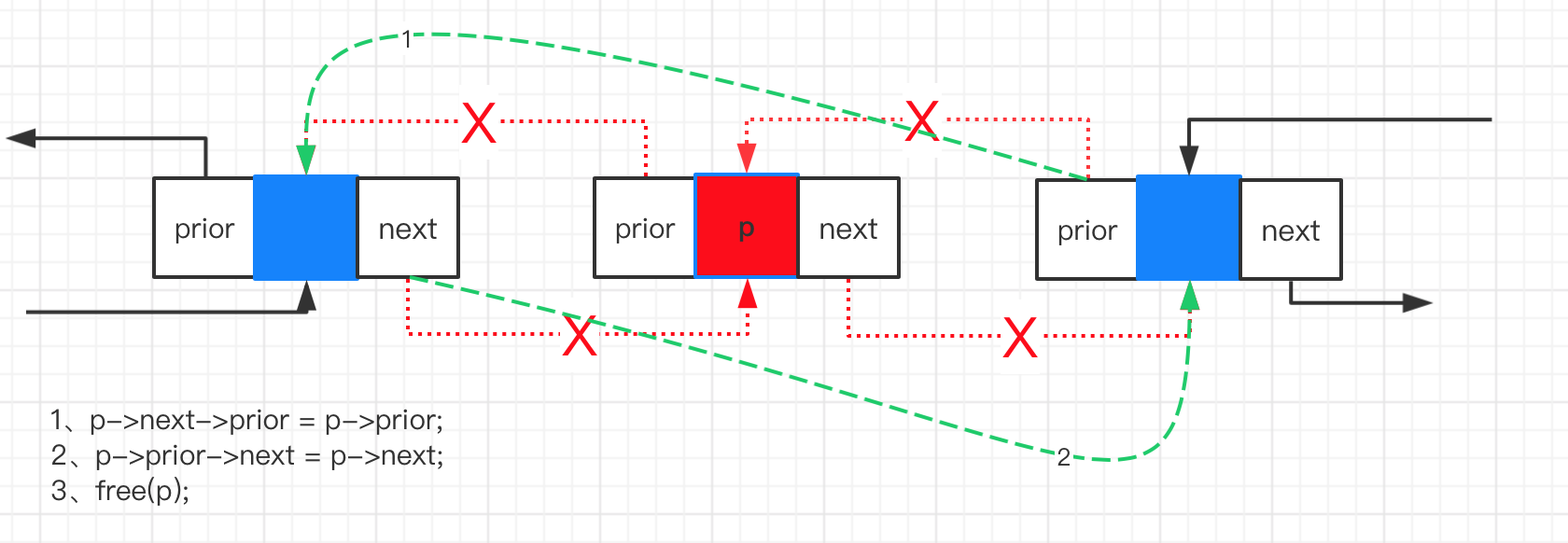
双链表的删除
老话重提,注意是不是删除尾节点,因为尾节点的next需要为null
Status ListDelete(LinkList *L, int place, ElemType *v)
{
// 有头节点 所以插入位置不能是<1
if (place < 1) return ERROR;
// 找到place位置的节点
LinkList p = (*L)->next; // 从首元节点开始
int i = 1
for (; i < place; i++) {
if (p->next == NULL) break;
p = p->next;
}
if (i < place) return ERROR;
*v = p->data;
if (p->next == NULL)
{
// p是尾节点
// 将p的前一个节点变成尾节点
p->prior->next = NULL;
// 释放p
free(p);
}
else
{
// p是任意位置的节点
// 1、将p的后一个节点指向p的前一个节点
p->next->prior = p->prior;
// 2、将p的前一个节点指向p的后一个节点
p->prior->next = p->next;
// 3、释放
free(p);
}
return 1;
}
双向循环链表的删除
循环链表不需要考虑是不是尾节点,因为他有下一个节点,把下一个节点和他前一个节点建立互相指向,释放自己。为什么在本篇博客中没有提及头指针的变更? 因为我们有头节点。
Status ListDelete(LinkList *L, int place, ElemType *v)
{
// 有头节点 所以插入位置不能是<1
if (place < 1) return ERROR;
// 找到place位置的节点
LinkList p = (*L)->next; // 从首元节点开始
int i = 1;
for (; i < place; i++) {
if (p->next == NULL) break;
p = p->next;
}
if (i < place) return ERROR;
*v = p->data;
// p是任意位置的节点
// 1、将p的后一个节点指向p的前一个节点
p->next->prior = p->prior;
// 2、将p的前一个节点指向p的后一个节点
p->prior->next = p->next;
// 3、释放
free(p);
return 1;
}
区别:双链表多了尾节点删除处理
更新节点对比
- 找到要操作的节点
- 更新data
两种链表步骤一样
图片可以参考上面删除的图片,在找到后,仅更改节点data即可
Status ListReplace(LinkList *L, int place, ElemType newValue)
{
// 有头节点 所以插入位置不能是<1
if (place < 1) return ERROR;
// 找到place位置的节点
LinkList p = (*L)->next; // 从首元节点开始
for (int i = 1; i < place; i++) {
if (p->next == NULL) break;
p = p->next;
}
p->data = newValue;
return 1;
}
查找指定位置的节点
按照上文替换、删除的方式找到要操作的place位置的节点。 两种链表在不涉及更改操作,单纯的执行查找时,是一样的
/// 查找节点
/// @param L 链表(没有使用指针,所以L是拷贝的链表,不是原链表!!!)
/// @param place 查找的位置
/// @param node 要查找的节点(C语言不好的同学,这里*node实际是存储节点地址的指针,与 function(LinkList *L) 一样,用了双指针)
Status FindNode(LinkList L, int place, LinkList *node)
{
if (L == NULL) {
printf("打印的双向循环链表为空!\n\n");
return ERROR;
}
// 有头节点 所以插入位置不能是<1
if (place < 1) return ERROR;
// 找到place位置的节点
LinkList p = L->next; // 从首元节点开始
int i = 1;
for (; i < place; i++) {
if (p->next == NULL) break;
p = p->next;
}
if (i < place) {
printf("位置超出链表长度!");
return ERROR;
}
*node = p;
return OK;
}
主函数
int main(int argc, const char * argv[]) {
LinkList L;
int place, value;
CreateList(&L);
DisplayList(L);
/*
*
* 。。。。。。。。
* ListInsert()插入测试数据
*/
printf("查询节点,请输入查询位置:\n");
LinkList node = NULL;
scanf("%d", &place);
FindNode(L, place, &node);
if (node != NULL) {
printf("节点:%p, data:%d\n",node,node->data);
}
}

