

前言
算法的功底决定了offer的质量,在《一个陌生女人的来信》中也说要写一点算法知识。于是今天就借助《雾都孤儿》这本英国小说来说一些必会的算法。这篇文章主要用一些故事串联一些算法问题,用经典的题型去理解算法背后的思想。
《雾都孤儿》这本小说的男主奥利弗作为富商的私生子,从小就是一个孤儿,今天的算法知识就从小说中男主逃出魔抓后又被骗入贼窟开始了~ 🐱👤
第一节:偷窃前的培训-算法复杂度
男主被半忽悠到盗窃组织开始,盗贼头头费金想让男主成为一名出色的小偷,进行了一系列手指灵敏脑袋灵活的课程训练,毕竟也不是人人都能当小偷的,何况是一个出色的小偷。男主上的第一课就是关于时间复杂度和空间复杂度,这关系到偷窃任务的效率。
可能那个时候如何在最短的时间和使用最小的成本完成一次组织的任务是一个衡量优秀小偷的标准吧。
ok,上面出现了两个关键词,效率和复杂度,盗窃组织的使用复杂度来判断偷窃任务的效率,在算法的世界里,复杂度就是算法效率的度量方法。
复杂度又分为时间复杂度和空间复杂度(代码执行的时间、执行消耗的存储空间)。但是鱼和熊掌不可兼得,要根据具体需求做出取舍,于是有时候会出现牺牲时间换空间,牺牲空间换时间的情况。
1.时间复杂度
引入时间复杂度
问:如何在最快的时间里计算出10层木头的数量,假如每层的根数等于层数。

你肯定想到了两种方法,从头加到尾和利用公式(首项+尾项)*项数/2,两种方法用代码实现如下
//普通的循环
var sum=0, n=10;//1次
for(i=1;i<=n;i++) {//n+1次
sum=sum+i//n次
}
//高斯的方法
var sum=0, n=10;//1次
sum=(1+n)*n/2; //1次
如何判断上面两种方式的时间复杂度?前面我们说时间复杂度就是代码的执行时间,假如一条语句执行一次是一个单位时间,那么第一种方法就是2n+2个单位时间,第二种方法就是2个单位时间。
这两个算法时间复杂度是n和1的差距,明显看出高斯小神童的方法在更快的时间里算出木头的数量,更快的完成盗贼头头的任务。
时间复杂度的表示方法
通常我们采用大O表示法,T(n)=O(f(n)),其中f(n)表示执行代码执行次数总,n表示数据规模。当n足够大可表示T(n) = O(n)。
但值得注意的是大O表示法不会精确计算每一个语句执行的次数,因为复杂度侧重的是随输入规模增大的一个抽象,这看上去有点不像人话。翻译成人话就是:
如果一段代码执行3n^2+3n个单位时间,就是O(n^2)
如果一段代码执行了2n+1个单位时间,就是O(n)
如果一段代码执行了999999个单位时间,就是O(1)
如何推导大O阶,根据时间复杂度侧重得是随着输入规模的一个抽象总结有以下三点:
- 常数项1取代运行的确定的常数时间
- 保留最高阶
- 去除高阶项的常数
追问:为什么可以这样表示
可能学过数据结构的朋友都会用大O法表示时间复杂度,但是不知道为什么可以这样,比如为什么999999个单位时间就是O(1),剩下的999998个单位时间为什么可以去掉。我开始学数据结构的时候就是死记的推导规则。
其实这里涉及到函数的渐进增长,对比下面两张图,随着n的不断变大两个函数图像越来越接近,这就进一步说明了时间复杂度侧重得是随着输入规模的一个抽象,这也是剩下的999998个单位可以被忽略的根本原因。是不是很简单😉
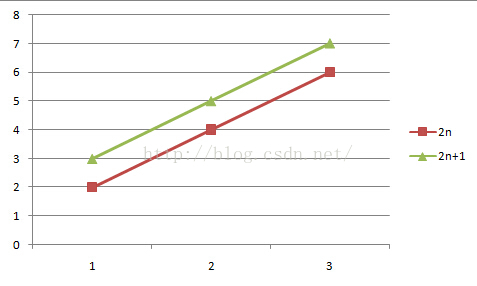
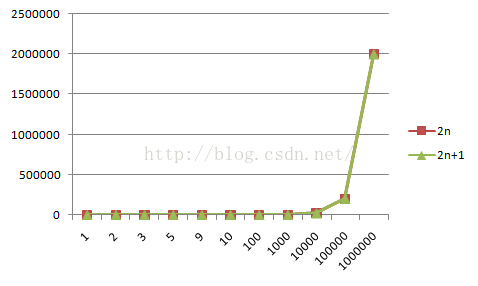
常见的时间复杂度分析
常见的时间复杂度有以下几种:
-
常数阶:O(1)
注意不存在O(2)、O(2222)等表示
-
对数阶:O(logn)
后面举例说明。
-
线性阶:O(n)
随n的扩大直线增长。
-
nlogn阶:O(nlogn)
对数阶外套一层循环。
-
平方阶:O(n^2)
两层嵌套循环。
还有一些比较复杂的阶,比如立方阶,指数阶,阶乘阶,他们随数据规模增大,增长速度巨快,应避免这样的算法。
前面算木头的代码中时间复杂度分别是线性阶O(n)和常数阶O(1)。下面对对数阶举例分析。
for(int i = 1; i< 100; i++){
i=i*3;
}
上面的循环中i每扩大三倍,3^1、3^2、3^3...假如执行x次,有式子3^x<100。
计算出执行次数x=log3n(其中2是对数的底,n是真数)。因为log(c)(b)/log(c)(a)=log(a)(b)。所以log(3)(n)/log(3)(2)=log(2)(n)。log(2)(n)也可以进行类似变形,最后该时间复杂度是O(logn)。
2. 空间复杂度
空间复杂度也还是用大O表示法,S(n)=O(f(n))。空间复杂度是随数据规模n的增大对执行消耗的存贮空间的抽象。
空间复杂度比较常用的有:O(1)、O(n)、O(n²)
比如一个二维数组a[n][n]的空间复杂度是O(n^2),一维数组a[n]的空间复杂度是O(n)。
3.小结
最后,上面的知识可以总结为两句话:
- 复杂度是度量算法效率的一种方式。
- 复杂度是随着输入数据n规模增大的对于执行消耗时间和空间的一个
抽象。
第二节:偷洋葱-递归与回溯
男主经过了脑袋灵活手指灵敏的一系列培训后,成功的出师了,他的第一个任务是去偷5个黄色洋葱,拿到洋葱后要求完好无损的取出洋葱最后一层。并且记录每个洋葱的总层数。
至于为什么要去偷洋葱,可能那个时候黄色洋葱很值钱???
问:有一个洋葱,想完整取出洋葱最里面的一层。怎么知道剥开的层数?

(几层我不知道,但是我知道这么大个洋葱辣眼睛应该不错😜)
我们要知道洋葱的层数先一层层把它剥开,当剥开到最后一层的时候就不用剥了,从最后一层由内向外,依次加1(最后一层层数=1、倒数第二层层数=最后一层+1、倒数第三层层数=倒数第二层+1......第一层层数=第二层+1),最后得到了这个洋葱的层数。
上面获取洋葱层数的过程就是一个递归的过程。可能有点明白了,那递归到底是什么?
1. 什么是递归
递归就是函数调用函数本身。把一个大规模的问题不断变小后推导的过程。递归的过程是先递,遇到终止条件了再归。
上面把洋葱一层层剥开就是递的过程,一层层剥开把问题规模缩小;最后一层停止往下剥就是递的终止条件;由内向外依次加1的过程就是归。
2.如何使用递归
递归是一个逆向思考的过程,做题的时候千万不能钻到一次次递归里面,不需要把每一层都弄清除,我刚开始做递归死扣每一步,一道树的递归可以弄一天。但是人脑子能入几个栈?
所以要跳出细节,从整体上来思考。考虑本级递归要做什么,下一级的逻辑不用关心,就像我们CSS中background-color: red为什么背景色变成红色一样,不用关心它的逻辑。
总结递归的实现有下面三个步骤:
-
找整个递归的终止条件:递归应该在什么时候结束?
-
本级递归与下一级的关系:找到一个递推公式表示问题与子问题的关系?
-
代码实现
大家都知道斐波拉切数列是典型的递归,所以就不说了,说一下青蛙跳台阶的问题😎:
一只青蛙一次可以跳一级台阶或者两级台阶,问n级台阶这只青蛙有多少种跳法。
我们逆向思考,假如青蛙最后一次跳的时候可能是两级,也可能是跳一级。所以第n级的跳法是n-1级和n-2级的和。
-
先找递推公式,在第n级跳法 f(n)=f(n-1)+f(n-2);同理那n-1级台阶也有两种跳法,f(n-1)=f(n-1-1)+f(n-1-2),到n-2级台阶也是两种跳法...于是得到递推公式当前台阶的跳法f(n)=f(n-1)+f(n-2)。
-
什么时候结束,递归的终止条件就是当台阶为1阶或者2阶的时候结束递归。
-
代码实现如下,根据需求写返回值。
function jumpWay(n){
if(n==1) return 1;
if(n==2) return 2;
return jumpWay(n-1)+jumpWay(n-2);
}
现在是不是有点感觉了, 再看一道两两交换链表结点的题
(lc24): 给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。比如输入1->2->3->4->5->6,返回2->1->4->3->6->5。
-
递归公式:结点两两交换最后结果可看成先只对前面两个结点处理的结果加上后面的。
- 2->1加
3->4->5->6的结果, - 3->4->5->6的结果可看作4->3加
5->6交换的结果, - 5->6交换的结果是6->5。
得到递推公式head.next=swapPairs(head.next.next),其中head是当前结点,swapPairss是交换结点的函数。这就是本次问题与下一级的子问题的关系。
- 2->1加
-
递归出口:什么时候递归结束,如果当前结点是最后一个或者是空节点的时候就是递归的出口。
-
代码实现,要注意返回值。
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode swapPairs(ListNode head) {
//出口
if(head==null||head.next==null) return head;
ListNode next=head.next;
//递归公式
head.next=swapPairs(next.next);
//第二个结点指向第一个结点
next.next=head;
return next;
}
}
上面的代码如果理解起来有问题就将swapPairs(next.next);看成一个节点3。我们来模拟一下,虚线表示最初的关系,实线表示函数执行后结果。最后的结果就是前面两个结点交换后加后面的部分。
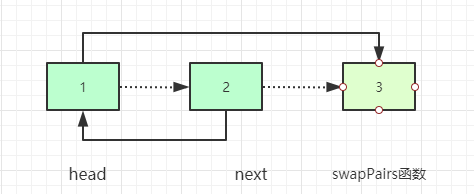
第三节:洋葱的层数-排序
还记得前面男主偷了5个洋葱吗,现在要对洋葱的层数进行排序。找到层数最多的洋葱。
JS中sort方法就是对数组进行排序。排序算法很多,不同的排序算法在不同情况下执行效率不同,所以排序算法没有优劣之分。十大排序算法先介绍五种最常见的。
如果五个洋葱的层数是16,23,13,14,9。对[16,23,13,14,9]这个数组进行排序
1.冒泡排序
是一种原地排序,没有产生新的数组。
冒泡排序的思想:
从第一个数据开始相邻的两个数据比较大小,大的放到后面,将当前最大的放到最后面。就像一层层冒泡一样。 直到所有的数据从小到大有序排列结束。
过程分析
第一轮比较,看下面的动图,一个长度为5的数组第0位到第4位进行比较,比较了四次。第一轮比较结束后将23放到了第4位。结果是[16,13,14,9,23].
(linglong第一次做动图,鸡冻手有点抖,莫怪👀)
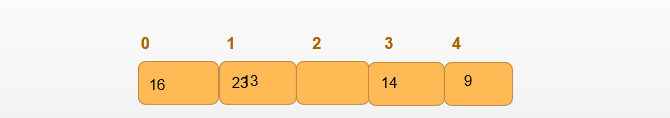

通过观察我们知道要进行length-1轮比较才能得到结果,也就是第0位到第1位比较大小后不再比较,此时数组有序。
每轮比较是相邻元素间两两比较。比较的次数又有什么规律呢?第一轮是length-1次,第二轮是length-2次,第三轮是length-3...那么第i轮就是比较length-i次了。
分析完过程开始写代码。
//冒泡
function buble(arr){
var len = arr.length;
//i表示轮数
for(var i = 0;i < len-1;i++){
for(var j = 0; j<len-i-1;j++){
//j是每轮比较的次数
if(arr[j]>arr[j+1])swap(arr,j,j+1);
}
// console.log(arr);
}
return arr;
}
//交换函数
function swap(arr2, a, b) {
var c = arr2[a];
arr2[a] = arr2[b];
arr2[b] = c;
}
函数实现了,虽然冒泡是最简单的排序,但还是两点有必要说明一下。
一是注意交换函数swap要把数组参数传过去,因为是对数组里的元素修改。
二是可以对代码进行优化,上面两层循环的次数都是固定的,也就是说可能排序完毕后还会比较。我们可以通过设置标志位判断上一轮循环中有没有发生交换,如果没有发生交换,那么说明当前数组就是有序的,退出循环。
复杂度分析
冒泡排序是稳定的排序,通过两层循环时间复杂度是O(n^2),没有利用新空间,空间复杂度O(1)。如果数组本身是有序的交换的次数就会减少。
2.插入排序
V8引擎在数组较小的时候就会使用插入排序。
思想
将数据分为左右两部分,第i位左边是排好的数据,第i位右边没排好的(包括第i位)数,插入排序就是把右边无序的数依次插入到右边有序的数当中。
过程分析
假如第1位前面的数据是有序的,现在就从第一位开始插入到右边有序数中。
第一位中的23比16大,直接放到第0位16的后面。第一轮的结果是[(16,23),13,14,9]


比较结束后再让最后一位的9与前面的元素比较。最后比较的结果是[(9,13,14,16,23)],左边再没有数据。
综上所述,我们从第1位到最后一位都要与左边的有序树比较插入到合适的位置。
每一轮如何比较,如何找到合适的位置?当前右边待插入数如果比左边被插入的数小,就将被插入的数往后移一位,当出现被插入的数比当前要待插入数小的时候就停止比较。最后将当前的要比较的数放入比它小的数后面。
代码实现
function insert(arr) {
要比较length-1轮
for(var i = 1; i<arr.length; i++){
//将当前要插入的数用temp保存起来
var temp = arr[i];
//当前要插入的数与被插入的数进行比较
for(var j = i-1;temp < arr[j]&& j >= 0;j--){
//把arr[j]往后移。我已经昏了,这里的赋值写成等于号找bug找半天
arr[j+1] = arr[j];
}
//arr[j]比temp小,将temp放到arr[j]后面。如果temp是最小的,此时j==-1,temp放到第一位。
arr[j+1] = temp;
console.log(arr);
}
return arr;
}
复杂度分析
两层循环因此时间复杂度是O(n^2),但是当数组有序的时候temp < arr[j]不成立故不会进入到第二层循环。因此最好的情况下时间复杂度是O(n)。在原数组中进行交换没有新空间空间复杂度是O(1)。
3.归并排序
归并排序的思想是分治,就是把一个复杂的问题分成两个或多个相同或者相似的子问题,然后把子问题分成更小的子问题直到子问题可以简单的直接求解,最开始的问题就是子问题的合并。前面的递归也是分治的思想。
思想:
把数组从中间划分为两个子数组,一直递归把子数组划分为更小的子数组,直到子数组里面只有一个元素,如下图将数组分为一个元素的子数组后,然后递归进行归并。
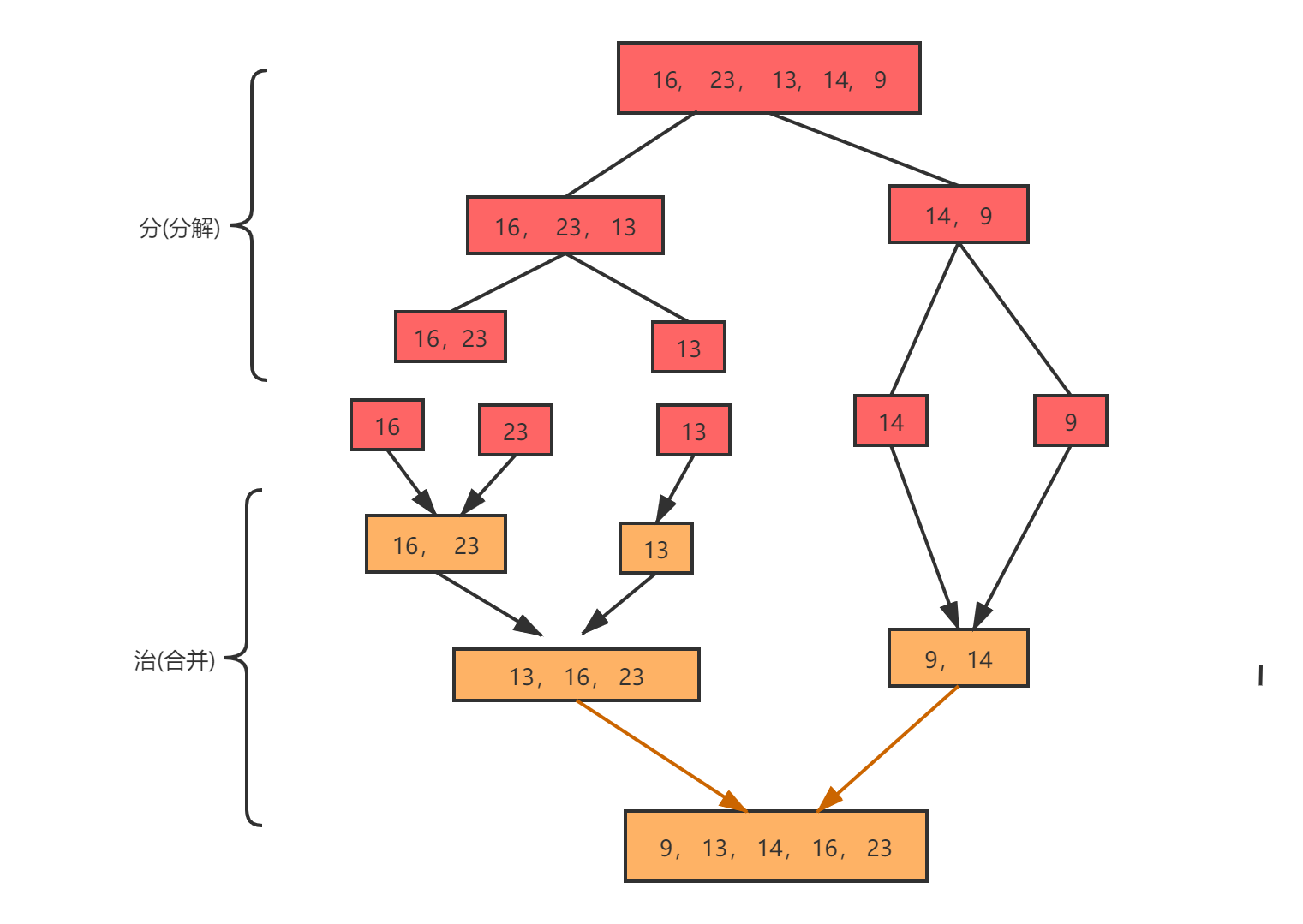
过程分析
首先对16和23归并。然后[16,23]和13归并[13, 16, 23]。然后右边的14,9归并。最后[13,16,23]和[9, 14]归并。
归并的具体细节就是:创建一个新数组,将左右两个数组(left,right)归并的结果放到数组中去,首先比较两个数组的第一个元素大小,把较小的元素放到数组中。我们可以借助两个指针(i,j)分别指向数组的第0位。如果left[i]<right[j],先把left[i]放入新数组的第0位,然后让i指针往后移动一位。继续判断大小直到一个数组为空。加入此时left数组为空就把right数组剩余元素依次放到新数组中,最后返回新数组。
但是js语法给数组提供了很多API,十分灵活,归并的时候我们可以使用能够改变数组的shift方法来取代ij指针。
var mergesort = function (arr){
var len = arr.length;
//当数组长度==1的时候停止分解
if(len<2) return arr;
//找到数组的中间位置,如果len=5,前三位放到左边。
var mid = Math.floor(len/2);
//slice函数返回一个(0-mid位,不包含第mid位)新数组,
var left = arr.slice(0, mid);
var right = arr.slice(mid);
//将两个数组合并
return merge(mergesort(left),mergesort(right));
}
//合并函数
var merge = function (left, right) {
var result=[];
//1.当左右两个数组的长度不为0,比较大小,利用shift方法取出第一个元素放入新数组
while(left.length&&right.length){
var l = left[0], r= right[0];
if(l<=r) result.push(left.shift());
else result.push(right.shift());
}
//2.当左边数组长度!=0,右边为0的时候直接将左边的数依次取出放入新数组
while(left.length!=0) result.push(left.shift());
//3.当右边的数组长度!=0,左边为0的时候直接将右边的数依次取出放入数组
while(right.length!=0) result.push(right.shift());
return result;
}
复杂度分析
这里把n个元素的数组分解为n/2个子问题。每个子问题的复杂度就是T(n/2)。两个子问题就是2*T(n/2)。当子问题不能再分解的时候进行合并,合并的时候子数组会进行大小比较,最多进行n-1次比较,所以合并的复杂度就是O(n)。
于是得到时间复杂度的公式:T(n)=2*T(n/2)+O(n)
这个递归公式的求解可以看这里。T(n)=2*T(n/2)+O(n)的求解,最后的结果O(nlgn)。
对于空间复杂度,由于利用了空间为n一个新数组存放结果。空间复杂度S(n)=O(n)。
4.快速排序
快速排序其实也是用到了分治的思想
思想
快速排序借助数组中任意一个元素做作一个中间值temp,将比temp小的放到temp右边,将比temp大的放到temp的左边。然后对于左边的数据和右边的数据重复同样的操作。直到排序完成。
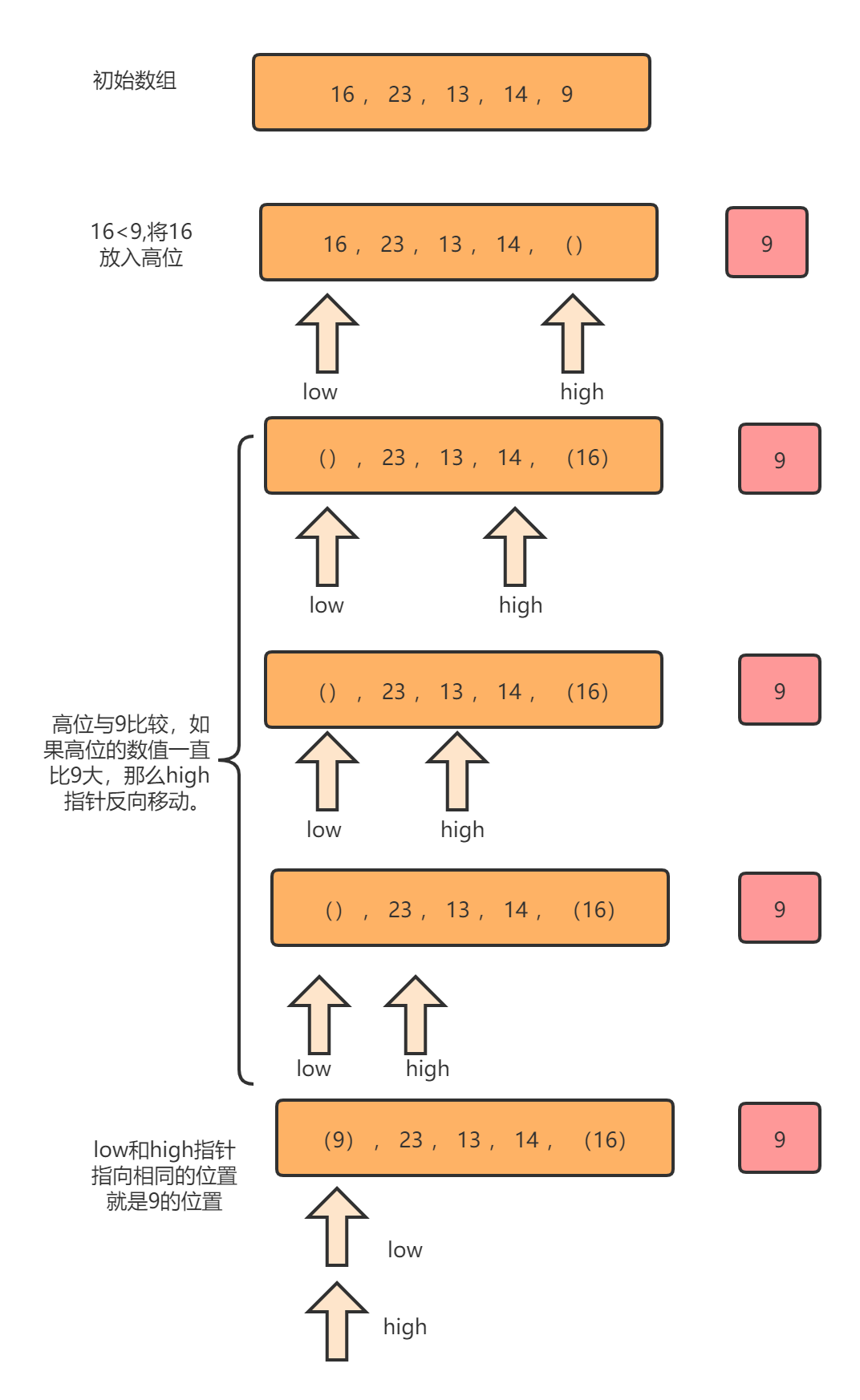
过程分析
假如把最后一位9作为中间值temp,利用low和high两个指针。low与temp比较大小,如果low小于temp,那么low向前移动。如果low大于temp,将arr[high]=arr[low]。
然后移动high指针。如果high>temp,high指针一直反向移动,如果high<temp,将arr[low]=arr[high]。
直到low和high指针指向同一位置就是temp的位置。
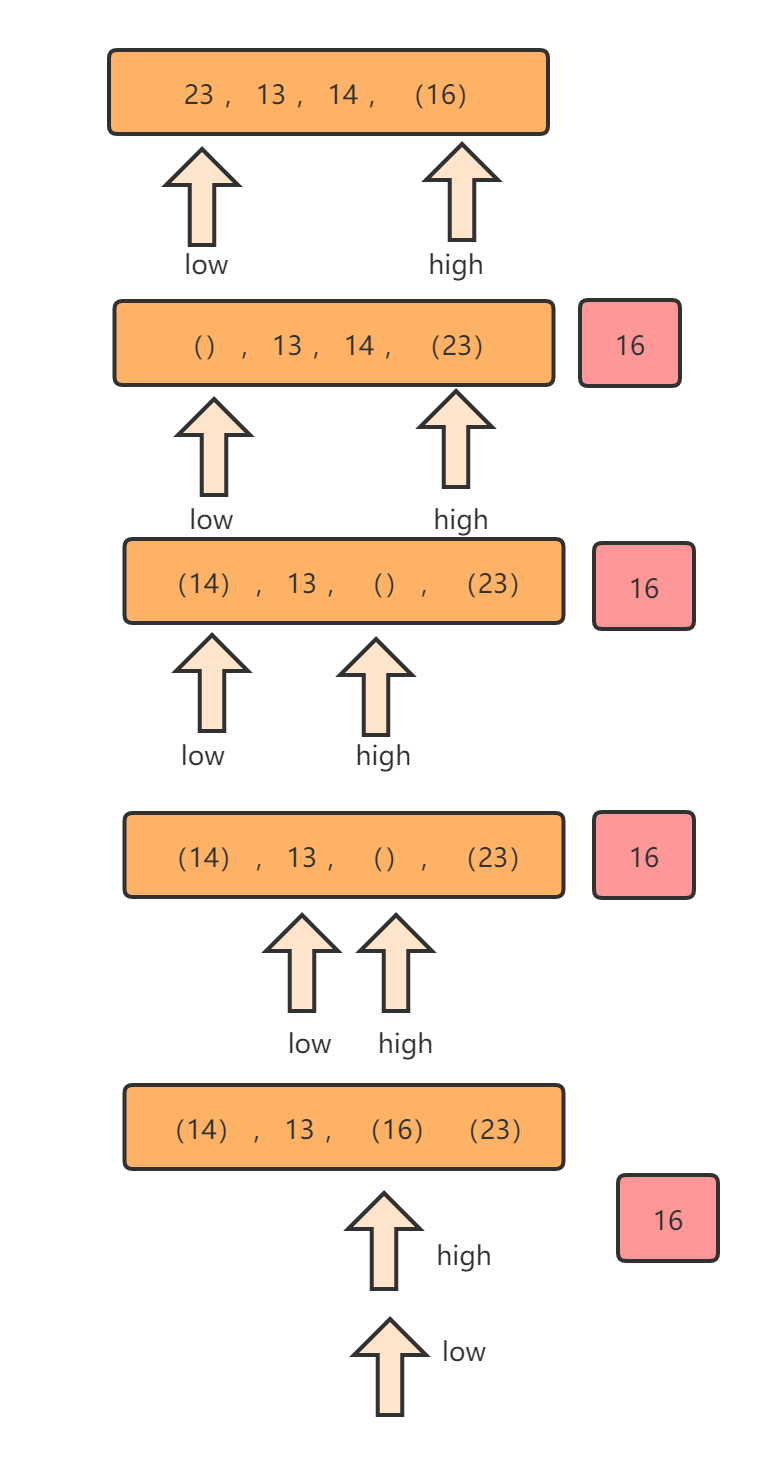
这个时候9的右边都比9大,我们对9的右边进行上面同样的操作。把16作为中间值。
代码
function quickSort(arr){
var left = 0, right = arr.length-1;
function _quickSort(left, right) {
// 排除例外,比如上一轮结束low和high都指向最后一个时,次轮low+1就超过了数组的长度
if(left<0||right>arr.length-1|| left>right) return;
var temp = arr[right];
var low = 0, high = right;
//这里应该使用while循环,而不是if判断。因为当low==high时可能左右两边不止循环一次
while(low < high){
// 下面的low<high是为了避免temp比所有的都大
while(arr[low] <= temp && low < high){
low++;
}
// debugger;
arr[high]=arr[low];
debugger;
while(arr[high] > temp&& high > low){
high--;
}
arr[low]=arr[high];
}
// debugger
arr[low] = temp;
_quickSort(left, low-1);
_quickSort(low+1, right);
}
_quickSort(left, right);
return arr;
}
var result2=quickSort([16,23,13,14,9]);
复杂度分析
快速排序的时间复杂度与中间值有关联,当中间值刚好能够均分这个数组。同归并排序的时间复杂度O n(logn)。当中间值是数组中最大或者最小的,如上面的例子中选择最小的9作为中间值的时候时间复杂度O(n^2)。
对于空间复杂度需要空间临时保存待比较的值,空间的大小与递归的次数有关。空间复杂度是O(n)。
5.堆排序
堆排序利用到了大顶堆。
大顶堆就是一个二叉树,规定树的每一个结点的值都大于它的左子树和右子树。
思想
-
先构造一个大顶堆,堆顶的元素就是数组中最大值,
-
取出堆顶元素将数组的最后一位变成大顶堆堆顶的元素,堆的最后一个元素放到堆顶
-
然后对n-1个元素的堆进行调整,将剩下的元素重新构造大顶堆。
-
重复上述过程,知道大顶堆只剩下一个元素。
过程分析
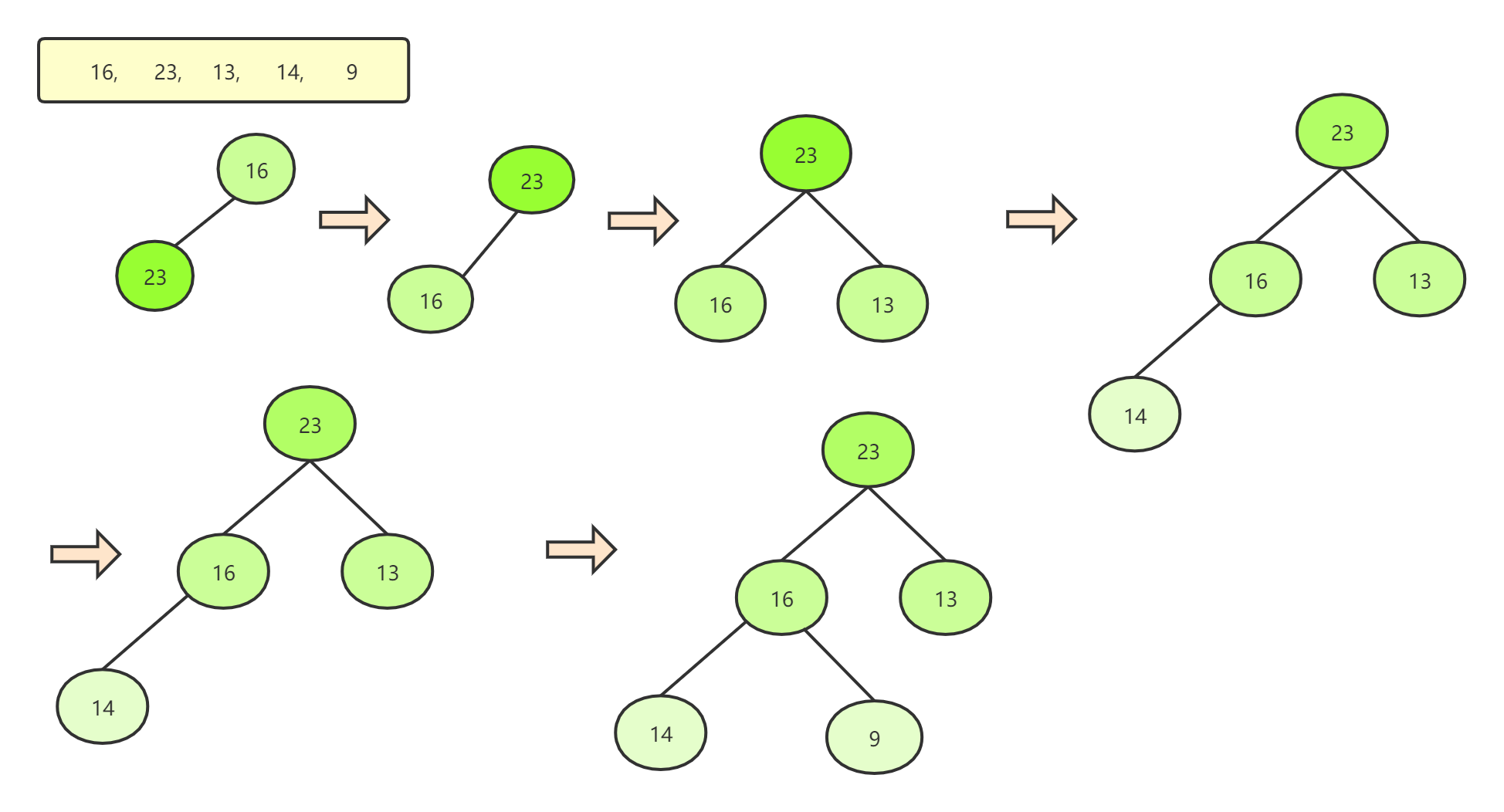
-
构造大顶堆 一层层构造,第一个数据16位堆顶,但是第二个元素23大于16就交换元素将23作为堆顶,一共要构造Math.floor((arr.length-1)/2)层。
-
取堆顶元素后调整堆得到新的大顶堆.将23放到数组的最后一位
将23与最后一个元素交换。
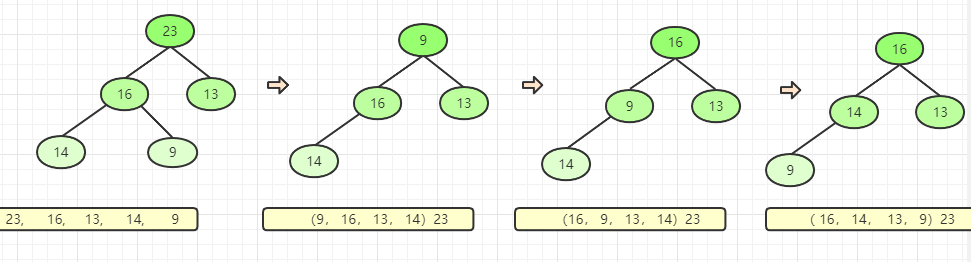
将16与最后一个元素交换
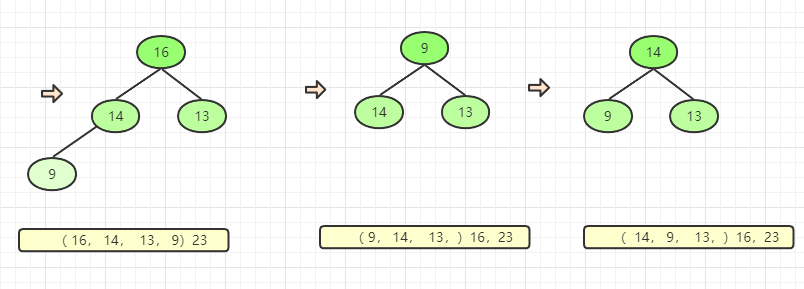
将14与最后一个元素交换
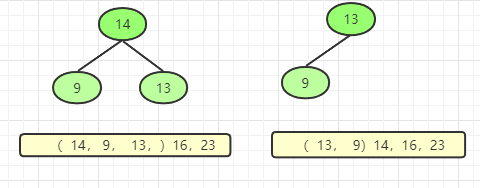

代码实现
/* 大顶堆排序 */
var heapSort = function(arr, heapSize){
var i;
buildMaxHeap(arr, heapSize);
for (i=heapSize-1; i>0; i--) {
swap(arr, 0, i);
maxHeapify(arr, 0, i);
}
};
/* 创建大顶堆 */
var buildMaxHeap = function(arr, heapSize) {
var i, iParent = Math.floor((heapSize - 1) / 2);
for (i=iParent; i>=0; i--) {
maxHeapify(arr, i, heapSize);
}
};
/* 大顶堆调整 */
var maxHeapify = function(arr, index, heapSize) {
var iMax, iLeft, iRight;
do {
iMax = index;
iLeft = 2 * index + 1;
iRight = 2 * (index + 1);
// 是否左子节点比当前节点的值更大
if (iLeft < heapSize && arr[index] < arr[iLeft]) {
iMax = iLeft;
}
// 是否右子节点比当前更大节点的值更大
if (iRight < heapSize && arr[iMax] < arr[iRight]) {
iMax = iRight;
}
// 如果三者中,当前节点值不是最大的
if (iMax != index) {
swap(arr, iMax, index);
index = iMax;
}
} while (iMax != index)
}
var swap = function(arr, i, j) {
var temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
堆排序参考:浅解前端必须掌握的算法(五):堆排序(下)
复杂度分析
堆排序是一个基于完全二叉树的排序,每次堆顶元素交换进行调整的时间复杂度是O(logn)。堆排序的空间复杂度是O(1)。
第四节: 贪心
当求解全局最优解的问题时,我们将全局问题分为小的局部问题,去寻找局部最优解.同时可以证明局部最优解累计的结果就是全局最优解。贪心算法不用回溯因而效率很高。
lc605种花问题改编:男主偷洋葱的时候顺便偷了一些洋葱种子。他准备将种子种起来,但是种种子有一个规则。花坛中的种子不能种在相邻的地块上。它们会争夺水源,两者都会死去。
给定一个花坛(表示为一个数组包含0和1,其中0表示没种植花,1表示种植了花),和一个数 n 。能否在不打破种植规则的情况下种入 n 颗种子?能则返回True,不能则返回False。
过程分析
这里我们要找到最多有多少块土地可以种植,然后能种植的土里count与n比较大小。
如何找到最多的土地,从第0块土地开始遍历,能种的标记为1,count加1,然后从第一块土地继续遍历。直到遍历到最后一块。最后count的结果就是能中的土地数量。。再让结果与准备种的种子数n比较大小。
找到每一轮循环的最大土地块数,累计和得到最后的结果就是最优解
那么如何判断土地能否种植,只用判断这块土地的前面和后面是否是空地。当此时土地是最前或者最后一块土地的时候只用判断相邻的一块是否是空地。
代码实现
/**
* @param {number[]} flowerbed
* @param {number} n
* @return {boolean}
*/
var canPlaceFlowers = function(flowerbed, n) {
var count = 0, i = 0;
while(i<flowerbed.length) {
if(flowerbed[i] === 0&& !flowerbed[i-1] && !flowerbed[i+1]){
flowerbed[i] = 1;
count++;
}
i++;
}
return count >= n;
};
贪心的后果
贪心的缺点:不是所有的问题都能用它去解决。 得到的结果不一定是正确的,因为贪心过早的做出了决定,没有站在全局的角度思考。
比如找零问题,假如有面值为[25,30,10,1]的四种人民币,我现在要找零52元钱,如果用贪心算法那么找零结果是[30,10,10,1,1]。如果回溯的话就是[25,25,11]。此时我们就看到了贪心的缺点。
第五节 :种种子-动态规划
个人理解动态规划是分治法的升级,分治法有一个问题,就是容易重复计算已经计算过的值,使用动态规划,可以讲每一次分治时算出的值记录下来,防止重复计算,从而提高效率。
因此动态规划的判断:一是否有分治思想,最优子结构(最优解包含其子问题的最优解时,就称该问题具有最优子结构性质),二是否有重叠子问题。比如斐波拉切数列就可以用动态规划。
过程分析
前面的青蛙跳台阶问题。假如有10级台阶。fn(10)=f(9)+f(8);f(9)=f(8)+f(7)...上面f(8)就出现了两次,重复计算。因而可以使用一个缓存,计算出一种结果就放入缓存,下次遇到想同的子问题就从缓存中获取结果。
代码实现
function count2(total) {
var cache = {}; //缓存已经计算过的结果
function _count(total) {
if (cache[total] !== undefined) {
return cache[total]; //直接使用缓存结果
}
num2++;
var result;
if (total === 0) result = 0;
else if (total === 1) result = 1;
else if (total === 2) result = 2;
else {
result = _count(total - 1) + _count(total - 2);
}
//在缓存中放入结果
cache[total] = result;
return result;
}
//console.log("缓存", cache);
return _count(total);
}
快排和归并是动态规划吗?
快速排序和动态规划虽然用到了分治的思想,但是没有重叠的子结构,因而不算是动态规划。
动态规划可以看看leetcode上的lc198打家劫舍-入室抢劫系列,做个小偷真的难呐~
最后
这篇算法文章先也到这里了,里面最有价值的是排序算法,画图就花了好几个小时,感觉整个人都升华了,另外思想弄清楚了最重要的是自己去实现一遍。当然这篇算法文章后面也会继续更新下去🐢。
在原小说中,男主虽然周围环境十分糟糕,但是出淤泥而不染最后还是没有被黑化,始终保持着自己的善良和美好。最后和姨妈幸福生活在一起,算得上是一个美好的结局👏
emmm,总之,像奥利弗一样,坚守初心,坚持下去。
毕竟玲珑也幻想着有一天也能够和算法幸福的生活在一起呐~
