

前言
文本已收录至我的GitHub仓库,欢迎Star:github.com/bin39232820…
种一棵树最好的时间是十年前,其次是现在
我知道很多人不玩qq了,但是怀旧一下,欢迎加入六脉神剑Java菜鸟学习群,群聊号码:549684836 鼓励大家在技术的路上写博客
絮叨
我们继续来探索mysql。前面我们了解了mysql的索引的一些基础知识,今天我们来康康B+树索引
- Mysql从入门到入神之(一)Schema 数据类型优化 和索引基础
- Mysql从入门到入神之(二)Select 和Update的执行过程
- Mysql从入门到入神之(三)InnoDB的存储结构
- Mysql从入门到入神之(四)B+树索引
- Mysql从入门到入神之(五)表空间和单表查询
上面那章是基础,讲的是单表的查询方式,如果没有看过的,请移驾上面一章。
慢查询基础:优化数据访问
查询性能低下的很大的原因就是我们要查询的数据太多,你一个报表查询本来就得很慢,对于低效的查询,我们可能参考以下2个步骤。
- 确定应用程序是否在检索大量超过需要的数据。
- 确定mysql 服务器层是否分析大量超过需要的数据。
是否像数据库请求了不需要的数据。
有很多sql,请求了超过实际需要的数据,这种会给服务器带来额外的负担,并增加网络开销。比如下面的案例就是不好的案例
- 例如只需要返回2个列 但是你却使用了*这种情况就是不应该的。
- 第二个就是你比如需要查询10条数据,但是你确没有用limit去限制查询的个数。
是否扫描额外的记录
在确定以及肯定我们需要返回的行数之后,接下来需要优化的就是看是否查询了过多的数据,对于mysql来说,最简单的衡量查询开销的三个指标如下:
- 响应时间
- 扫描行数
- 返回的行数
扫描行数和返回行数
如果发现我们扫描过多的行数,但是我们确只是返回少量的行数,这种的优化方式有以下几个方面。
- 使用索引覆盖扫描,把所有需要的列都放到索引中,这样存储引擎无须回表获取对应行就可以返回结果了
- 改变库表结构,使用单独的汇总表
- 重写这个复杂的sql,用代码的逻辑来拆分这个sql。
重构查询方式
在优化查询问题时,我们的目标是找到一个方法,只要结果是和原来的结果相同,然后更少的时间开销的方法,以前总是强调需要数据库层面去完成尽可能多的工作,这样的逻辑在以前认为成立的原因是他们以为网络开销会很高,但是这些对于mysql来说并不适用,mysql的连接和断开都是很轻量的,所以小查询才是王道
一个复杂的查询还是多个简单的查询
我最近接手一个项目,前同事的sql里面全是逻辑。导致系统的性能特别的慢,然后我们接手之后,做了一波优化,把他全部拆成多个简单的查询,虽然说连接的次数多了,但是我们的查询效率,和代码的可复用性,可拓展性不知道强了多少倍,所以说看情况,如果可以优化成多个简单查询,就尽量优化。
切分查询 (分而治之)
就拿批量更新来说,比如我修改了一个题目的章节,我需要修改这个题目以前做个的用户的章节,那么我就需要批量更新,如果说一次性更新那么多的数据,是不是会锁很多的数据,导致大事务,如果我把他拆成多个更新,每次更新1k个就会好很多。
分解关联查询
很多高性能的应用都会对关联查询进行分解,简单地,可以对每一张表进行单表查询,然后把查出来的结果在应用层去做关联,比如下面的例子


为啥要这样做。这样做的好处是什么
- 拆分查询之后,执行单个查询 可以减少锁竞争
- 在应用层做分解,更加容易对数据库进行拆分,更容易做到高性能的拓展
- 查询本身的性能也会有所增加
- 拆分查询可以减少冗余的查询
关联子查询优化
其实很多的关联子查询是非常糟糕的,最糟的是 where 后面跟 in的子查询,一般像这样的子查询我们建议使用left join来实现
对最大值,最小值的优化,
很多情况下,对一个字段求他的最大值,最小值,我们会用函数去做,但是这样的情况并不是最好的,比如有些场景,就是我们可以知道这个查询字段如果是索引的话,那么索引本身就是有排序的,那么我们只需要把他排序好,取limit 1 比你用 函数会好很多。
对count的优化
很多博客啥的说最后不要count(),其实他们这样是错误的,其实最好的查询结果的行数的方式就是count(),因为人家底层对他做了优化的。
按照效率排序的话,count(字段)<count(主键 id)<count(1)≈count(),所以我 建议你,尽量使用 count()。
连接的原理
搞数据库一个避不开的概念就是Join,翻译成中文就是连接。相信很多小伙伴在初学连接的时候有些一脸懵逼,理解了连接的语义之后又可能不明白各个表中的记录到底是怎么连起来的,以至于在使用的时候常常陷入下边两种误区:
- 误区一:业务至上,管他三七二十一,再复杂的查询也用在一个连接语句中搞定。
- 误区二:敬而远之,上次 DBA 那给报过来的慢查询就是因为使用了连接导致的,以后再也不敢用了。
内连接和外连接的概念
- 对于内连接的两个表,驱动表中的记录在被驱动表中找不到匹配的记录,该记录不会加入到最后的结果集,我们上边提到的连接都是所谓的内连接。
- 对于外连接的两个表,驱动表中的记录即使在被驱动表中没有匹配的记录,也仍然需要加入到结果集。
- 在MySQL中,根据选取驱动表的不同,外连接仍然可以细分为2种: - 左连接 - 右连接
可是这样仍然存在问题,即使对于外连接来说,有时候我们也并不想把驱动表的全部记录都加入到最后的结果集。这就犯难了,有时候匹配失败要加入结果集,有时候又不要加入结果集,这咋办,有点儿愁啊。。。噫,把过滤条件分为两种不就解决了这个问题了么,所以放在不同地方的过滤条件是有不同语义的:
-
WHERE子句中的过滤条件
- WHERE子句中的过滤条件就是我们平时见的那种,不论是内连接还是外连接,凡是不符合WHERE子句中的过滤条件的记录都不会被加入最后的结果集。
-
ON子句中的过滤条件
- 对于外连接的驱动表的记录来说,如果无法在被驱动表中找到匹配ON子句中的过滤条件的记录,那么该记录仍然会被加入到结果集中,对应的被驱动表记录的各个字段使用NULL值填充。
连接的原理
嵌套循环连接(Nested-Loop Join)
我们前边说过,对于两表连接来说,驱动表只会被访问一遍,但被驱动表却要被访问到好多遍,具体访问几遍取决于对驱动表执行单表查询后的结果集中的记录条数。对于内连接来说,选取哪个表为驱动表都没关系,而外连接的驱动表是固定的,也就是说左(外)连接的驱动表就是左边的那个表,右(外)连接的驱动表就是右边的那个表。我们上边已经大致介绍过t1表和t2表执行内连接查询的大致过程,我们温习一下:
- 步骤1:选取驱动表,使用与驱动表相关的过滤条件,选取代价最低的单表访问方法来执行对驱动表的单表查询。
- 步骤2:对上一步骤中查询驱动表得到的结果集中每一条记录,都分别到被驱动表中查找匹配的记录。
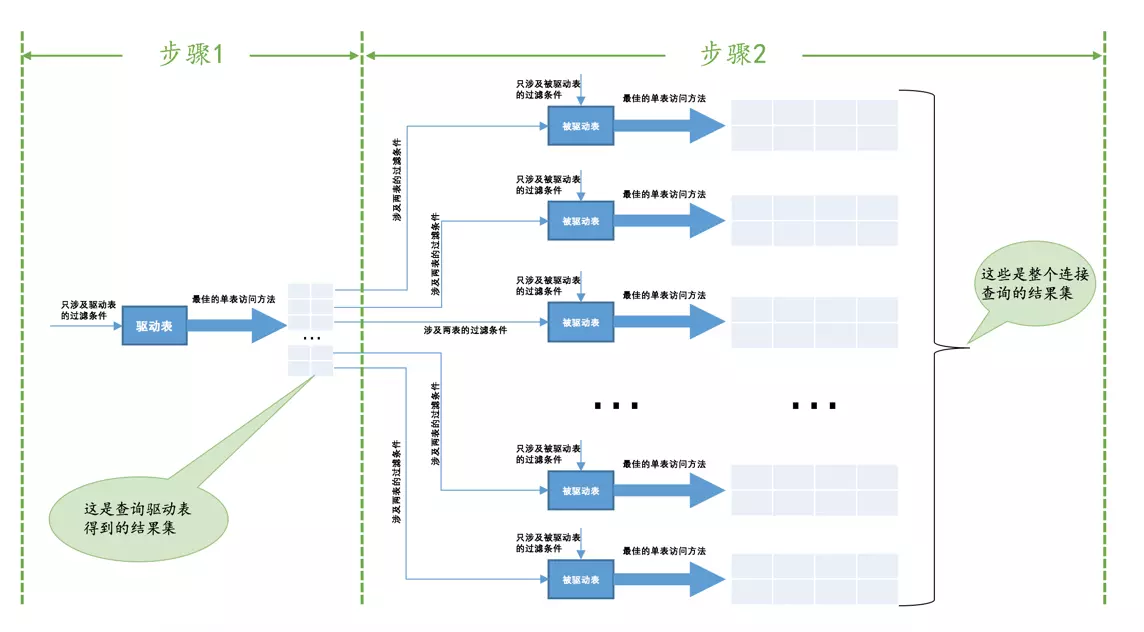
如果有3个表进行连接的话,那么步骤2中得到的结果集就像是新的驱动表,然后第三个表就成为了被驱动表,重复上边过程,也就是步骤2中得到的结果集中的每一条记录都需要到t3表中找一找有没有匹配的记录,用伪代码表示一下这个过程就是这样:
for each row in t1 { #此处表示遍历满足对t1单表查询结果集中的每一条记录
for each row in t2 { #此处表示对于某条t1表的记录来说,遍历满足对t2单表查询结果集中的每一条记录
for each row in t3 { #此处表示对于某条t1和t2表的记录组合来说,对t3表进行单表查询
if row satisfies join conditions, send to client
}
}
}
使用索引加快连接速度
比如说在被驱动表上建立索引,让他们的查询类型变成 cast 或者是ref 这样就能加快查询速度了
基于块的嵌套循环连接(Block Nested-Loop Join)
提前划出一块内存(join buffer)存储驱动表结果集中的记录,然后开始扫描被驱动表,每一条被驱动表的记录一次性和这块内存中的多条驱动表记录匹配,可以显著减少被驱动表的I/O操作。
结尾
我们下章继续再战。
日常求赞
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是真粉。
创作不易,各位的支持和认可,就是我创作的最大动力,我们下篇文章见
六脉神剑 | 文 【原创】如果本篇博客有任何错误,请批评指教,不胜感激 !
