

作者:Shreyas Raghavan
翻译:老齐
与本文相关的图书推荐:《数据准备和特征工程》

本书已经由电子工业出版社出版发行,购买地址:电子工业出版社天猫旗舰店
不是很久以前,商人们往往找占星家来预测下明年是否能挣钱,虽然这毫无根据,并且结果也不确定,但如果听专家的建议来为自己的商业行为作出决定,与此有什么本质却别?现在不同了,我们正在变化,目前已经可以基于事实和数字进行预测。
我们生活在一个大数据的世界中,去Domino商店订购披萨,他们首先要问你的手机号,通过该手机号,他们能够提取出你的住址、购买记录等信息,但是是否仅限于列出这些数据? 还是我们可以根据这些数据做些什么?这就是数据科学家的职责了。
现在,我们就来探讨一些分析数据的工具。
-
SAS,是“ Statistical Analysis System”的简称,可以用于高级分析、数据管理、商业智能,它是NCSU(北卡罗来纳州立大学)从1966年到1976年研发的许可软件,现在仍然被广泛应用,特别是财富500强的公司都在应用。
-
R语言,是一种开源高级语言,提供了很多分析和统计的模块,包含了很多开源库,主要操作在命令行界面实现。
-
Python语言,我个人最喜欢了。Python是门革命性的语言,本文就要使用此语言。它是由吉多·范罗索姆(Guido Van Rossum)发明的一种高级编程语言,开源,每天都会有很多库产生。如果你打算在机器学习、人工智能领域从业,Python是一门理想的编程语言。
现在,我们就要来看看Python在数据科学中的应用。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
此处,我们引入了三个基本的库,你的项目大概有90%都会用到这三个库,它们都有什么作用呢?
- Numpy:这个库实现众多数学函数运算,比如矩阵乘法、转置等。
- Pandas:很重要的库,比如加载数据集、创建DataFrame对象,Pandas在分析和预测方面能够实现你想做的任何事情。
- %matplotlib inline:写上这句话,就可以将制作的可视化图像插入到Jupyter中。
train = pd.read_csv('train.csv')
以上,我们载入了数据集,pd是对pandas的重命名(import pandas as pd),read_csv是pandas里的一个函数,train.csv是一个已经存在的文件。用上面的命令成功地在当前Python环境中加载了文件,从而创建了一个DataFrame对象。
train.head()
什么是head?不是人体的顶部的吗?Pandas用head函数,是要给我们呈现DataFrame对象中前面的若干条记录,默认显示前5条。
如果head(20)就会返回前20条记录,是不是很有意思?
我们也可以用tail()查看最后5条记录(默认值是5)。
下面是head()的输出结果:
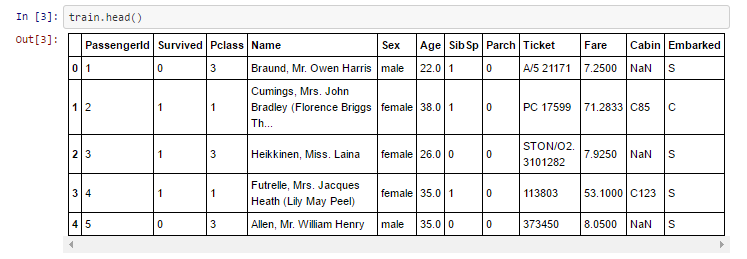
到现在,已经从DataFrame数据集中得到了前5条记录了。
接下来,重要的事情是你要了解所处理的数据集,比如大小、形状和描述性统计,这些信息对我们进一步处理数据都非常有用,也就是说,我们必须了解数据集(注:《数据准备和特征工程》一书中对此内容做了更详细的阐述,请参考。)因为有少数数据集很大,处理它们才是真正的痛苦工作,我们需要从中找到有用的信息,并剔除不需要的内容,这听起来似乎很容易,但真正做起来,非常困难。

从输出结果中可以看到,我们现在操作的数据有891行,12列,总共有10692个数据。
让我们再来看看基本的统计:
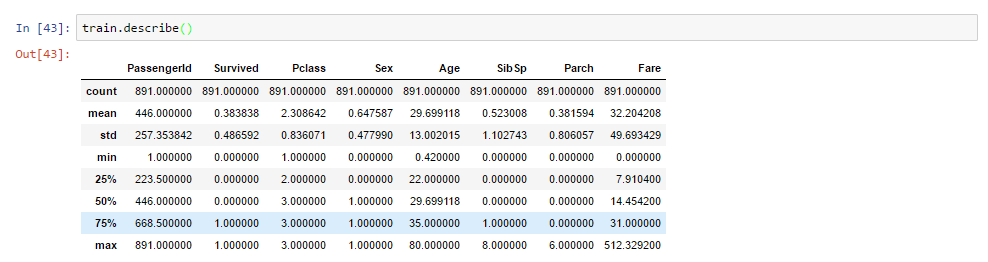
这里呈现的统计数据,比如计数、平均值、百分位、标准差等,在我们处理金融数据或者研究数据间关系是,都是非常重要的。
继续,我们要实施数据可视化,这是数据科学中最重要的技能,必须会。前面已经导入了matplotlib,这是数据可视化中应用非常广泛的库,如果你去搜索,还会发现别的库,但matplotlib是广受欢迎的。
对于数据科学家而言,最重要的是知道用什么方式进行表达,下面就讨论这个问题,然后演示代码。
表达的方式
进行数据可视化,必须要知道的几件事:
- 在一张图中要展现几个变量?
- 一个数据点包含了一个信息还是多个?
- 展示一段时间的数据,还是将它们分组?
这些会影响图示的效果。
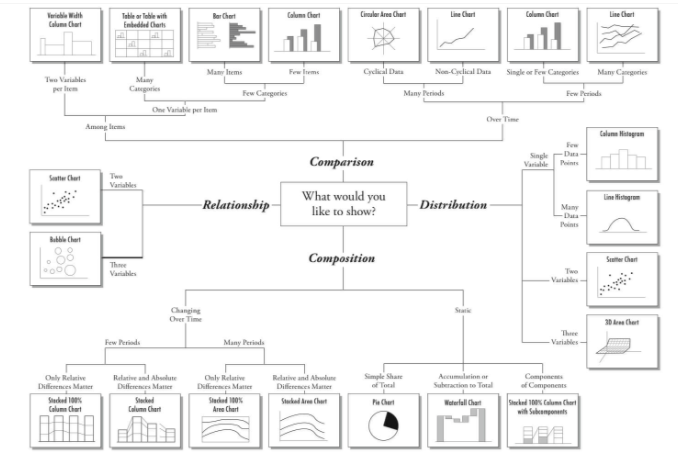
上面这张图帮助我们理清楚何时用何种类型的可视化方式。
对于学习数据可视化而言,上面的图示是具有高度参考价值的。很多公司都希望通过数据告诉我们吸引人的故事。
可视化工具,比如Tableau、PowerBI等创建的仪表盘,能够告诉我们数据中的故事。
现在,我们要研究如何用matplotlib实现数据可视化:
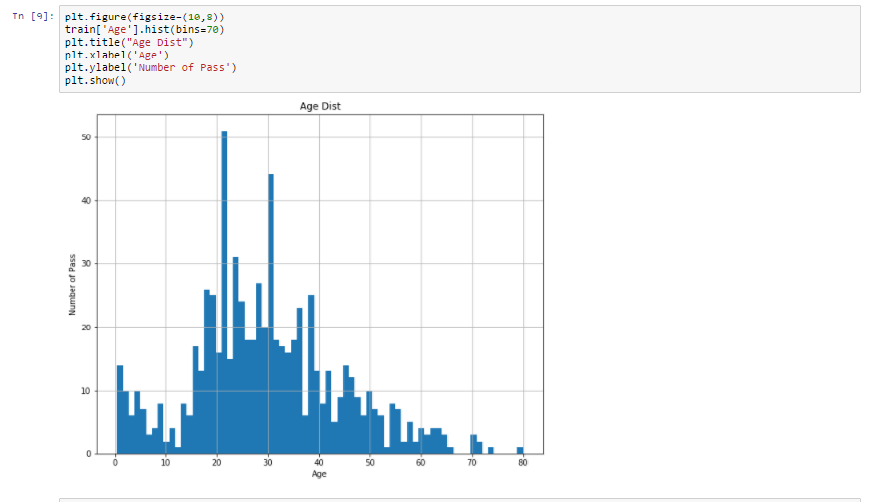
前面已经引入了matplotlib,并命名别称为plt。从第一行开始,用参数figsize设置了图示的大小,通常,我们可以使用默认值。接下来,就回执年龄的图示。
我们能够设置标签,xlable意味着x轴,ylable意味着y轴,titile用于设置图示的标题。
通过图示,我们能够从数据中得到一些信息,能推论出以下各项吗?
- 年轻人更多在甲板上。
- 老年人数量很少。
- 22岁的最多。
- 79岁的老人还去旅游。
我们通过图示,能够推断出的还很多。
当然,我们也能够用这个数据集做其他类型的统计图。
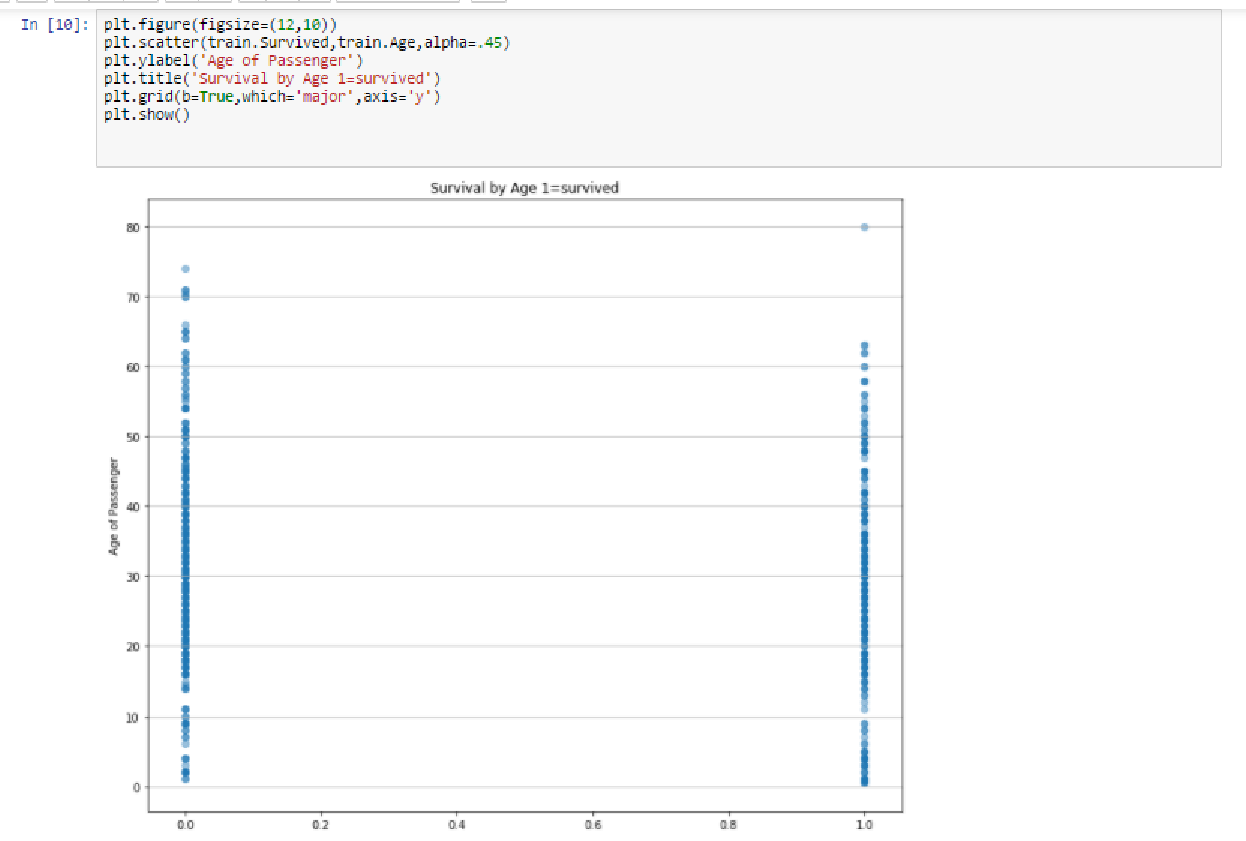
数据中用二进制的方式标识了一个人是否获救,这是我们下面要研究的内容,通过统计模型进行预测。
让我们继续,依靠前面的数据,用计算机来预测一个乘客是否能获救。
机器学习算法
到目前,我们已经完成了载入数据、数据可视化,以及如何根据数据进行推论,现在我们要看看哪个算法可以用于预测。
在机器学习中,有两类算法:
- 有监督学习:如果数据中有标签列,就可以使用有监督学习,机器会查找跟数据匹配的标签。
- 无监督学习:没有标签时就要用无监督学习,机器会对数据进行聚类,并找到数据之间的关系。
有监督学习的典型例子是回归,而贝叶斯则是无监督学习的典型示例。
但是,对于本文中的数据,我们打算用Logistic回归试试。具体怎么做?
Logistic回归能够帮助我们预测某数据的标签是true还是false。基本过程是用给定的数据输入到机器中,然后机器用回归模型进行计算,最后告诉我们一个二进制形式的结果。
根据维基百科,Logistic回归,或者logit回归、logit模型,是一种回归模型,它的因变量是分类型的。本文中的因变量用二级制形式表示,即只取两个数,“0”或者“1”,这种二进制方式可以代表不同的输出结果,比如通过/挂科、赢/输、生/死,或者健康/生病等。如果因变量是超过两个值得分类数据,可以用多元Logistic回归。如果多个类型值是有顺序的,可以用序数Logistic回归。在经济领域,Logisti回归是一种反应定性问题或者离散问题的模型示例。
那么,Logistic回归在这里对我们有什么用?
我们已经有用二进制形式表示获救情况的列,这已不是问题。但是,我们需要将性别(gender)列的值修改为1和0,这样我们就能依靠性别预测一个人是否获救。
需要导入sklearn库,sklearn非常强大,它不仅仅是统计工具。
按照下面的操作:
from sklearn.linear_model import LogisticRegression
从sklearn库中引入Logistic回归模块。
为了使用Logistic回归,先要具备两组数据:
- 训练集:用于训练模型
- 测试集:通常规模较小,用于检验机器学习模型
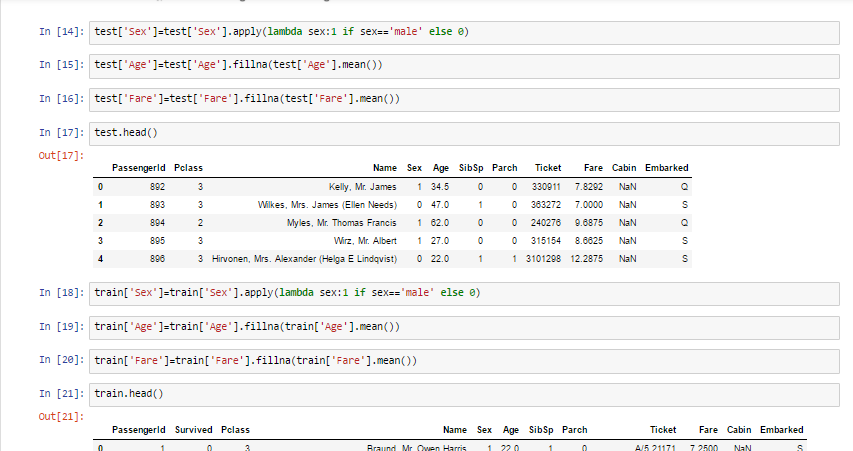
将性别转化为二级制形式之后,就可以使用LogisticRegression模型预测输出结果了。
首先,我们将训练集中的Survived列作为Logistic回归模型的输出。
为此,已经将数据集划分为训练集和测试集。
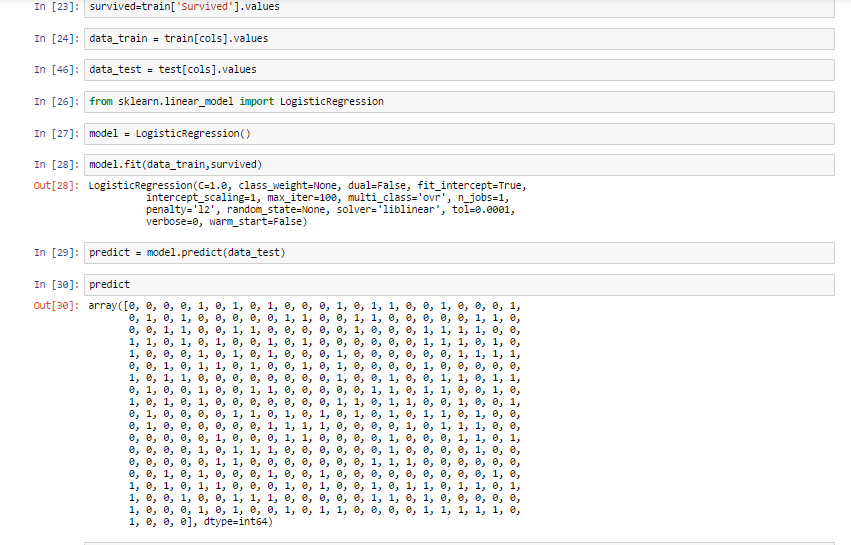
下面逐步来看看上面的过程:
- 将Survived列作为标签,即输出。data_train是输入的训练数据,其中不包含Survived列。
- 然后引入sklean,并创建Logistic模型实例。
- 接下来训练模型,计算机会努力找到一种模式,然后用这个模型对给定数据进行预测。
- 我们已经得到了一个被称为测试集的数据,它里面没有Survived列。下面利用训练得到的模型对这些数据进行预测。
以上就是计算机如何通过学习进行预测的过程,当然还有别的模型,以后有机会还要介绍对模型的评估方法,比如评估分数、矩阵分数等。
希望此文对你有启发。「老齐教室」这个微信公众号中还有很多数据科学、机器学习的文章,共学习者参考。
原文链接:towardsdatascience.com/how-to-begi…
搜索技术问答的公众号:老齐教室

在公众号中回复:老齐,可查看所有文章、书籍、课程。
觉得好看,就点赞转发/strong>
