C10K 问题是什么?
如何在一台物理机上同时服务 10000 个用户?这里 C 表示并发,10K 等于 10000。得益于操作系统、编程语言的发展,在现在的条件下,普通用户使用 Java Netty、Libevent 等框架或库就可以轻轻松松写出支持并发超过 10000 的服务器端程序,甚至于经过优化之后可以达到十万,乃至百万的并发,但在二十年前,突破 C10K 问题可费了不少的心思,是一个了不起的突破。
解决 C10K 问题需要考虑哪些方面?
操作系统层面
- 文件句柄
文件句柄用完会出现以下错误
Socket/File:Can't open so many files
$ulimit -n 可以查看系统设置的 Linux 的文件句柄数量
通过设置 增大
fs.file-max = 10000
net.ipv4.ip_conntrack_max = 10000
net.ipv4.netfilter.ip_conntrack_max = 10000
- 系统内存
我们假设每个连接需要 128K 的缓冲区,那么 1 万个链接就需要大约 1.2G 的应用层缓冲。
- 网络带宽
假设 1 万个连接,每个连接每秒传输大约 1KB 的数据,那么带宽需要 10000 x 1KB/s x8 = 80Mbps。这在今天的动辄万兆网卡的时代简直小菜一碟。
网络编程层面
在系统资源层面C10K 问题是可以解决的,但是并不意味着可以很好地解决。 在网络编程中,涉及到频繁的用户态-内核态数据拷贝,高并发场景下设计不好的程序性能可能成指数级别的下降。
举一个例子,如果没有考虑好 C10K 问题,一个基于 select 的经典程序可能在一台服务器上可以很好处理 1000 的并发用户,但是在性能 2 倍的服务器上,却往往并不能很好地处理 2000 的并发用户。
接下来我们将从两个层面上来统筹考虑。
第一个层面,应用程序如何和操作系统配合,感知 I/O 事件发生,并调度处理在上万个套接字上的 I/O 操作?前面讲过的阻塞 I/O、非阻塞 I/O 讨论的就是这方面的问题。
第二个层面,应用程序如何分配进程、线程资源来服务上万个连接。
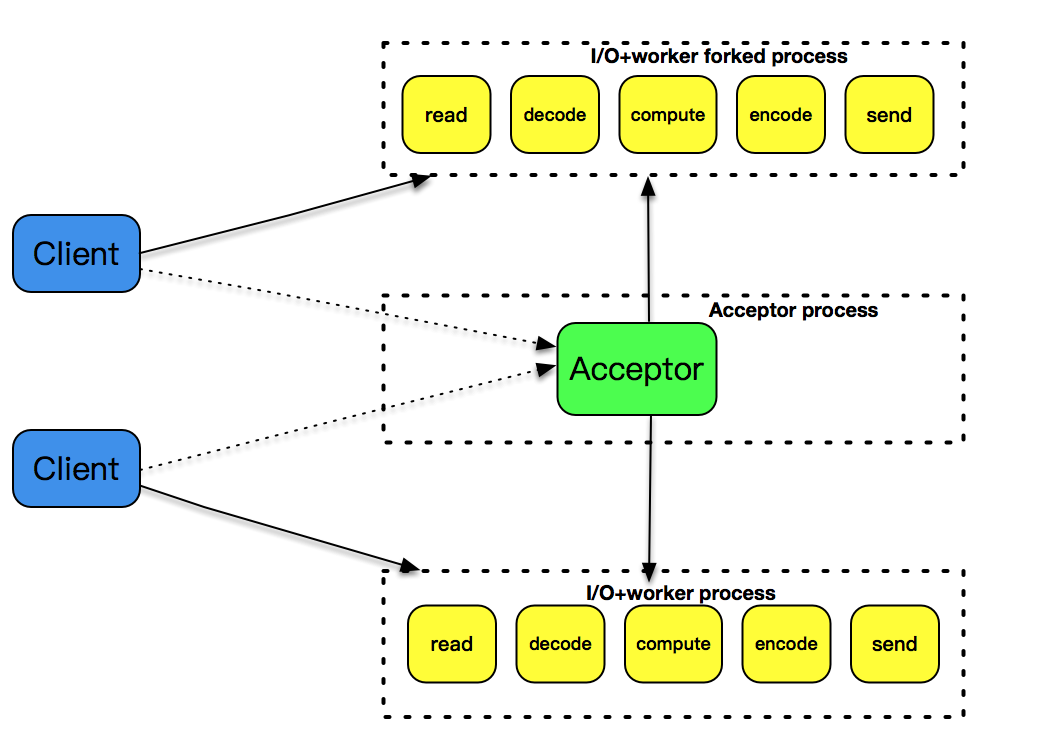
1. 阻塞 I/O + 进程
do {
accept connections
fork for conneced connection fd
process_run(fd)
}
#include "lib/common.h"
#define MAX_LINE 4096
char rot13_char(char c) {
if ((c >= 'a' && c <= 'm') || (c >= 'A' && c <= 'M'))
return c + 13;
else if ((c >= 'n' && c <= 'z') || (c >= 'N' && c <= 'Z'))
return c - 13;
else
return c;
}
void child_run(int fd) {
char outbuf[MAX_LINE + 1];
size_t outbuf_used = 0;
ssize_t result;
while (1) {
char ch;
result = recv(fd, &ch, 1, 0);
if (result == 0) {
break;
} else if (result == -1) {
perror("read");
break;
}
if (outbuf_used < sizeof(outbuf)) {
outbuf[outbuf_used++] = rot13_char(ch);
}
if (ch == '\n') {
send(fd, outbuf, outbuf_used, 0);
outbuf_used = 0;
continue;
}
}
}
void sigchld_handler(int sig) {
while (waitpid(-1, 0, WNOHANG) > 0);
return;
}
int main(int c, char **v) {
int listener_fd = tcp_server_listen(SERV_PORT);
// 注册信号函数, 用来回收子进程资源
signal(SIGCHLD, sigchld_handler);
while (1) {
struct sockaddr_storage ss;
socklen_t slen = sizeof(ss);
int fd = accept(listener_fd, (struct sockaddr *) &ss, &slen);
if (fd < 0) {
error(1, errno, "accept failed");
exit(1);
}
if (fork() == 0) {
// 进入子进程
close(listener_fd);
child_run(fd);
exit(0);
} else {
close(fd);
}
}
return 0;
}
使用阻塞 I/O 和进程模型,为每一个连接创建一个独立的子进程来进行服务,是一个非常简单有效的实现方式,这种方式可能很难满足高性能程序的需求,但好处在于实现简单,Apache 服务器就是采用这种模型。 在实现这样的程序时,我们需要注意两点:
- 要注意对套接字的关闭梳理;
- 要注意对子进程进行回收,避免产生不必要的僵尸进程。
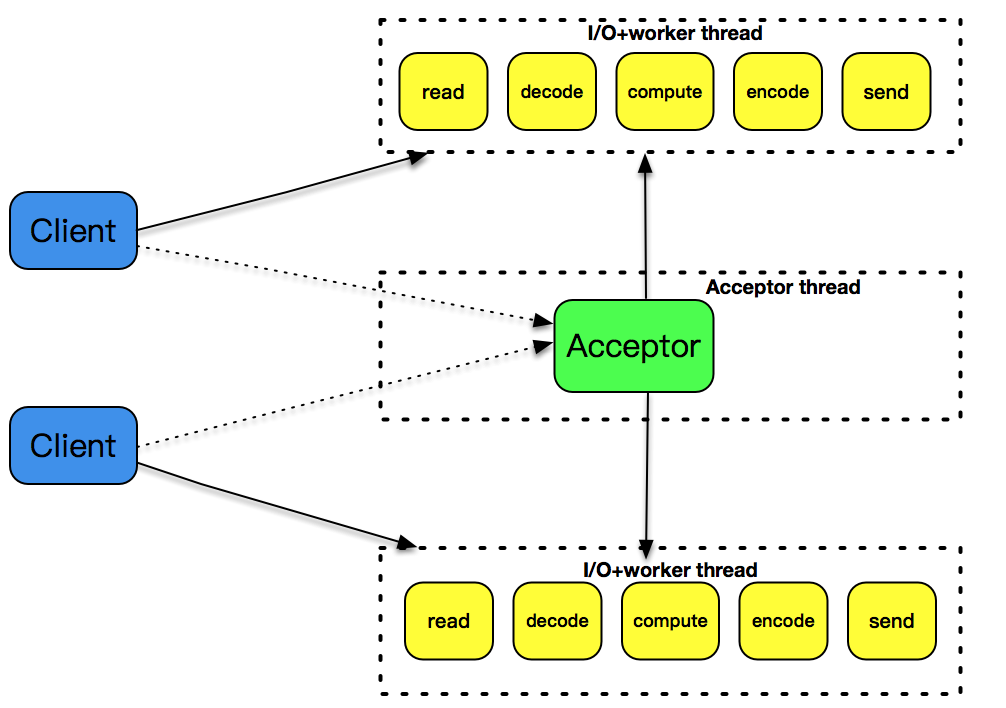
2. 阻塞 I/O + 线程
do {
accept connections
pthread_create for connected connection fd
thread_run(fd)
} while (true)
#include "lib/common.h"
extern void loop_echo(int);
void thread_run(void *arg) {
pthread_detach(pthread_self());
int fd = (int) arg;
loop_echo(fd);
}
int main(int c, char **v) {
int listener_fd = tcp_server_listen(SERV_PORT);
pthread_t tid;
while (1) {
struct sockaddr_storage ss;
socklen_t slen = sizeof(ss);
int fd = accept(listener_fd, (struct sockaddr *) &ss, &slen);
if (fd < 0) {
error(1, errno, "accept failed");
} else {
pthread_create(&tid, NULL, &thread_run, (void *) fd);
}
}
return 0;
}
char rot13_char(char c) {
if ((c >= 'a' && c <= 'm') || (c >= 'A' && c <= 'M'))
return c + 13;
else if ((c >= 'n' && c <= 'z') || (c >= 'N' && c <= 'Z'))
return c - 13;
else
return c;
}
void loop_echo(int fd) {
char outbuf[MAX_LINE + 1];
size_t outbuf_used = 0;
ssize_t result;
while (1) {
char ch;
result = recv(fd, &ch, 1, 0);
//断开连接或者出错
if (result == 0) {
break;
} else if (result == -1) {
error(1, errno, "read error");
break;
}
if (outbuf_used < sizeof(outbuf)) {
outbuf[outbuf_used++] = rot13_char(ch);
}
if (ch == '\n') {
send(fd, outbuf, outbuf_used, 0);
outbuf_used = 0;
continue;
}
}
}
相比于阻塞IO+多进程,减少了上下文切换所带来的开销,性能有所提高。
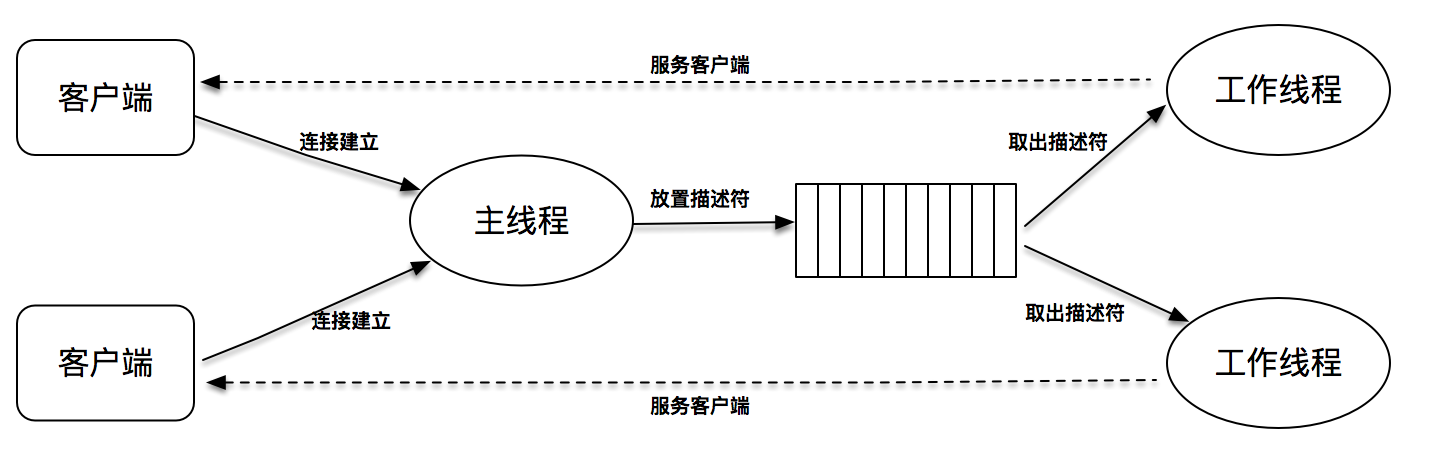
线程池优化:
create thread pool
do {
accept connections
get connection fd
push_queue(fd)
} while (true)
void thread_run(void *arg) {
pthread_t tid = pthread_self();
pthread_detach(tid);
block_queue *blockQueue = (block_queue *) arg;
while (1) {
int fd = block_queue_pop(blockQueue);
printf("get fd in thread, fd==%d, tid == %d", fd, tid);
loop_echo(fd);
}
}
int main(int c, char **v) {
int listener_fd = tcp_server_listen(SERV_PORT);
block_queue blockQueue;
block_queue_init(&blockQueue, BLOCK_QUEUE_SIZE);
thread_array = calloc(THREAD_NUMBER, sizeof(Thread));
int i;
for (i = 0; i < THREAD_NUMBER; i++) {
pthread_create(&(thread_array[i].thread_tid), NULL, &thread_run, (void *) &blockQueue);
}
while (1) {
struct sockaddr_storage ss;
socklen_t slen = sizeof(ss);
int fd = accept(listener_fd, (struct sockaddr *) &ss, &slen);
if (fd < 0) {
error(1, errno, "accept failed");
} else {
block_queue_push(&blockQueue, fd);
}
}
return 0;
}
//定义一个队列
typedef struct {
int number; //队列里的描述字最大个数
int *fd; //这是一个数组指针
int front; //当前队列的头位置
int rear; //当前队列的尾位置
pthread_mutex_t mutex; //锁
pthread_cond_t cond; //条件变量
} block_queue;
//初始化队列
void block_queue_init(block_queue *blockQueue, int number) {
blockQueue->number = number;
blockQueue->fd = calloc(number, sizeof(int));
blockQueue->front = blockQueue->rear = 0;
pthread_mutex_init(&blockQueue->mutex, NULL);
pthread_cond_init(&blockQueue->cond, NULL);
}
//往队列里放置一个描述字fd
void block_queue_push(block_queue *blockQueue, int fd) {
//一定要先加锁,因为有多个线程需要读写队列
pthread_mutex_lock(&blockQueue->mutex);
//将描述字放到队列尾的位置
blockQueue->fd[blockQueue->rear] = fd;
//如果已经到最后,重置尾的位置
if (++blockQueue->rear == blockQueue->number) {
blockQueue->rear = 0;
}
printf("push fd %d", fd);
//通知其他等待读的线程,有新的连接字等待处理
pthread_cond_signal(&blockQueue->cond);
//解锁
pthread_mutex_unlock(&blockQueue->mutex);
}
//从队列里读出描述字进行处理
int block_queue_pop(block_queue *blockQueue) {
//加锁
pthread_mutex_lock(&blockQueue->mutex);
//判断队列里没有新的连接字可以处理,就一直条件等待,直到有新的连接字入队列
while (blockQueue->front == blockQueue->rear)
pthread_cond_wait(&blockQueue->cond, &blockQueue->mutex);
//取出队列头的连接字
int fd = blockQueue->fd[blockQueue->front];
//如果已经到最后,重置头的位置
if (++blockQueue->front == blockQueue->number) {
blockQueue->front = 0;
}
printf("pop fd %d", fd);
//解锁
pthread_mutex_unlock(&blockQueue->mutex);
//返回连接字
return fd;
}
相比于阻塞IO+多线程,减少了线程频繁创建和销毁的开销,性能有了进一步的提高。
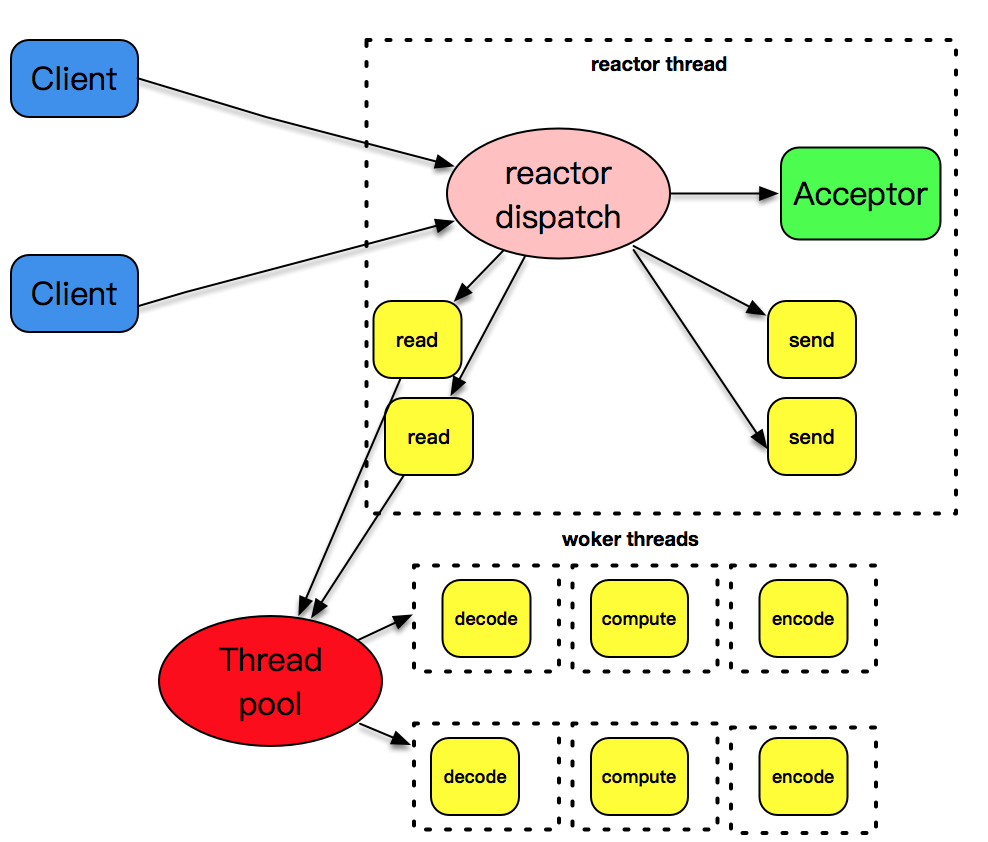
3. 非阻塞 I/O + readiness notification + 单线程
相比于阻塞IO + 线程池,采用了更加先进的事件驱动设计思想,资源占用少、效率高、扩展性强,是支持高性能高并发场景的利器。
for fd in fdset {
if (is_readable(fd) == true) {
handle_read(fd)
} else if (is_writeable(fd) == true) {
handle_write(fd)
}
}
#include <lib/acceptor.h>
#include "lib/common.h"
#include "lib/event_loop.h"
#include "lib/tcp_server.h"
char rot13_char(char c) {
if ((c >= 'a' && c <= 'm') || (c >= 'A' && c <= 'M'))
return c + 13;
else if ((c >= 'n' && c <= 'z') || (c >= 'N' && c <= 'Z'))
return c - 13;
else
return c;
}
//连接建立之后的callback
int onConnectionCompleted(struct tcp_connection *tcpConnection) {
printf("connection completed\n");
return 0;
}
//数据读到buffer之后的callback
int onMessage(struct buffer *input, struct tcp_connection *tcpConnection) {
printf("get message from tcp connection %s\n", tcpConnection->name);
printf("%s", input->data);
struct buffer *output = buffer_new();
int size = buffer_readable_size(input);
for (int i = 0; i < size; i++) {
buffer_append_char(output, rot13_char(buffer_read_char(input)));
}
tcp_connection_send_buffer(tcpConnection, output);
return 0;
}
//数据通过buffer写完之后的callback
int onWriteCompleted(struct tcp_connection *tcpConnection) {
printf("write completed\n");
return 0;
}
//连接关闭之后的callback
int onConnectionClosed(struct tcp_connection *tcpConnection) {
printf("connection closed\n");
return 0;
}
int main(int c, char **v) {
//主线程event_loop
struct event_loop *eventLoop = event_loop_init();
//初始化acceptor
struct acceptor *acceptor = acceptor_init(SERV_PORT);
//初始tcp_server,可以指定线程数目,如果线程是0,就只有一个线程,既负责acceptor,也负责I/O
struct TCPserver *tcpServer = tcp_server_init(eventLoop, acceptor, onConnectionCompleted, onMessage,
onWriteCompleted, onConnectionClosed, 0);
tcp_server_start(tcpServer);
// main thread for acceptor
event_loop_run(eventLoop);
}
优化 fdset 循环遍历效率
do {
poller.dispatch()
for fd in registered_fdset {
if (is_readable(fd) == true) {
handle_read(fd)
} else if (is_writeable(fd) == true) {
handle_write(fd)
}
}
}while(true)
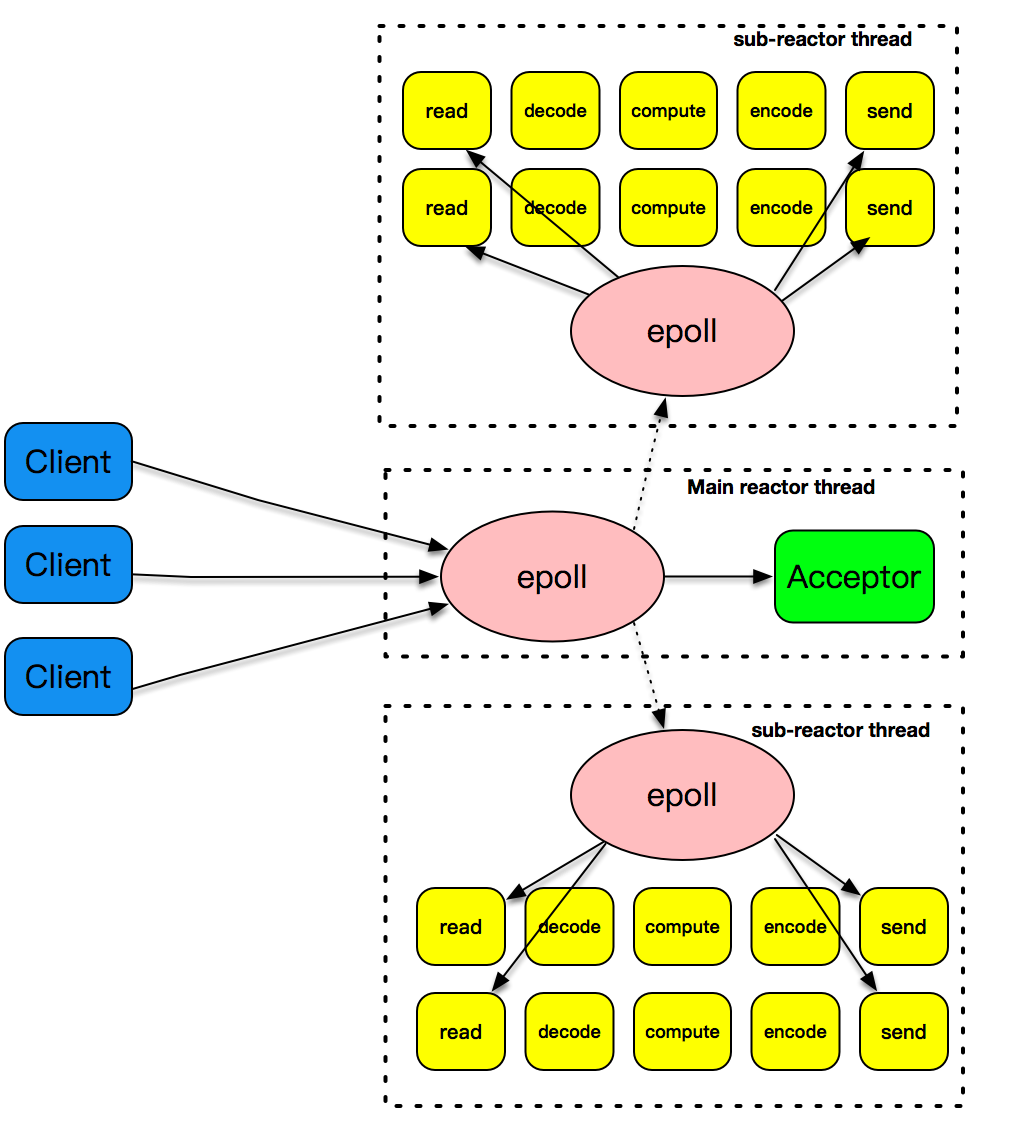
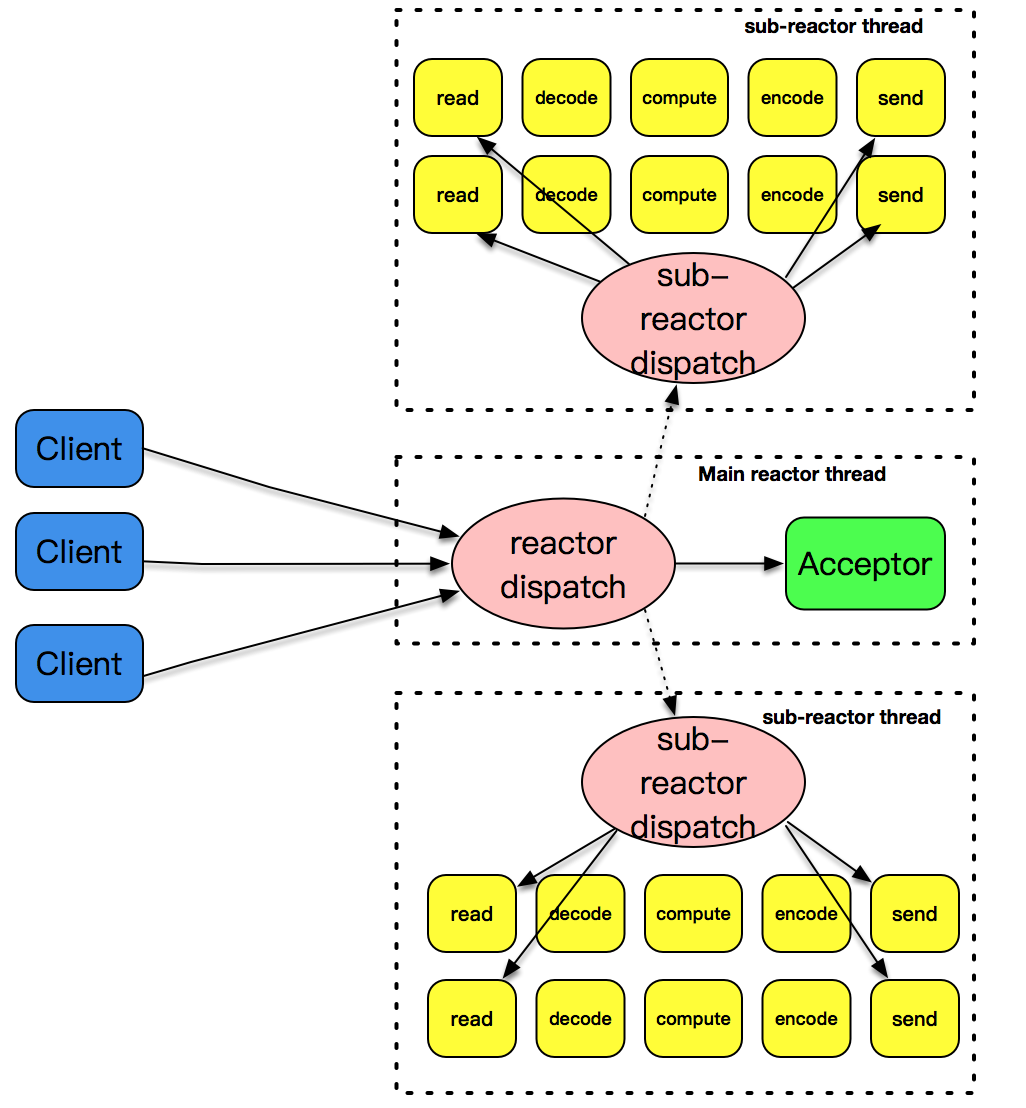
4. 非阻塞 I/O + readiness notification + 多线程
相比于Reactor + 线程池,将连接建立事件和已建立连接的各种IO事件分离,主Reactor只负责处理连接事件,从Reactor只负责处理各种IO事件,这样能增加客户端连接的成功率,并且可以充分利用现在多CPU的资源特性进一步的提高IO事件的处理效率。
将 decode、compute、encode 等 CPU 密集型的工作从 I/O 线程中拿走,这些工作交给 worker 线程池来处理
样例程序
#include <lib/acceptor.h>
#include "lib/common.h"
#include "lib/event_loop.h"
#include "lib/tcp_server.h"
char rot13_char(char c) {
if ((c >= 'a' && c <= 'm') || (c >= 'A' && c <= 'M'))
return c + 13;
else if ((c >= 'n' && c <= 'z') || (c >= 'N' && c <= 'Z'))
return c - 13;
else
return c;
}
//连接建立之后的callback
int onConnectionCompleted(struct tcp_connection *tcpConnection) {
printf("connection completed\n");
return 0;
}
//数据读到buffer之后的callback
int onMessage(struct buffer *input, struct tcp_connection *tcpConnection) {
printf("get message from tcp connection %s\n", tcpConnection->name);
printf("%s", input->data);
struct buffer *output = buffer_new();
int size = buffer_readable_size(input);
for (int i = 0; i < size; i++) {
buffer_append_char(output, rot13_char(buffer_read_char(input)));
}
tcp_connection_send_buffer(tcpConnection, output);
return 0;
}
//数据通过buffer写完之后的callback
int onWriteCompleted(struct tcp_connection *tcpConnection) {
printf("write completed\n");
return 0;
}
//连接关闭之后的callback
int onConnectionClosed(struct tcp_connection *tcpConnection) {
printf("connection closed\n");
return 0;
}
int main(int c, char **v) {
//主线程event_loop
struct event_loop *eventLoop = event_loop_init();
//初始化acceptor
struct acceptor *acceptor = acceptor_init(SERV_PORT);
//初始tcp_server,可以指定线程数目,这里线程是4,说明是一个acceptor线程,4个I/O线程,没一个I/O线程
//tcp_server自己带一个event_loop
struct TCPserver *tcpServer = tcp_server_init(eventLoop, acceptor, onConnectionCompleted, onMessage,
onWriteCompleted, onConnectionClosed, 4);
tcp_server_start(tcpServer);
// main thread for acceptor
event_loop_run(eventLoop);
}
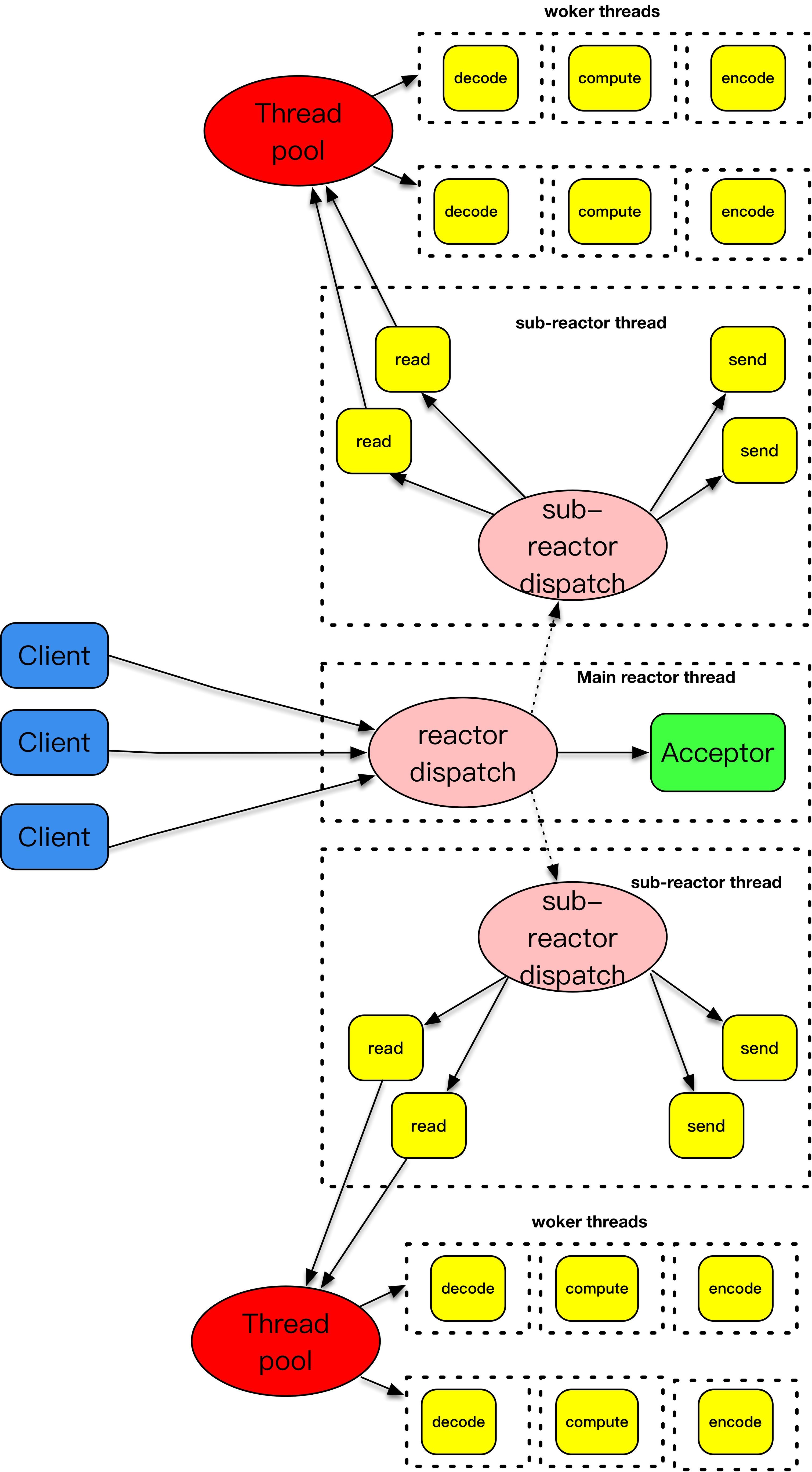
5. epoll + 多线程
epoll 的性能凭什么就要比 poll 或者 select 好呢?这要从两个角度来说明。
第一个角度是事件集合。在每次使用 poll 或 select 之前,都需要准备一个感兴趣的事件集合,系统内核拿到事件集合,进行分析并在内核空间构建相应的数据结构来完成对事件集合的注册。而 epoll 则不是这样,epoll 维护了一个全局的事件集合,通过 epoll 句柄,可以操纵这个事件集合,增加、删除或修改这个事件集合里的某个元素。要知道在绝大多数情况下,事件集合的变化没有那么的大,这样操纵系统内核就不需要每次重新扫描事件集合,构建内核空间数据结构。
第二个角度是就绪列表。每次在使用 poll 或者 select 之后,应用程序都需要扫描整个感兴趣的事件集合,从中找出真正活动的事件,这个列表如果增长到 10K 以上,每次扫描的时间损耗也是惊人的。事实上,很多情况下扫描完一圈,可能发现只有几个真正活动的事件。而 epoll 则不是这样,epoll 返回的直接就是活动的事件列表,应用程序减少了大量的扫描时间。