

在 SVM 白板推导| 由最大间隔化目标演化的损失函数推导过程 中白板手推了 SVM 的原理,并介绍了硬间隔核函数的实现原理及公式推导,这一节我来详细介绍下 SVM 中的 Keynel Function。
一直以来我们只知道核函数能让 SVM 在高维空间中实现非线性可分,那么,核函数是在什么情况下被提出的呢?又有哪几种核函数呢?
本篇文章从 2 个角度讲解 SVM 核函数。
- 非线性带来高维转换 (模型角度),
- 对偶表示带来内积 (优化角度),
从线性可分到线性不可分
如下表中介绍了 感知机 PLA 和 SVM 从线性可分到非线性可分的模型演变结果。
| 线性可分 | 一点点错误 | 严格非线性 |
|---|---|---|
| PLA | Pocket Algorithm | |
| Hard-Margin SVM | Soft-Margin SVM |
而在线性不可分的情况下,如果让模型能够变得线性可分?上面已经讲了,从 2 个角度来理解。
1. 非线性带来高维转换,引入 )
我们知道高维空间中的特征比低维空间中的特征更易线性可分,这是一个定理,是可以证明的,这里只需要知道就行。
那么,我们就可以想到一个办法,就是把在输入空间中的特征通过一个函数映射到高维空间。

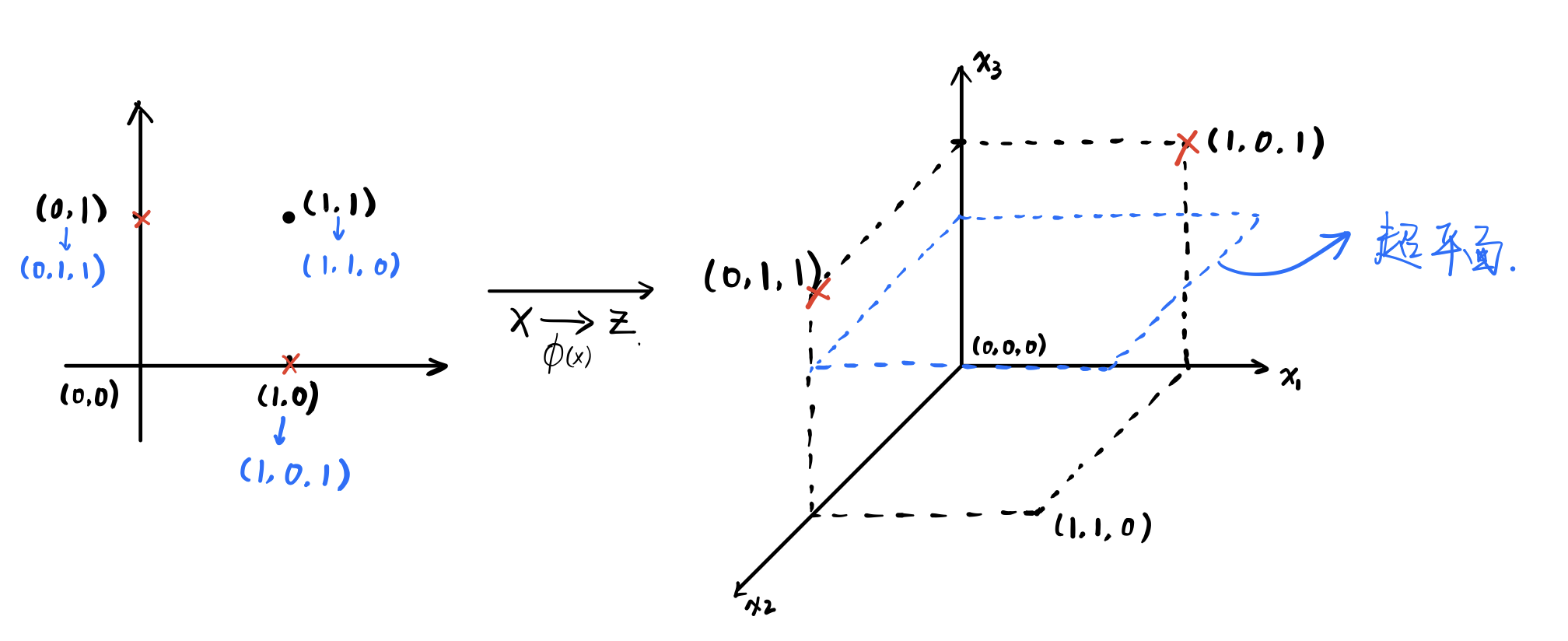
假设输入空间有一个点 ,是二维的,我们通过一个函数
将其映射到三维空间
,从二维到三维空间中的表示为:
2. 对偶表示带来内积,引入核函数
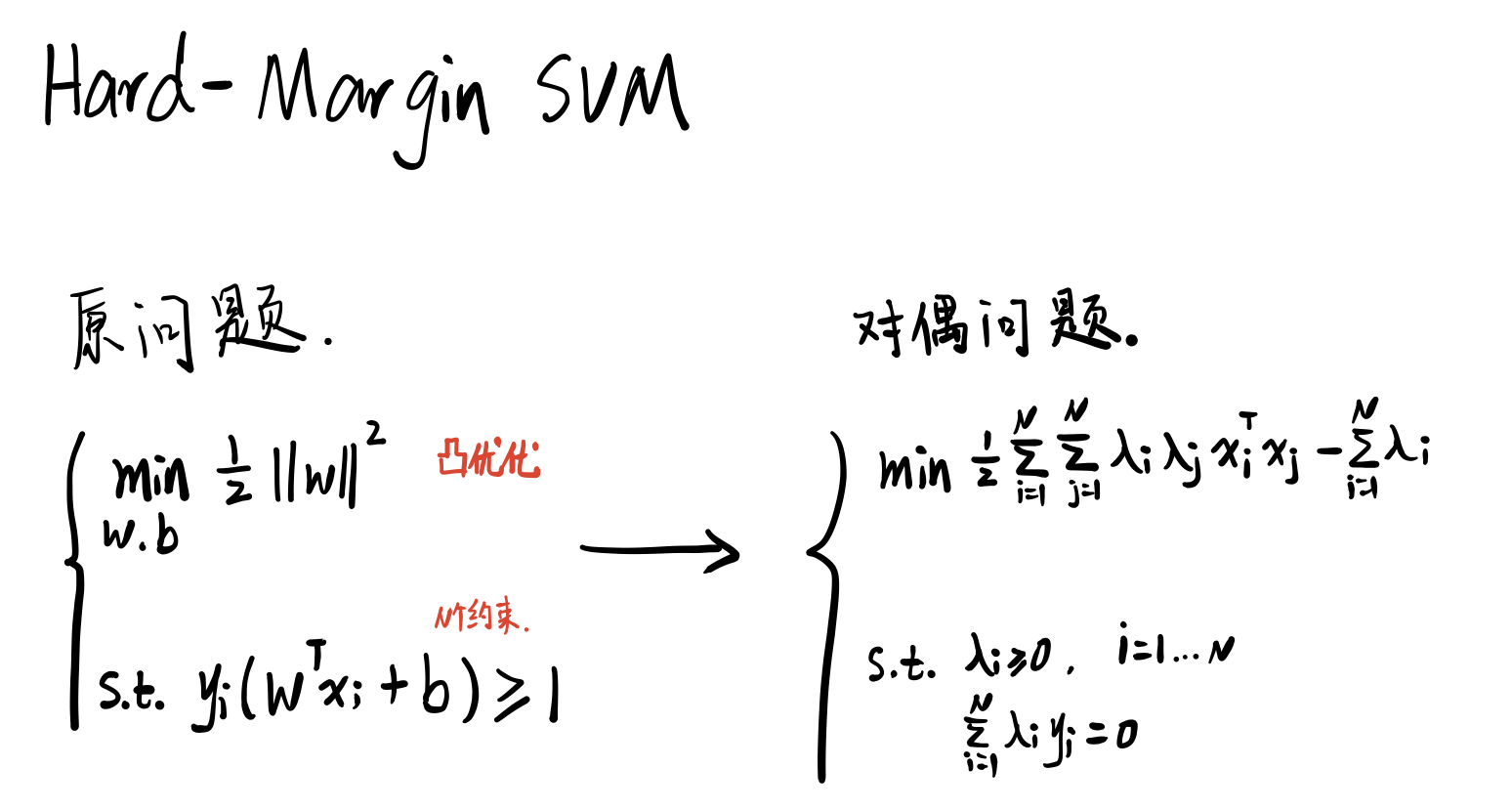
从另一个角度来看,之前我们已经推导出 SVM 的损失函数,Hard-Margin SVM 的对偶问题中,最终的优化问题只与 X 的内积有关,也即是支持向量有关。
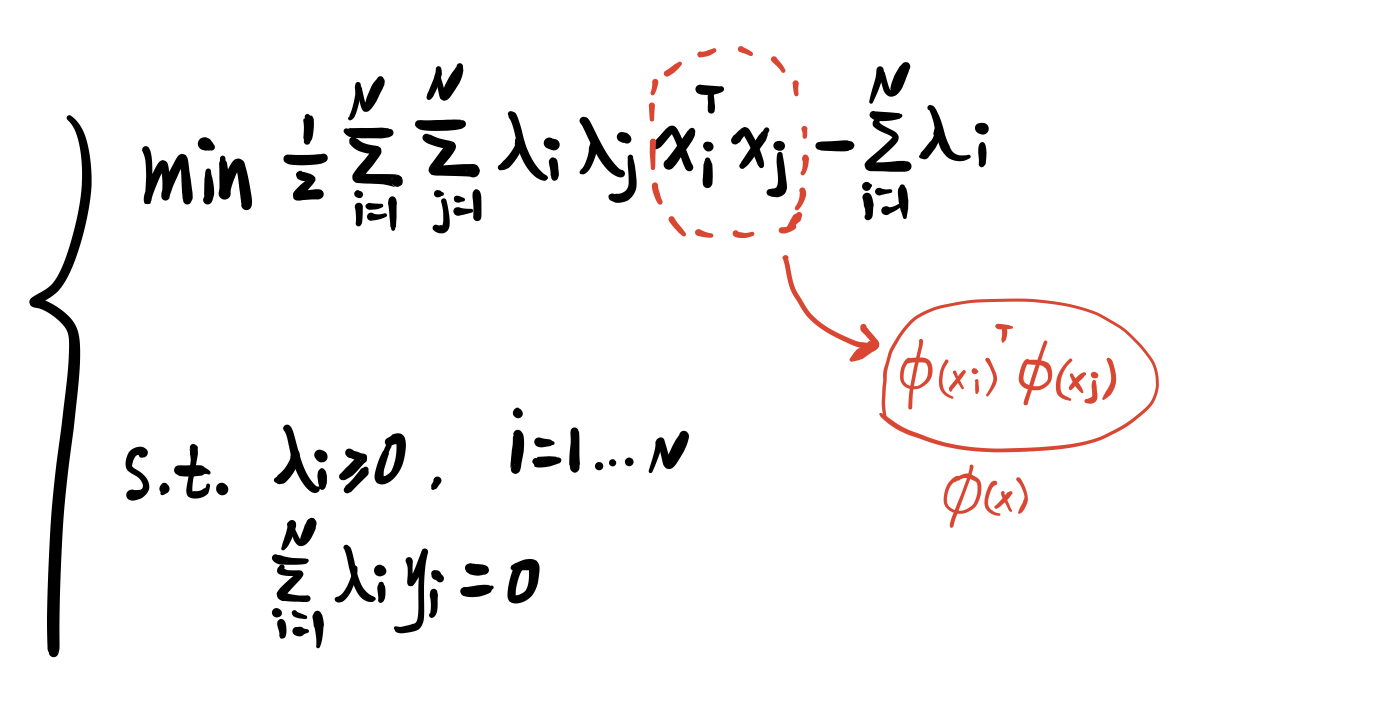
由此,我们可以将 X 的内积表示为 的内积
。
而我们现实生活中,可能 并不是上面举例的三维或者更高维,而是无限维,那么 的
将会非常难求。

换个角度思考,其实我们关心的只是 的内积,并不关心
。有没有一种方法能直接求出内积?答案是有的。
我们可以引入核函数 keynel function。

如上中的一个核函数,我们可以直接求出 X 的内积,避免在高维空间中求 。
针对核函数,我们可以总结出 3 点。
- 当在线性不可分的时候,我们可以将输入空间中的特征映射到高维空间,来实现线性可分。
- 在高维空间中,由于计算
非常困难,因为
- 因此,我们引入核函数,将原本需要在高维空间计算的内积变成在输入空间计算内积,也能达到一样的效果,从而减小计算。
核函数存在条件
定理: 令 为输入空间,
是定义在
上的对称函数,则
是核函数当且仅当对于任意数据
,“核矩阵”
总是半正定的:
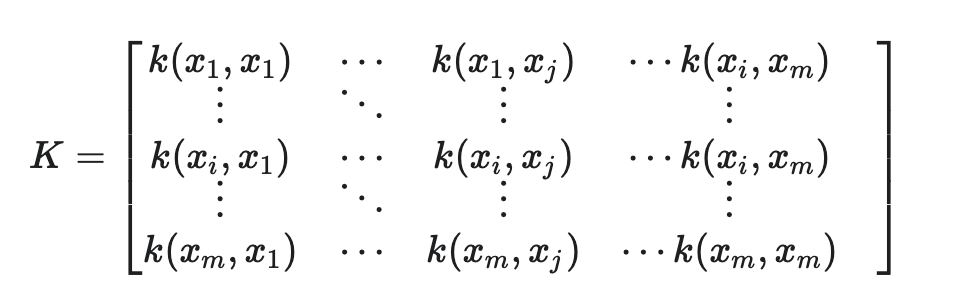
定理表明,只要一个对称函数所对应的核矩阵半正定,那么它就可以作为核函数使用。事实上,对于一个半正定核矩阵,总能找到一个与之对应的映射 。换言之,任何一个核函数都隐式定义了一个称为 “再生核希尔伯特空间” 的特征空间。
常见的核函数
通过前面的介绍,核函数的选择,对于非线性支持向量机的性能至关重要。但是由于我们很难知道特征映射的形式,所以导致我们无法选择合适的核函数进行目标优化。于是 “核函数的选择” 称为支持向量机的最大变数,我们常见的核函数有以下几种:

此外,还可以通过函数组合得到,例如:
- 若
和
为核函数,则对于任意正数
,其线性组合也是核函数。
- 若
- 若k_1k1为核函数,则对于任意函数
也是核函数。
对于非线性的情况,SVM 的处理方法是选择一个核函数 ,通过将数据映射到高维空间,来解决在原始空间中线性不可分的问题。由于核函数的优良品质,这样的非线性扩展在计算量上并没有比原来复杂多少,这一点是非常难得的。
当然,这要归功于核方法——除了 SVM 之外,任何将计算表示为数据点的内积的方法,都可以使用核方法进行非线性扩展。

