

上回说到我们已经通过爬虫以及将视频切割成多幅图片,今天就来谈谈如何通过机器学习的方法来减少筛选杰尼龟的工作量。这些图片可以粗暴地分为两类,是杰尼龟或者不是杰尼龟,这个分类任务不同于猫狗识别的二分类,而是单分类任务。
分类算法
分类算法若是按照类别个数划分,可以分为单分类、二分类以及多分类这三种。一般我们见的比较多是二分类或是多分类。
通过朴素贝叶斯算法来识别垃圾邮件、用神经网络来识别猫狗都是典型的二分类,垃圾邮件和正常邮件都有其对应特征及标签,猫和狗也都有其对应特征及标签,属于监督学习的范畴。
手写数字识别0-9则是一种典型的多分类,而今天我们的任务是判断某张图片是不是杰尼龟,即单分类任务。因为我们仅有现成的少量杰尼龟的图片作为正样本训练集并且很难找到合适的负样本,我们需要训练出一个单分类模型,该模型只关注与正样本相似或是匹配程度高的样本,将不属于该类的所有其他样本统一判为“不是”,而非由于属于另外一类而返回“不是”。
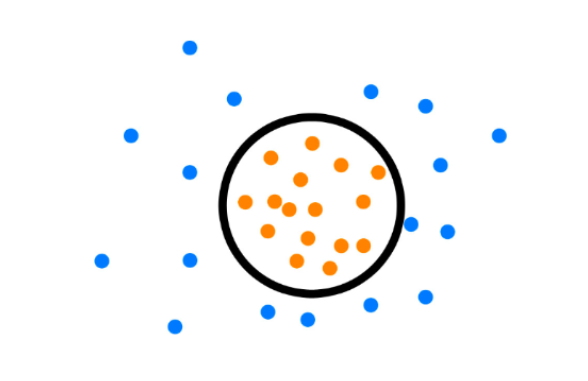
单分类支持向量机正是这样一种单分类算法,它实际上是确定正样本的边界,边界之外的数据会被分为另一类。恰好适用于当前这样负样本的特征不容易确定的场景。实际上,这是一种异常检测的算法。
特征提取
整体的思想是使用深度神经网络做特征提取,把提取出来的特征用于现有的单类别分类方法进行分类。
特征提取部分采用了inception v3的网络结构,把每一张图片转成的像素矩阵作为数据传入到张量中做前向计算,从而得到高维特征。把我们手头少量的杰尼龟图片的特征一次全部提取,把切割得到的图片分批次提取特征。
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
tensor=sess.graph.get_tensor_by_name('pool_3/_reshape:0')
for i in range(num_batches):
batch_img_data=img_datas[i*batch_size:(i+1)*batch_size]
batch_img_labels=img_labels[i*batch_size:(i+1)*batch_size]
feature_v=[]
for j in batch_img_data:
j_vector=sess.run(tensor,feed_dict={'DecodeJpeg/contents:0':j})
feature_v.append(j_vector)
feature_v=np.vstack(feature_v)
save_path=os.path.join(folder,'data_%d.pickle'%i)
with tf.gfile.FastGFile(save_path,'w') as f:
pickle.dump((feature_v,batch_img_labels),f)
print(save_path,'is_ok!')OneClass SVM
把这些杰尼龟图片的特征当作训练集来训练这个OneClass SVM模型,勾勒出一个包含杰尼龟特征的超平面,接着对切割得到的图片特征进行检测,如果包含在超平面内,则得到结果1,反之得结果-1。得到结果之后,将正例的所有图片复制移动到新的文件夹,而该文件夹里面的图片便是我们的目标图片。
def one_class_svm():
model=svm.OneClassSVM()
feature_matrix,_=get_matrix('data_jieni',50)
model.fit(feature_matrix)
vedieo_feature_matrix,origin_labels=get_matrix('data_vedio',500)
result=model.predict(vedieo_feature_matrix)
for i in range(len(origin_labels)):
if result[i]==1:
move(src='vedio',dst='result',i=origin_labels[i])筛选完成后,我们会得到这个新的result文件夹包含机器学习所筛选出来的杰尼龟图片,但实际上效果不是特别理想,仍有不少并不是杰尼龟的图片成为漏网之鱼,也被放入到这个文件夹之中,我们可以考虑对正样本集进行一些处理,进行随机切割,图片反转,旋转等方式来扩充训练集。

至此,我们已经通过机器学习的方法对切割得到的图片集进行了一个筛选并获得了大量杰尼龟的图片,最后一弹我们就来聊聊如何操作这些图片。
