

spark的基本概念
spark是围绕resilient distributed dataset(rdd)来解决问题的,其中rdd是可分布式计算的。
rdd支持两种操作
-
transformations从已有的数据集创建一个新的数据集,例如
map -
actions对数据集进行操作,并返回一个值,例如
reduce
Spark中的一些操作可以触发shuffle事件。shuffle是Spark中的一种重新分发数据的机制,从而不同的partitions的数据可以重新分组。
处理数据的流程
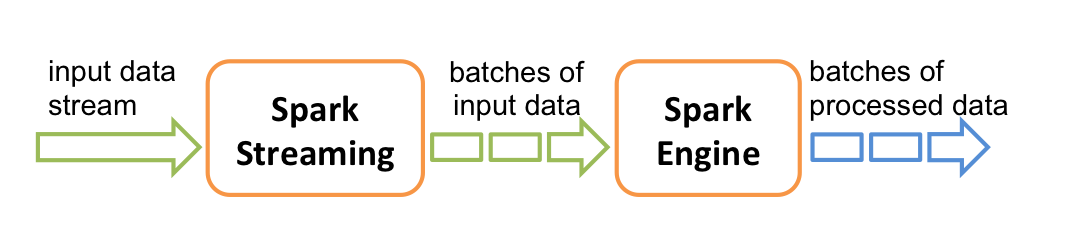
Spark处理数据的流程如上,接受数据并把这些数据切分为batches,然后Spark Engine就会把这些batches处理并产生batches的结果
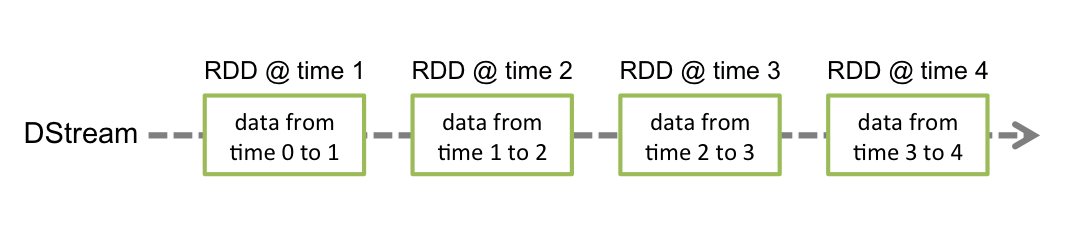
Spark Streaming会对数据提供了高等级的抽象,称数据为discretized stream或者DStream,表示一段数据流的数据。在内部而言,就是一段连续的RDDs。DStream中的每个RDD中包含的数据都是来自一个特定的间隔,如下图所示。任何对DStream的操作,都会转化为对其包含的RDDs的操作。
关于StreamingContext
- 一旦context启动,数据处理的过程就不能修改
- 一旦context停止,就不能重新启动
- 在一个jvm中,只能有一个context
窗口函数
Spark Streaming支持窗口函数,这样就可以进行滑动窗口的操作了
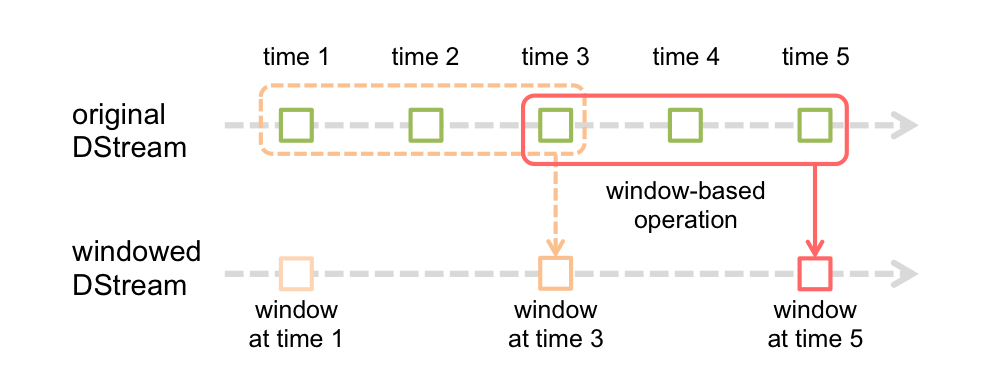
主要涉及两个参数:
- window length—窗口的长度
- sliding interval—操作执行的时间间隔
需要注意的是上述两个长度必须是context初始化的时候设置的batch interval的倍数。context初始化代码可以如下:
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
ctx = SparkContext()
streaming_ctx = StreamingContext(ctx, 1)
其中设置的batch interval是1,表示的是每一秒的数据,转化为一个batch。
实践
spark streaming 消费kafka发送的数据,并统计频次
conf = SparkConf()
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
conf.set('spark.streaming.kafka.maxRatePerPartition', 10000)
conf.set('spark.driver.extraJavaOptions', "-Xss30M")
ctx = SparkContext(appName="PythonStreamingIDCount", conf=conf)
ctx.setLogLevel('FATAL')
ctx.setCheckpointDir('./checkpoint')
streaming_ctx = StreamingContext(ctx, 1) # s
broker, topic = "127.0.0.1:9092", ["new-spark"]
kvs = KafkaUtils.createDirectStream(streaming_ctx, topic, {"metadata.broker.list": broker})
lines = kvs.map(lambda items: items[1])
counts = lines.\
map(lambda ip: (ip, 1)).\
reduceByKeyAndWindow(lambda a, b: a + b, lambda a, b: a - b, 10, 1)
counts.pprint(10)
streaming_ctx.start()
streaming_ctx.awaitTermination()
此处使用的是Direct Approach的方式(还有另外一种方式Receiver-based Approach),限制灌进来的数据的速度参数是
spark.streaming.kafka.maxRatePerPartition,而使用Receiver-based Approach限制灌进来的数据的参数是spark.streaming.receiver.maxRate。同样是限制消费速率的方法,而两种方式参数是不一样的,如果搞错了会发现参数完全没屁用。
提交代码的语句如下
spark-submit --jars ~/Downloads/spark-streaming-kafka-0-8-assembly_2.11-2.4.4.jar main.py --conf "spark.executor.extraJavaOptions=-XX:+UseConcMarkSweepGC"
需要注意的是jar包是需要自己下载的,这个可以直接在maven上下载下来。
