

AST 训练营
- 什么是AST
- 应用场景
- 解析原理
- 实战
什么是AST
AST 全称 abstract syntax tree(抽象语法树),把文本代码解析成机器可识别的数据结构
顾名思义,AST是一种类似树型的结构,其中每个节点表示一种独立的语法含义。
比如: 下面这段代码
let path = './src/index.js'
function outputFn (content) {
console.log(content)
}
outputFn(path)
转成ast之后
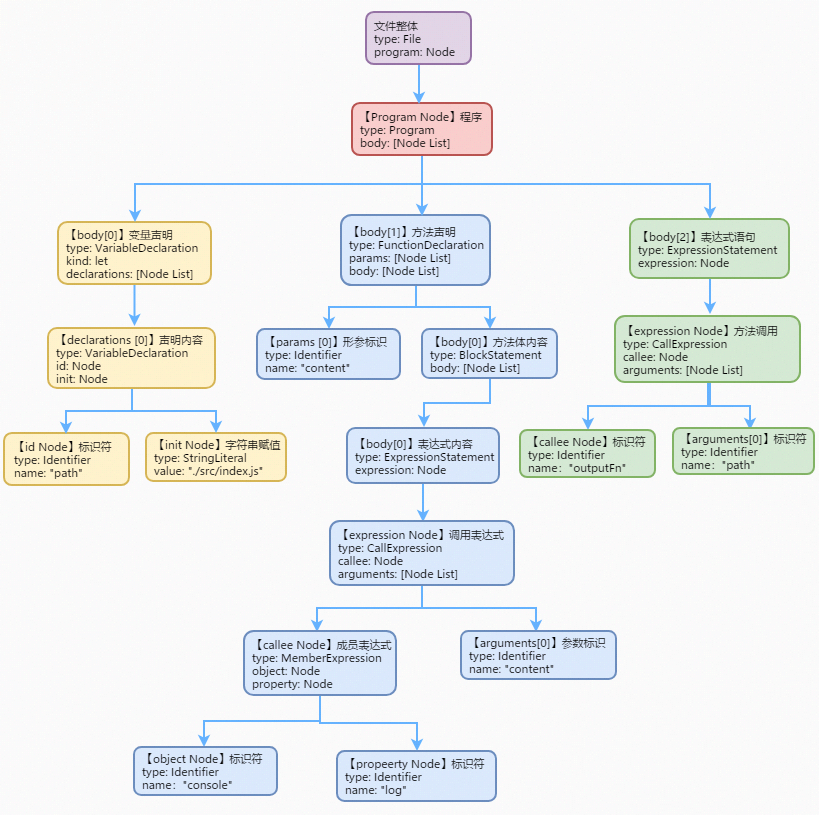
调试ast可以借助astexplorer
代码中的3部分内容语句分别被转换成了3棵子树
- 紫色部分:指文件内容了(额外添加的节点)
- 红色部分:程序内容(额外添加的节点)
- 黄色部分:变量声明
- 蓝色部分:方法声明
- 绿色部分:方法调用
应用场景
- babel编译es6+语法转换为es5
- IDE代码高亮、格式化、错误提示等等
- eslint校验
- 代码压缩
- js反编译
- ...
解析过程
解析大致包含两个步骤
- 词法分析
- 语法分析
1.1 词法分析
词法分析是计算机科学中将字符序列转换为单词(Token)序列的过程
进行词法分析的程序或者函数叫作词法分析器(Lexical analyzer,简称Lexer),也叫扫描器(Scanner)
要专门处理下面内容:
- 空白符
- 换行符
- 注释
- 词
- 标识符名称:变量名、关键字、保留字
- 符号:运算符、括号等
- 数字
- 字符串
- 正则
- 字符串模板
这部分处理后,会把代码转换成token(词法令牌)
const a = 1
转换后:
[ Token {
type:
TokenType {
label: 'const',
keyword: 'const',
beforeExpr: false,
startsExpr: false,
rightAssociative: false,
isLoop: false,
isAssign: false,
prefix: false,
postfix: false,
binop: null,
updateContext: null },
value: 'const',
start: 0,
end: 5,
loc: SourceLocation { start: [Object], end: [Object] } },
Token {
type: {...},
value: 'a',
start: 6,
end: 7,
loc: SourceLocation { start: [Object], end: [Object] } },
Token {
type:{...},
value: '=',
start: 8,
end: 9,
loc: SourceLocation { start: [Object], end: [Object] } },
Token {
type:{...},
value: 1,
start: 10,
end: 11,
loc: SourceLocation { start: [Object], end: [Object] } },
Token {
type:
TokenType {
label: 'eof',
keyword: undefined,
beforeExpr: false,
startsExpr: false,
rightAssociative: false,
isLoop: false,
isAssign: false,
prefix: false,
postfix: false,
binop: null,
updateContext: null },
value: undefined,
start: 11,
end: 11,
loc: SourceLocation { start: [Object], end: [Object] } } ]
1.2 语法分析
语法分析是编译过程的一个逻辑阶段
处理这部分的逻辑也叫解析器(parser)
语法分析的任务是在词法分析的基础上将单词序列组合成各类语法短语,如“程序”,“语句”,“表达式”等等。
语法分析程序判断源程序在结构上是否正确
经过语法分析后,就生成了上面提到的AST语法树
1.3 ast node结构
Node {
type: 'ClassProperty',
start: 427,
end: 663,
loc:
SourceLocation {
start: Position { line: 27, column: 2 },
end: Position { line: 35, column: 4 } },
static: false,
key:
Node {
type: 'Identifier',
start: 427,
end: 433,
loc: SourceLocation { start: [Object], end: [Object], identifierName: 'events' },
name: 'events' },
computed: false,
value:
Node {
type: 'ObjectExpression',
start: 436,
end: 662,
loc: SourceLocation { start: [Object], end: [Object] },
properties: [ [Object], [Object] ]
}
}
ast node通常由几部分构成:
- type: 节点类型,这里我打印的是“类属性节点”,所以是ClassProperty
- start: 代码起始位置
- end:代码结束位置
- loc:代码行列坐标
- 其他属性:这个就根据不同节点会有不同属性了
- key,在作为属性名称时才会有
- value,也同样,通常和key配对使用
- 再比如,type为FunctionDeclaration时,会有params和body字段等
全部type类型请查看官方文档
实战
wepy js代码转换为vue js代码(小程序转换工具部分逻辑)
首先我们先认识一下常用的包(用babel包)
- @babel/parser 将js代码解析成ast语法树
- @babel/generator 将ast语法树转换成js代码
- @babel/traverse 遍历语法树(深度优先)
- @babel/types 用来判断astNode类型的包
- prettier 用来美化(格式化)代码
看一下要转换的wepy代码
import wepy from 'wepy';
import Banners from '@/components/Banners'; //banner切换调度配置
let bannerChangeDispatch = {
ev: null,
//最近一次切换事件
pause: false //是否暂停处理
};
export default class extends wepy.component {
components = {
Banners
};
data = {
banners: [],
config: {
current: 0,
//当前所在图片的 index
indicatorDots: false
},
style: '',
itemStyle: '',
current: 0
};
events = {
pageShow() {
bannerChangeDispatch.pause = false;
bannerChangeDispatch.ev && this.handleBannerChange(bannerChangeDispatch.ev);
},
pageHide() {
bannerChangeDispatch.pause = true;
}
};
methods = {
onBannerChange(ev) {
this.handleBannerChange(ev);
}
};
/**
* @public
* @param data
*/
init(data) {
this.banners = data.banners;
this.$apply();
}
handleBannerChange(ev) {
if (bannerChangeDispatch.pause) {
//处于后台时只记录最新状态,不进行变换处理,避免:iOS-切到后台-一段时间后回来-背景连续快速频繁变换
bannerChangeDispatch.ev = ev;
return;
}
this.current = ev.detail.current;
this.$apply();
this.$emit('change', ev);
}
}
转换分析
- 要把wepy相关的内容去掉,如:
- import wepy from 'wepy'
- this.$apply()
- wepy.component
- 类写法改为对象写法
- 非生命周期的方法放到methods中
- events中的方法也要放到methods中
- data改为方法形式,返回定义的数据对象
- 组件中的onLoad方法更名为created(因为:wepy组件中的onLoad和page上的onLoad同时触发,而uniapp组件中对应的同意义钩子为created)
为了上手容易,示例中我们没有加入过多的特殊逻辑
转换思路
- 正则替换掉wepy相关的已知内容(如:import wepy from 'wepy')
- 将类外部的内容抽出(如:import部分或者类外面定义的逻辑)
- 将类内部的内容分别抽出(如:data部分、methods部分等)
- 将类内部抽出的内容进行处理(如:events中的内容合并到methods中)
- 将抽出内容与vue模板拼接
开始转换
1. js内容抽取
我们可以通过node的fs模块,读取文件内容并抽离出script部分内容。
读取和js抽离逻辑因为不是本文重点,这里一笔带过。
最终我们获取的js内容赋值到【jsContent】 的变量中
2. 确定的内容可以优先考虑用正则处理
const beforeParse = function (code) {
return code
.replace(/_*this\.\$apply\(\);?/gm, '')
.replace(/import\s+wepy\s+from\s+['"]wepy['"];?/gm, '')
}
jsContent = beforeParse(jsContent)
这里的作用是清除掉下面内容:
import wepy from 'wepy';
this.$apply();
那wepy.component为什么不通过正则去掉呢?
前面提到了,因为我们会重新拼接vue模板,所以这里即使替换后面也用不到
3. js内容分块抽离(敲黑板)
这部分内容才是本文的重点
3.1 首先通过@babel/parser模块,将js转换成ast语法树
const parse = require('@babel/parser').parse
// 将jscontent转换为ast语法
let ast = parse(jsContent, {
sourceType: 'module',
plugins: [
'jsx',
'asyncGenerators',
'decorators-legacy',
'exportDefaultFrom',
'exportNamespaceFrom',
'objectRestSpread',
'classProperties'
],
})
对于@babel/parser的详细配置,请查看《babel-parser文档》
这步解析后的ast语法树结构,就是上文提到的那张“树状”图了
3.2 抽离js的各部分内容
这里我们将文件看成几部分内容
- 类外部的代码,即下面部分的代码
import Banners from '@/components/Banners' //banner切换调度配置
//banner切换调度配置
let bannerChangeDispatch = {
ev: null,
//最近一次切换事件
pause: false, //是否暂停处理
}
-
类内部的代码
- 类属性(以 xx = {...} 形式定义的)
- components
- data(需要变更为方法,return数据对象)
- events(需要和methods合并)
- methods
- 类方法(以 xxx() {...} 形式定义的
- init(需要放到methods中)
- handleBannerChange(需要放到methods中)
- onLoad(生命周期,需要更名为created)
- 类属性(以 xx = {...} 形式定义的)
OK,我们开始进行抽离
首先定义缓存对象,用来保存抽离后的内容
// 当前文件数据缓存对象
let contentCache = {
outsideStr: '', // 外部内容字符串
components: null, // components ast节点value
data: null, // data ast节点value
methods: null, // methods ast节点
lifeCycle: [] // 生命周期节点数组 ast节点
}
下面开始解析ast,按照上面划分,逐部分抽离
const traverse = require('@babel/traverse').default
const babelGenerate = require('@babel/generator').default
const t = require('@babel/types')
// 遍历ast语法树
traverse(ast, {
enter (astPath) {
// 外层import部分语句
if (t.isImportDeclaration(astPath)) {
...
// 外层变量处理
} else if (t.isVariableDeclaration(astPath)) {
...
// 判断如果是类属性
} else if (t.isClassProperty(astPath)) {
...
// 判断如果是类方法
} else if (t.isClassMethod(astPath)) {
...
}
}
})
注:traverse会遍历语法树的每一个节点,深度优先遍历。
抽离外部【import】内容,直接转换成【字符串】存起来
// 处理import部分语句
if (t.isImportDeclaration(astPath)) {
contentCache.outsideStr += `${babelGenerate(astPath.node).code}\r\n`
}
抽离外部【变量声明】内容,直接转换成【字符串】存起来
// 变量处理(外层)
if (t.isVariableDeclaration(astPath)) {
// 获取上层节点
const parent = astPath.parentPath.parent
// 如果是文件,则表明已经最外层的变量声明
if (t.isFile(parent)) {
// 拼接到缓存变量中
contentCache.outsideStr += `${babelGenerate(astPath.node).code}\r\n`
}
}
注:为什么import可以直接转成字符串缓存,而变量却要做个判断?
因为一般使用import都是在最外层,而变量声明在任何地方存在,所以这里要明确限定是class外部的变量声明。所以通过确认父节点来判断是否为最外层。
如果类外部又包含其他表达式逻辑呢?
可以继续完善类型判断,加入isExpressionStatement(astPath)场景的处理
这样,类外部的内容就提取完成了~
抽离【类属性】,根据类型和场景缓存对应的【节点内容】
// 判断如果是类属性
if (t.isClassProperty(astPath)) {
//根据不同类属性进行不同处理,把wepy的类属性写法提取出来,放到VUE模板中
const key = astPath.node.key.name
switch (key) {
case 'components':
case 'data':
contentCache[key] = astPath.node.value
break
case 'events':
case 'methods':
if (!contentCache.methods) {
contentCache.methods = astPath.node.value
} else {
contentCache.methods.properties = contentCache.methods.properties
.concat(astPath.node.value.properties)
}
break
}
}
这里有疑问的可能是events和methods的处理
contentCache.methods.properties = contentCache.methods.properties
.concat(astPath.node.value.properties)
这句是将events和methods合并的核心语句
astPath.node.value.properties指的是指该节点的所有子节点,将events和methods所有的子节点放到同一个数组,达到合并的目的。
抽离【类方法】,缓存对应的【节点】
因为生命周期需要单独处理,所以要把生命周期方法枚举
// 生命周期方法枚举对象
const lifeCycleFunction = {
onLoad: true,
onShow: true,
onHide: true,
...
}
// 判断如果是类方法
if (t.isClassMethod(astPath)) {
// 获取方法名
let key = astPath.node.key.name
// 如果是生命周期相关的方法
if (lifeCycleFunction[key]) {
// 提取生命周期的方法
contentCache.lifeCycle.push(astPath.node)
} else {
// 如果不存在methods节点,创建一个
if (!contentCache.methods) {
// 创建一个对象节点
contentCache.methods = t.objectExpression([])
}
// 提取非生命周期的方法,合并到methods中
contentCache.methods.properties.push(astPath.node)
}
}
这部分两个核心逻辑:
- 将生命周期的方法节点放到一起
- 将类方法中,非生命周期的方法放到methods的节点中。
至此,所有抽离工作就完成了。
4. 将抽离后的内容加工,并生成js代码
// vue内容转换
let newJsContent = cacheToVueString(contentCache)
cacheToVueString方法实现:
const cacheToVueString = function (cache) {
let rst = ''
// class外部的内容
rst += cache.outsideStr
// 获取到内容后删除
delete cache.outsideStr
rst += `export default {`
// 遍历class内部的内容
for (let i in cache) {
if (parseService[i]) {
// 将对应内容转换为ast
rst += parseService[i](cache[i])
}
}
rst += `}`
return rst
}
cacheToVueString方法其实就是一个模板的动态拼接。
每一部分的生成逻辑由parseService完成:
const parseService = {
// data处理
data (ast) {
let dataStr = `${babelGenerate(ast).code}\r\n`
let rst = `
data () {
return ${dataStr}
},
`
return rst
},
// components处理
components (ast) {
return `components: ${babelGenerate(ast).code},\r\n`
},
// 生命周期处理
lifeCycle (astList) {
let rst = ''
astList.forEach(item => {
if (item.key.name === 'onLoad') {
item.key.name = 'created'
}
rst += `${babelGenerate(item).code},\r\n`
})
return rst
},
// 方法处理
methods (ast) {
let rst = `methods: ${babelGenerate(ast).code},\r\n`
return rst
}
}
整个转换逻辑就完成了
5. 将最终代码通过prettier格式化
const prettier = require('prettier')
// 格式化
newJsContent = prettier.format(newJsContent, {
parser: 'babel',
// 去除分号
semi: false,
// 单引号
singleQuote: true
})
最终转换后的代码如下
import Banners from '@/components/Banners' //banner切换调度配置
//banner切换调度配置
let bannerChangeDispatch = {
ev: null,
//最近一次切换事件
pause: false, //是否暂停处理
}
export default {
components: {
Banners,
},
data() {
return {
banners: [],
config: {
current: 0,
//当前所在图片的 index
indicatorDots: false,
},
style: '',
itemStyle: '',
current: 0,
}
},
methods: {
pageShow() {
bannerChangeDispatch.pause = false
bannerChangeDispatch.ev &&
this.handleBannerChange(bannerChangeDispatch.ev)
},
pageHide() {
bannerChangeDispatch.pause = true
},
onBannerChange(ev) {
this.handleBannerChange(ev)
},
/**
* @public
* @param data
*/
init(data) {
this.banners = data.banners
},
handleBannerChange(ev) {
if (bannerChangeDispatch.pause) {
//处于后台时只记录最新状态,不进行变换处理,避免:iOS-切到后台-一段时间后回来-背景连续快速频繁变换
bannerChangeDispatch.ev = ev
return
}
this.current = ev.detail.current
this.$emit('change', ev)
},
},
created() {
console.log('created life cycle')
},
}
结语与背景
上述代码,由转换工具部分逻辑改编而来,目的是希望大家上手更容易一些。
其实要实现一个转换工具要比这复杂的多的多的多。
转换工具背景
由于工作需要,我们要完成wepy向uniapp的转换,但公司内部小程序非常多,一个个手动转换显然不现实。于是我们就希望能有一个wepy转uniapp的工具,而官网正好提供了wepy转uni-app转换器
但我们更希望可以转换成ts版本的,毕竟ts是大趋势。于是我们对官方的转换工具进行了改造,重写了js部分的生成逻辑,同时抹平了很多两个框架间的差异。
最终可以生成typescript版的代码(当然有部分内容仍需手动处理,工具可以完成98%+的工作)。
成果:
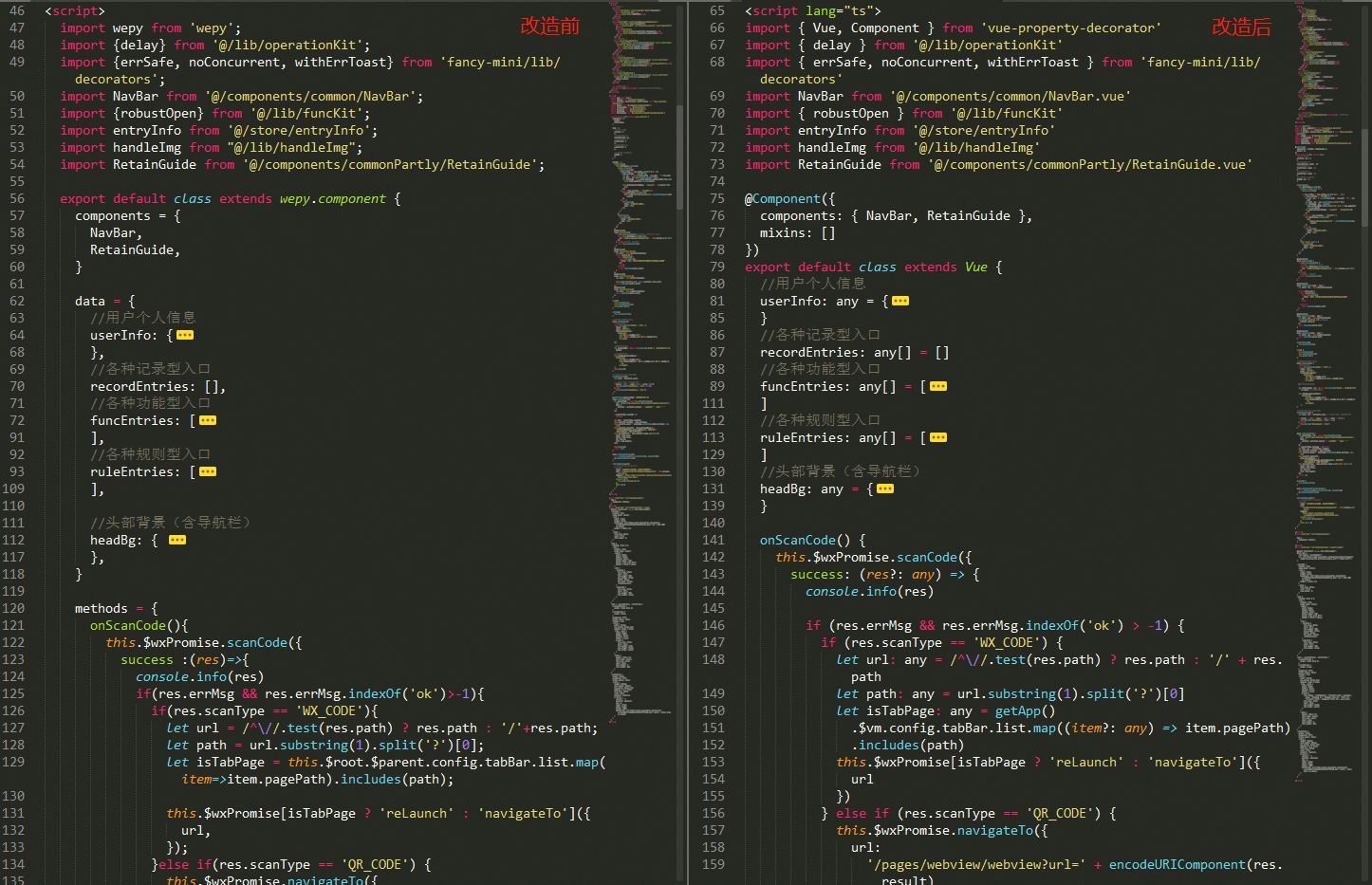
后面如果有机会,可能还会分享一些转typescript的练习
