

- 论文题目:Model-Based Reinforcement Learning via Meta-Policy Optimization

所解决的问题?
提出一种不依赖于learned dynamic model精度的学习算法Model-Based Meta-Policy-Optimization (MB-MPO),。同样是使用emsemble的方法集成learned model,然后用meta-train的方法学一个policy,使得其能够对任意一个model都具有较好的学习效果。最终使得算法的鲁棒性更强。
背景
之前的大多数model-based方法都集中在trajectory sample和dynamic model train这两个步骤。如用贝叶神经网络的这些方法。贝叶斯的方法一般用于低维空间,神经网络虽然具备用于高维空间的潜力,但是很大程度会依赖模型预测的精度才能取得较好效果。
也有前人工作是解决model学习不准确的问题,与本文最相似的就是EM-TRPO算法,而本文采用的是元学习算法,指在模型不精确的情况下加强其鲁棒性。
所采用的方法?
Model Learning
在学习model的时候,作者学习的是状态的改变量。用的是one-step预测:
为了防止过拟合,作者采用以下三点:
- early stopping the training based on the validation loss;
- normalizing the inputs and outputs of the neural network;
- weight normalization
- T.Salimans and D.P.Kingma. Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks. In NIPS, 2 2016.
Meta-Reinforcement Learningon Learned Models
Each task constitutes a different belief about what the dynamics in the true environment could be. 优化目标为:
其中表示是在策略
和估计的动态模型
下的期望回报。

这里是直接学习如何调整,而不是从学好的模型的数据中学习policy,这也是与ME-TRPO的区别。
取得的效果?
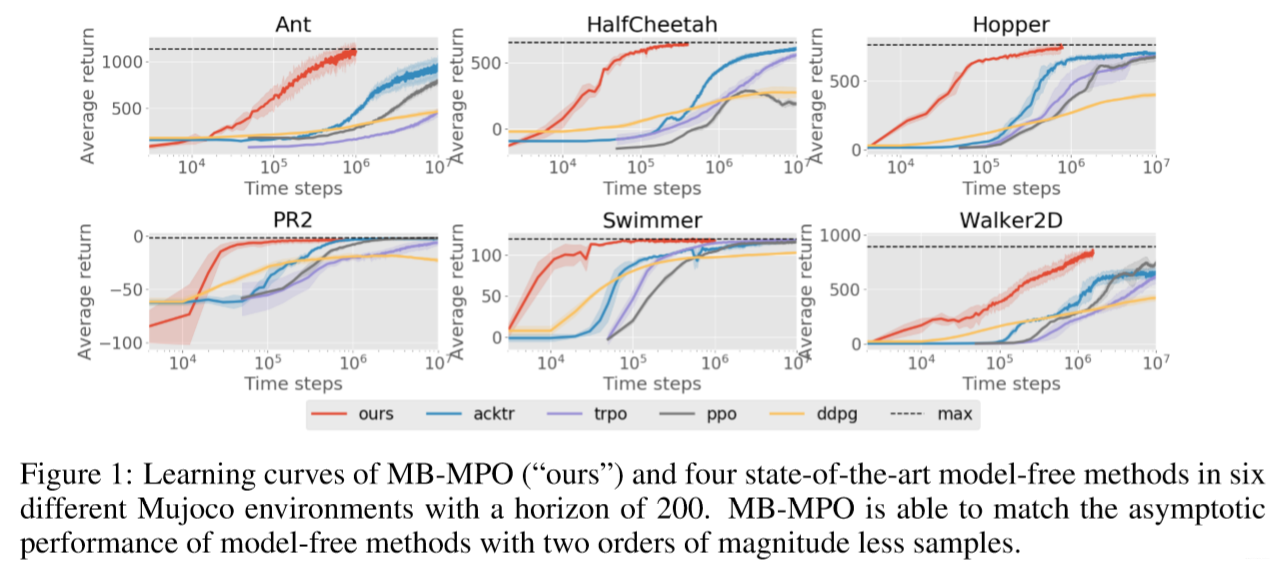
与model-free算法对比:
与model-based算法对比:
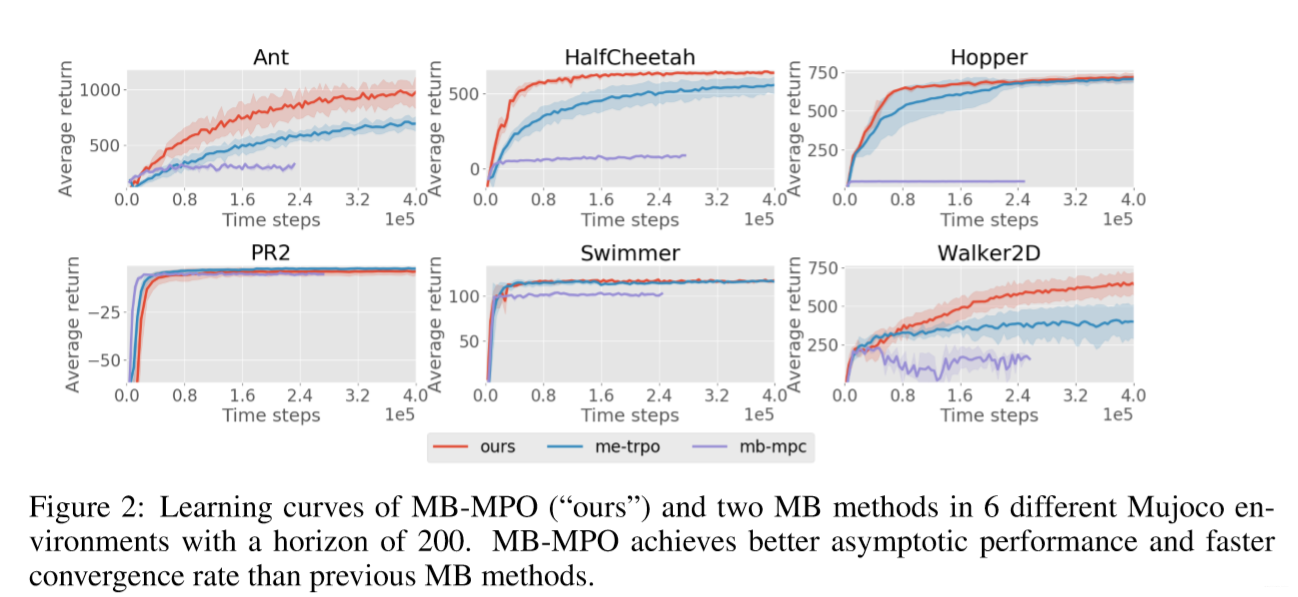
作者还做了一些实验与MR-TRPO算法对比,感兴趣可以参考原文。
所出版信息?作者信息?
Ignasi Clavera 加州大学伯克利分校 CS的三年级博士生,导师伯克利人工智能研究(BAIR)实验室的Pieter Abbeel。研究方向是机器学习与控制的交集,旨在使机器人系统能够学习如何有效地执行复杂的任务。

