

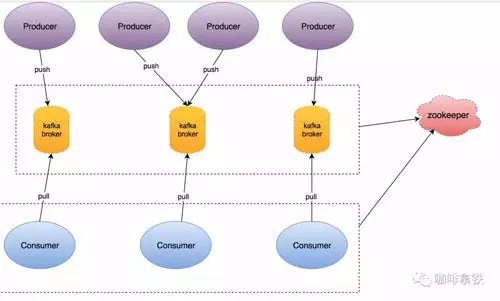
kafka特性
kafka是一个 分布式的、支持分区的(partition)、多副本的(replica),基于zookeeper协调的 分布式消息系统。
从上面的描述中我们可以知道kafka的核心知识点:partition、replica
Topic和Partition
一个topic可以认为一个一类消息,每个topic将被分成多个partition。
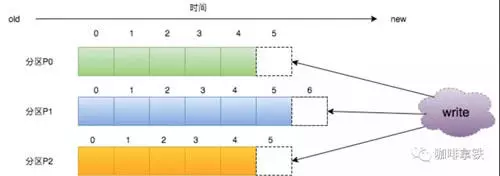
在上图中我们的生产者会决定发送到哪个 Partition:
如果没有 Key 值则进行轮询发送。
如果有 Key 值,对 Key 值进行 Hash,然后对分区数量取余,保证了同一个 Key 值的会被路由到同一个分区。(所有系统的partition都是同一个路数)
在上图我们也可以看到,offset是跟partition走的,每个partition都有自己的offset。
Kafka文件存储机制
总所周知,topic在物理层面以partition为分组,一个topic可以分成若干个partition,那么topic以及partition又是怎么存储的呢?
其实partition还可以细分为logSegment,一个partition物理上由多个logSegment组成,那么这些segment又是什么呢?
LogSegment 文件由两部分组成,分别为“.index”文件和“.log”文件,分别表示为 Segment 索引文件和数据文件。
这两个文件的命令规则为:partition全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值,数值大小为64位,20位数字字符长度,没有数字用0填充,如下:
第一个segment
00000000000000000000.index
00000000000000000000.log
第二个segment,文件命名以第一个segment的最后一条消息的offset组成
00000000000000170410.index
00000000000000170410.log
第三个segment,文件命名以上一个segment的最后一条消息的offset组成
00000000000000239430.index
00000000000000239430.log 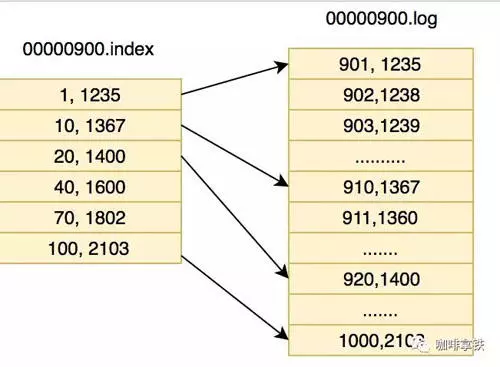
如上图,“.index”索引文件存储大量的元数据,“.log”数据文件存储大量的消息,索引文件中的元数据指向对应数据文件中message的物理偏移地址。其中以“.index”索引文件中的元数据[3, 348]为例,在“.log”数据文件表示第3个消息,即在全局partition中表示170410+3=170413个消息,该消息的物理偏移地址为348。
那么如何从partition中通过offset查找message呢?
以上图为例,读取offset=170418的消息,首先查找segment文件,其中00000000000000000000.index为最开始的文件,第二个文件为00000000000000170410.index(起始偏移为170410+1=170411),而第三个文件为00000000000000239430.index(起始偏移为239430+1=239431),所以这个offset=170418就落到了第二个文件之中。其他后续文件可以依次类推,以其实偏移量命名并排列这些文件,然后根据二分查找法就可以快速定位到具体文件位置。其次根据00000000000000170410.index文件中的[8,1325]定位到00000000000000170410.log文件中的1325的位置进行读取。
要是读取offset=170418的消息,从00000000000000170410.log文件中的1325的位置进行读取,那么怎么知道何时读完本条消息,否则就读到下一条消息的内容了?
这个就需要联系到消息的物理结构了,消息都具有固定的物理结构,包括:offset(8 Bytes)、消息体的大小(4 Bytes)、crc32(4 Bytes)、magic(1 Byte)、attributes(1 Byte)、key length(4 Bytes)、key(K Bytes)、payload(N Bytes)等等字段,可以确定一条消息的大小,即读取到哪里截止。
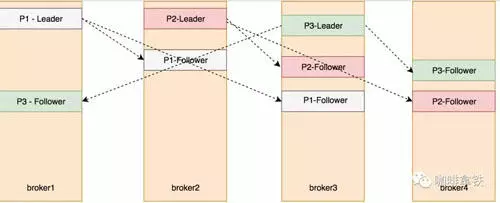
副本机制
Kafka 的副本机制是多个服务端节点对其他节点的主题分区的日志进行复制。当集群中的某个节点出现故障,访问故障节点的请求会被转移到其他正常节点(这一过程通常叫 Reblance)。
Kafka 每个主题的每个分区都有一个主副本以及 0 个或者多个副本,副本保持和主副本的数据同步,当主副本出故障时就会被替代。
数据可靠性和持久性保证(对数据一致性的要求)
当producer向leader发送数据时,可以通过request.required.acks参数来设置数据可靠性的级别:
- 1(默认):这意味着producer在ISR中的leader已成功收到的数据并得到确认后发送下一条message。如果leader宕机了,则会丢失数据。
- 0:这意味着producer无需等待来自broker的确认而继续发送下一批消息。这种情况下数据传输效率最高,但是数据可靠性确是最低的。
- -1:producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高。
kafka选举
在kafka系统中,会涉及到多处选举机制,主要有这三方面:
- 控制器(Broker)选主
- 分区多副本选主
- 消费组选主
本文由博客群发一文多发等运营工具平台 OpenWrite 发布
