

@[TOC]
1. IOS面试考察(九):性能优化相关问题
1.1 启动优化
1.1.1 启动时间
APP的启动时间,直接影响用户对你的APP的第一体验和判断。如果启动时间过长,不单单体验直线下降,而且可能会激发苹果的watch dog机制kill掉你的APP,那就悲剧了,用户会觉得APP怎么一启动就卡死然后崩溃了,不能用,然后长按APP点击删除键。(Xcode在debug模式下是没有开启watch dog的,所以我们一定要连接真机测试我们的APP)
在衡量APP的启动时间之前我们先了解下,APP的启动流程:
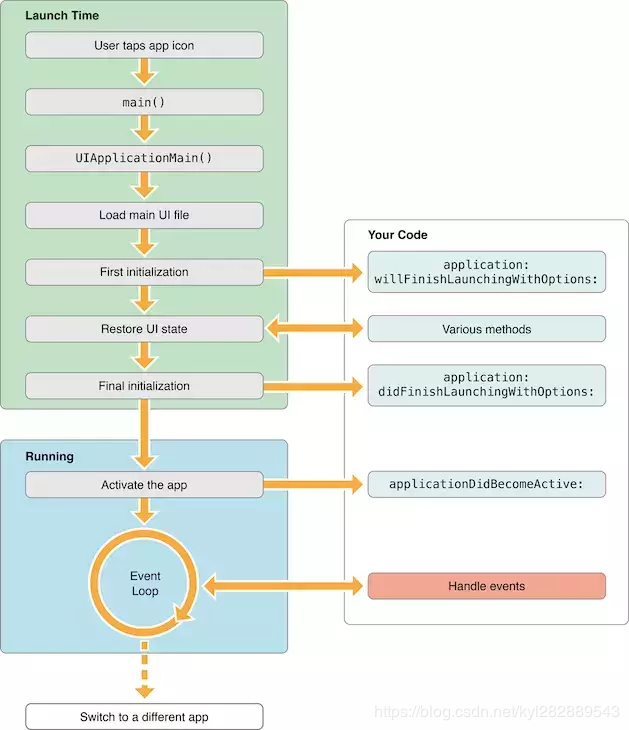
我们将 App 启动方式分为:
- 冷启动: App 启动时,应用进程不在系统中(初次打开或程序被杀死),需要系统分配新的进程来启动应用。
- 热启动: App 退回后台后,对应的进程还在系统中,启动则将应用返回前台展示。
1.1.2 APP启动过程
APP的启动可以分为两个阶段,即main()执行之前和main()执行之后。总结如下:
- t(App 总启动时间) = t1( main()之前的加载时间 ) + t2( main()之后的加载时间 )。
- t1 = 系统的
dylib(动态链接库)和 App 可执行文件的加载时间;- t2 =
main()函数执行之后到AppDelegate类中的applicationDidFinishLaunching:withOptions:方法执行结束前这段时间。
所以我们对APP启动时间的获取和优化都是从这两个阶段着手,下面先看看main()函数执行之前如何获取启动时间。
1.1.2.1 main()函数执行之前
衡量main()函数执行之前的耗时
对于衡量main()之前也就是time1的耗时,苹果官方提供了一种方法,即在真机调试的时候,勾选DYLD_PRINT_STATISTICS选项(如果想获取更详细的信息可以使用DYLD_PRINT_STATISTICS_DETAILS),如下图:
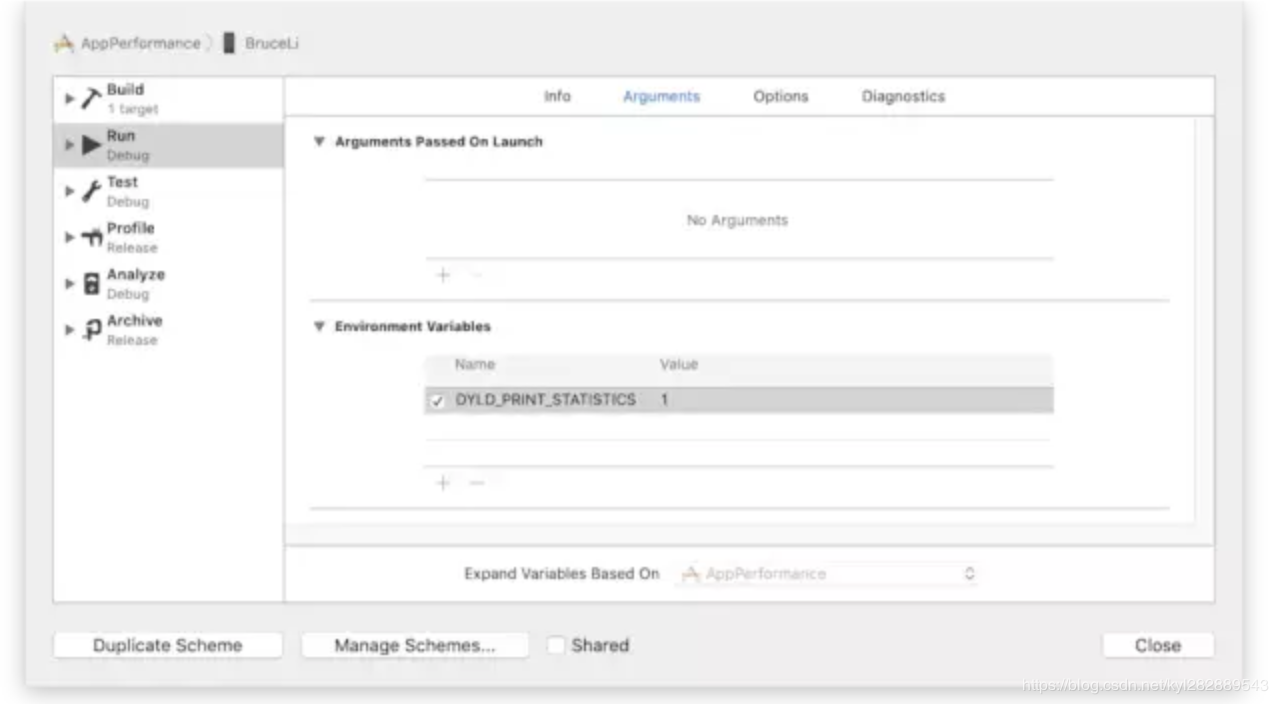
Total pre-main time: 34.22 milliseconds (100.0%)
dylib loading time: 14.43 milliseconds (42.1%)
rebase/binding time: 1.82 milliseconds (5.3%)
ObjC setup time: 3.89 milliseconds (11.3%)
initializer time: 13.99 milliseconds (40.9%)
slowest intializers :
libSystem.B.dylib : 2.20 milliseconds (6.4%)
libBacktraceRecording.dylib : 2.90 milliseconds (8.4%)
libMainThreadChecker.dylib : 6.55 milliseconds (19.1%)
libswiftCoreImage.dylib : 0.71 milliseconds (2.0%)
系统级别的动态链接库,因为苹果做了优化,所以耗时并不多,而大多数时候,t1的时间大部分会消耗在我们自身App中的代码上和链接第三方库上。
所以我们应如何减少main()调用之前的耗时呢,我们可以优化的点有:
- 合并动态库,减少不必要的
framework,特别是第三方的,因为动态链接比较耗时;- check
framework应设为optional和required,如果该framework在当前App支持的所有iOS系统版本都存在,那么就设为required,否则就设为optional,因为optional会有些额外的检查;- 合并或者删减一些
OC类,关于清理项目中没用到的类,可以借助AppCode代码检查工具:- 删减一些无用的静态变量
- 删减没有被调用到或者已经废弃的方法
- 将不必须在+load方法中做的事情延迟到+initialize中
- 尽量不要用C++虚函数(创建虚函数表有开销)
- 避免使用
attribute((constructor)),可将要实现的内容放在初始化方法中配合dispatch_once使用。- 减少非基本类型的 C++ 静态全局变量的个数。(因为这类全局变量通常是类或者结构体,如果在构造函数中有繁重的工作,就会拖慢启动速度)
我们可以从原理上分析main函数执行之前做了一些什么事情:
- 加载可执行文件: 加载
Mach-O格式文件,既 App 中所有类编译后生成的格式为.o的目标文件集合。 - 加载动态库 : dyld 加载 dylib 会完成如下步骤:
- 分析 App 依赖的所有
dylib。- 找到
dylib对应的Mach-O文件。- 打开、读取这些
Mach-O文件,并验证其有效性。- 在系统内核中注册代码签名
- 对
dylib的每一个segment调用mmap()。
系统依赖的动态库由于被优化过,可以较快的加载完成,而开发者引入的动态库需要耗时较久。
-
Rebase和Bind操作: 由于使用了
ASLR技术,在dylib加载过程中,需要计算指针偏移得到正确的资源地址。Rebase将镜像读入内存,修正镜像内部的指针,消耗IO性能;Bind查询符号表,进行外部镜像的绑定,需要大量CPU计算。 -
Objc setup : 进行 Objc 的初始化,包括注册 Objc 类、检测 selector 唯一性、插入分类方法等。
-
Initializers : 往应用的堆栈中写入内容,包括执行
+load方法、调用 C/C++ 中的构造器函数(用attribute((constructor))修饰的函数)、创建非基本类型的 C++ 静态全局变量等。
1.1.2.2 main()函数执行之后
衡量main()函数执行之后的耗时
第二阶段的耗时统计,我们认为是从main ()执行之后到applicationDidFinishLaunching:withOptions:方法最后,那么我们可以通过打点的方式进行统计。
Objective-C项目因为有main文件,所以我么直接可以通过添加代码获取:
// 1. 在 main.m 添加如下代码:
CFAbsoluteTime AppStartLaunchTime;
int main(int argc, char * argv[]) {
AppStartLaunchTime = CFAbsoluteTimeGetCurrent();
.....
}
// 2. 在 AppDelegate.m 的开头声明
extern CFAbsoluteTime AppStartLaunchTime;
// 3. 最后在AppDelegate.m 的 didFinishLaunchingWithOptions 中添加
dispatch_async(dispatch_get_main_queue(), ^{
NSLog(@"App启动时间--%f",(CFAbsoluteTimeGetCurrent()-AppStartLaunchTime));
});
Swift项目是没有main文件,但我们可以通过添加@UIApplicationMain标志的方式,帮我们添加了main函数了。所以如果是我们需要在main函数中做一些其它操作的话,需要我们自己来创建main.swift文件,这个也是苹果允许的。
我们可以删除AppDelegate类中的 @UIApplicationMain标志;
然后自行创建main.swift文件,并添加程序入口:
import UIKit
var appStartLaunchTime: CFAbsoluteTime = CFAbsoluteTimeGetCurrent()
UIApplicationMain(
CommandLine.argc,
UnsafeMutableRawPointer(CommandLine.unsafeArgv)
.bindMemory(
to: UnsafeMutablePointer<Int8>.self,
capacity: Int(CommandLine.argc)),
nil,
NSStringFromClass(AppDelegate.self)
)
然后在AppDelegate的didFinishLaunchingWithOptions :方法最后添加:
// APP启动时间耗时,从mian函数开始到didFinishLaunchingWithOptions方法结束
DispatchQueue.main.async {
print("APP启动时间耗时,从mian函数开始到didFinishLaunchingWithOptions方法:(CFAbsoluteTimeGetCurrent() - appStartLaunchTime)。")
}
总的说来,main函数之后的优化有以下方式:
- 尽量使用纯代码编写,减少xib的使用;
- 启动阶段的网络请求,是否都放到异步请求;
- 一些耗时的操作是否可以放到后面去执行,或异步执行等。
- 使用简单的广告页作为过渡,将首页的计算操作及网络请求放在广告页展示时异步进行。
- 涉及活动需变更页面展示时(例如双十一),提前下发数据缓存
- 首页控制器用纯代码方式来构建,而不是 xib/Storyboard,避免布局转换耗时。
- 避免在主线程进行大量的计算,将与首屏无关的计算内容放在页面展示后进行,缩短 CPU 计算时间。
- 避免使用大图片,减少视图数量及层级,减轻 GPU 的负担。
- 做好网络请求接口优化(DNS 策略等),只请求与首屏相关数据。
- 本地缓存首屏数据,待渲染完成后再去请求新数据。
1.1.3 APP启动优化
1.1.3.1 APP启动优化 -- 二进制重排
上面1.1.1和1.1.2将的App启动相关的优化,都是基于一些代码层面,设计方面尽量做到好的优化减少启动时间。我们还有一种重操作系统底层原理方面的优化,也是属于main函数执行之前阶段的优化。
学过操作系统原理,我们就会知道我们操作系统加载内存的时候有分页和分段两种方式,由于手机的实际内存的限制,一般操作系统给我们的内存都是虚拟内存,也就是说内存需要做映射。如分页存储的方式,如果我们App需要的内存很大,App一次只能加载有限的内存页数,不能一次性将App所有的内存全部加载到内存中。 如果在APP启动过程中发现开始加载的页面没有在内存中,会发生缺页中断,去从磁盘找到缺少的页,从新加入内存。而缺页中断是很耗时的,虽然是毫秒级别的,但是,如果连续发生了多次这样的中断,则用户会明显感觉到启动延迟的问题。
知道了这个原理,我们就需要从分页这个方面来解决。我们用二进制重排的思想就是要将我们APP启动所需要的相关类,在编译阶段都重新排列,排到最前面,尽量避免,减少缺页中断发生的次数,从而达到启动优化的目的。
下面我们来详细分析一下内存加载的原理
1.1.3.1.1 内存加载原理
在早期的计算机中 , 并没有虚拟内存的概念 , 任何应用被从磁盘中加载到运行内存中时 , 都是完整加载和按序排列的 . 但是这样直接使用物理内存会存在一些问题:
- 安全问题 : 由于在内存条中使用的都是真实物理地址 , 而且内存条中各个应用进程都是按顺序依次排列的 . 那么在 进程1 中通过地址偏移就可以访问到 其他进程 的内存 .
- 效率问题 : 随着软件的发展 , 一个软件运行时需要占用的内存越来越多 , 但往往用户并不会用到这个应用的所有功能 , 造成很大的内存浪费 , 而后面打开的进程往往需要排队等待 .
为了解决上面物理内存存在的问题,引入了虚拟内存的概念。引用了虚拟内存后 , 在我们进程中认为自己有一大片连续的内存空间实际上是虚拟的 , 也就是说从 0x000000 ~ 0xffffff 我们是都可以访问的 . 但是实际上这个内存地址只是一个虚拟地址 , 而这个虚拟地址通过一张映射表映射后才可以获取到真实的物理地址 .
整个虚拟内存的工作原理这里用一张图来展示 :
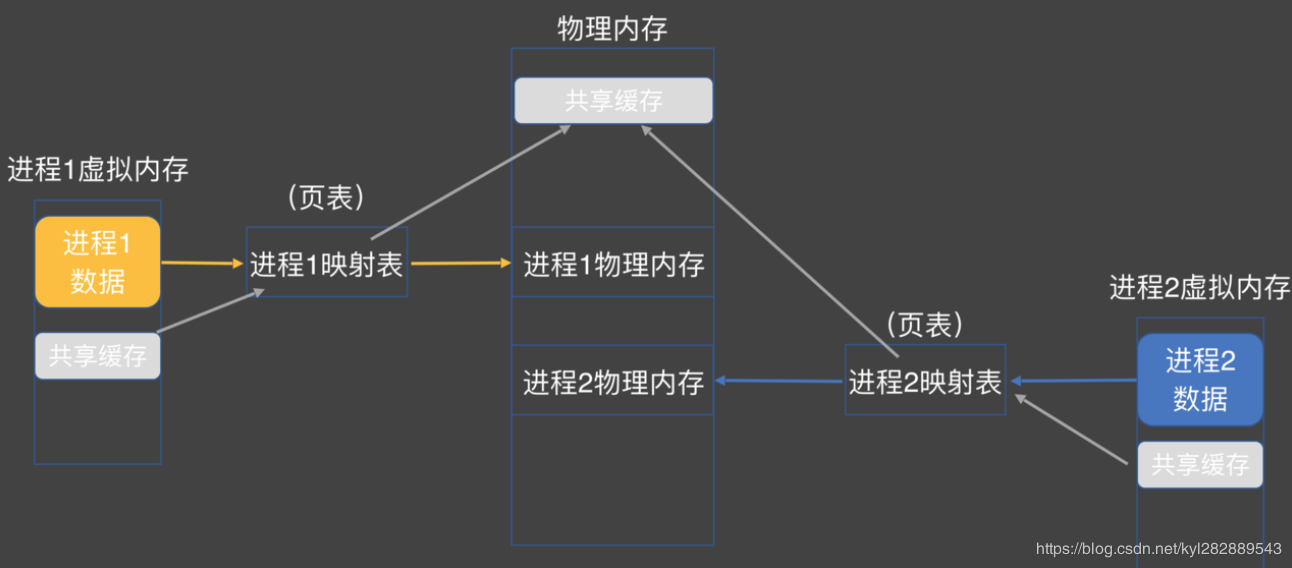
引用虚拟内存后就不存在通过偏移可以访问到其他进程的地址空间的问题了 。因为每个进程的映射表是单独的 , 在你的进程中随便你怎么访问 , 这些地址都是受映射表限制的 , 其真实物理地址永远在规定范围内 , 也就不存在通过偏移获取到其他进程的内存空间的问题了 .
引入虚拟内存后 , cpu 在通过虚拟内存地址访问数据需要通过映射来找到真实的物理地址。过程如下:
- 通过虚拟内存地址 , 找到对应进程的映射表 .
- 通过映射表找到其对应的真实物理地址 , 进而找到数据 .
学过操作系统,我们知道cpu内存寻址有两种方式:分页和分段两种方式。
虚拟内存和物理内存通过映射表进行映射 , 但是这个映射并不可能是一一对应的 , 那样就太过浪费内存了 ,我们知道物理内存实际就是一段连续的空间,如果全部分配给一个应用程序使用,这样会导致其他应用得不到响应. 为了解决效率问题 , 操作系统为了高效使用内存采用了分页和分段两种方式来管理内存。
对于我们这种多用户多进程的大部分都是采用分页的方式,操作系统将内存一段连续的内存分成很多页,每一页的大小都相同,如在 linux 系统中 , 一页内存大小为 4KB , 在不同平台可能各有不同 . Mac OS 系统内核也是基于linux的, 因此也是一页为 4KB。但是在iOS 系统中 , 一页为 16KB 。
内存被分成很多页后,就像我们的一本很厚的书本,有很多页,但是这么多页,如果没有目录,我们很难找到我们真正需要的那一页。而操作系统采用一个高速缓存来存放需要提前加载的页数。由于CPU的时间片很宝贵,CPU要负责做很多重要的事情,而直接从磁盘读取数据到内存的IO操作非常耗时,为了提高效率,采用了高速缓存模式,就是先将一部分需要的分页加载到高速缓存中,CPU需要读取的时候直接从高速缓存读取,而不去直接方法磁盘,这样就大大提高了CPU的使用效率,但是我们高速缓存大小也是很有限的,加载的页数是有限的,如果CPU需要读取的分页不在高速缓存中,则会发生缺页中断,从磁盘将需要的页加载到高速缓存。
如下图,是两个进程的虚拟页表映射关系:
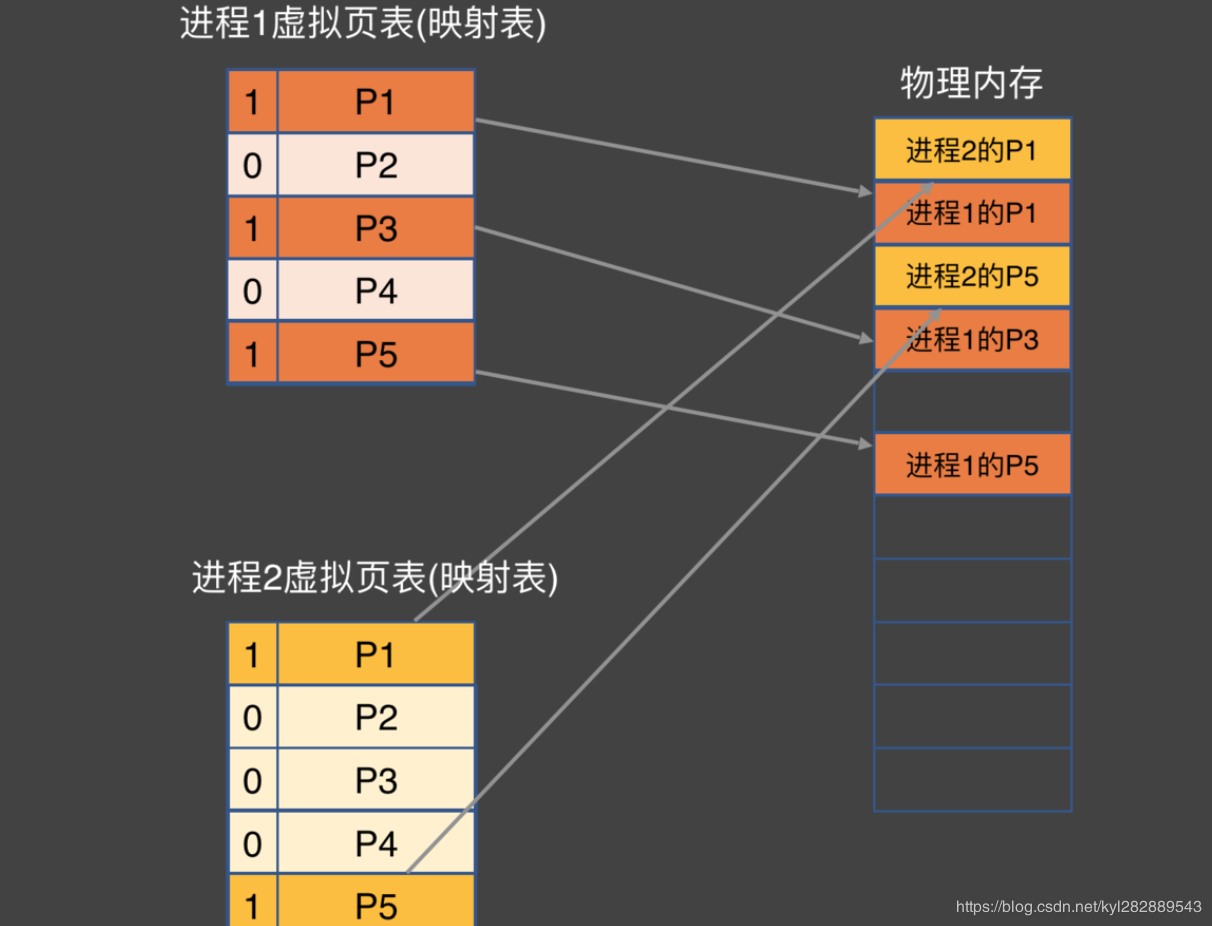
当应用被加载到内存中时 , 并不会将整个应用加载到内存中 . 只会放用到的那一部分 . 也就是懒加载的概念 , 换句话说就是应用使用多少 , 实际物理内存就实际存储多少 .
当应用访问到某个地址 , 映射表中为 0 , 也就是说并没有被加载到物理内存中时 , 系统就会立刻阻塞整个进程 , 触发一个我们所熟知的 缺页中断 - Page Fault .
当一个缺页中断被触发 , 操作系统会从磁盘中重新读取这页数据到物理内存上 , 然后将映射表中虚拟内存指向对应 ( 如果当前内存已满 , 操作系统会通过置换页算法 找一页数据进行覆盖 , 这也是为什么开再多的应用也不会崩掉 , 但是之前开的应用再打开时 , 就重新启动了的根本原因 ).
操作系统通过这种分页和覆盖机制 , 就完美的解决了内存浪费和效率问题,但是由于采用了虚拟内存 , 那么其中一个函数无论如何运行 , 运行多少次 , 都会是虚拟内存中的固定地址 . 这样就会有漏洞,黑客可以很轻易的提前写好程序获取固定函数的实现进行修改 hook 操作 . 所以产生这个非常严重的安全性问题。
例如:假设应用有一个函数 , 基于首地址偏移量为
0x00a000, 那么虚拟地址从0x000000 ~ 0xffffff, 基于这个 , 那么这个函数我无论如何只需要通过0x00a000这个虚拟地址就可以拿到其真实实现地址 .
为了解决上面安全问题,引入了ASLR 技术 . 其原理就是 每次 虚拟地址在映射真实地址之前 , 增加一个随机偏移值。
Android 4.0 , Apple iOS4.3 , OS X Mountain Lion10.8开始全民引入 ASLR 技术 , 而实际上自从引入ASLR后 , 黑客的门槛也自此被拉高 . 不再是人人都可做黑客的年代
通过上面对内存加载原理的讲解,我们了解了分页和缺页中断。而我们接下来要讲解的启动优化--二进制重排技术 就是基于上面的原理,尽量减少缺页中断发生的次数,从而达到减少启动时间的损耗,最终达到启动时间优化的目的。
1.1.3.1.2 二进制重排技术原理
在了解了内存分页会触发中断异常 Page Fault 会阻塞进程后 , 我们就知道了这个问题是会对性能产生影响的 .
实际上在 iOS 系统中 , 对于生产环境的应用 , 当产生缺页中断进行重新加载时 , iOS 系统还会对其做一次签名验证 . 因此 iOS 生产环境的应用 page fault 所产生的耗时要更多 .
抖音团队分享的一个
Page Fault,开销在0.6 ~ 0.8ms, 实际测试发现不同页会有所不同 , 也跟 cpu 负荷状态有关 , 在0.1 ~ 1.0 ms之间 。
当用户使用应用时 , 第一个直接印象就是启动 app 耗时 , 而恰巧由于启动时期有大量的类 , 分类 , 三方 等等需要加载和执行 , 多个 page fault 所产生的的耗时往往是不能小觑的 . 这也是二进制重排进行启动优化的必要性 .
假设在启动时期我们需要调用两个函数 method1 与 method4 . 函数编译在 mach-o 中的位置是根据 ld ( Xcode 的链接器) 的编译顺序并非调用顺序来的 . 因此很可能这两个函数分布在不同的内存页上 .

那么启动时 , page1 与 page2 则都需要从无到有加载到物理内存中 , 从而触发两次 page fault .
而二进制重排的做法就是将 method1 与 method4 放到一个内存页中 , 那么启动时则只需要加载 page1 即可 , 也就是只触发一次 page fault , 达到优化目的 .
实际项目中的做法是将启动时需要调用的函数放到一起 ( 比如 前10页中 ) 以尽可能减少 page fault , 达到优化目的 . 而这个做法就叫做 : 二进制重排 .
1.1.3.1.3 如何查看 page fault
如果想查看真实 page fault 次数 , 应该将应用卸载 , 查看第一次应用安装后的效果 , 或者先打开很多个其他应用 .
因为之前运行过 app , 应用其中一部分已经被加载到物理内存并做好映射表映射 , 这时再启动就会少触发一部分缺页中断 , 并且杀掉应用再打开也是如此 .
其实就是希望将物理内存中之前加载的覆盖/清理掉 , 减少误差 .
查看步骤如下:
-
打开
Instruments, 选择System Trace.
-
选择真机 , 选择工程 , 点击启动 , 当首个页面加载出来点击停止 . 这里注意 , 最好是将应用杀掉重新安装 , 因为冷热启动的界定其实由于进程的原因并不一定后台杀掉应用重新打开就是冷启动 .

- 等待分析完成 , 查看缺页次数
如下图是后台杀掉重启应用的情况:
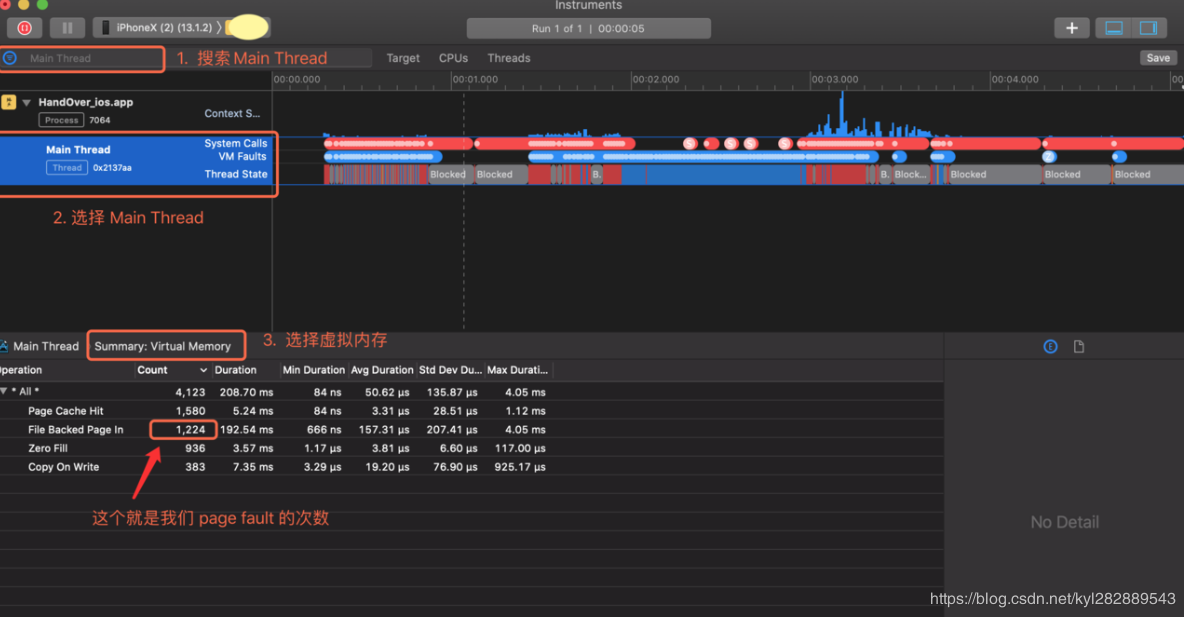
如下图是第一次安装启动应用的情况:
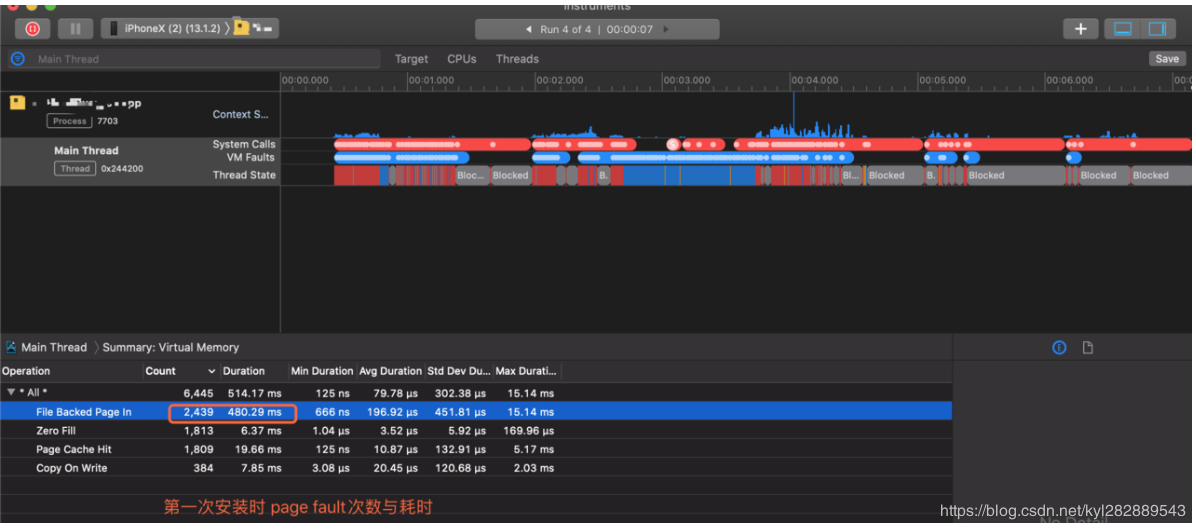
此外,你还可以通过添加 DYLD_PRINT_STATISTICS 来查看 pre-main 阶段总耗时来做一个侧面辅证 .
1.1.3.1.4 二进制重排具体如何操作
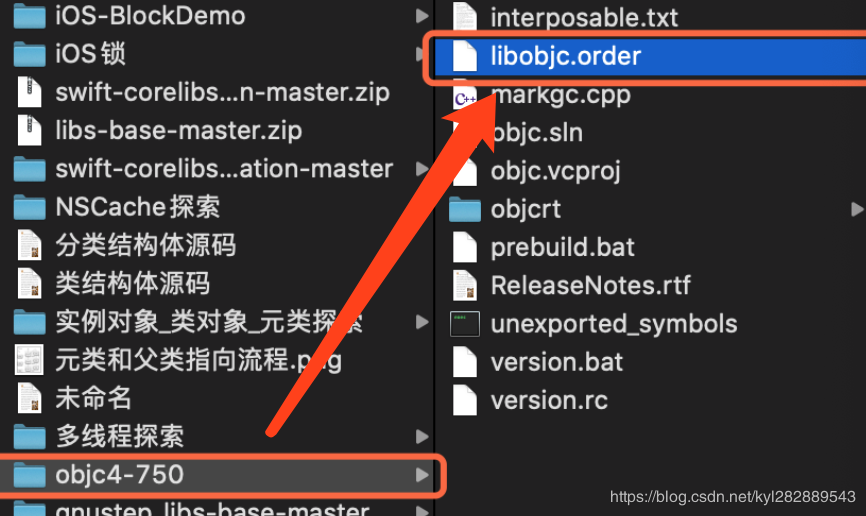
二进制重排具体操作,其实很简单 , Xcode 已经提供好这个机制 , 并且 libobjc 实际上也是用了二进制重排进行优化 .
在objc4-750源码中提供了libobjc.order 如下图:
我们在Xcode中通过如下步骤来进行二进制重排:
-
首先 , Xcode 是用的链接器叫做
ld,ld有一个参数叫Order File, 我们可以通过这个参数配置一个order文件的路径 . -
在这个
order文件中 , 将你需要的符号按顺序写在里面 -
当工程
build的时候 , Xcode 会读取这个文件 , 打的二进制包就会按照这个文件中的符号顺序进行生成对应的mach-O.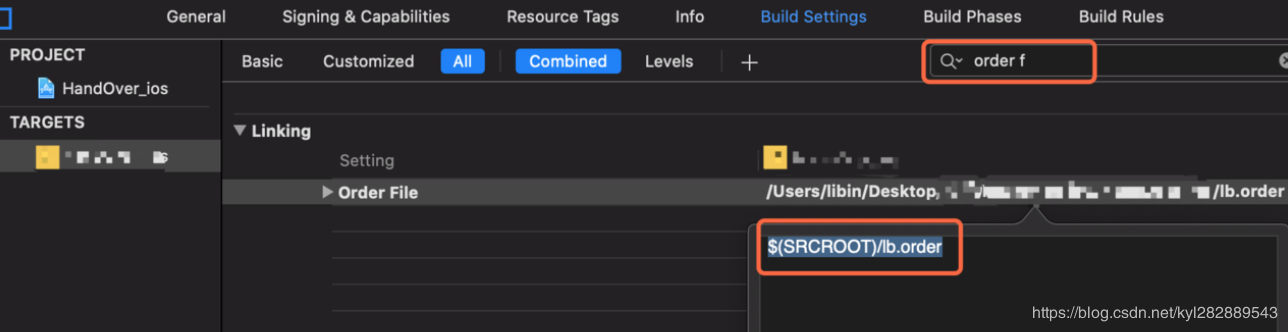
-
如何查看自己工程的符号顺序
重排前后我们需要查看自己的符号顺序有没有修改成功 , 这时候就用到了 Link Map .
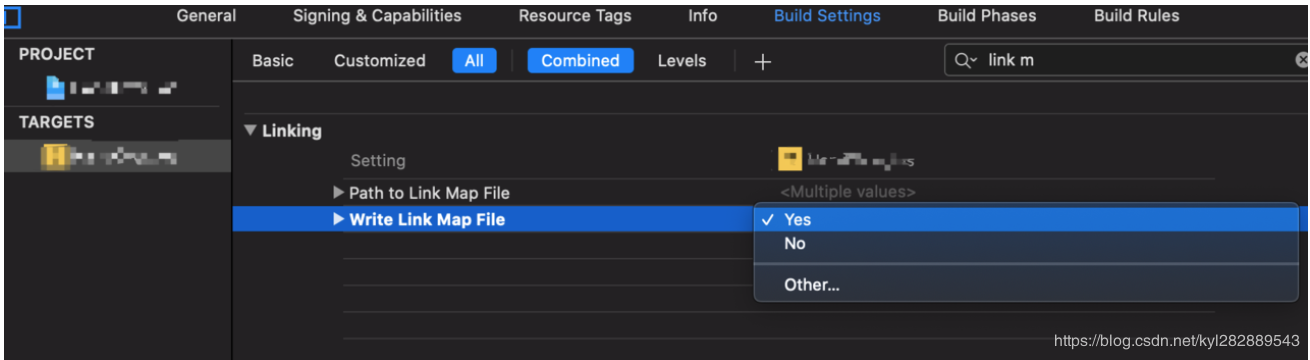
1.1.3.1.5 Link Map
Link Map 是编译期间产生的产物 , ( ld 的读取二进制文件顺序默认是按照 Compile Sources - GUI 里的顺序 ) , 它记录了二进制文件的布局 . 通过设置 Write Link Map File 来设置输出与否 , 默认是 no .
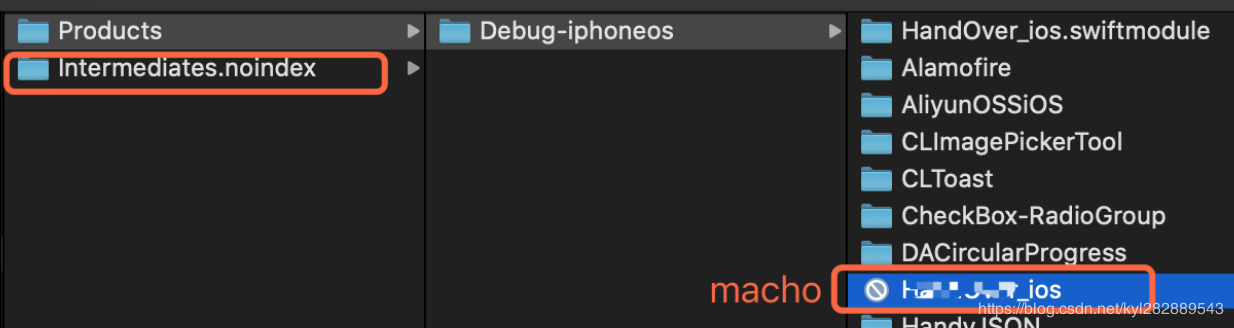
clean 一下 , 运行工程 , Products - show in finder, 找到 macho 的上上层目录.
按下图依次找到最新的一个 .txt 文件并打开.

这个文件中就存储了所有符号的顺序 , 在 # Symbols: 部分:
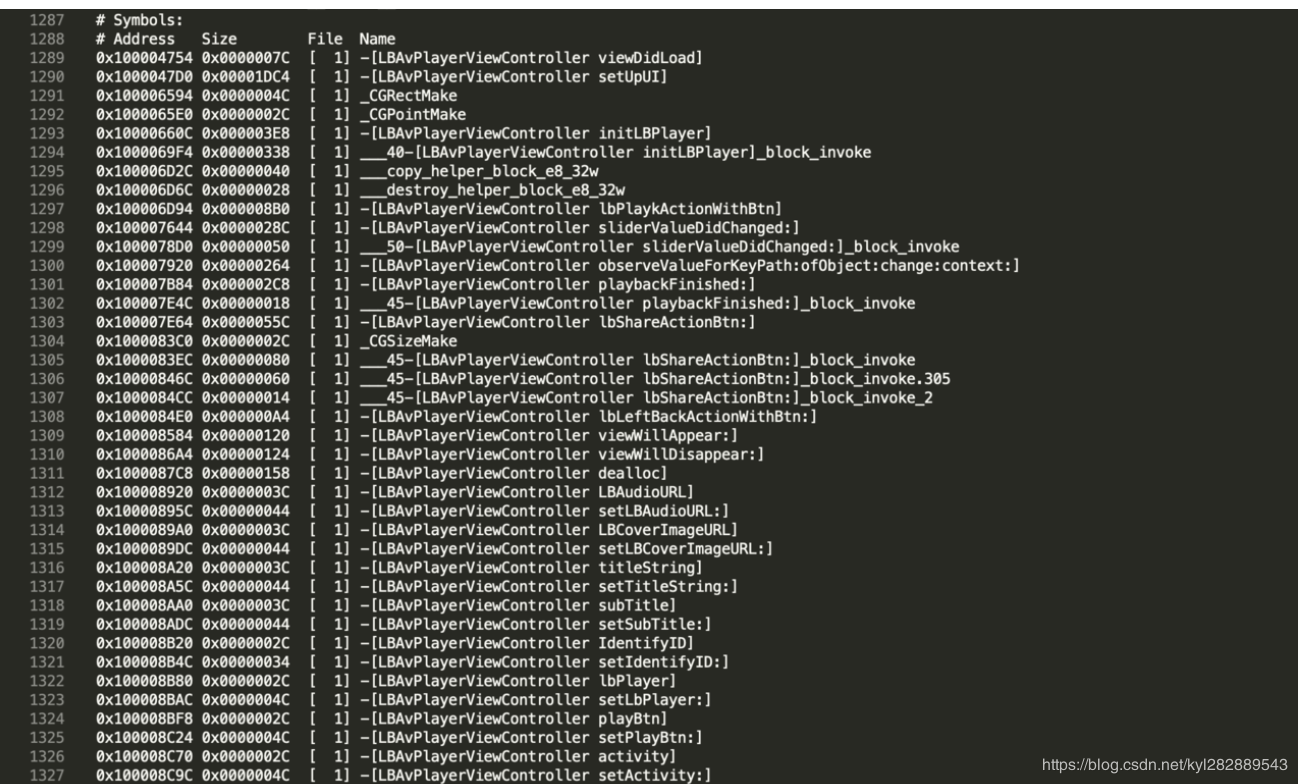
page fault 的次数从而实现时间上的优化.
可以看到 , 这个符号顺序明显是按照 Compile Sources 的文件顺序来排列的 .
1.2 卡顿优化
1.2.1 卡顿原理分析
在了解卡顿产生的原因之前,先看下屏幕显示图像的原理。
我们先要连接一些关于CPU,GPU的相关概念:
- CPU:负责对象的创建和销毁、对象属性的调整、布局计算、文本的计算和排版、图片的格式转换和解码、图像的绘制(Core Graphics)
- GPU:负责纹理的渲染(将数据渲染到屏幕)
- GPU是一个专门为图形高并发计算而量身定做的处理单元,比CPU使用更少的电来完成工作并且GPU的浮点计算能力要超出CPU很多。
- GPU的渲染性能要比CPU高效很多,同时对系统的负载和消耗也更低一些,所以在开发中,我们应该尽量让CPU负责主线程的UI调动,把图形显示相关的工作交给GPU来处理,当涉及到光栅化等一些工作时,CPU也会参与进来,这点在后面再详细描述。
- 相对于CPU来说,GPU能干的事情比较单一:接收提交的纹理(Texture)和顶点描述(三角形),应用变换(transform)、混合(合成)并渲染,然后输出到屏幕上。通常你所能看到的内容,主要也就是纹理(图片)和形状(三角模拟的矢量图形)两类。
-
CPU 和 GPU 的协作:
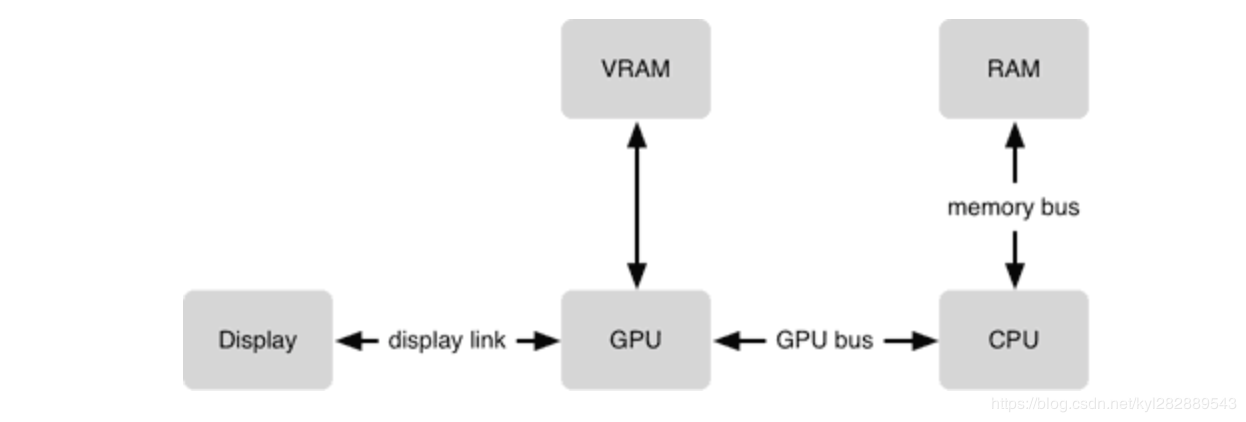
-
垂直同步技术:让CPU和GPU在收到vSync信号后再开始准备数据,防止撕裂感和跳帧,通俗来讲就是保证每秒输出的帧数不高于屏幕显示的帧数。
-
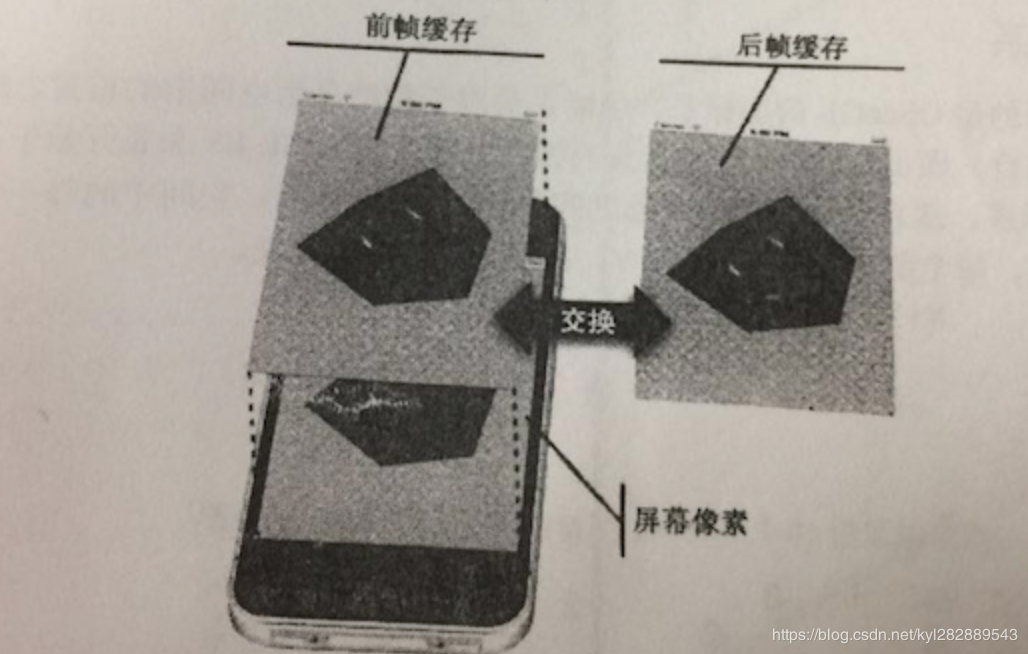
双缓冲技术:iOS是双缓冲机制,前帧缓存和后帧缓存,cpu计算完GPU渲染后放入缓冲区中,当gpu下一帧已经渲染完放入缓冲区,且视频控制器已经读完前帧,GPU会等待vSync(垂直同步信号)信号发出后,瞬间切换前后帧缓存,并让cpu开始准备下一帧数据 安卓4.0后采用三重缓冲,多了一个后帧缓冲,可降低连续丢帧的可能性,但会占用更多的CPU和GPU
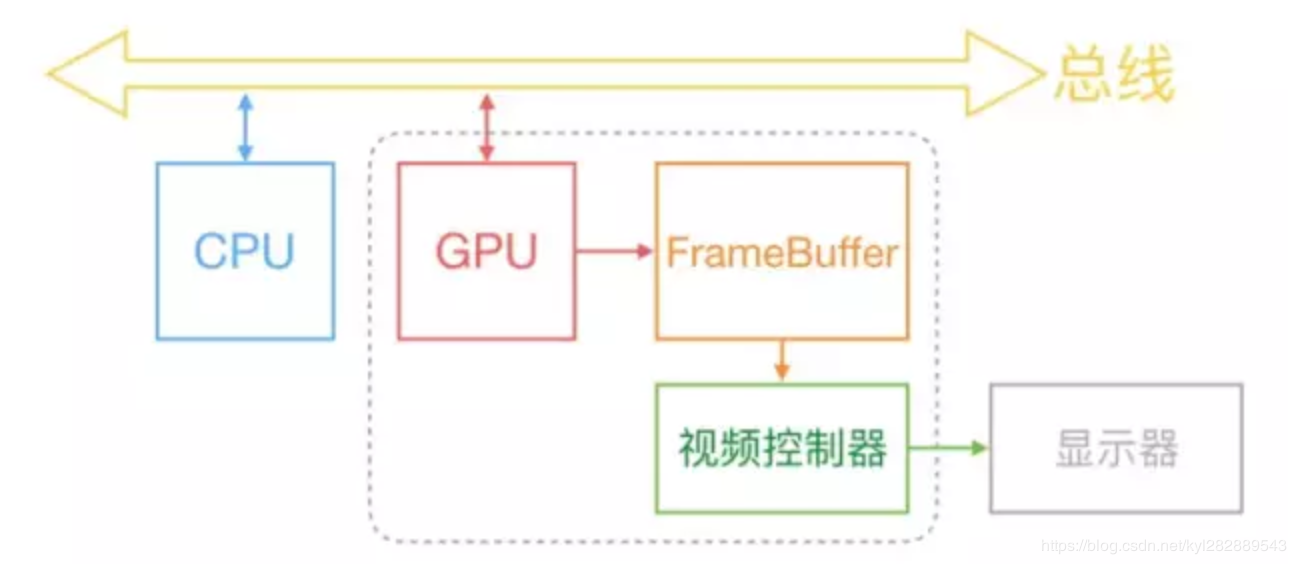
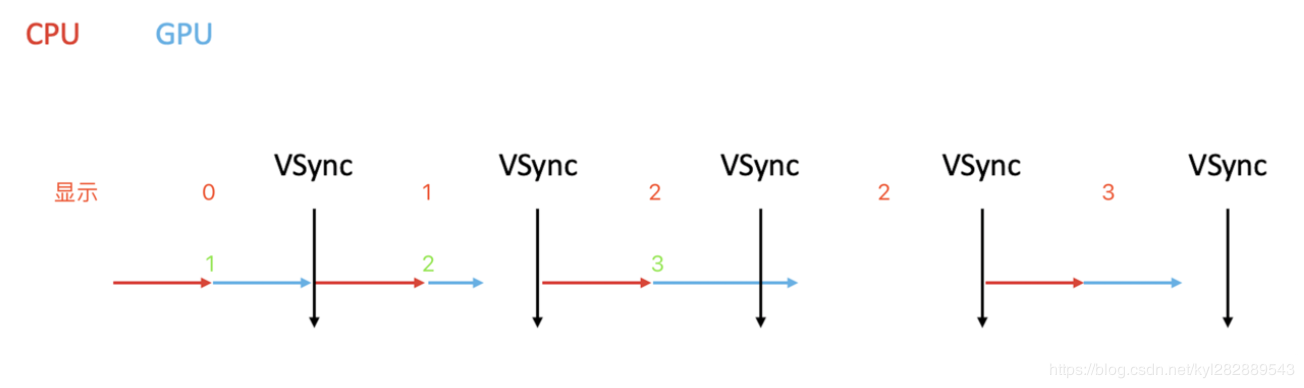
- 屏幕显示图像的原理:
- 屏幕绘制原理:
现在的手机设备基本都是采用双缓存+垂直同步(即V-Sync)屏幕显示技术。 如上图所示,系统内CPU、GPU和显示器是协同完成显示工作的。其中CPU负责计算显示的内容,例如视图创建、布局计算、图片解码、文本绘制等等。随后CPU将计算好的内容提交给GPU,由GPU进行变换、合成、渲染。GPU会预先渲染好一帧放入一个缓冲区内,让视频控制器读取,当下一帧渲染好后,GPU会直接将视频控制器的指针指向第二个容器(双缓存原理)。这里,GPU会等待显示器的VSync(即垂直同步)信号发出后,才进行新的一帧渲染和缓冲区更新(这样能解决画面撕裂现象,也增加了画面流畅度,但需要消费更多的计算资源,也会带来部分延迟)。
1.2.1.1 iOS 中图片的解压缩到渲染过程
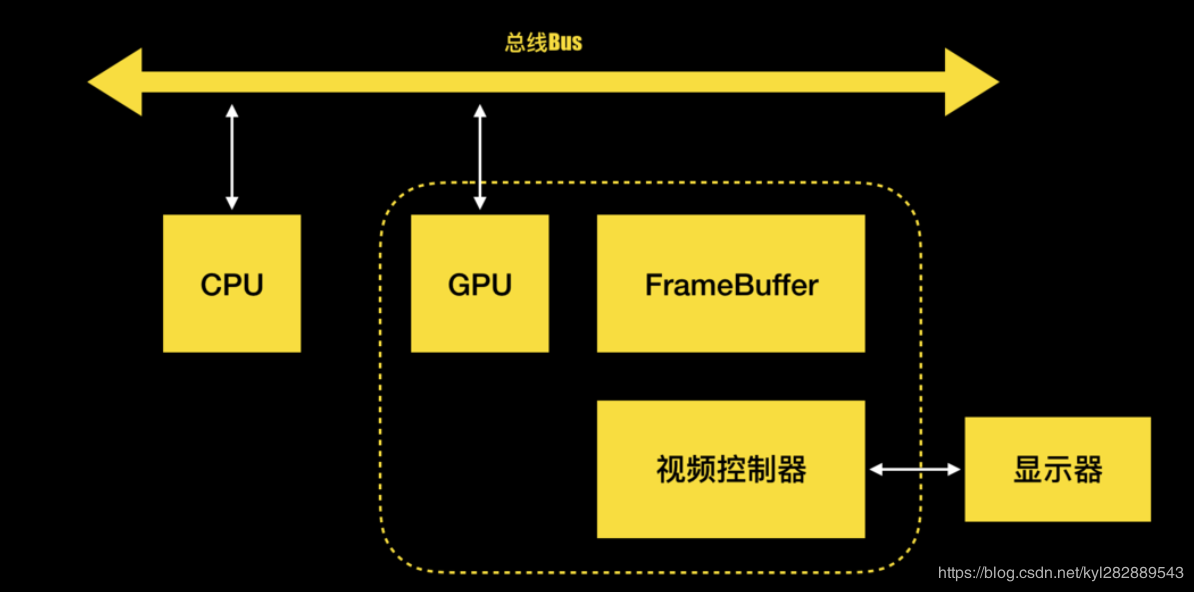
- CPU: 计算视图frame,图片解码,需要绘制纹理图片通过数据总线交给GPU
- GPU: 纹理混合,顶点变换与计算,像素点的填充计算,渲染到帧缓冲区。
- 时钟信号:垂直同步信号V-Sync / 水平同步信号H-Sync。
- iOS设备双缓冲机制:显示系统通常会引入两个帧缓冲区,双缓冲机制
- 图片显示到屏幕上是CPU与GPU的协作完成
总的说来,图片渲染到屏幕的过程:
读取文件->计算Frame->图片解码->解码后纹理图片位图数据通过数据总线交给GPU->GPU获取图片Frame->顶点变换计算->光栅化->根据纹理坐标获取每个像素点的颜色值(如果出现透明值需要将每个像素点的颜色*透明度值)->渲染到帧缓存区->渲染到屏幕
1.2.1.1.1 图片加载流程
- 图片加载的工作流程:
- 假设我们使用 +imageWithContentsOfFile: 方法从磁盘中加载一张图片,这个时候的图片并没有解压缩;
- 然后将生成的 UIImage 赋值给 UIImageView
- 接着一个隐式的 CATransaction 捕获到了 UIImageView 图层树的变化
- 在主线程的下一个 runloop 到来时,Core Animation 提交了这个隐式的 transaction ,这个过程可能会对图片进行 copy 操作,而受图片是否字节对齐等因素的影响,这个 copy 操作可能会涉及以下部分或全部步骤: (1).分配内存缓冲区用于管理文件 IO 和解压缩操作 (2). 将文件数据从磁盘读到内存中; (3).将压缩的图片数据解码成未压缩的位图形式,这是一个非常耗时的 CPU 操作; (4). 最后 Core Animation 中CALayer使用未压缩的位图数据渲染 UIImageView 的图层。 (5). CPU计算好图片的Frame,对图片解压之后.就会交给GPU来做图片渲染
- 渲染流程: (1).GPU获取获取图片的坐标 (2).将坐标交给顶点着色器(顶点计算) (3).将图片光栅化(获取图片对应屏幕上的像素点) (4). 片元着色器计算(计算每个像素点的最终显示的颜色值) (5).从帧缓存区中渲染到屏幕上
1.2.1.1.2 为什么要解压缩图片
既然图片的解压缩需要消耗大量的 CPU 时间,那么我们为什么还要对图片进行解压缩呢?是否可以不经过解压缩,而直接将图片显示到屏幕上呢?答案是否定的。要想弄明白这个问题,我们首先需要知道什么是位图
其实,位图就是一个像素数组,数组中的每个像素就代表着图片中的一个点。我们在应用中经常用到的 JPEG 和 PNG 图片就是位图
大家可以尝试
UIImage *image = [UIImage imageNamed:@"text.png"];
CFDataRef rawData = CGDataProviderCopyData(CGImageGetDataProvider(image.CGImage));
打印rawData,这里就是图片的原始数据.
事实上,不管是 JPEG 还是 PNG 图片,都是一种压缩的位图图形格式。只不过 PNG 图片是无损压缩,并且支持 alpha 通道,而 JPEG 图片则是有损压缩,可以指定 0-100% 的压缩比。值得一提的是,在苹果的 SDK 中专门提供了两个函数用来生成 PNG 和 JPEG 图片:
// return image as PNG. May return nil if image has no CGImageRef or invalid bitmap format
UIKIT_EXTERN NSData * __nullable UIImagePNGRepresentation(UIImage * __nonnull image);
// return image as JPEG. May return nil if image has no CGImageRef or invalid bitmap format. compression is 0(most)..1(least)
UIKIT_EXTERN NSData * __nullable UIImageJPEGRepresentation(UIImage * __nonnull image, CGFloat compressionQuality);
因此,在将磁盘中的图片渲染到屏幕之前,必须先要得到图片的原始像素数据,才能执行后续的绘制操作,这就是为什么需要对图片解压缩的原因。
1.2.1.1.3 解压缩图片的原理
既然图片的解压缩不可避免,而我们也不想让它在主线程执行,影响我们应用的响应性,那么是否有比较好的解决方案呢?
我们前面已经提到了,当未解压缩的图片将要渲染到屏幕时,系统会在主线程对图片进行解压缩,而如果图片已经解压缩了,系统就不会再对图片进行解压缩。因此,也就有了业内的解决方案,在子线程提前对图片进行强制解压缩。
而强制解压缩的原理就是对图片进行重新绘制,得到一张新的解压缩后的位图。其中,用到的最核心的函数是 CGBitmapContextCreate :
CG_EXTERN CGContextRef __nullable CGBitmapContextCreate(void * __nullable data,
size_t width, size_t height, size_t bitsPerComponent, size_t bytesPerRow,
CGColorSpaceRef cg_nullable space, uint32_t bitmapInfo)
CG_AVAILABLE_STARTING(__MAC_10_0, __IPHONE_2_0);
函数参数解释:
-
data:如果不为 NULL ,那么它应该指向一块大小至少为 bytesPerRow * height 字节的内存;如果 为 NULL ,那么系统就会为我们自动分配和释放所需的内存,所以一般指定 NULL 即可; -
width 和height:位图的宽度和高度,分别赋值为图片的像素宽度和像素高度即可; -
bitsPerComponent:像素的每个颜色分量使用的 bit 数,在 RGB 颜色空间下指定 8 即可; -
bytesPerRow:位图的每一行使用的字节数,大小至少为 width * bytes per pixel 字节。当我们指定 0/NULL 时,系统不仅会为我们自动计算,而且还会进行 cache line alignment 的优化 -
space:就是我们前面提到的颜色空间,一般使用 RGB 即可; -
bitmapInfo:位图的布局信息.kCGImageAlphaPremultipliedFirst -
YYImage中解压图片的代码:
YYImage用于解压缩图片的函数YYCGImageCreateDecodedCopy存在于YYImageCoder类中,核心代码如下:
CGImageRef YYCGImageCreateDecodedCopy(CGImageRef imageRef, BOOL decodeForDisplay) {
...
if (decodeForDisplay) { // decode with redraw (may lose some precision)
CGImageAlphaInfo alphaInfo = CGImageGetAlphaInfo(imageRef) & kCGBitmapAlphaInfoMask;
BOOL hasAlpha = NO;
if (alphaInfo == kCGImageAlphaPremultipliedLast ||
alphaInfo == kCGImageAlphaPremultipliedFirst ||
alphaInfo == kCGImageAlphaLast ||
alphaInfo == kCGImageAlphaFirst) {
hasAlpha = YES;
}
// BGRA8888 (premultiplied) or BGRX8888
// same as UIGraphicsBeginImageContext() and -[UIView drawRect:]
CGBitmapInfo bitmapInfo = kCGBitmapByteOrder32Host;
bitmapInfo |= hasAlpha ? kCGImageAlphaPremultipliedFirst : kCGImageAlphaNoneSkipFirst;
CGContextRef context = CGBitmapContextCreate(NULL, width, height, 8, 0, YYCGColorSpaceGetDeviceRGB(), bitmapInfo);
if (!context) return NULL;
CGContextDrawImage(context, CGRectMake(0, 0, width, height), imageRef); // decode
CGImageRef newImage = CGBitmapContextCreateImage(context);
CFRelease(context);
return newImage;
} else {
...
}
}
它接受一个原始的位图参数 imageRef ,最终返回一个新的解压缩后的位图 newImage ,中间主要经过了以下三个步骤:
- 使用 CGBitmapContextCreate 函数创建一个位图上下文;
- 使用 CGContextDrawImage 函数将原始位图绘制到上下文中;
- 使用 CGBitmapContextCreateImage 函数创建一张新的解压缩后的位图。
事实上,SDWebImage 中对图片的解压缩过程与上述完全一致,只是传递给 CGBitmapContextCreate 函数的部分参数存在细微的差别. SDWebImage和YYImage解压图片性能对比:
- 在解压PNG图片,SDWebImage>YYImage
- 在解压JPEG图片,SDWebImage<YYImage
SDWebImage 解压图片的核心代码如下:
SDWebImage的使用:
CGImageRef imageRef = image.CGImage;
// device color space
CGColorSpaceRef colorspaceRef = SDCGColorSpaceGetDeviceRGB();
BOOL hasAlpha = SDCGImageRefContainsAlpha(imageRef);
// iOS display alpha info (BRGA8888/BGRX8888)
CGBitmapInfo bitmapInfo = kCGBitmapByteOrder32Host;
bitmapInfo |= hasAlpha ? kCGImageAlphaPremultipliedFirst : kCGImageAlphaNoneSkipFirst;
size_t width = CGImageGetWidth(imageRef);
size_t height = CGImageGetHeight(imageRef);
// kCGImageAlphaNone is not supported in CGBitmapContextCreate.
// Since the original image here has no alpha info, use kCGImageAlphaNoneSkipLast
// to create bitmap graphics contexts without alpha info.
CGContextRef context = CGBitmapContextCreate(NULL,
width,
height,
kBitsPerComponent,
0,
colorspaceRef,
bitmapInfo);
if (context == NULL) {
return image;
}
// Draw the image into the context and retrieve the new bitmap image without alpha
CGContextDrawImage(context, CGRectMake(0, 0, width, height), imageRef);
CGImageRef imageRefWithoutAlpha = CGBitmapContextCreateImage(context);
UIImage *imageWithoutAlpha = [[UIImage alloc] initWithCGImage:imageRefWithoutAlpha scale:image.scale orientation:image.imageOrientation];
CGContextRelease(context);
CGImageRelease(imageRefWithoutAlpha);
return imageWithoutAlpha;
1.2.2 卡顿原因和监控
1.2.2.1 卡顿原因
上面讲解了图片显示的原理和屏幕渲染的原理,造成卡顿的原因有很多,最主要的原因是因为发生了掉帧,如下图:
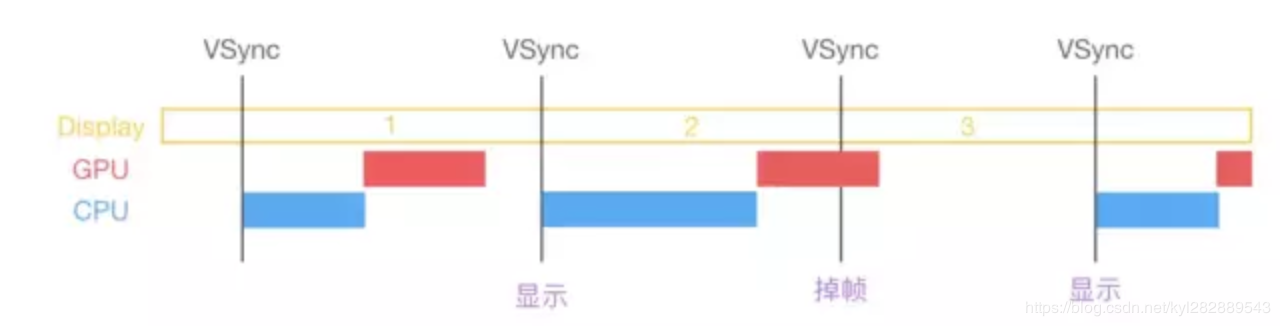
由上面屏幕显示的原理,采用了垂直同步机制的手机设备。在 VSync 信号到来后,系统图形服务会通过 CADisplayLink 等机制通知 App,App 主线程开始在 CPU 中计算显示内容,比如视图的创建、布局计算、图片解码、文本绘制等。随后 CPU 会将计算好的内容提交到 GPU 去,由 GPU 进行变换、合成、渲染。随后 GPU 会把渲染结果提交到帧缓冲区去,等待下一次 VSync 信号到来时显示到屏幕上。由于垂直同步的机制,如果在一个 VSync 时间内,CPU 或者 GPU 没有完成内容提交,则那一帧就会被丢弃,等待下一次机会再显示,而这时显示屏会保留之前的内容不变。这就是界面卡顿的原因。
在开发中,CPU和GPU中任何一个压力过大,都会导致掉帧现象,所以在开发时,也需要分别对CPU和GPU压力进行评估和优化。
1.2.2.2 卡顿监控
卡顿监控一般有两种实现方案:
- 主线程卡顿监控。通过子线程监测主线程的runLoop,判断两个状态区域之间的耗时是否达到一定阈值。
- FPS监控。要保持流畅的UI交互,App 刷新率应该当努力保持在 60fps。FPS的监控实现原理,上面已经探讨过这里略过。
在使用FPS监控性能的实践过程中,发现 FPS 值抖动较大,造成侦测卡顿比较困难。为了解决这个问题,通过采用检测主线程每次执行消息循环的时间,当这一时间大于规定的阈值时,就记为发生了一次卡顿的方式来监控。 这也是美团的移动端采用的性能监控Hertz 方案,微信团队也在实践过程中提出来类似的方案--微信读书 iOS 性能优化总结。
如下图是美团Hertz方案流程图:
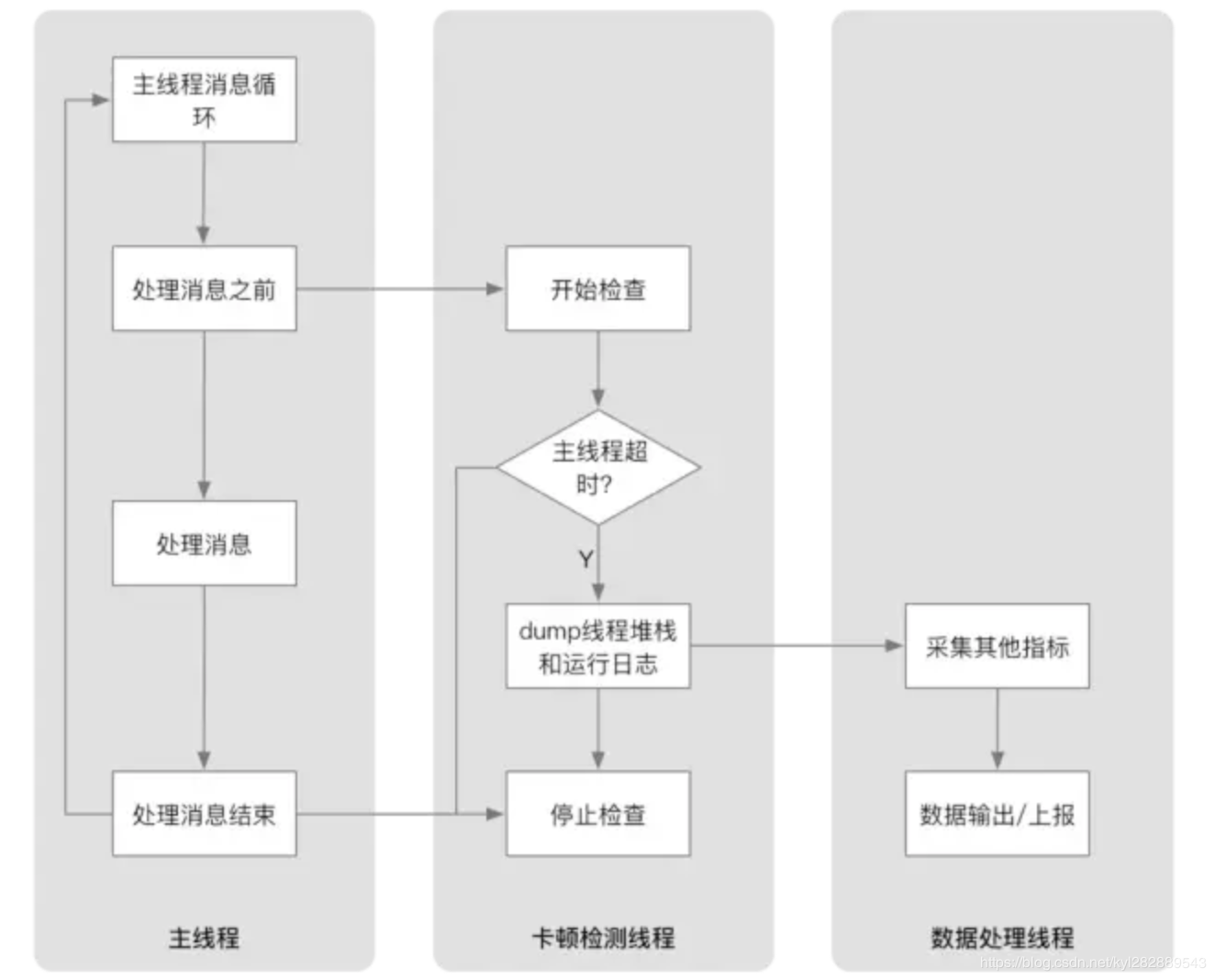
方案的提出,是根据滚动引发的Sources事件或其它交互事件总是被快速的执行完成,然后进入到kCFRunLoopBeforeWaiting状态下;假如在滚动过程中发生了卡顿现象,那么RunLoop必然会保持kCFRunLoopAfterWaiting或者kCFRunLoopBeforeSources这两个状态之一。 所以监控主线程卡顿的方案一:
开辟一个子线程,然后实时计算 kCFRunLoopBeforeSources 和 kCFRunLoopAfterWaiting 两个状态区域之间的耗时是否超过某个阀值,来断定主线程的卡顿情况。
但是由于主线程的RunLoop在闲置时基本处于Before Waiting状态,这就导致了即便没有发生任何卡顿,这种检测方式也总能认定主线程处在卡顿状态。
为了解决这个问题寒神(南栀倾寒)给出了自己的解决方案,Swift的卡顿检测第三方ANREye。这套卡顿监控方案大致思路为:创建一个子线程进行循环检测,每次检测时设置标记位为YES,然后派发任务到主线程中将标记位设置为NO。接着子线程沉睡超时阙值时长,判断标志位是否成功设置成NO,如果没有说明主线程发生了卡顿。
结合这套方案,当主线程处在Before Waiting状态的时候,通过派发任务到主线程来设置标记位的方式处理常态下的卡顿检测:
#define lsl_SEMAPHORE_SUCCESS 0
static BOOL lsl_is_monitoring = NO;
static dispatch_semaphore_t lsl_semaphore;
static NSTimeInterval lsl_time_out_interval = 0.05;
@implementation LSLAppFluencyMonitor
static inline dispatch_queue_t __lsl_fluecy_monitor_queue() {
static dispatch_queue_t lsl_fluecy_monitor_queue;
static dispatch_once_t once;
dispatch_once(&once, ^{
lsl_fluecy_monitor_queue = dispatch_queue_create("com.dream.lsl_monitor_queue", NULL);
});
return lsl_fluecy_monitor_queue;
}
static inline void __lsl_monitor_init() {
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
lsl_semaphore = dispatch_semaphore_create(0);
});
}
#pragma mark - Public
+ (instancetype)monitor {
return [LSLAppFluencyMonitor new];
}
- (void)startMonitoring {
if (lsl_is_monitoring) { return; }
lsl_is_monitoring = YES;
__lsl_monitor_init();
dispatch_async(__lsl_fluecy_monitor_queue(), ^{
while (lsl_is_monitoring) {
__block BOOL timeOut = YES;
dispatch_async(dispatch_get_main_queue(), ^{
timeOut = NO;
dispatch_semaphore_signal(lsl_semaphore);
});
[NSThread sleepForTimeInterval: lsl_time_out_interval];
if (timeOut) {
[LSLBacktraceLogger lsl_logMain]; // 打印主线程调用栈
// [LSLBacktraceLogger lsl_logCurrent]; // 打印当前线程的调用栈
// [LSLBacktraceLogger lsl_logAllThread]; // 打印所有线程的调用栈
}
dispatch_wait(lsl_semaphore, DISPATCH_TIME_FOREVER);
}
});
}
- (void)stopMonitoring {
if (!lsl_is_monitoring) { return; }
lsl_is_monitoring = NO;
}
@end
其中LSLBacktraceLogger是获取堆栈信息的类,详情见代码Github。
打印日志如下:
2018-08-16 12:36:33.910491+0800 AppPerformance[4802:171145] Backtrace of Thread 771:
======================================================================================
libsystem_kernel.dylib 0x10d089bce __semwait_signal + 10
libsystem_c.dylib 0x10ce55d10 usleep + 53
AppPerformance 0x108b8b478 $S14AppPerformance25LSLFPSTableViewControllerC05tableD0_12cellForRowAtSo07UITableD4CellCSo0kD0C_10Foundation9IndexPathVtF + 1144
AppPerformance 0x108b8b60b $S14AppPerformance25LSLFPSTableViewControllerC05tableD0_12cellForRowAtSo07UITableD4CellCSo0kD0C_10Foundation9IndexPathVtFTo + 155
UIKitCore 0x1135b104f -[_UIFilteredDataSource tableView:cellForRowAtIndexPath:] + 95
UIKitCore 0x1131ed34d -[UITableView _createPreparedCellForGlobalRow:withIndexPath:willDisplay:] + 765
UIKitCore 0x1131ed8da -[UITableView _createPreparedCellForGlobalRow:willDisplay:] + 73
UIKitCore 0x1131b4b1e -[UITableView _updateVisibleCellsNow:isRecursive:] + 2863
UIKitCore 0x1131d57eb -[UITableView layoutSubviews] + 165
UIKitCore 0x1133921ee -[UIView(CALayerDelegate) layoutSublayersOfLayer:] + 1501
QuartzCore 0x10ab72eb1 -[CALayer layoutSublayers] + 175
QuartzCore 0x10ab77d8b _ZN2CA5Layer16layout_if_neededEPNS_11TransactionE + 395
QuartzCore 0x10aaf3b45 _ZN2CA7Context18commit_transactionEPNS_11TransactionE + 349
QuartzCore 0x10ab285b0 _ZN2CA11Transaction6commitEv + 576
QuartzCore 0x10ab29374 _ZN2CA11Transaction17observer_callbackEP19__CFRunLoopObservermPv + 76
CoreFoundation 0x109dc3757 __CFRUNLOOP_IS_CALLING_OUT_TO_AN_OBSERVER_CALLBACK_FUNCTION__ + 23
CoreFoundation 0x109dbdbde __CFRunLoopDoObservers + 430
CoreFoundation 0x109dbe271 __CFRunLoopRun + 1537
CoreFoundation 0x109dbd931 CFRunLoopRunSpecific + 625
GraphicsServices 0x10f5981b5 GSEventRunModal + 62
UIKitCore 0x112c812ce UIApplicationMain + 140
AppPerformance 0x108b8c1f0 main + 224
libdyld.dylib 0x10cd4dc9d start + 1
方案二: 是结合CADisplayLink的方式实现
1.2.2.2.1 FPS
通过维基百科我们知道,FPS是Frames Per Second 的简称缩写,意思是每秒传输帧数,也就是我们常说的“刷新率(单位为Hz)。 FPS是测量用于保存、显示动态视频的信息数量。每秒钟帧数愈多,所显示的画面就会愈流畅,FPS值越低就越卡顿,所以这个值在一定程度上可以衡量应用在图像绘制渲染处理时的性能。一般我们的APP的FPS只要保持在 50-60之间,用户体验都是比较流畅的。 苹果手机屏幕的正常刷新频率是每秒60次,即可以理解为FPS值为60。我们都知道
CADisplayLink是和屏幕刷新频率保存一致,所以我们是否可以通过它来监控我们的FPS呢?
CADisplayLink是什么?
CADisplayLink是CoreAnimation提供的另一个类似于NSTimer的类,它总是在屏幕完成一次更新之前启动,它的接口设计的和NSTimer很类似,所以它实际上就是一个内置实现的替代,但是和timeInterval以秒为单位不同,CADisplayLink有一个整型的frameInterval属性,指定了间隔多少帧之后才执行。默认值是1,意味着每次屏幕更新之前都会执行一次。但是如果动画的代码执行起来超过了六十分之一秒,你可以指定frameInterval为2,就是说动画每隔一帧执行一次(一秒钟30帧)。
使用CADisplayLink监控界面的FPS值,参考自YYFPSLabel:
import UIKit
class LSLFPSMonitor: UILabel {
private var link: CADisplayLink = CADisplayLink.init()
private var count: NSInteger = 0
private var lastTime: TimeInterval = 0.0
private var fpsColor: UIColor = UIColor.green
public var fps: Double = 0.0
// MARK: - init
override init(frame: CGRect) {
var f = frame
if f.size == CGSize.zero {
f.size = CGSize(width: 55.0, height: 22.0)
}
super.init(frame: f)
self.textColor = UIColor.white
self.textAlignment = .center
self.font = UIFont.init(name: "Menlo", size: 12.0)
self.backgroundColor = UIColor.black
link = CADisplayLink.init(target: LSLWeakProxy(target: self), selector: #selector(tick))
link.add(to: RunLoop.current, forMode: RunLoopMode.commonModes)
}
deinit {
link.invalidate()
}
required init?(coder aDecoder: NSCoder) {
fatalError("init(coder:) has not been implemented")
}
// MARK: - actions
@objc func tick(link: CADisplayLink) {
guard lastTime != 0 else {
lastTime = link.timestamp
return
}
count += 1
let delta = link.timestamp - lastTime
guard delta >= 1.0 else {
return
}
lastTime = link.timestamp
fps = Double(count) / delta
let fpsText = "(String.init(format: "%.3f", fps)) FPS"
count = 0
let attrMStr = NSMutableAttributedString(attributedString: NSAttributedString(string: fpsText))
if fps > 55.0{
fpsColor = UIColor.green
} else if(fps >= 50.0 && fps <= 55.0) {
fpsColor = UIColor.yellow
} else {
fpsColor = UIColor.red
}
attrMStr.setAttributes([NSAttributedStringKey.foregroundColor:fpsColor], range: NSMakeRange(0, attrMStr.length - 3))
attrMStr.setAttributes([NSAttributedStringKey.foregroundColor:UIColor.white], range: NSMakeRange(attrMStr.length - 3, 3))
DispatchQueue.main.async {
self.attributedText = attrMStr
}
}
}
通过CADisplayLink的实现方式,并真机测试之后,确实是可以在很大程度上满足了监控FPS的业务需求和为提高用户体验提供参考,但是和Instruments的值可能会有些出入。下面我们来讨论下使用CADisplayLink的方式,可能存在的问题。
(1). 和Instruments值对比有出入,原因如下:
CADisplayLink运行在被添加的那个RunLoop之中(一般是在主线程中),因此它只能检测出当前RunLoop下的帧率。RunLoop中所管理的任务的调度时机,受任务所处的RunLoopMode和CPU的繁忙程度所影响。所以想要真正定位到准确的性能问题所在,最好还是通过Instrument来确认。
(2). 使用CADisplayLink可能存在的循环引用问题。
例如以下写法:
let link = CADisplayLink.init(target: self, selector: #selector(tick))
let timer = Timer.init(timeInterval: 1.0, target: self, selector: #selector(tick), userInfo: nil, repeats: true)
原因:以上两种用法,都会对 self 强引用,此时 timer持有 self,self 也持有 timer,循环引用导致页面 dismiss 时,双方都无法释放,造成循环引用。此时使用 weak 也不能有效解决:
weak var weakSelf = self
let link = CADisplayLink.init(target: weakSelf, selector: #selector(tick))
那么我们应该怎样解决这个问题,有人会说在deinit(或dealloc)中调用定时器的invalidate方法,但是这是无效的,因为已经造成循环引用了,不会走到这个方法的。
YYKit作者提供的解决方案是使用 YYWeakProxy,这个YYWeakProxy不是继承自NSObject而是继承NSProxy。
NSProxy是一个为对象定义接口的抽象父类,并且为其它对象或者一些不存在的对象扮演了替身角色。
修改后代码如下:
let link = CADisplayLink.init(target: LSLWeakProxy(target: self), selector: #selector(tick))
1.2.2.3 卡顿优化 CPU 相关优化
卡顿优化从 CPU层面的 相关优化,有下面这些方式:
- 尽量用轻量级的对象,比如用不到事件处理的地方使用
CALayer取代UIView- 尽量提前计算好布局(例如
cell行高)- 不要频繁地调用和调整
UIView的相关属性,比如frame、bounds、transform等属性,尽量减少不必要的调用和修改(UIView的显示属性实际都是CALayer的映射,而CALayer本身是没有这些属性的,都是初次调用属性时通过resolveInstanceMethod添加并创建Dictionary保存的,耗费资源)Autolayout会比直接设置frame消耗更多的CPU资源,当视图数量增长时会呈指数级增长.- 图片的
size最好刚好跟UIImageView的size保持一致,减少图片显示时的处理计算- 控制一下线程的最大并发数量
- 尽量把耗时的操作放到子线程
- 文本处理(尺寸计算、绘制、
CoreText和YYText): (1). 计算文本宽高boundingRectWithSize:options:context:和文本绘制drawWithRect:options:context:放在子线程操作 (2). 使用CoreText自定义文本空间,在对象创建过程中可以缓存宽高等信息,避免像UILabel/UITextView需要多次计算(调整和绘制都要计算一次),且CoreText直接使用了CoreGraphics占用内存小,效率高。(YYText)- 图片处理(解码、绘制) 图片都需要先解码成
bitmap才能渲染到UI上,iOS创建UIImage,不会立刻进行解码,只有等到显示前才会在主线程进行解码,固可以使用CoreGraphics中的CGBitmapContextCreate相关操作提前在子线程中进行强制解压缩获得位图.- TableViewCell 复用: 在
cellForRowAtIndexPath:回调的时候只创建实例,快速返回cell,不绑定数据。在willDisplayCell: forRowAtIndexPath:的时候绑定数据(赋值)- 高度缓存: 在
tableView滑动时,会不断调用heightForRowAtIndexPath:,当cell高度需要自适应时,每次回调都要计算高度,会导致 UI 卡顿。为了避免重复无意义的计算,需要缓存高度。- 视图层级优化: 不要动态创建视图,在内存可控的前提下,缓存
subview。善用hidden。- 减少视图层级: 减少
subviews个数,用layer绘制元素. 少用clearColor,maskToBounds,阴影效果等。- 减少多余的绘制操作.
- 图片优化: (1)不要用
JPEG的图片,应当使用PNG图片。 (2)子线程预解码(Decode),主线程直接渲染。因为当image没有Decode,直接赋值给imageView会进行一个Decode操作。 (3)优化图片大小,尽量不要动态缩放(contentMode)。 (4)尽可能将多张图片合成为一张进行显示。- 减少透明
view: 使用透明view会引起blending,在iOS的图形处理中,blending主要指的是混合像素颜色的计算。最直观的例子就是,我们把两个图层叠加在一起,如果第一个图层的透明的,则最终像素的颜色计算需要将第二个图层也考虑进来。这一过程即为Blending。- 理性使用
-drawRect: 当你使用UIImageView在加载一个视图的时候,这个视图虽然依然有CALayer,但是却没有申请到一个后备的存储,取而代之的是使用一个使用屏幕外渲染,将CGImageRef作为内容,并用渲染服务将图片数据绘制到帧的缓冲区,就是显示到屏幕上,当我们滚动视图的时候,这个视图将会重新加载,浪费性能。所以对于使用-drawRect:方法,更倾向于使用CALayer来绘制图层。因为使用CALayer的-drawInContext:,Core Animation将会为这个图层申请一个后备存储,用来保存那些方法绘制进来的位图。那些方法内的代码将会运行在 CPU上,结果将会被上传到GPU。这样做的性能更为好些。 静态界面建议使用-drawRect:的方式,动态页面不建议。- 按需加载: 局部刷新,刷新一个cell就能解决的,坚决不刷新整个
section或者整个tableView,刷新最小单元元素。 利用runloop提高滑动流畅性,在滑动停止的时候再加载内容,像那种一闪而过的(快速滑动),就没有必要加载,可以使用默认的占位符填充内容。
- 关于
Blending补充:
会导致
blending的原因:
UIView的alpha< 1。UIImageView的image含有alpha channel(即使UIImageView的alpha是1,但只要image含有透明通道,则仍会导致blending)。
为啥
blending会导致性能的损失?
- 原因是很直观的,如果一个图层是不透明的,则系统直接显示该图层的颜色即可。而如果图层是透明的,则会引起更多的计算,因为需要把另一个的图层也包括进来,进行混合后的颜色计算。
opaque设置为YES,减少性能消耗,因为GPU将不会做任何合成,而是简单从这个层拷贝。
1.2.2.4 卡顿优化 GPU 相关优化
- 从
GPU层面的卡顿相关优化有下面这些方式:
- 尽量避免短时间内大量图片的显示,尽可能将多张图片合成一张进行显示
GPU能处理的最大纹理尺寸是4096x4096,一旦超过这个尺寸,就会占用CPU资源进行处理,所以纹理尽量不要超过这个尺寸GPU会将多个视图混合在一起再去显示,混合的过程会消耗CPU资源,尽量减少视图数量和层次- 减少透明的视图(
alpha<1),不透明的就设置opaque为YES,GPU就不会去进行alpha的通道合成- 尽量避免出现离屏渲染.
- 合理使用光栅化
shouldRasterize: 光栅化是把GPU的操作转到CPU上,生成位图缓存,直接读取复用。CALayer会被光栅化为bitmap,shadows、cornerRadius等效果会被缓存。 更新已经光栅化的layer,会造成离屏渲染。bitmap超过100ms没有使用就会移除。 受系统限制,缓存的大小为 2.5X Screen Size。shouldRasterize适合静态页面显示,动态页面会增加开销。如果设置了shouldRasterize为 YES,那也要记住设置rasterizationScale为contentsScale。- 异步渲染.在子线程绘制,主线程渲染。例如 VVeboTableViewDemo
1.2.3 离屏渲染
- 什么是离屏渲染?
- 在OpenGL中,GPU有2种渲染方式 On-Screen Rendering:当前屏幕渲染,在当前用于显示的屏幕缓冲区进行渲染操作 Off-Screen Rendering:离屏渲染,在当前屏幕缓冲区以外新开辟一个缓冲区进行渲染操作
- 离屏渲染消耗性能的原因 需要创建新的缓冲区 离屏渲染的整个过程,需要多次切换上下文环境,先是从当前屏幕(On-Screen)切换到离屏(Off-Screen);等到离屏渲染结束以后,将离屏缓冲区的渲染结果显示到屏幕上,又需要将上下文环境从离屏切换到当前屏幕
- 什么操作会导致离屏渲染?
- 光栅化,
layer.shouldRasterize = YES- 遮罩,
layer.mask- 圆角,同时设置
layer.masksToBounds = YES、layer.cornerRadius大于0. 考虑通过CoreGraphics绘制裁剪圆角,或者叫美工提供圆角图片- 阴影,
layer.shadowXXX如果设置了layer.shadowPath就不会产生离屏渲染.layer.allowsGroupOpacity为YES,layer.opacity的值小于1.0
- 离屏渲染优化
- 使用
ShadowPath指定layer阴影效果路径。- 使用异步进行
layer渲染(Facebook开源的异步绘制框架AsyncDisplayKit)。- 设置
layer的opaque值为YES,减少复杂图层合成。- 尽量使用不包含透明(
alpha)通道的图片资源。- 尽量设置
layer的大小值为整形值。- 直接让美工把图片切成圆角进行显示,这是效率最高的一种方案。
- 很多情况下用户上传图片进行显示,可以在客户端处理圆角。
- 使用代码手动生成圆角
image设置到要显示的View上,利用UIBezierPath(Core Graphics框架)画出来圆角图片。
1.2.4 xcode性能分析工具
1.2.4.1 Instuments
- Instuments:
Instuments是Xcode套件中没有被充分利用的工具,很多iOS开发者从来没用过Instrument,特别是通过短暂培训出来的同学们,所以,很多面试官也会问性能条调优方面的知识,来判断面试的同学是否真正应用对年开发经验。
1.2.4.2 Activity Monitor
- Activity Monitor:个人觉的很像Windows的任务管理器,可以查看所有的进程,以及进程的内存、cpu使用百分比等数据等。
1.2.4.3 Allocations
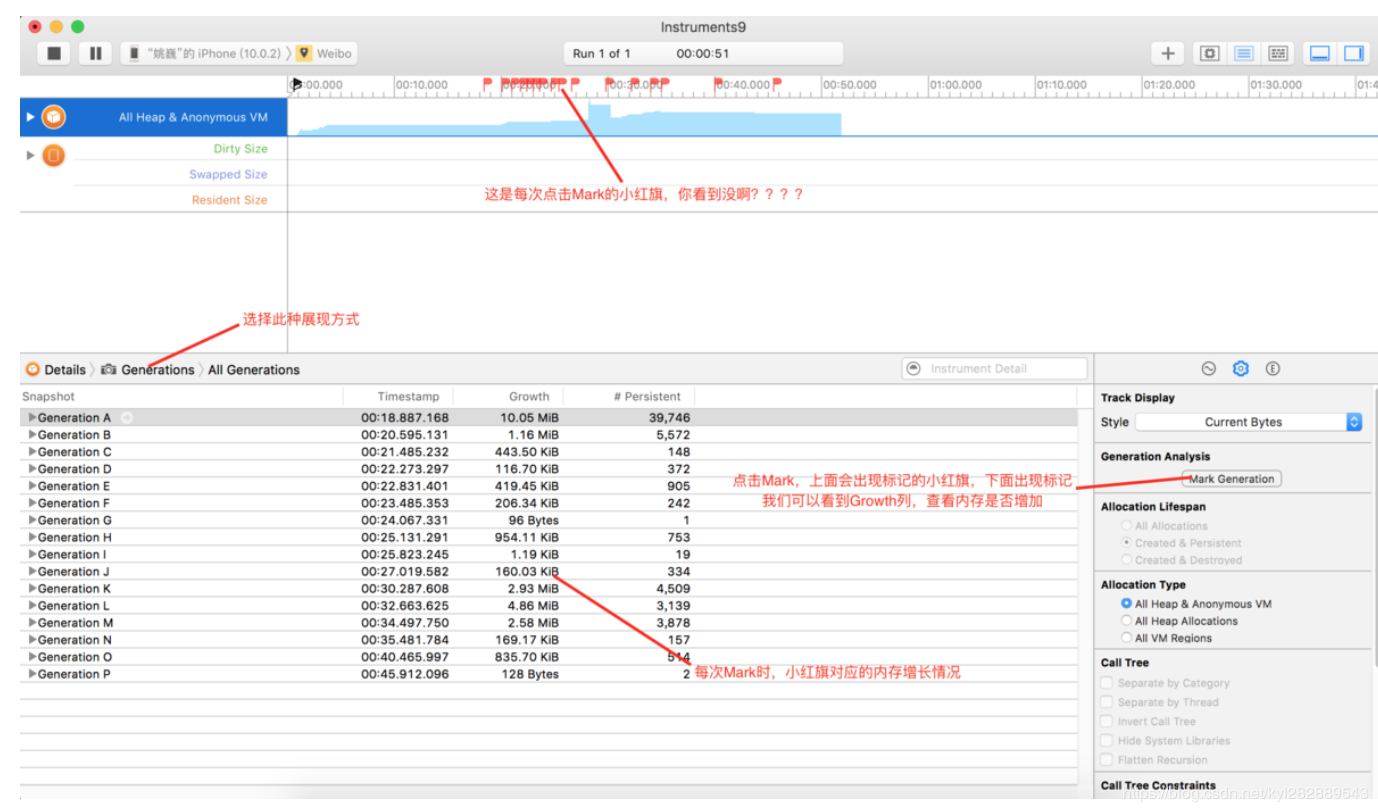
- Allocations :管理内存是app开发中最重要的一个方面,对于开发者来说,在程序架构中减少内存的使用通常都是使用Allocations去定位和找出减少内存使用的方式 接下来,谈一下内存泄漏的两种情况
- 第一种:为对象A申请了内存空间,之后再也没用过对象A,也没释放过A导致内存泄漏,这种是
Leaked Memory内存泄漏- 第二种:类似于递归,不断地申请内存空间导致的内存泄漏,这种情况是
Abandoned Momory
Allocations工具可以让开发者很好的了解每个方法占用内存的情况,并定位相关的代码,如下图:
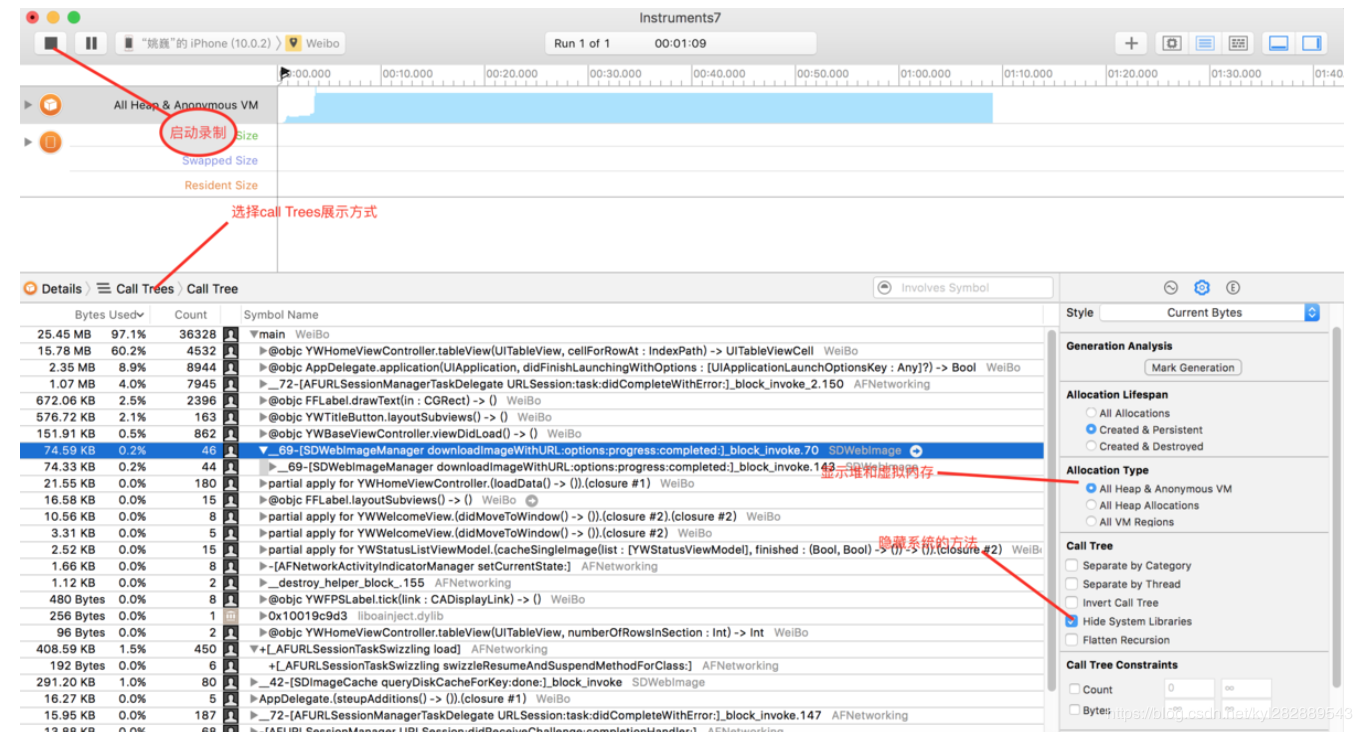
右键就可以打开Xcode自动定位到相关占用内存方法的代码上
1.2.4.4 Core Animation
- Core Animation
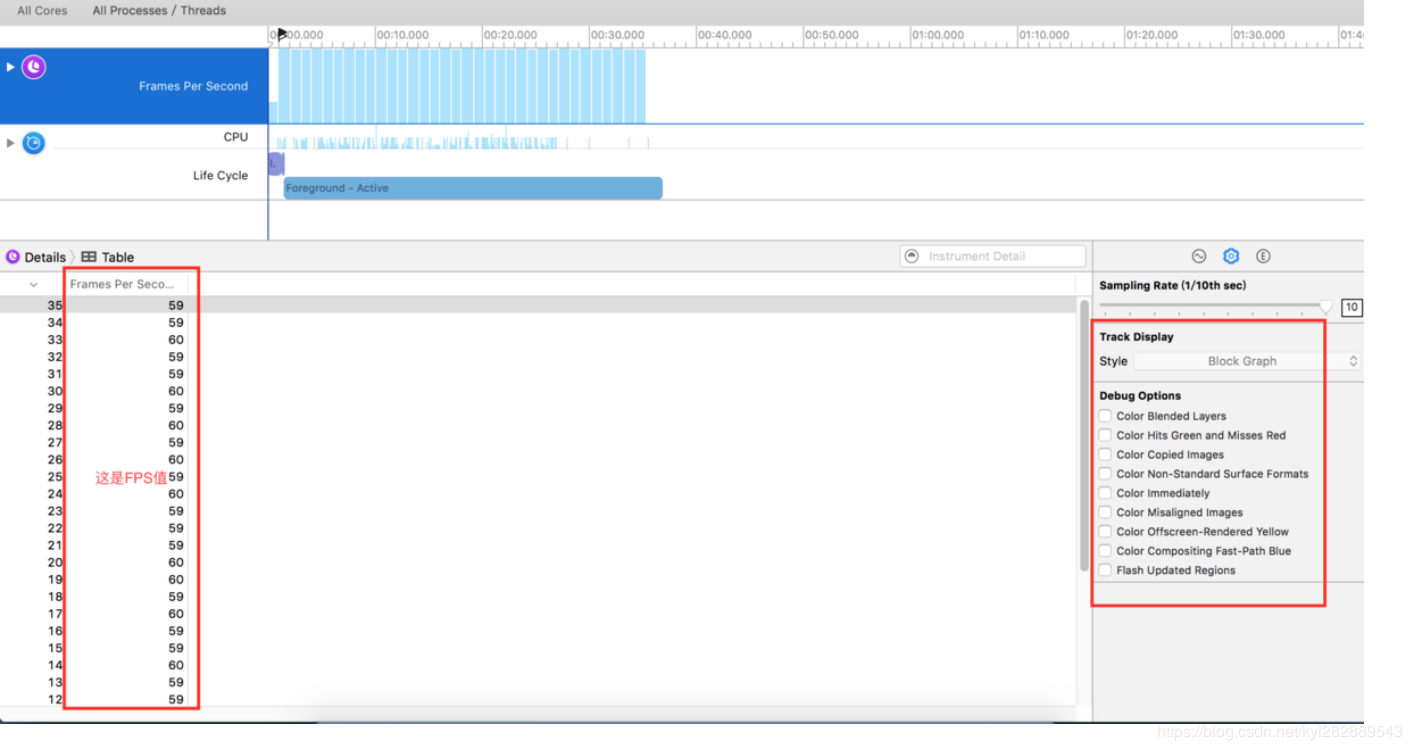
圈着数字红色方框中的数字,代表着FPS值,理论上60最佳,实际过程中59就可以了,说明就是很流畅的,说明一下操作方式:在手指不离开屏幕的情况下,上下滑动屏幕列表 介绍一下Deug Display中选项的作用
- Color Blended Layers(混合过度绘制):
打开此选项屏幕的效果图如下:

这个选项基于渲染程度对屏幕中的混合区域进行绿到红的高亮(也就是多个半透明图层的叠加),由于重绘的原因,混合对GPU性能会有影响,同时也是滑动或者动画掉帧的罪魁祸首之一 GPU每一帧的绘制的像素有最大限制,这个情况下可以轻易绘制整个屏幕的像素,但如果发生重叠像素的关系需要不停的重绘同一区域的,掉帧和卡顿就有可能发生。 GPU会放弃绘制那些完全被其他图层遮挡的像素,但是要计算出一个图层是否被遮挡也是相当复杂并且会消耗CPU的资源,同样,合并不同图层的透明重叠元素消耗的资源也很大,所以,为了快速处理,一般不要使用透明图层, 1). 给View添加一个固定、不透明的颜色 2). 设置opaque 属性为true 但是这对性能调优的帮助并不大,因为UIView的opaque 属性默认为true,也就是说,只要不是认为设置成透明,都不会出现图层混合 而对于UIIimageView来说,不仅需要自身需要不是透明的,它的图片也不能含有alpha通道,这也上图9张图片是绿色的原因,因此图像自身的性质也可能会对结果有影响,所以你确定自己的代码没问题,还出现了混合图层可能就是图片的问题了 而针对于屏幕中的文字高亮成红色,是因为一没有给文字的label增加不透明的背景颜色,而是当UILabel内容为中文时,label的实际渲染区域要大于label的size,因为外围有了一圈的阴影,才会出现图层混合我们需要给中文的label加上如下代码:
retweededTextLab?.layer.masksToBounds = true
retweededTextLab?.backgroundColor = UIColor.groupTableViewBackground
statusLab.layer.masksToBounds = true
statusLab.backgroundColor = UIColor.white
看下效果图:
statusLab.layer.masksToBounds = true 单独使用不会出现离屏渲染
2). 如果对label设置了圆角的话,圆角部分会离屏渲染,离屏渲染的前提是位图发生了形变
- Color Hits Green and Misses Red(光栅化缓存图层的命中情况)
这个选项主要是检测我们有无滥用或正确使用layer的shouldRasterize属性.成功被缓存的layer会标注为绿色,没有成功缓存的会标注为红色。 很多视图Layer由于Shadow、Mask和Gradient等原因渲染很高,因此UIKit提供了API用于缓存这些Layer,self.layer.shouldRasterize = true系统会将这些Layer缓存成Bitmap位图供渲染使用,如果失效时便丢弃这些Bitmap重新生成。图层Rasterization栅格化好处是对刷新率影响较小,坏处是删格化处理后的Bitmap缓存需要占用内存,而且当图层需要缩放时,要对删格化后的Bitmap做额外计算。 使用这个选项后时,如果Rasterized的Layer失效,便会标注为红色,如果有效标注为绿色。当测试的应用频繁闪现出红色标注图层时,表明对图层做的Rasterization作用不大。 在测试的过程中,第一次加载时,开启光栅化的layer会显示为红色,这是很正常的,因为还没有缓存成功。但是如果在接下来的测试,。例如我们来回滚动TableView时,我们仍然发现有许多红色区域,那就需要谨慎对待了
- Color Copied Image (拷贝的图片)
这个选项主要检查我们有无使用不正确图片格式,由于手机显示都是基于像素的,所以当手机要显示一张图片的时候,系统会帮我们对图片进行转化。比如一个像素占用一个字节,故而RGBA则占用了4个字节,则1920 x 1080的图片占用了7.9M左右,但是平时jpg或者png的图片并没有那么大,因为它们对图片做了压缩,但是是可逆的。所以此时,如果图片的格式不正确,则系统将图片转化为像素的时间就有可能变长。而该选项就是检测图片的格式是否是系统所支持的,若是GPU不支持的色彩格式的图片则会标记为青色,则只能由CPU来进行处理。CPU被强制生成了一些图片,然后发送到渲染服务器,而不是简单的指向原始图片的的指针。我们不希望在滚动视图的时候,CPU实时来进行处理,因为有可能会阻塞主线程。
- Color Immediately (颜色立即更新)
通常 Core Animation 以每秒10此的频率更新图层的调试颜色,对于某些效果来说,这可能太慢了,这个选项可以用来设置每一帧都更新(可能会影响到渲染性能,所以不要一直都设置它)
- Color Misaligned Image (图片对齐方式)
这里会高亮那些被缩放或者拉伸以及没有正确对齐到像素边界的图片,即图片Size和imageView中的Size不匹配,会使图过程片缩放,而缩放会占用CPU,所以在写代码的时候保证图片的大小匹配好imageView,如下图所示: 图片尺寸 170 * 220px
可以看到图片高亮成黄色显示,更改下imageView的大小:

let imageView = UIImageView(frame: CGRect(x: 50, y: 100, width: 85, height: 110))
imageView.image = UIImage(named: "cat")
view.addSubview(imageView)
看下效果图:

- Color Offscreen- Rendered Yellow (离屏渲染) 这里会把那些需要离屏渲染的到图层高亮成黄色,而出发离屏渲染的可能有
/* 圆角处理 */
view.layer.maskToBounds = truesomeView.clipsToBounds = true
/* 设置阴影 */
view.shadow..
/* 栅格化 */
view.layer.shouldRastarize = true
针对栅格化处理,我们需要指定屏幕的分辨率
//离屏渲染 - 异步绘制 耗电
self.layer.drawsAsynchronously = true
//栅格化 - 异步绘制之后 ,会生成一张独立的图片 cell 在屏幕上滚动的时候,本质上滚动的是这张图片
//cell 优化,要尽量减少图层的数量,想当于只有一层
//停止滚动之后,可以接受监听
self.layer.shouldRasterize = true
//使用 “栅格化” 必须指定分辨率
self.layer.rasterizationScale = UIScreen.main.scale
指定阴影的路径,可以防止离屏渲染
// 指定阴影曲线,防止阴影效果带来的离屏渲染
imageView.layer.shadowPath = UIBezierPath(rect: imageView.bounds).cgPath
这行代码制定了阴影路径,如果没有手动指定,Core Animation会去自动计算,这就会触发离屏渲染。如果人为指定了阴影路径,就可以免去计算,从而避免产生离屏渲染。 设置cornerRadius本身并不会导致离屏渲染,但很多时候它还需要配合layer.masksToBounds = true使用。根据之前的总结,设置masksToBounds会导致离屏渲染。解决方案是尽可能在滑动时避免设置圆角,如果必须设置圆角,可以使用光栅化技术将圆角缓存起来:
// 设置圆角
label.layer.masksToBounds = true
label.layer.cornerRadius = 8
label.layer.shouldRasterize = true
label.layer.rasterizationScale = layer.contentsScale
如果界面中有很多控件需要设置圆角,比如tableView中,当tableView有超过25个圆角,使用如下方法
view.layer.cornerRadius = 10
view.maskToBounds = Yes
那么fps将会下降很多,特别是对某些控件还设置了阴影效果,更会加剧界面的卡顿、掉帧现象,对于不同的控件将采用不同的方法进行处理: 1). 对于label类,可以通过CoreGraphics来画出一个圆角的label 2). 对于imageView,通过CoreGraphics对绘画出来的image进行裁边处理,形成一个圆角的imageView,代码如下:
/// 创建圆角图片
///
/// - parameter radius: 圆角的半径
/// - parameter size: 图片的尺寸
/// - parameter backColor: 背景颜色 默认 white
/// - parameter lineWith: 圆角线宽 默认 1
/// - parameter lineColor: 线颜色 默认 darkGray
///
/// - returns: image
func yw_drawRectWithRoundCornor(radius: CGFloat, size: CGSize, backColor: UIColor = UIColor.white, lineWith: CGFloat = 1, lineColor: UIColor = UIColor.darkGray) -> UIImage? {
let rect = CGRect(origin: CGPoint(x: 0, y: 0), size: size)
UIGraphicsBeginImageContextWithOptions(rect.size, true, 0)
let bezier = UIBezierPath(roundedRect: rect, byRoundingCorners: UIRectCorner.allCorners, cornerRadii: CGSize(width: radius, height: radius))
backColor.setFill()
UIRectFill(rect)
bezier.addClip()
draw(in: rect)
bezier.lineWidth = 1
lineColor.setStroke()
bezier.stroke()
let result = UIGraphicsGetImageFromCurrentImageContext()
UIGraphicsEndImageContext()
return result
}
- Color Compositing Fast-Path Blue
这个选项会对任何直接使用OpenGL绘制的图层进行高亮,如果仅仅使用UIKit或者Core Animation的API,不会有任何效果
- Flash Updated Regions (Core Graphics 绘制的图层) 此选项会对重绘的内容进行高亮成黄色,也就是软件层面使用Core Graphics 绘制的图层。
1.2.4.5 Leaks
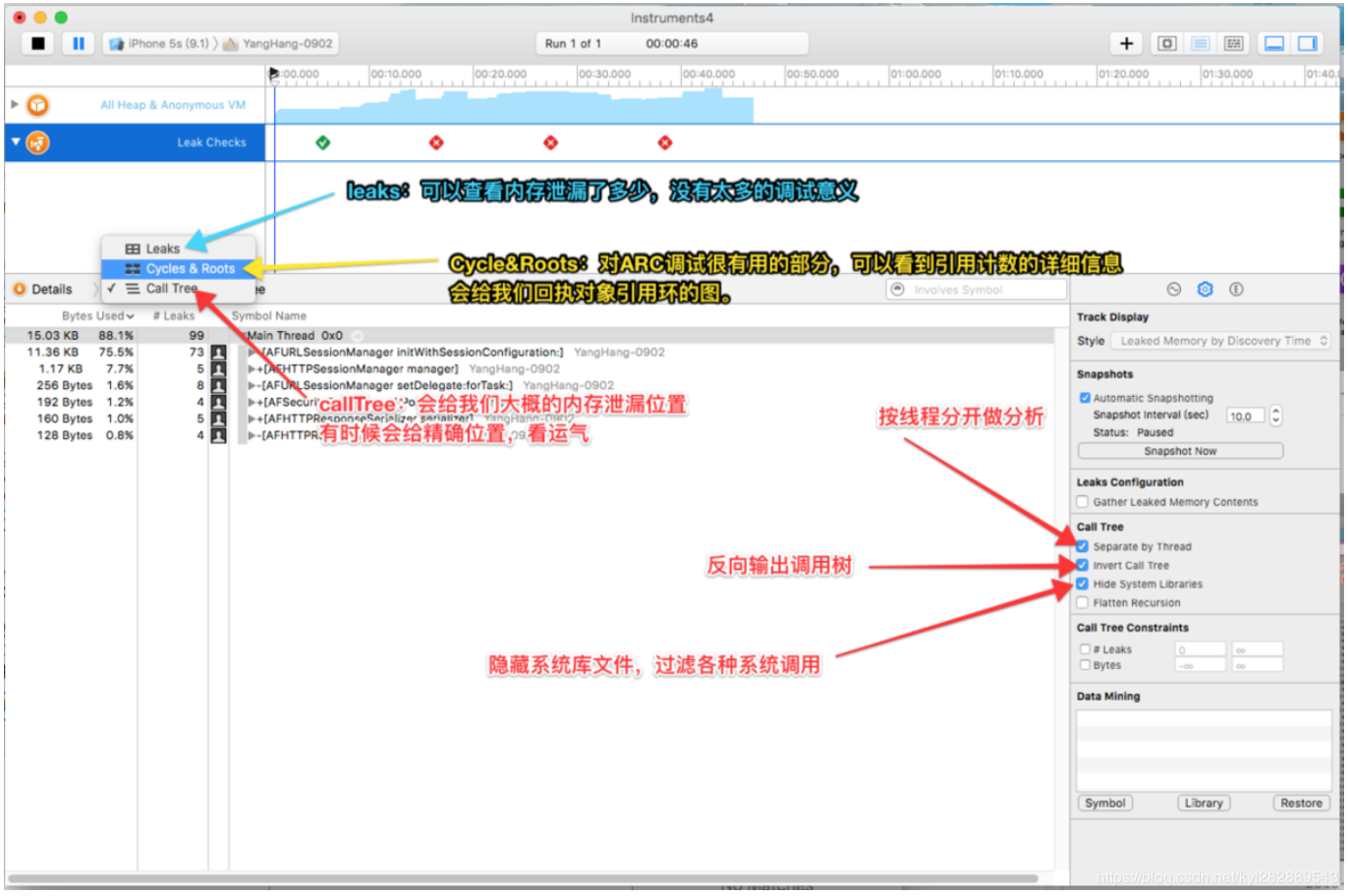
Leaks主要用来检查内存泄漏,在前面Allcations里面我们提到内存泄漏分两种,现在我们研究Leaked Memory, 从用户使用角度来看,内存泄漏本身不会产生什么危害,作为用户,根本感觉不到内存泄漏的存在,真正的危害在于内存泄漏的堆积,最终会耗尽系统所有的内存。我们直接看图:
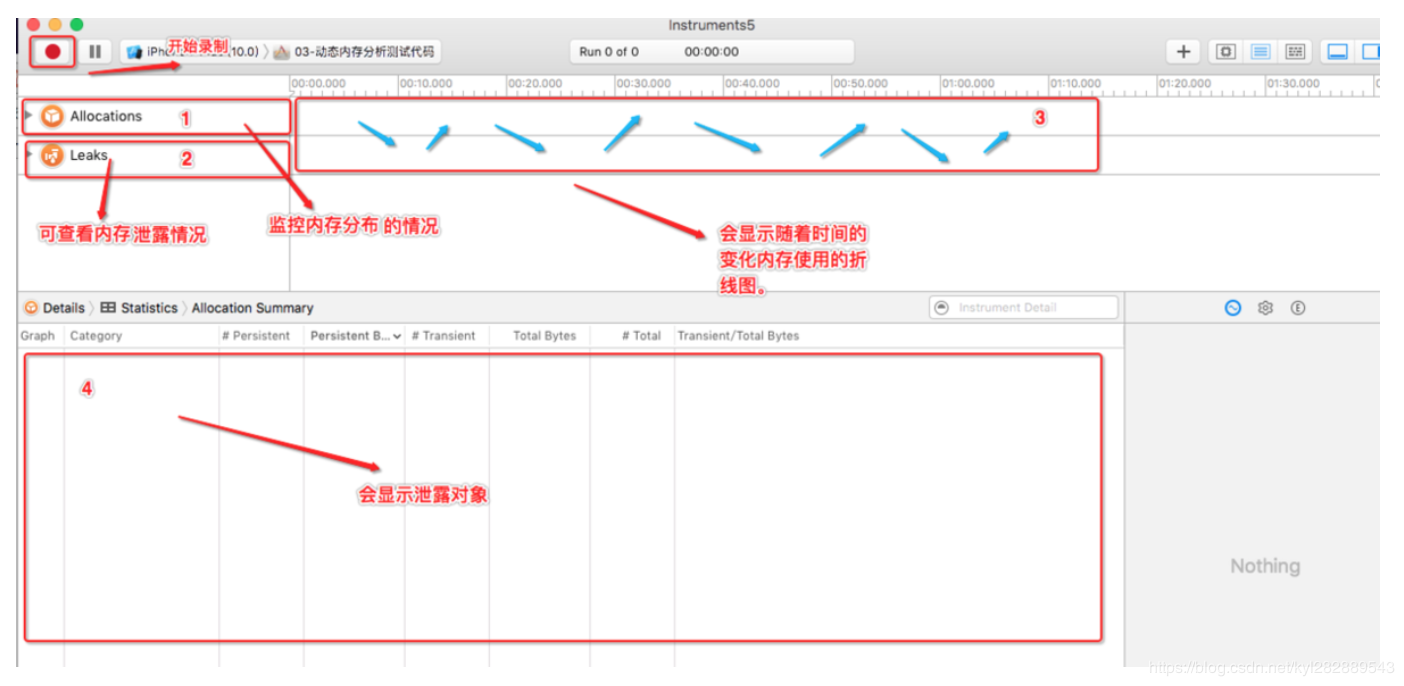
instruments 中,虽然选择了 Leaks 模板,但默认情况下也会添加 Allocations 模板.基本上凡是内存分析都会使用 Allocations 模板, 它可以监控内存分布情况。
选中 Allocations 模板3区域会显示随着时间的变化内存使用的折线图,同时在4区域会显示内存使用的详细信息,以及对象分配情况.
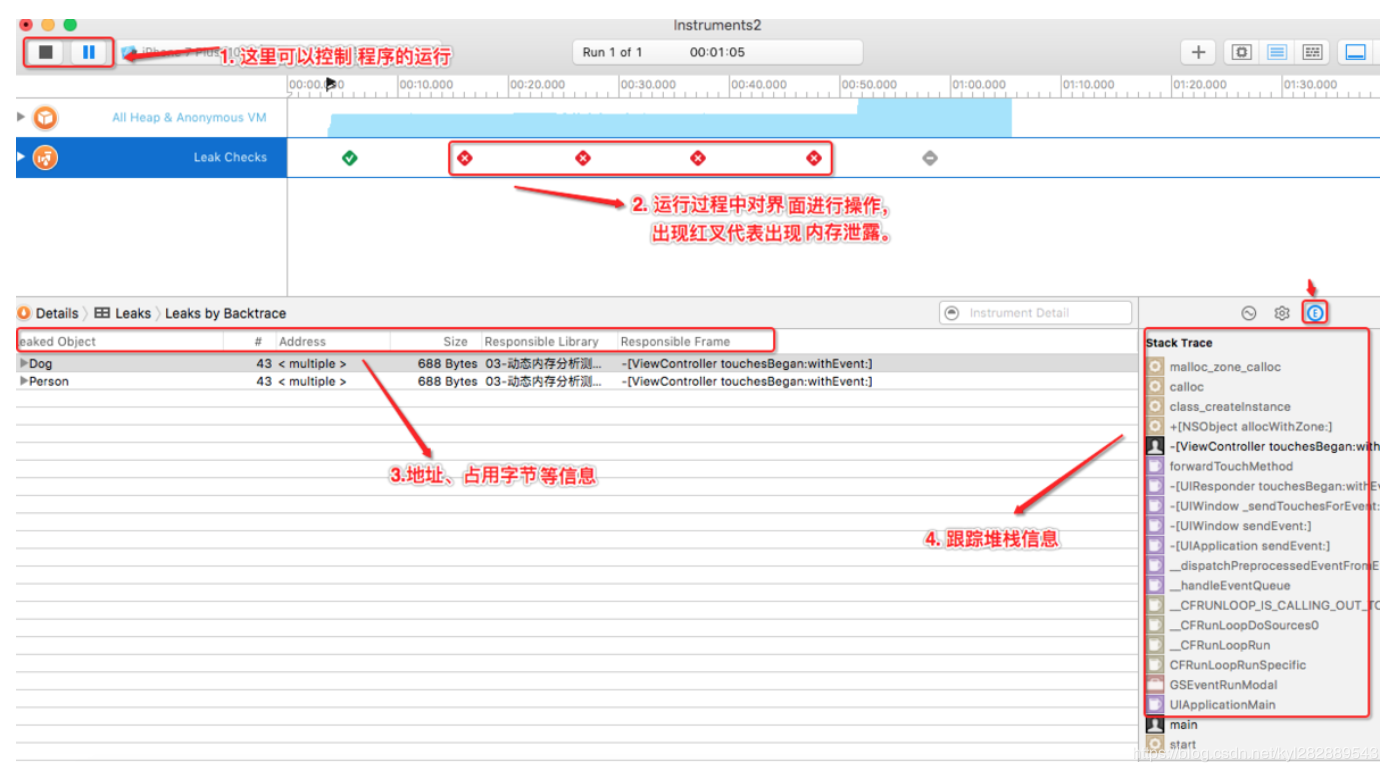
点击 Leaks 模板, 可以查看内存泄露情况。如果在3区域有 红X 出现, 则有内存泄露, 4区域则会显示泄露的对象.
打用leaks进行监测:点击泄露对象可以在(下图)看到它们的内存地址, 占用字节, 所属框架和响应方法等信息.打开扩展视图, 可以看到右边的跟踪堆栈信息,4 黑色代码最有可能出现内存泄漏的方法
监测结果的分析:
1.2.4.6 Time Profiler
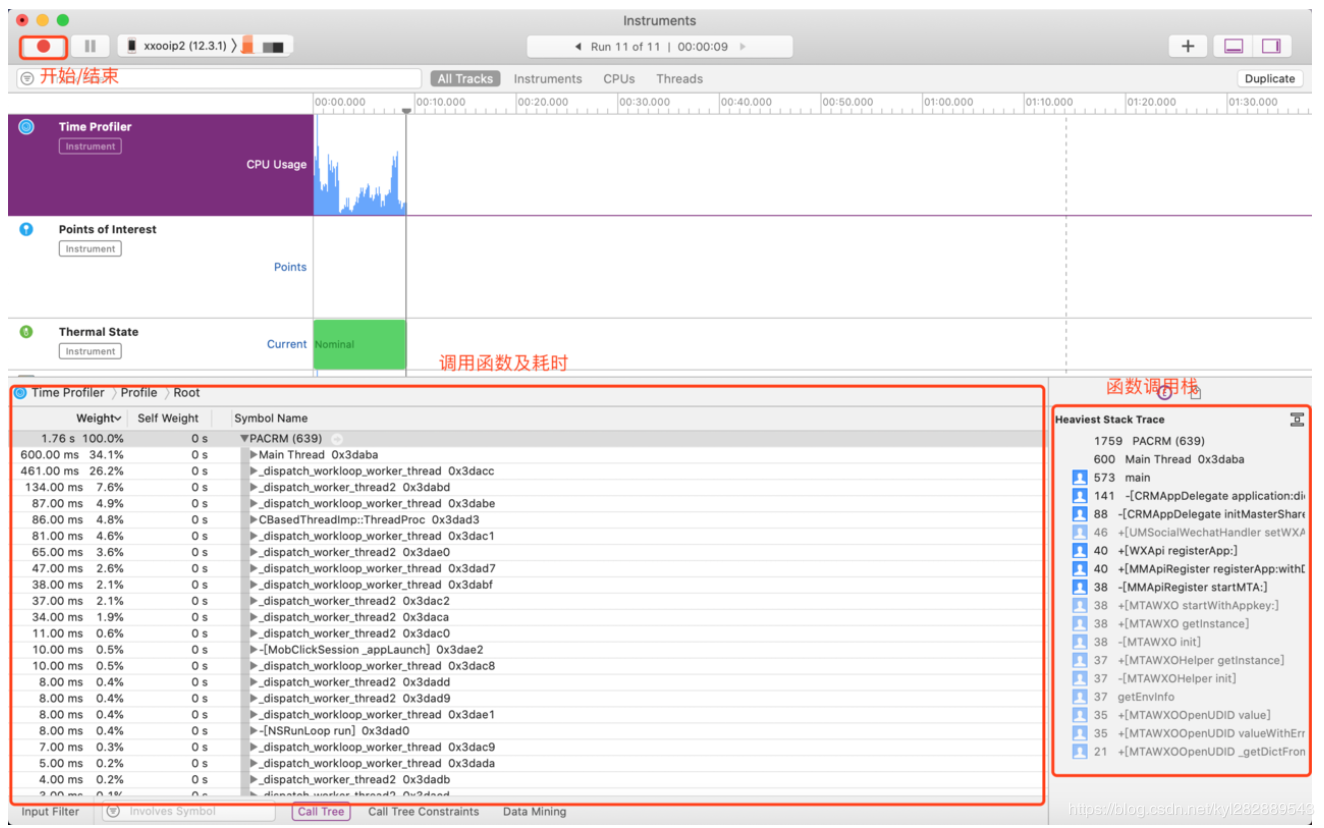
Time Profiler是Xcode自带的工具,原理是定时抓取线程的堆栈信息,通过统计比较时间间隔之间的堆栈状态,计算一段时间内各个方法的近似耗时。精确度取决于设置的定时间隔。
通过 Xcode → Open Developer Tool → Instruments → Time Profiler 打开工具,注意,需将工程中 Debug Information Format 的 Debug 值改为 DWARF with dSYM File,否则只能看到一堆线程无法定位到函数。
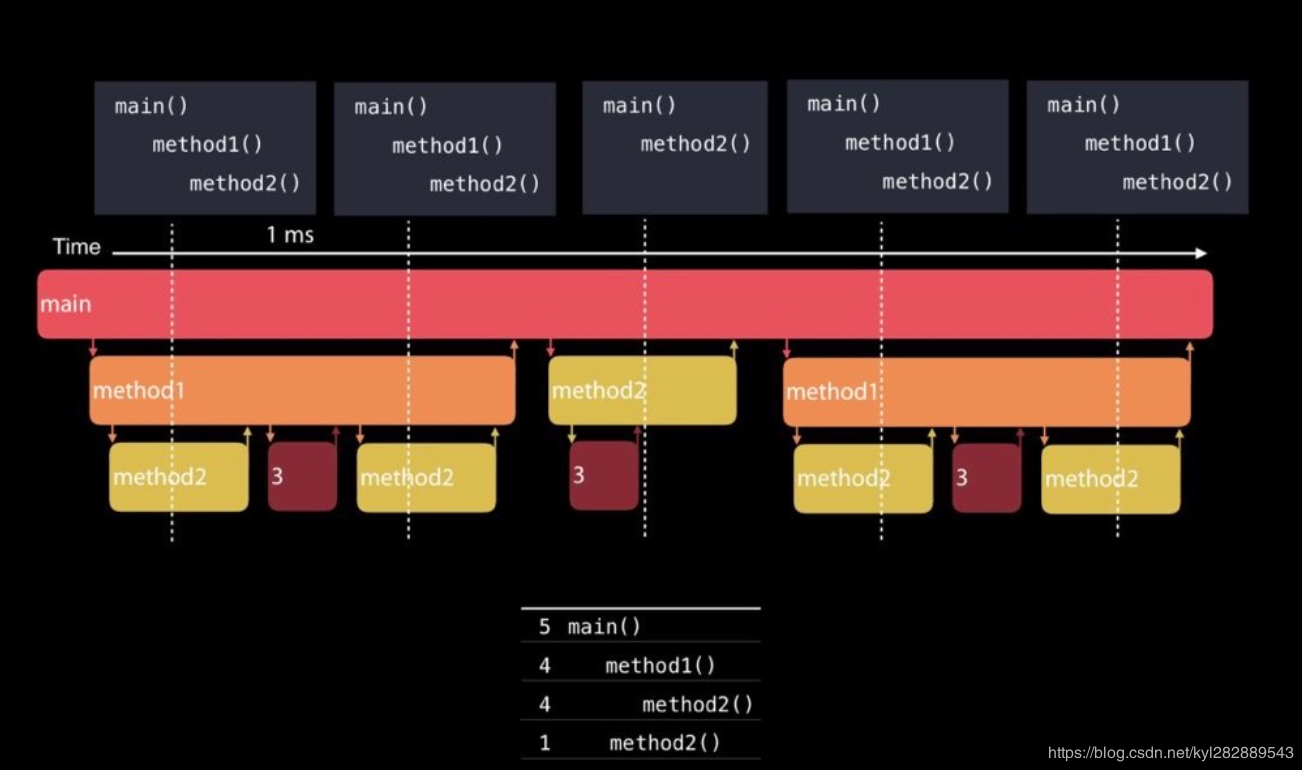
正常Time Profiler是每1ms采样一次, 默认只采集所有在运行线程的调用栈,最后以统计学的方式汇总。所以会无法统计到耗时过短的函数和休眠的线程,比如下图中的5次采样中,method3都没有采样到,所以最后聚合到的栈里就看不到method3。
我们可以将 File -> Recording Options 中的配置调高,即可获取更精确的调用栈。
- System Trace 有时候当主线程被其他线程阻塞时,无法通过 Time Profiler 一眼看出,我们还可以使用 System Trace,例如我们故意在 dyld 链接动态库后的回调里休眠10ms:
static void add(const struct mach_header* header, intptr_t imp) {
usleep(10000);
}
- (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launchOptions
{
dispatch_sync(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
_dyld_register_func_for_add_image(add);
});
....
}
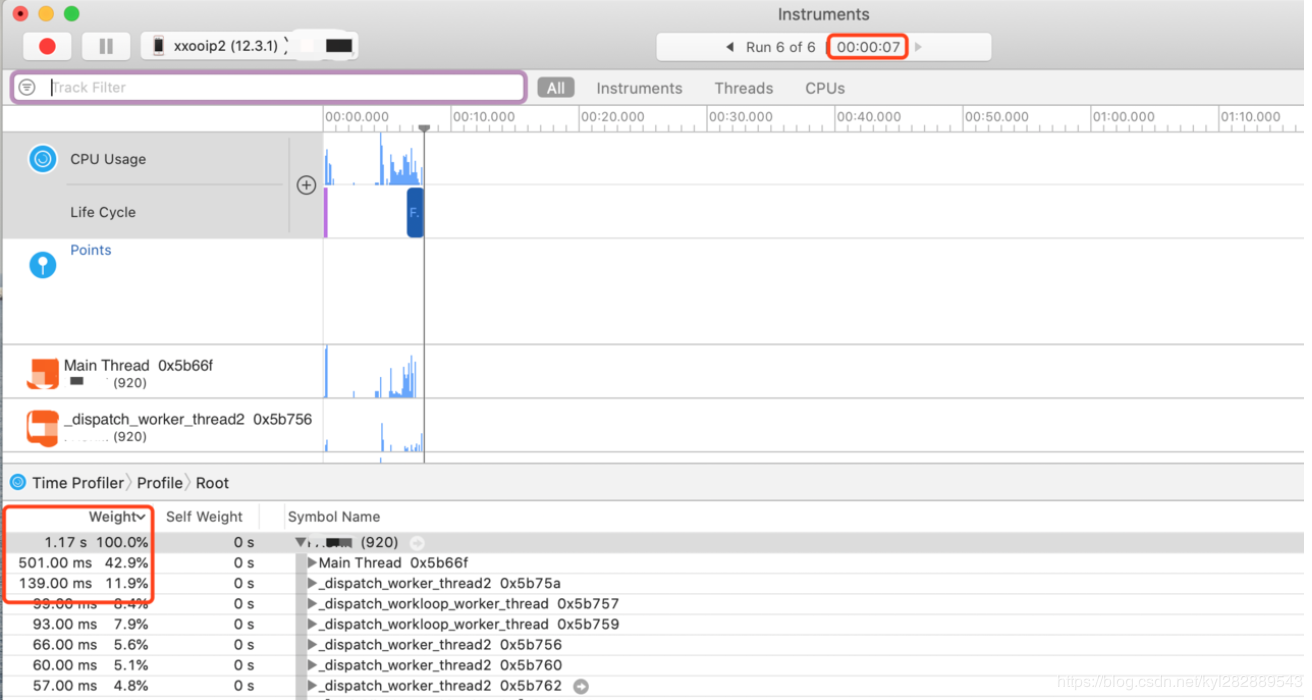
可以看到整个记录过程耗时7s,但 Time Profiler 上只显示了1.17s,且看到启动后有一段时间是空白的。这时通过 System Trace 查看各个线程的具体状态。
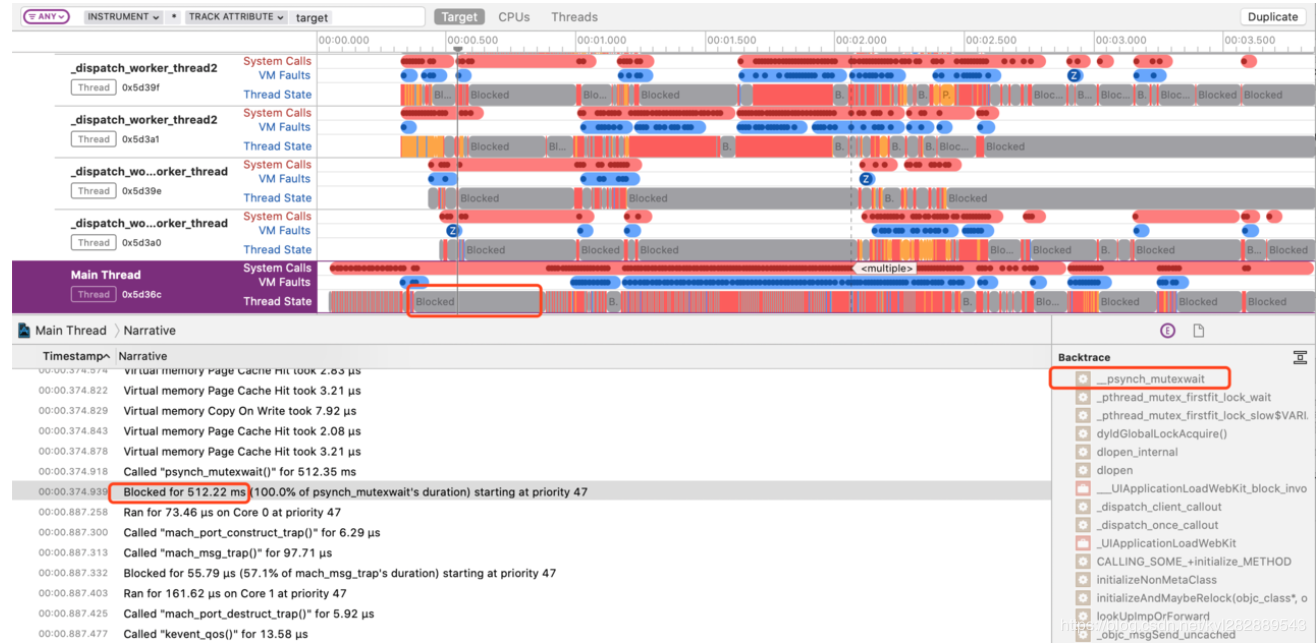
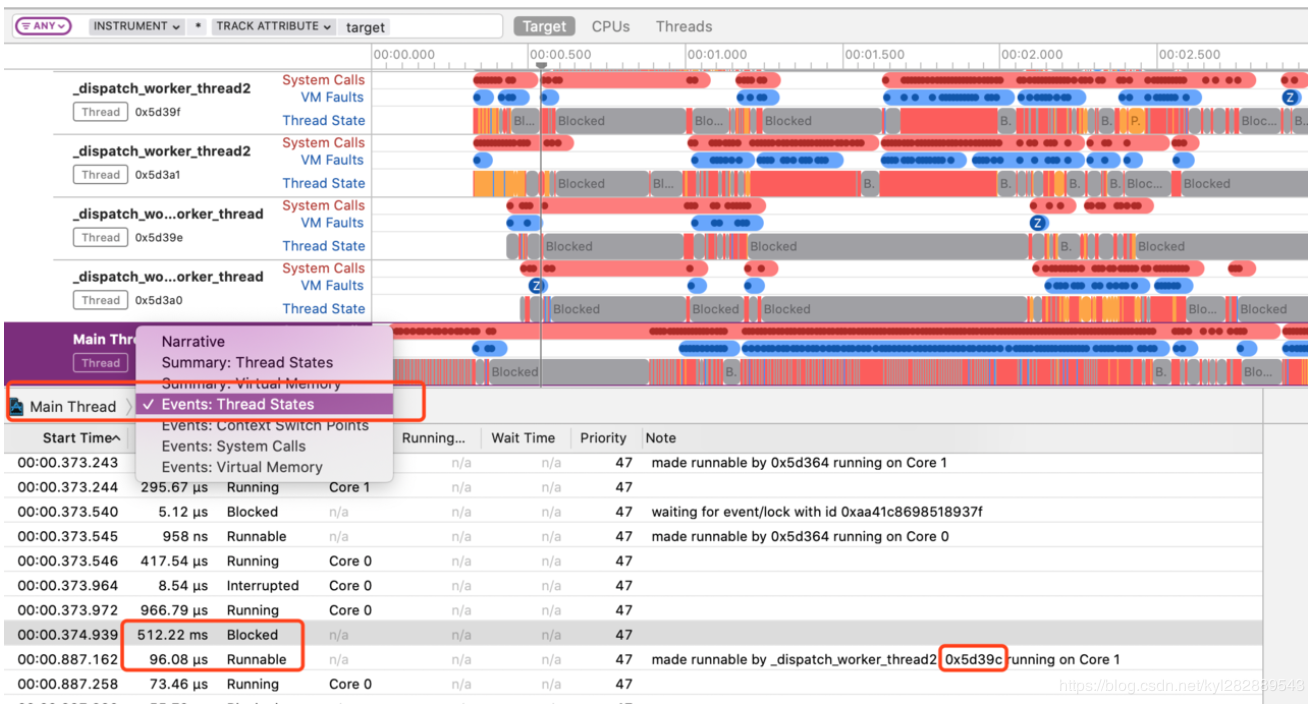
接着我们观察 0x5d39c 线程,发现在主线程阻塞的这段时间,该线程执行了多次10ms的 sleep 操作,到此就找到了主线程被子线程阻塞导致启动缓慢的原因。
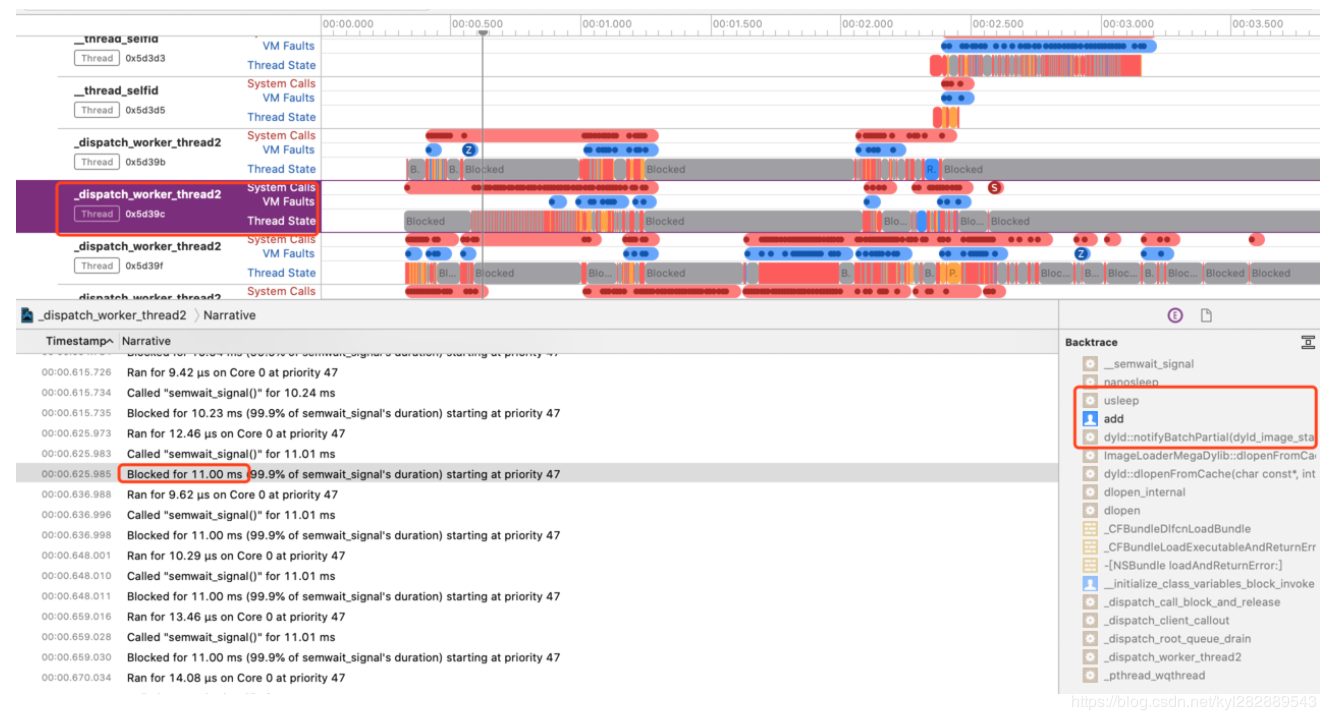
今后,当我们想更清楚的看到各个线程之间的调度就可以使用 System Trace,但还是建议优先使用 Time Profiler,使用简单易懂,排查问题效率更高。
1.2.4.7 App Launch
App Launch是Xcode11 之后新出的工具,功能相当于 Time Profiler 和 System Trace 的整合。
1.2.4.8 Hook objc_msgSend
可以对 objc_msgSend 进行 Hook 获取每个函数的具体耗时,优化在启动阶段耗时多的函数或将其置后调用。实现方法可查看笔者之前的文章 通过objc_msgSend实现iOS方法耗时监控。
1.2.5 关于卡顿有关的面试题解析
- 遇到tableView卡顿嘛?会造成卡顿的原因大致有哪些?
可能造成
tableView卡顿的原因有:
- 最常用的就是
cell的重用, 注册重用标识符 如果不重用cell时,每当一个cell显示到屏幕上时,就会重新创建一个新的cell; 如果有很多数据的时候,就会堆积很多cell。 如果重用cell,为cell创建一个ID,每当需要显示cell 的时候,都会先去缓冲池中寻找可循环利用的cell,如果没有再重新创建cell- 避免
cell的重新布局cell的布局填充等操作 比较耗时,一般创建时就布局好 如可以将cell单独放到一个自定义类,初始化时就布局好- 提前计算并缓存
cell的属性及内容 当我们创建cell的数据源方法时,编译器并不是先创建cell 再定cell的高度 而是先根据内容一次确定每一个cell的高度,高度确定后,再创建要显示的cell,滚动时,每当cell进入可视区域都会计算高度,提前估算高度告诉编译器,编译器知道高度后,紧接着就会创建cell,这时再调用高度的具体计算方法,这样可以方式浪费时间去计算显示以外的cell- 减少
cell中控件的数量 尽量使cell得布局大致相同,不同风格的cell可以使用不用的重用标识符,初始化时添加控件, 不适用的可以先隐藏- 不要使用
ClearColor,无背景色,透明度也不要设置为0 渲染耗时比较长- 使用局部更新 如果只是更新某组的话,使用
reloadSection进行局部更新- 加载网络数据,下载图片,使用异步加载,并缓存
- 少使用
addView给cell动态添加view- 按需加载cell,cell滚动很快时,只加载范围内的cell
- 不要实现无用的代理方法,
tableView只遵守两个协议- 缓存行高:
estimatedHeightForRow不能和HeightForRow里面的layoutIfNeed同时存在,这两者同时存在才会出现“窜动”的bug。所以我的建议是:只要是固定行高就写预估行高来减少行高调用次数提升性能。如果是动态行高就不要写预估方法了,用一个行高的缓存字典来减少代码的调用次数即可- 不要做多余的绘制工作。 在实现
drawRect:的时候,它的rect参数就是需要绘制的区域,这个区域之外的不需要进行绘制。例如上例中,就可以用CGRectIntersectsRect、CGRectIntersection或CGRectContainsRect判断是否需要绘制image和text,然后再调用绘制方法。- 预渲染图像。 当新的图像出现时,仍然会有短暂的停顿现象。解决的办法就是在
bitmap context里先将其画一遍,导出成UIImage对象,然后再绘制到屏幕;- 使用正确的数据结构来存储数据。
1.3 耗电优化
1.4 网络优化
1.5 crash问题优化
1.6 内存问题优化
1.7 安装包塑身问题优化
绘制像素到屏幕上 iOS图形原理与离屏渲染 iOS 保持界面流畅的技巧 Advanced Graphics and Animations for iOS Apps(session 419) 使用 ASDK 性能调优 - 提升 iOS 界面的渲染性能 Designing for iOS: Graphics & Performance iOS离屏渲染之优化分析 iOS视图渲染以及性能优化总结 iOS 离屏渲染 深刻理解移动端优化之离屏渲染 iOS 流畅度性能优化、CPU、GPU、离屏渲染 离屏渲染优化详解:实例示范+性能测试
iOS 官方文档
专题内容比较多,后面细分内容会有部分重复。
iOS 性能优化相关书籍
- Pro iOS Apps Performance Optimization
- High Performance iOS Apps
- iOS-Core-Animation-Advanced-Techniques
Instruments 工具相关
- Instruments User Guide 中文翻译-PDF
- Instruments之Leaks学习
- Instruments学习之Allocations
- instrument之Time Profiler总结
- Instruments学习之Core Animation学习
- Instruments之Activity Monitor使用入门
GMTC-2018 PPT
性能优化
- WWDC2012-235-iOS APP Performance:Responsiveness
- 微信读书iOS性能优化
- 微信读书 iOS 质量保证及性能监控
- 深入剖析 iOS 性能优化
- 魔窗研发副总裁沈哲:移动端SDK的优化之路
- 搜狗输入法 iOS 版开发与优化实践PPT
- 蘑菇街 App 的稳定性与性能实践PPT
- ⼿淘iOS性能优化探索
- iOS App 稳定性指标及监测
内存优化
- Memory Usage Performance Guidelines
- WWDC-2018-416中文翻译
- 探索iOS内存分配
- iOS微信内存监控
- 内存管理及优化(上)-QQ浏览器
- 内存管理及优化(下)-QQ浏览器
- OOM探究:XNU 内存状态管理
卡顿优化
- UIKit性能调优实战讲解
- QQ空间掉帧率优化实战
- 实现 60fps 的网易云音乐首页
- iOS 保持界面流畅的技巧
- iOS UI性能优化总结
- 微信iOS卡顿监控系统
- iOS-卡顿检测
- iOS监控:卡顿检测
- iOS应用UI线程卡顿监控
电量优化
- Guide - Energy Efficiency Guide for iOS Apps
- WWDC2017 - Writing Energy Efficient Apps
- iOS 常见耗电量检测方案调研
- 教你开发省电的 iOS app(WWDC17 观后)
- 浅析移动蜂窝网络的特点及其省电方案
- iOS电量测试实践
- iOS进阶--App功耗优化看这篇就够了
启动优化
- WWDC2016-406-Optimizing App Startup Time
- WWDC2017-413-App Startup Time:Past,Present,and Future
- 如何精准度量iOSAPP启动时间
- 优化 App 的启动时间-杨萧玉
- iOS客户端启动速度优化-今日头条
- iOS App 启动性能优化-WiFi管家
- iOS App如何优化启动时间-Facebook
- iOS 启动速度优化-百度输入法
- 一次立竿见影的启动时间优化
- obj中国-Mach-O 可执行文件
- iOS app启动速度研究实践
- iOS App冷启动治理:来自美团外卖的实践
体积优化
- iOS微信安装包瘦身
- 今日头条IPA安装包的优化
- iOS瘦身之删除FrameWork中无用mach-O文件
- 基于clang插件的一种iOS包大小瘦身方案
- iOS可执行文件瘦身方法
- iOS图片优化方案
- 滴滴出行 iOS 端瘦身实践的 Slides
网络优化
- 美团点评移动网络优化实践
- 开源版HttpDNS方案详解
- 携程App的网络性能优化实践
- 2016年携程App网络服务通道治理和性能优化实践
- 蘑菇街App Chromium网络栈实践
- 蘑菇街高并发多终端无线网关实践
- 移动 APP 网络优化概述
编译优化
APM
- 移动端监控体系之技术原理剖析
- 网易 - NeteaseAPM iOS SDK技术实现分享
- 网易乐得 - iOS无埋点数据SDK实践之路
- 听云 - 移动端 APM 产品研发技能
- 听云 - 移动 App 性能监测
- iOS 性能监控 SDK —— Wedjat(华狄特)开发过程的调研和整理
- 揭秘 APM iOS SDK 的核心技术
- iOS-Monitor-Resources
- iOS 流量监控分析
- 小试Xcode逆向:app内存监控原理初探
- APMCon-2016演讲实录
- 360移动端性能监控实践QDAS-APM(iOS篇)
- 移动端性能监控方案Hertz
