

宏任务、微任务
对JS的运行机制的理解,接着之前一篇JS核心理论之《JS引擎、运行时与调用椎栈》中的运行时概念。 更进一步讲,JS中任务类型分为两种:宏任务与微任务。宏任务与微任务各自维护着一个消息队列。
-
宏任务,macrotask,又称为task,可以理解为每次执行栈执行的代码就是一个宏任务(包括每次从事件队列中获取一个事件回调并放到执行栈中执行)。
包括:script(整个代码块),I/O,xhr,setTimeout,setInterval,setImmediate(仅Node),requestAnimationFrame(仅浏览器),UI交互事件, postMessage, MessageChannel
-
微任务,microtask,又称为job,可以理解是在当前 task 执行结束后立即执行的任务。
包括:Promise.then catch finally, await后面代码,process.nextTick(仅Node),MutationObserver(仅浏览器)
注意:new Promise在实例化的过程中所执行的代码都是同步进行的,而then中注册的回调才是异步执行的。 async/await底层是基于Promise封装的,所以await前面的代码相当于new Promise,是同步进行的,await后面的代码相当于then,才是异步进行的。
为了更好地理解宏任务与微任务,我们将事件循环比喻成银行柜台办理业务。每一个排队办业务的人理解为宏任务,而他除了主要业务外,还有一些零碎的其它业务,比如 咨询等,理解为微任务。
运行机制
Event Loop:JavaScript是单线程脚本语言,同一时间不能处理多个任务,所以何时执行宏任务,何时执行微任务?我们需要有这样的一个判断逻辑存在。这个判断逻辑被称为事件循环。
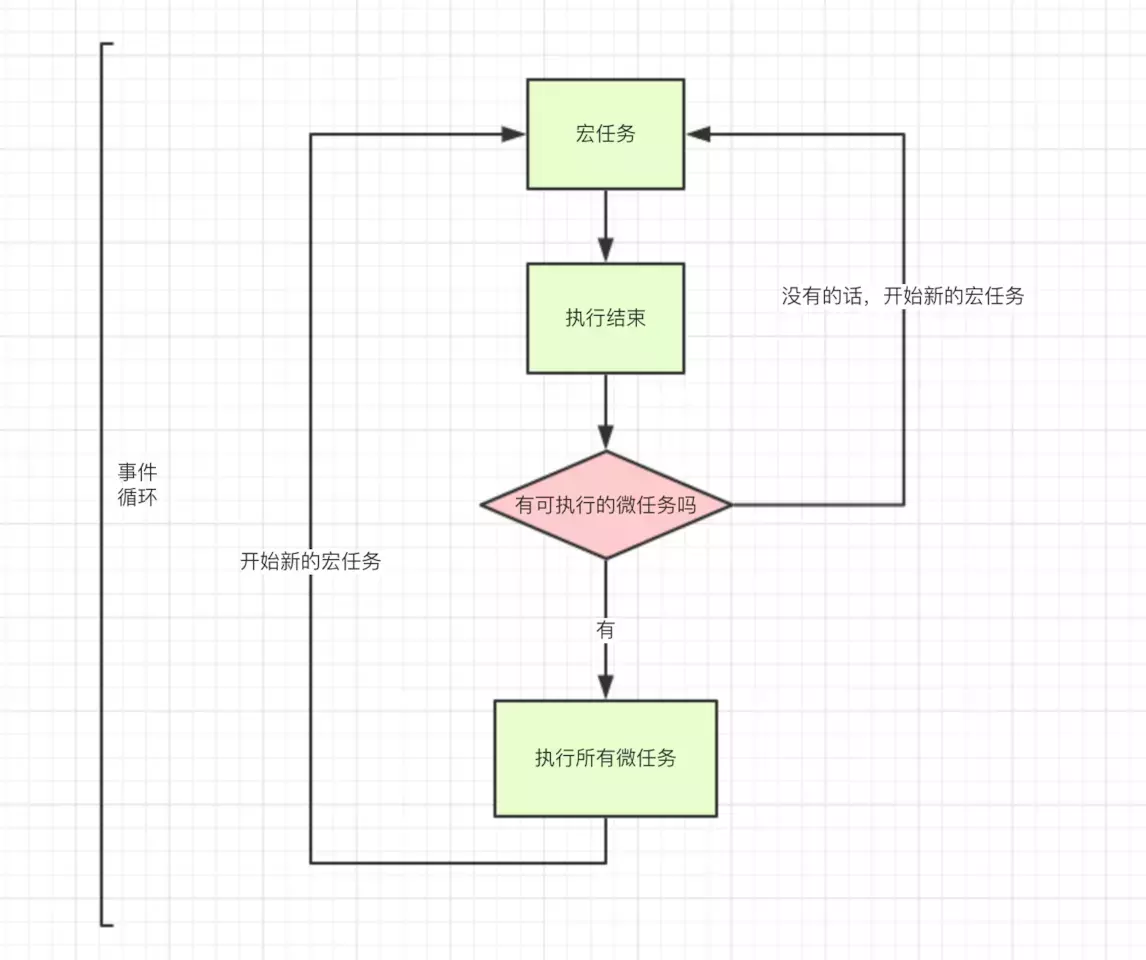
事件循环的过程如下:
- JS引擎(唯一主线程)按顺序解析代码,遇到函数声明,直接跳过,遇到函数调用,入栈;
- 如果是同步函数调用,直接执行得到结果,同步函数弹出栈,继续下一个函数调用;
- 如果是异步函数调用,分发给Web API(多个辅助线程),异步函数弹出栈,继续下一个函数调用;
- Web API中,异步函数在相应辅助线程中处理完成后,即异步函数达到触发条件了(比如setTimeout设置的10s后),如果异步函数是宏任务,则入宏任务消息队列,如果是微任务,则入微任务消息队列;
- Event Loop不停地检查主线程的调用栈与回调队列,当调用栈空时,就把微任务消息队列中的第一个任务推入栈中执行,执行完成后,再取第二个微任务,直到微任务消息队列为空;然后 去宏任务消息队列中取第一个宏任务推入栈中执行,当该宏任务执行完成后,在下一个宏任务执行前,再依次取出微任务消息队列中的所有微任务入栈执行。
- 上述过程不断循环,每当微任务队列清空,可作为本轮事件循环的结束。
有几个关键点如下:
- 所有微任务总会在下一个宏任务之前全部执行完毕,宏任务必然是在微任务之后才执行的(因为微任务实际上是宏任务的其中一个步骤)。
- 宏任务按顺序执行,且浏览器在每个宏任务之间渲染页面
- 所有微任务也按顺序执行,且在以下场景会立即执行所有微任务
- 每个回调之后且js执行栈中为空。
- 每个宏任务结束后。
const macroList = [
['task1'],
['task2', 'task3'],
['task4'],
]
for (let macroIndex = 0; macroIndex < macroList.length; macroIndex++) {
const microList = macroList[macroIndex]
for (let microIndex = 0; microIndex < microList.length; microIndex++) {
const microTask = microList[microIndex]
// 再添加一个微任务
if (microIndex === 1) microList.push('special micro task')
// 执行任务
console.log(microTask)
}
// 再添加一个宏任务
if (macroIndex === 2) macroList.push(['special macro task'])
}
// > task1
// > task2
// > task3
// > special micro task
// > task4
// > special macro task
我们通过几个示例来加深一下理解:
setTimeout(_ => console.log(4))
new Promise(resolve => {
resolve()
console.log(1)
}).then(_ => {
console.log(3)
})
console.log(2)
流程如下:
- 整体script作为第一个宏任务进入主线程,遇到setTimeout入栈处理,发现是异步函数(宏任务),出栈,移交给Web API处理,0秒等待后,将回调函数加到宏任务队列尾部;
- 遇到new Promise,入栈处理,发现是同步任务,直接执行,console输出1;
- 遇到then,入栈处理,发现是异步函数(微任务),出栈,移交给Web API处理,将回调函数加入微任务队列尾部;
- 遇到console.log(2),入栈处理,同步任务,直接console输出2, 出栈;
- 栈已清空,检查微任务队列;
- 取出第一个回调函数,入栈处理,发现是同步任务,直接console输出3, 出栈;
- 继续从取微任务队列中取下一个,发现微任务队列已清空,结束第一轮事件循环;
- 从宏任务队列中取出第一个宏任务,入栈处理,发现是同步任务,直接console输出4;
所以,最终输出结果为:1 > 2 > 3 > 4
我们先稍微改变一下:
setTimeout(_ => console.log(4))
new Promise(resolve => {
resolve()
console.log(1)
}).then(_ => {
console.log(3)
Promise.resolve().then(_ => {
console.log('before timeout')
}).then(_ => {
Promise.resolve().then(_ => {
console.log('also before timeout')
})
})
})
console.log(2)
最终输出结果为:1 > 2 > 3 > before timeout > also before timeout > 4
before timeout与also before timeout在4之前输出的原因是,在微任务执行的过程中,新产生的微任务会被直接添加到微任务队列尾部,并在下一宏任务执行之前,全部执行掉。 而如果在微任务执行的过程中,新产生了宏任务,则会进入到宏任务队列尾部,按照宏任务顺序在后面的事件循环中执行。
再来看一个嵌套的示例:
Promise.resolve().then(()=>{
console.log('Promise1')
setTimeout(()=>{
console.log('setTimeout2')
},0)
})
setTimeout(()=>{
console.log('setTimeout1')
Promise.resolve().then(()=>{
console.log('Promise2')
})
},0)
最后输出结果是Promise1 > setTimeout1 > Promise2 > setTimeout2
- 一开始执行栈的同步任务执行完毕,会去 microtasks queues 找,清空 microtasks queues ,输出Promise1,同时会生成一个异步任务 setTimeout1
- 去宏任务队列查看此时队列是 setTimeout1 在 setTimeout2 之前,因为setTimeout1执行栈一开始的时候就开始异步执行,所以输出 setTimeout1
- 在执行setTimeout1时会生成Promise2的一个 microtasks ,放入 microtasks queues 中,接着又是一个循环,去清空 microtasks queues ,输出 Promise2
- 清空完 microtasks queues ,就又会去宏任务队列取一个,这回取的是 setTimeout2
最后来一个复杂的示例,检测一下是否真正掌握了事件循环的机制。
console.log('1');
setTimeout(function() {
console.log('2');
process.nextTick(function() {
console.log('3');
})
new Promise(function(resolve) {
console.log('4');
resolve();
}).then(function() {
console.log('5')
})
})
process.nextTick(function() {
console.log('6');
})
new Promise(function(resolve) {
console.log('7');
resolve();
}).then(function() {
console.log('8')
})
setTimeout(function() {
console.log('9');
process.nextTick(function() {
console.log('10');
})
new Promise(function(resolve) {
console.log('11');
resolve();
}).then(function() {
console.log('12')
})
})
最终的输出结果为1,7,6,8,2,4,3,5,9,11,10,12。和你的答案一致吗?
Node中事件循环
关于Node详细内容会在后面篇章中专门讲解,这里只作简单介绍。 Node用V8作为js的解析引擎,而I/O处理方面使用了自己设计的libuv,libuv是一个基于事件驱动的跨平台抽象层,封装了不同操作系统一些底层特性,对外提供统一的API,事件循环机制也是它里面的实现。 Node也是单线程,但是在处理Event Loop上与浏览器稍微有些不同。
setImmediate为一次Event Loop执行完毕后立刻调用。 setTimeout则是通过计算一个延迟时间后进行执行。
所以如下示例,不能保证输出顺序。
setTimeout(_ => console.log('setTimeout'))
setImmediate(_ => console.log('setImmediate'))
而如果是下面这样,则一定是setImmediate先输出。
setTimeout(_ => console.log('setTimeout'), 20)
setImmediate(_ => console.log('setImmediate'))
process.nextTick方法可以在当前"执行栈"的尾部----下一次Event Loop(主线程读取"任务队列")之前----触发回调函数。也就是说,它指定的任务总是发生在所有异步任务之前。 process.nextTick和setImmediate的一个重要区别:多个process.nextTick语句总是在当前"执行栈"一次执行完,多个setImmediate可能则需要多次loop才能执行完。 事实上,这正是Node.js 10.0版添加setImmediate方法的原因,否则像下面这样的递归调用process.nextTick,将会没完没了,主线程根本不会去读取"事件队列"!
process.nextTick(function foo() {
process.nextTick(foo);
});
