

我是风筝,公众号「古时的风筝」,一个不只有技术的技术公众号,一个在程序圈混迹多年,主业 Java,另外 Python、React 也玩儿的 6 的斜杠开发者。 Spring Cloud 系列文章已经完成,可以到 我的 github 上查看系列完整内容。也可以在公众号内回复「pdf」获取我精心制作的 pdf 版完整教程。
话说那天中午吃饭的时候,一个同事说:“那个项目组的人快气死我了,程序有问题,早晨在群里@了他们,到中午才回消息,然后竟然还说他们的程序没有问题,是我们这边调用的太频繁了。简直想笑。”
一般来说,对接出现问题,如果不是错误太明显,我首先都会先怀疑是不是自己出了问题,以免到时候丢人。所以我说,吃完饭回去我帮你排查一下,看问题到底出在哪里。
背景说明
我们当前这个系统和很多的第三方系统做了集成,出问题的就是其中一个三方系统。其实很简单,他们的系统会产生一些个人待办任务,然后待办任务的个数需要推送到我们的 APP 上,作为图标的角标显示。
用户数据已经打通,其实很简单的需求,角标通知也不要求实时,10分钟刷一次就可以。这个场景非常典型,用消息队列再合适不过了。他们把数据推到消息队列,我们去消息队列取,完美。
可现实并不是这样,他们说系统是产品化,不支持消息队列,只能把待办任务接口开放出来。好的(微笑脸),你们是产品你们有理。可能有待办任务的用户不多,300多个,那就每隔 10 分钟请求 300 多次请求呗。也没用多线程,就是简单的循环 300 多次请求,每次耗时差不多的1分钟。
也可以,那就这样呗。
顺便说一下,这个服务的 JDK 是 1.6 版本,据说由于历史原因,现在已经不敢升级了。而且,服务要部署在 windows 上。(你说神奇不神奇)
花明柳暗
那就这样呗,做个定时任务,10分钟咔咔请求个 300 来次,也挺过瘾,也挺省心。

但是好景不长,天不遂人愿,服务器不遂程序员愿。
以下是同事的经历,我转述以下。
就在定时任务跑起来后的第二个晚上,那本来该是一个平常的晚上,可是告警邮件扰人清梦。一看日志,内存使用空间过高,撑爆了,导致机器自动重启了。windows 就这点好啊,还会自动重启(尴尬脸)。然后手动上去把服务启动起来,解决。
隔了一天,还是晚上,又报警了,服务器又自动重启了,又是内存使用空间过高。又手动上去把服务启动了。
于是他反馈给这个服务的开发人员,结果得到的回复是:“我们的服务没有问题,肯定是你们的调用有问题,你们把定时任务停掉肯定就好了,所以是你们的问题”。
于是,他过来找我,跟我说明情况,问我可能会是什么问题。
我:你确定定时服务是 10 分钟一次,没有出现死循环吗?
同事:确定。
我:那他们的服务有使用 redis 之类的外部缓存吗?
同事:不知道。
我:。。。 既然你确定你调用的没问题,那肯定是他们程序出现问题把内存撑爆了呀,这有什么好怀疑的,让他们改吧。
同事:他们现在说自己没问题啊。
挖出真凶
好吧,既然他们说没问题,那我就来帮他把问题找出来吧。于是,远程进了那台 windows 服务器。
这时候已经把定时任务已经跑了两天了,16G 的内存已经用掉 15G 多了,眼看随时有可能崩溃,然后把定时任务停掉,内存使用量也并不会下来。
我开始怀疑是不是用了 redis 之类的外部缓存,结果进服务器一查 redis 、memcached 之类的压根儿就没装,所以排除外部缓存。(随后使用 JVM 工具查看也证明了这一点)
那既然不是外部缓存,那肯定出在 JVM 上了,要不然就是用了 JVM 缓存,要不然就是内存泄漏什么的。于是我想用 jinfo -flags看一下 JVM 初始参数,JDK 6 竟然还不支持 -flags 。
然后我不知道是不是尝试了 jmap -heap 还是就看了一眼 jmap -help以为不支持 jamp -heap,反正最后我是通过 jconsole来观察的 JVM。一看 JVM 参数明显就是默认没特殊设置过,并且奇怪的是对内存一共采用了 700 多M。700M 和 15G 比,差哪儿去了,没道理啊,问题没出在堆上。
然后我尝试执行 GC 操作,然而并没有任何改善。直到这里,我严重怀疑是出现了内存泄漏了。
于是我执行了 jmap -dump,把堆、线程信息 dump 下来,然后拉到本地分析。不看不知道,一看吓一跳,线程多到令人窒息。
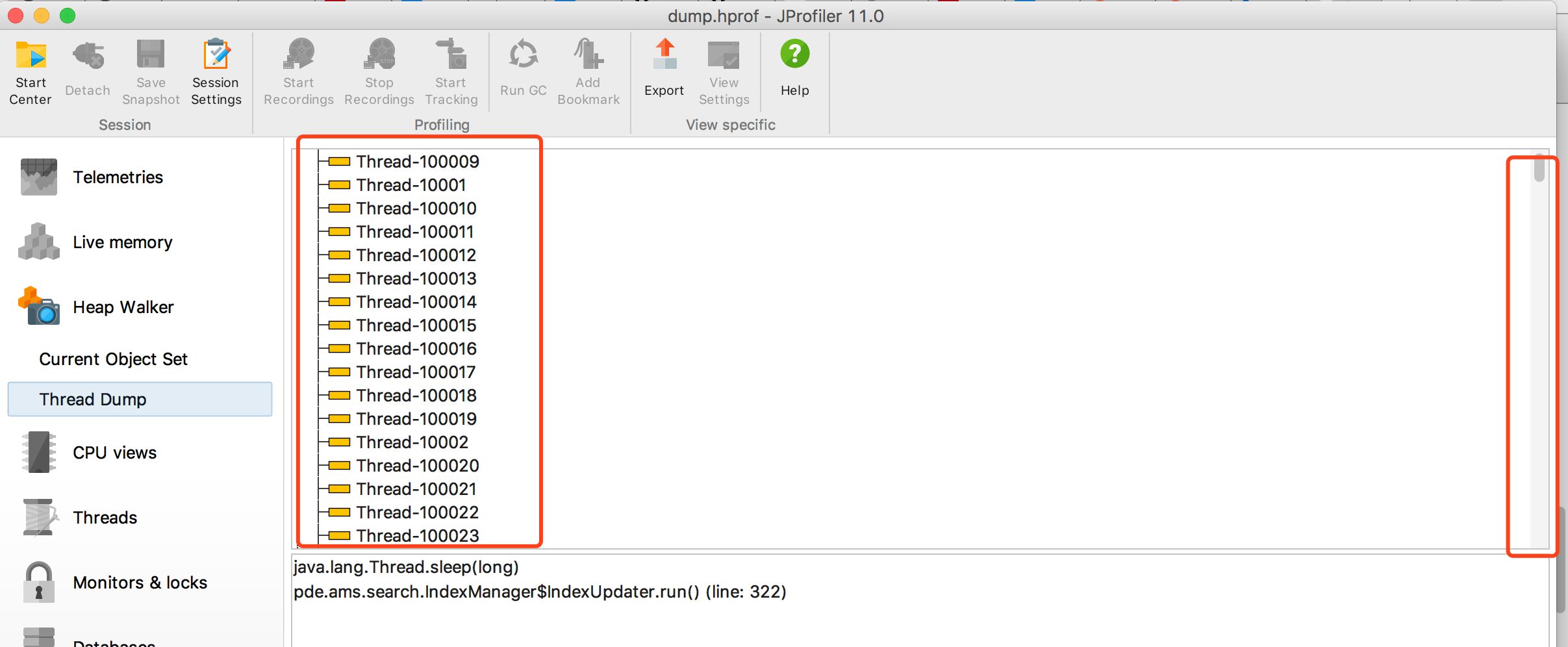
不得不说,有一点他们做的非常好,竟然贴心的给线程编了号,没错,就是有这么多线程 10万多个。于是我们算了一下假设 10分钟请求 300 次,那就是 300 个线程,一小时就是 30 x 6=1800,一天24小时就是1800 x 24=43200,两天多的时间 10万多个线程那就正好对上了,好牛x的样子。
一个线程默认占用空间大小 1M,10万多个线程那就是 10个多G,加上堆内存占用和机器上其他服务的内存占用,内存飙到 15G 就对的上了。
谁的问题谁处理
有问题就找问题就这么难吗,不承认自己的程序有问题是怎么想的呢。
好啊,你们自己不查,我帮你找到问题原因了,满意了吧。
于是,同事理直气壮的把上面那张截图发给他们,但是没有额外说一句话。
下午,微信群里对方发来消息,问题已修改,可以再试试。
然后,好多天过去了,问题没有再出现。
规避问题
有的同学问了,系统能创建10万多个线程吗,有可能的。这篇文章是「你假笨」大神写的 Linux 系统下能创建多少个线程的源码分析 club.perfma.com/article/244…,有兴趣可以上去看一看。
这个问题产生的原因就是线程创建了但是没有销毁,估计是销毁逻辑写的有些问题吧。
抛开逻辑错误不说,使用线程的正确做法是使用线程池,以免带来不必要的性能损耗和这种未加控制、未及时销毁带来的线程无止境创建的问题。
创作不易,小小的赞,大大的暖,快来温暖我。不用客气了,赞我!
我是风筝,公众号「古时的风筝」,一个在程序圈混迹多年,主业 Java,另外 Python、React 也玩儿的很 6 的斜杠开发者。可以在公众号中加我好友,进群里小伙伴交流学习,好多大厂的同学也在群内呦。

