

前言
笔者是一个算法的初学者,对于笔者而言,莱文斯坦距离的计算是比较抽象难懂的,而本文主要从比较通俗的角度来解析莱文斯坦距离的详细计算步骤,希望能够帮助到其他和我一样的算法小白。
算法定义
什么是莱文斯坦距离(Levenshtein distance)?它是编辑距离的一种,指两个字符串之间,由一个转成另一个所需的最少编辑操作次数。允许的操作为增加一个字符,删除一个字符,修改一个字符。俄罗斯科学家弗拉基米尔·莱文斯坦在1965年提出这个概念。 例如将字符串'abcde'修改为'aebcdf'最少需要两步
abcde -> aebcde //增加一个e
aebcde -> aebcdf //将e修改为f
很显然它与逐字修改相比节省了很多步骤,这个算法广泛运用于搜索引擎和输入法等。
话不多说,我们直接看莱文斯坦距离计算的公式和他的一些固定属性
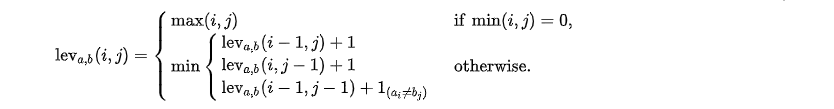
- 莱文斯坦距离至少是两个字符串长度的差值
- 莱文斯坦距离不大于较大的那个字符串的长度
- 如果两个字符串相等,那么它们的莱文斯坦距离为0
- 如果两个字符串等长,那么它们的汉明距离(Hamming distance)是莱文斯坦距离的上界
- 两字符串的莱文斯坦距离不大于它们与第三个字符串的莱文斯坦距离之和(三角性)
汉明距离是两个相同长度的字符串从头开始分别比对两个字符串对应字符位置的值是否相同,不相同则距离加1
步骤拆分
首先我们需要理解莱文斯坦距离需要逐个字符进行计算,我们继续使用上面的例子
string A = 'abcde'; string B = 'aebcdf'
将字符串拆分为一个二维数组 edist[][]
| B\A | 0 | a | b | c | d | e |
|---|---|---|---|---|---|---|
| 0 | ||||||
| a | ||||||
| e | ||||||
| b | ||||||
| c | ||||||
| d | ||||||
| f |
将这个公式翻译成我们更容易理解的代码语言
- 如果 i=0,edist[i][j]=j,如果j=0,edist[i][j]=i
- 如果 i && j>=1 则 edist[i][j] = min{edist[i-1][j]+1,edist[i][j-1]+1,edist[i-1][j-1]+x} 如果A[i]=B[j]相等,则x=0,否则x=1;
其中 i 为数组 A[] 的序号, j 为数组 B[] 的序号
根据第一条我们可以得到
| B\A | 0 | a | b | c | d | e |
|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4 | 5 |
| a | 1 | |||||
| e | 2 | |||||
| b | 3 | |||||
| c | 4 | |||||
| d | 5 | |||||
| f | 6 |
那么重点来了,如何理解第二条呢?
我们一步步来理解,当我们要求 edist[i][j] 的时候,他的值从 edist[i-1][j]+1, edist[i][j-1]+1, edist[i-1][j-1]+x 三个中取最小值,那么这三个值分别是什么呢?
我们以A="a",B="a"为例,即 edist[1,1],他的上一状态为 A="0",B="a" ;A="a",B="0"; A="0",B="0" 三种情况,他们对应的其实就是 edist[i-1][j], edist[i][j-1], edist[i-1][j-1] ,对于 edist[i-1][j], edist[i][j-1] 这两种情况,他们需要转换到 edist[1,1] 状态的话无论如何编辑距离都需要 +1, 而对于 edist[i-1][j-1] 来说,如果新增的两个字符是相等的话,是可以不增加编辑距离的,例如从"a","a"到"ab","ab",是不用增加编辑距离的,但是如果新增的字符不相等,例如从"a","a"到"ab","ac",还是要进行一次字符修改,因此编辑距离需要 +1,这就是式子中设置未知数 x 的作用。 理解了第二步,我们就可以得到下面的表
| B\A | 0 | a | b | c | d | e |
|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4 | 5 |
| a | 1 | 0 | ||||
| e | 2 | 1 | ||||
| b | 3 | 2 | ||||
| c | 4 | 3 | ||||
| d | 5 | 4 | ||||
| f | 6 | 5 |
在这里我们可以理解一下为什么我们要从三个上一状态中取最小值而不是从任一路径直接算到结尾,我们取字符串 A 为 "ab",B为 "aeb" 时,他的上一状态分别为A:"ab",B:"ae"; A:"a",B:"ae"; A:"a",B:"aeb"三种,他们对应的值分别为 1、1、2,通过我们的式子计算后得到的结果分别为 1、2、3。
我们通过简单的循环嵌套获得完整的表格
| B\A | 0 | a | b | c | d | e |
|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4 | 5 |
| a | 1 | 0 | 1 | 2 | 3 | 4 |
| e | 2 | 1 | 1 | 2 | 3 | 3 |
| b | 3 | 2 | 1 | 2 | 3 | 4 |
| c | 4 | 3 | 2 | 1 | 2 | 3 |
| d | 5 | 4 | 3 | 2 | 1 | 2 |
| f | 6 | 5 | 4 | 3 | 2 | 1 |
如果你看到了这里还是觉得难以理解的话,可以尝试自己写几个字符串,像我一样以表格的形式把他列出来并且尝试自己去计算它的编辑距离,慢慢的就会发现其中的规律。如果理解了的话代码应该很轻松就能写出来,这里就不做赘述了。
小结
莱文斯坦距离对于算法的初学者来说可能过于抽象,难以理解,但是这对我们磨练自己的算法思维是很有帮助的,希望这篇文章能够对你有所帮助,笔者也是一个算法小白,如果有写的不对的地方还请不吝赐教。
