

感谢 @Alan-Liang 分享的题目
不看答案,试着想下如下题的结果是什么?
console.log("more".replace(/.*/g, "p"));
说实话,这道题我答错了,我以为答案是: p
我们来看下正确的结果:

我理解在贪婪模式下是最长匹配规则,这里直接匹配整个字符串:more,结果输出: p , 但是为什么会输出:pp 呢?
我们改用正则的懒惰模式试试:
console.log("more".replace(/.*?/g, "p"));
执行结果如下:

果然和我想象的不一样!我以为结果会是:pppp。我意识到可能又遇到了某个技术盲点了!
要想真正弄懂这两道题的原理,还得从 ECMA-262 规范中来寻找答案。
首先我们来看下这两道题的差异。
贪婪 & 懒惰
在 JS 正则表达式规则中,量词修饰主要分为如下两类规则:
贪婪模式:最长匹配,尽可能多的匹配字符。
正则匹配中,优先量词修饰包括:{m,n}、{m,}、?、* 和 + 。
贪婪模式总是匹配尽可能多的字符,比如 {1,3} 量词,就会尽可能的匹配到 3 个字符。 如下例子:
"abcdefg".replace(/\w{1,3}/g,"1");按照最长匹配规则,这里会尽可能的匹配到最长字符: 3 个,于是这里有 [abc,def,g] 三个匹配项, 每个匹配项都用 ”1" 替换,所以最终输出结果是:111
懒惰模式:最短匹配,尽可能少的匹配字符,一旦匹配成功就截止。
正则匹配中,在优先量词修饰后面增加问号 ?,即懒惰模式,如:{m,n}?、{m,}?、??、*?和 +?。
如下例子:
"abcdefg".replace(/\w{1,3}?/g,"1");懒惰模式总是选择匹配尽可能少的字符,上面例子中 {1,3} 量词,匹配到 1 个字符就停止了。
这里总共产生 [a,b,c,d,e,f,g] 总共 7 个匹配项,每个匹配项都会替换成 1,输出结果是:1111111。
再比如笔者,本着搞懂这道题就够了,也不打算把 ecma262 规范从头看到尾了,这就是开启了懒惰模式[狗头][狗头][狗头]。
了解了这两者差异之后,我们再用几个栗子来加强认识。
栗子 1:
"abc".match(/(\w*)(\w*)(\w*)/);
// output
["abc", "abc", "", "", index: 0, input: "abc", groups: undefined]
这里的正则定义了三个分组,都是( \w* ),且匹配项是贪婪模式,按照最长匹配规则, 每一个分组都可以匹配整个字符串:abc。
从左至右,第一个分组匹配了整个字符串:abc,于是后面两个分组匹配都是空("")。
match 方法匹配成功后,会返回一个匹配项数组,从左至右, 数组第一项是整个匹配到的内容,从第二项开始则是分组的内容(如果有分组),依次数组第二位是 分组1, 第三位是 分组2 ……
栗子 2:
"abc".match(/(\w*?)(\w*)(\w*)/);
["abc", "", "abc", "", index: 0, input: "abc", groups: undefined]
这里第一个分组( \w*? ),添加了" ? ",使用懒惰模式,* 代表[ 0 或 多个], 按照最短匹配规则,第一个分组直接匹配 0 个就截止了,所以匹配项为空。
第二个分组( \w* ),是一个贪婪的家伙,直接匹配完整个字符串:“abc”,导致第三个分组无内容可匹配,匹配结果为空。
栗子 3:
"abc".match(/(\w+?)(\w*)(\w*)/);
["abc", "a", "bc", "", index: 0, input: "abc", groups: undefined]
这里第一个分组( \w+? ),添加" ?",开启懒惰模式,+ 代表[ 1 或多个],所以匹配到了一个 a 字符, 就结束了。
然后第二个分组 ( \w* ),是个贪婪的家伙,把剩下的字符:abc 都匹配完了,导致第三个分组匹配为空。
通过上面三个栗子,相信我们对贪婪模式和懒惰模式有个不错的了解了。
接下来我们通过 ecms262 规范来解答最开头的两道题。
开始读懂规范
开头的那两道题是属于正则表达式的 replace,所以我们来看下 ECMA-262 怎么定义 replace 的, 查询规范 RegExp.prototype [ @@replace ][1]
这里 rx 即正则表达式 RegExp 的值,S 为需要匹配的字符串内容。原文如下:
When the @@replace method is called with arguments string and replaceValue, the following steps are taken:
……
7. Let global be ! ToBoolean(? Get(rx, "global")).
8. If global is true, then
a. Let fullUnicode be ! ToBoolean(? Get(rx, "unicode")).
b. Perform ? Set(rx, "lastIndex", 0, true).
9. Let results be a new empty List.
10. Let done be false.
11. Repeat, while done is false
a. Let result be ? RegExpExec(rx, S).
b. If result is null, set done to true.
c. Else,
i. Append result to the end of results.
ii. If global is false, set done to true.
iii. Else,
1. Let matchStr be ? ToString(? Get(result, "0")).
2. If matchStr is the empty String, then
a. Let thisIndex be ? ToLength(? Get(rx, "lastIndex")).
b. Let nextIndex be AdvanceStringIndex(S, thisIndex, fullUnicode).
c. Perform ? Set(rx, "lastIndex", nextIndex, true).
上述是 ECMA-262 规范定义的伪代码,由于前面 1 ~ 6 我们这里用不上,我们暂时先忽略。
为了更好的理解,我们首先把它用中文描述翻译如下:
7. 如果 rx 对象存在 global 属性,则设置 global 变量为 true,否则为 false
8. 如果 global 为 true,则执行以下操作
a. 如果 rx 对象存在 unicode 属性,则设置 fullUnicode 变量为 true,否则为 false
b. 设置 rx 的 lastIndex 为 0
9. 设置 results 变量为一个空数组
10. 设置 done 变量为 false
11. 执行循环,如果 done 为 false
a. 设置 result 变量为 RegExpExec(rx,S) 的值
b. 如果 result 为 null,则设置 done 为 true
c. 如果 result 不为 null
i. 将 result 加到 results 的 末尾
ii. 如果 global 为 false,则 设置 done 为 true
iii. 如果 global 为 true
1. 设置 matchStr 变量为 result 的第 0 个值
2. 如果 matchStr 为是一个空字符串,则
a. 设置 thisIndex 变量为 rx 的 lastIndex
b. 设置 nextIndex 变量为 AdvanceStringIndex(S,thisIndex,fullUnicode)
c. 设置 rx 的 lastIndex 为 nextIndex
上面使用到的 AdvanceStringIndex, 参照规范[2], 当前只用到一条语句,作用就是将正则匹配的 lastIndex 后移一位:
// 如果不是 unicode ,则直接返回 index + 1。
4. unicode is false, return index + 1。
正则匹配中,有一个很重要的变量是 lastIndex,这个是指匹配的位置,对于字符串 ”more“, 有对应 5 个位置: 0 ~ 4,同样有四个字符内容: m,o,r,e。
位置对应关系如下图:
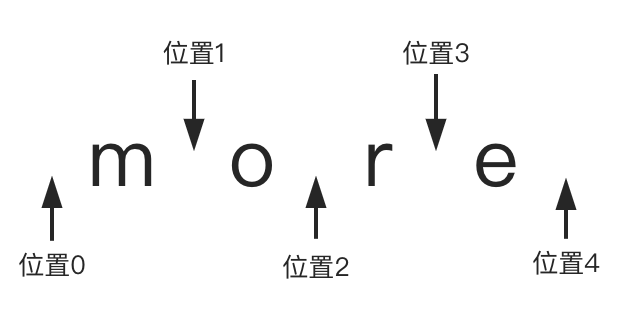
正则匹配从 lastIndex = 0 的位置开始匹配,直到 lastIndex = 4 最后一个位置截止。
到这里我们把 replace 规范已经读完,是不是感觉清晰多了!
下面我们就可以开始解答最上面两道题。
看贪婪模式题目
原题目如下:
"more".replace(/.*/g, "p")
按照上面的规范,我们将匹配步骤翻译成更加容易理解的 js 代码,翻译内容如下:
let rx = /.*/g;
let S = 'more';
let global = !!rx.global;// true
if(global){
var fullUnicode = !!rx.unicode;// false
rx.lastIndex = 0;
}
let results = [];
let done = false;
while(!done){
//第一次循环 result=["more", index: 0, input: "more", groups: undefined]
//第二次循环 result=["", index: 4, input: "more", groups: undefined]
//第三次循环 result=null
let result = rx.exec(S);
if(result==null){
done = true;
}else{
//第一次循环 results=["more"]
//第二次循环 results=["more",""]
[].push.apply(results,result);
if(!global){
done = true;
}else{
//第一次循环 matchStr="more"
//第二次循环 matchStr=""
let matchStr = String(result[0]);
if(!matchStr){
let thisIndex = rx.lastIndex;// 4
let nextIndex = thisIndex+1; // 5
rx.lastIndex = nextIndex; // rx.lastIndex = 5;
}
}
}
}
通过这里我们清晰的看到,匹配步骤执行了三次循环:
第一次循环:result 为 "more",results 为 ["more"]
第二次循环:result 为 ”“,results 为 ["more",""],得到 matchStr 为空,然后将 rx 的 lastIndex 设置为 5
第三次循环:result 为 null,然后终止循环。
这里经过三次循环之后,得到的 results 是 ["more",""],也就是获得的 match list, 这里 match list 的每一项都会去进行内容替换,这里有两个替换项,所以 replace 之后,最终结果为: pp。
这下终于真相大白了!
回过头来看,这道题出乎我们意料的是最后一个空(”“)字符串, 因为这里正则表达式(.*)是匹配任意字符,所以在循环中也将空("") push 到了 match results, 最终被替换成 p 了。
再看懒惰模式题目
原题目如下:
"more".replace(/.*?/g, "p")
有了上道题目分析之后,这道题分析就变的简单了:
let rx = /.*?/g;
let S = 'more';
let global = !!rx.global;// true
if(global){
var fullUnicode = !!rx.unicode;// false
rx.lastIndex = 0;
}
let results = [];
let done = false;
while(!done){
//循环第 1~5 次: ["", index: 0, input: "more", groups: undefined]
//第六次循环 null
let result = rx.exec(S);
if(result==null){
done = true;
}else{
//第一次循环 results=[""]
//第二次循环 results=["",""]
//第三次循环 results=["","",""]
//第四次循环 results=["","","",""]
//第五次循环 results=["","","","",""]
[].push.apply(results,result);
if(!global){
done = true;
}else{
//每次循环都是 matchStr=""
let matchStr = String(result[0]);
if(!matchStr){
let thisIndex = rx.lastIndex;//循环第 1~5 次对应值:0 1 2 3 5
let nextIndex = thisIndex+1;
rx.lastIndex = nextIndex; //循环第 1~5 次对应值:1 2 3 4 5
}
}
}
}
这里经过了六次循环,开始时 lastIndex 为 0 ,然后依次从位置 0 到 5 执行匹配, 由于每次匹配都是懒惰模式,遵循最短匹配规则,/.*?/ 正则在匹配 0 个字符后即匹配结束。
前五次循环都是匹配 "" 即止,然后 push 到 results。第六次为 null,然后结束循环, 最终得到的 match results 是 ["","","","",""],所以最终替换后的结果为:pmpoprpep, 将匹配的 results 全部替换为 p 字符了。
到此,我们对正则表达式的 replace 就算有了更深的认识了。
现在我们就更容易理解如下题了:
"more".replace(/.+?/g, "p") // pppp
由于是懒惰模式,按照最短匹配规则,这里的量词修饰是 +?,最短匹配元素是 1 个,所以这里会输出:pppp
如本文上述内容描述,字符串 replace 的时候,从位置 lastIndex 为 0 开始匹配,一直到末尾结束。
我们结合贪婪量词修饰 * ,有如下匹配结果也是意料之中了:
"more".replace(/\d*/g, "p") // 输出 pmpoprpep
"more".replace(/\s*/g, "p") // 输出 pmpoprpep
至此,总算又终结了自己的一个技术盲点!
寄语:使用 replace 正则替换的时候,尤其是用到量词修饰符, 如 * 的时候,要多加留意,以防导致结果不符合预期。
欢迎关注我的微信公众号,一起做靠谱前端!

