

前言
-
昨天有读者朋友留言,想要陈某写一篇防止缓存穿透的文章,今天特意写了一篇。 
-
文章目录如下:
-
什么是缓存穿透?
-
**缓存穿透**其实是指从缓存中没有查到数据,而不得不从后端系统(比如数据库)中查询的情况。
-
缓存毕竟是在内存中,不可能所有的数据都存储在 Redis 中,因此少量的缓存穿透是不可避免的,也是系统能够承受的,但是一旦在瞬间发生大量的缓存穿透,数据库的压力会瞬间增大,后果可想而知。
-
在开发中使用缓存的方案如下图,在查询数据库之前会先查询 Redis: 
-
缓存穿透的整个过程分为如下几个步骤:
-
应用查询缓存,**缓存不命中**
-
DB 层查询不命中,**不将空结果缓存**
-
返回空结果
-
下一个请求继续重复1,2,3步。
-
解决方案
-
万事万物都是相生相克,既然出现了缓存穿透,就一定有避免的方案。
-
下面介绍两种缓存的方案,分别是`缓存空值`、`布隆过滤器`。
缓存空值
-
回顾缓存穿透的定义知道,**大量空值没有缓存导致重复的访问 DB 层**,由此解决方案也是很明显了,直接将返回的空值也缓存即可。此时的执行步骤如下图: 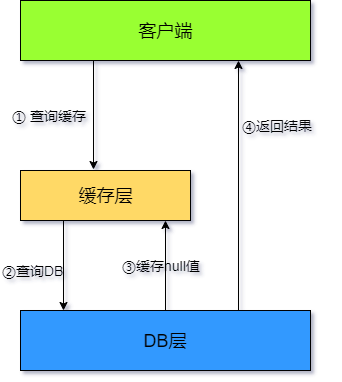
-
如上图所示,如果缓存不命中,查询 DB 层之后,直接将空值缓存在 Redis 中。伪代码如下:
Object nullValue = new Object(); try { Object valueFromDB = getFromDB(uid); //从数据库中查询数据 if (valueFromDB == null) { cache.set(uid, nullValue, 10); //如果从数据库中查询到空值,就把空值写入缓存,设置较短的超时时间 } else { cache.set(uid, valueFromDB, 1000); } } catch(Exception e) { // 出现异常也要写入缓存 cache.set(uid, nullValue, 10); }
-
通过伪代码可以很清楚的了解了缓存空值的流程,但是需要注意以下问题:
-
**缓存一定要设置过期时间**:因为空值并不是准确的业务数据,并且会占用缓存空间,所以要给空值加上一个过期时间,使得能够在短期之内被淘汰。但是随之而来的一个问题就是在一定的时间窗口内缓存的数据和实际数据不一致,比如设置 10 秒钟过期时间,但是在这 10 秒之内业务又写入了数据,那么返回就不应该为空值了,所以还要考虑数据一致的问题,解决方法很简单,利用消息系统或者主动更新的方式清除掉缓存中的数据即可。
-
布隆过滤器
-
1970 年布隆提出了一种布隆过滤器的算法,用来判断一个元素是否在一个集合中。这种算法由一个二进制数组和一个 Hash 算法组成。
-
具体的算法思想这里不再详细解释了,如有不了解的可以看陈某上一篇文章[大白话布隆过滤器,又能和面试官扯皮了~](https://mp.weixin.qq.com/s/Vo935pCXH0aPgG20f1ppEg)。
-
解决缓存穿透的大致思想:**在访问缓存层和存储层之前,可以通过定时任务或者系统任务来初始化布隆过滤器,将存在的 key 用布隆过滤器提前保存起来,做第一层的拦截**。例如:一个推荐系统有 4 亿个用户 id, 每个小时算法工程师会根据每个用户之前历史行为计算出推荐数据放到存储层中, 但是最新的用户由于没有历史行为, 就会发生缓存穿透的行为, 为此可以将所有推荐数据的用户做成布隆过滤器。 如果布隆过滤器认为该用户 id 不存在, 那么就不会访问存储层, 在一定程度保护了存储层。此时的结构如下图: 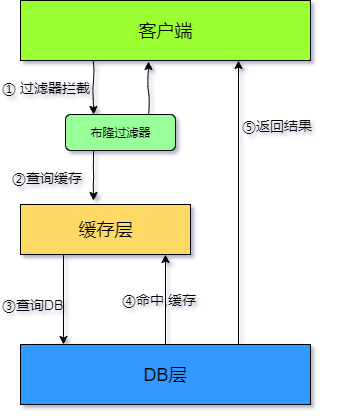
-
当然布隆过滤器的**假阳性**的存在导致了误判率,但是我们可以尽量的降低误判率,一个解决方案就是:使用多个 Hash 算法为元素计算出多个 Hash 值,只有所有 Hash 值对应的数组中的值都为 1 时,才会认为这个元素在集合中。
-
这种方法适用于`数据命中不高`、 `数据相对固定`、 `实时性低`(通常是`数据 集较大`)的应用场景,代码维护较为复杂,但是缓存空间占用少。为什么呢?因为布隆过滤器不支持删除元素,一旦数据变化,并不能及时的更新布隆过滤器。
两种方案对比
-
两种方案各有优缺点,具体使用哪种方案还是要根据业务场景和系统体量来定。具体的区别如下表:
| 方案 | 适用场景 | 维护成本 |
|---|---|---|
| 缓存对象 | 1\. 数据命中不高 2\. 数据频繁变化,实时性高 | 代码维护点单、需要过多的缓存空间,数据一致性需要自己实现 |
| 布隆过滤器 | 1\. 数据命中不高 2.数据相对固定,实时性低 | 代码维护复杂、缓存空间占用少 |
总结
-
至此,如何解决缓存穿透的问题已经介绍完了,觉得写得不错的,有所收获的朋友,点点在看,分享关注一波。
