

前言
本文是V8引擎详解系列的第二篇,重点内容是关于V8在编译运行过程中生成抽象语法树(AST)的一些理解,如果不知道v8基本运行过程的同学可以先看一下本人的第一篇文章 V8引擎详解(一)——概述。
AST的概念
一、什么是AST
看过我上一篇文章的同学应该了解到V8引擎会先将javascript代码转换成AST(抽象语法树),而事实上无论使用什么编程语言(无论是解释形语言还是编译形语言)都会将源代码解析成 抽象语法树(abstract syntax tree, AST),AST是计算机科学中很早的一个概念,不是V8特有的(只是V8在转换过程中做了非常多的优化)更不是javascript特有的。
大家都知道想要运行javascript程序,需要处理原始的js文件才能让v8引擎理解,而第一步就是将js代码解析成一个抽象语法树(AST),本质上就是一组表示程序结构的对象。然后再由Lgnition(未来我的文章中会有详细介绍)编译AST生成字节码。
二、AST的用途
AST的作用也不仅仅是用来在v8的编译上,我们在实际的开发过程中也是经常使用的,比如我们常用的babel插件将 es6->es5 、ts->js 、代码压缩、css预处理器、eslint等等,他们在我们的实际开发中都是必不可少的,而他们的底层原理其实也都是AST。
三、结构
我们已经知道了AST的一些基本概念也知道了一些用途,那么到底AST是一个什么样结构的存在。我通过一个小工具给大家展示一下。(v8生成的AST结构和下面展示的是不太一样的,V8生成的不太容易阅读并且做了专门的优化,该图是为了方便大家先理解)
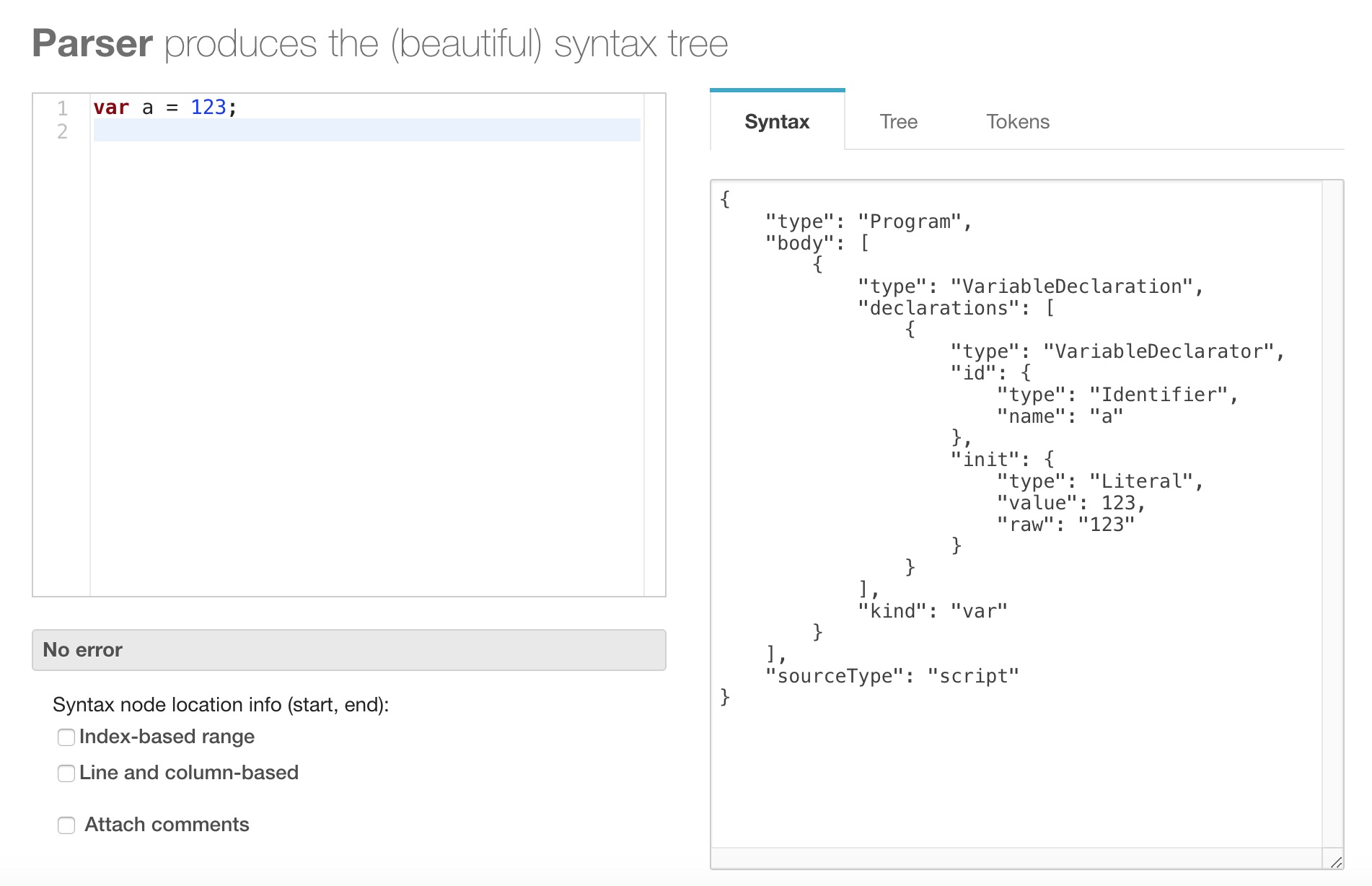
工具的地址:esprima.org/demo/parse.…
实际上,上图的解析格式才是符合业界规范的,最早由js之父Brendan Eich设计了第一代js引擎SpiderMonkey,后交给了Mozilla维护,再后来就开源了也就是 Parser_API 伴随着ECMAScript的升级迭代也逐渐升级,慢慢的变成了现在的业界规范。
这个格式并不复杂大家可以打开Parser_API配合esprima在线工具边看边调很快就可以了解并掌握
AST编译过程
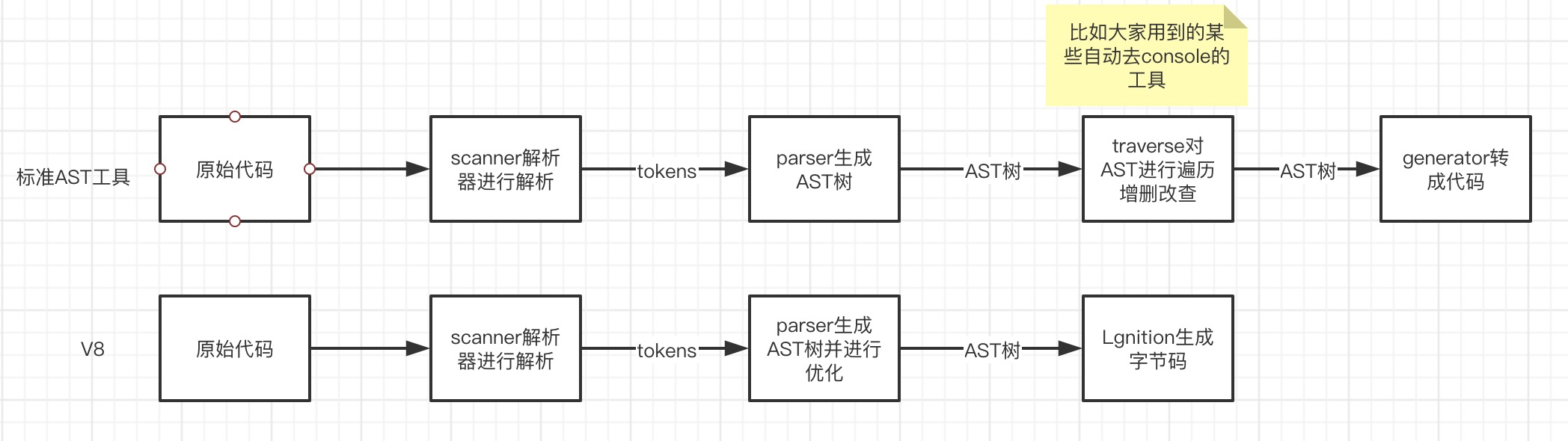
一、基本流程
我们先来看一下流程图:
二、词法分析scanner
scanner最重要的功能就是将js源码转换成一个个有意义的词(token)形成的数组。
我们一起通过一个简单的小例子来了解一下它大概的运行流程还是以一个最简单语句进行分析。
var a = 123;
我们设想代码开始从 HTTP 协议收到的上面的字符流读取字符,当我们读取到了第一个字符 "v":
-
我们会通过条件判断语句判断这个字符是 字母, "/" , "数字" , 空格 , "(" , ")" , ";" 等等。
-
如果是 ';' 这种会生成{"type" : "Punctuator" , "value" : ";" }$放入数组中。
-
如果是字母会继续往下看如过还是字母或者数字,会继续这一过程直到不是为止,这个时候发现找到这个字符串是一个 "var" 是一个Keyword并且下面一个字符是一个 "空格" 就会生成{ "type" : "Keyword" , "value" : "var" }放入数组中。
-
它继续向下找发现了一个字母 'a'(因为找到的上一个值是 "var" 这个时候如果它发现下一个字符不是字母可能直接就会报错返回)并且后面是空格,生成{ "type" : "Identifier" , "value" : "a" }放到数组中。
-
发现了一个 "=", 生成了{ "type" : "Punctuator" , "value" : "=" }放到了数组中。
-
发现了'123',生成了{ "type" : "Numeric" , "value" : "123" }放到了数组中。
-
最后发现了 ';', 生成了{ "type" : "Punctuator" , "value" : ";" }放入数组中。
我们来看一下生成的结果
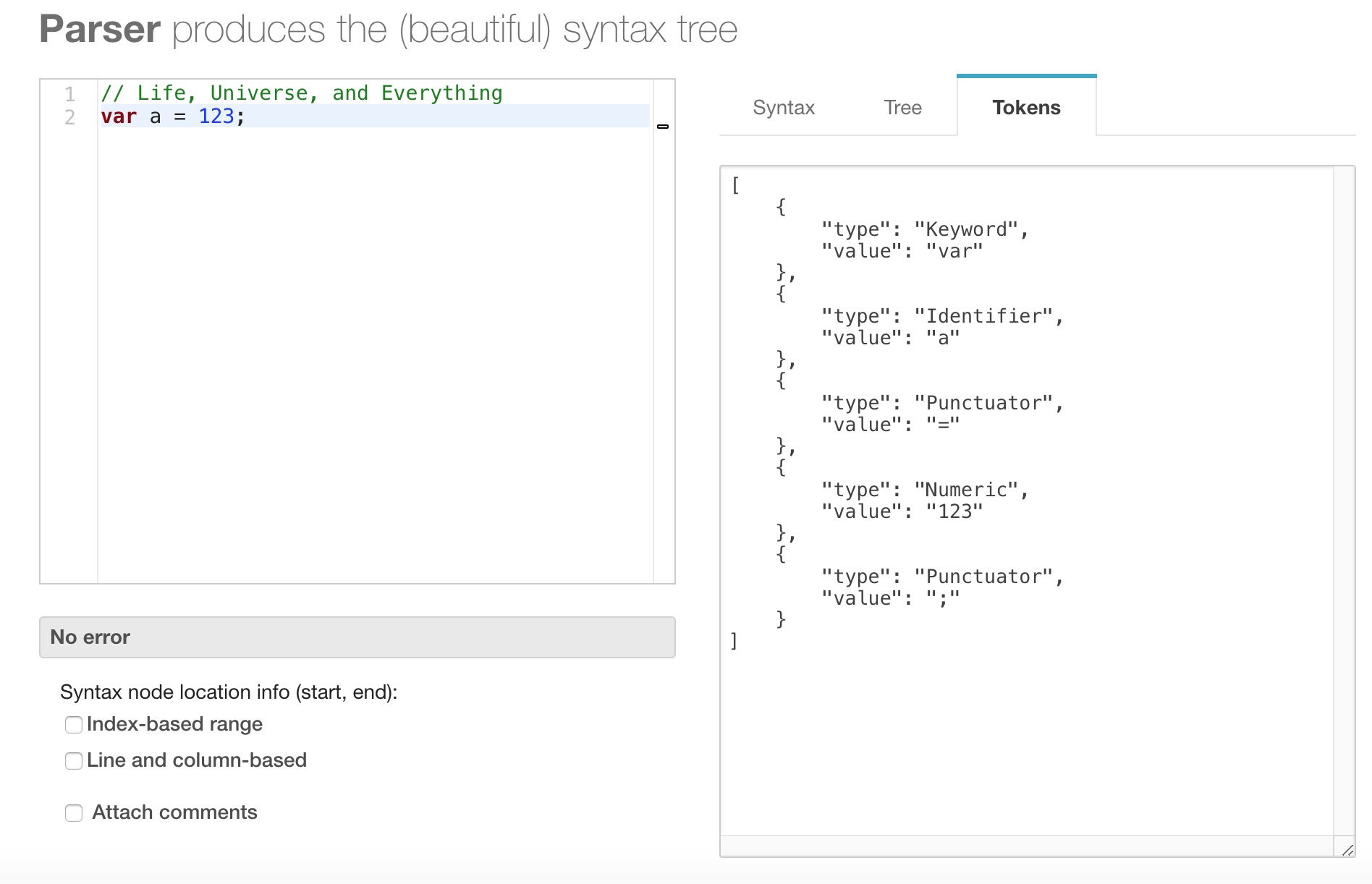
大概的原理基本就是这样,当然 v8 有它自己的实现策略肯定不会像我写的那么简单,不过基本原理都是类似的。
如果有兴趣想更深一步的了解 v8 scanner的实现策略可以看一下v8官方出的文档:
v8.dev/blog/scanne…
事实上绝大多数语言的词法部分都是用类似的状态机原理实现的,甚至包括了我们熟知的HTML官方文档。
三、语法分析parser
接下来就是 Parser 所做的工作实际上就是,对词法分析之后的结果( 返回的数组)再次进行分析,分析过程中将该数组按照特定的格式转换成一个对象,基本的原理也是遍历我们的数组进行判断来生成结构(AST树),这里我重点想讲的是v8和普通工具生成的AST的一些差异。
之前说过普通的AST树是使用同一个业界标准的,也就是说通过Parser生成的AST树甚至是可以直接给bable直接进行编译转换的,而通过v8生成的则是给v8自己的Lgnition引擎生成字节码的生成的结果是优化过的,所以两者有着很大的差异,接下来我还是通过几个小例子来帮助大家理解。
还是先从最简单的开始
var a = 123;
对比一下生成的结果
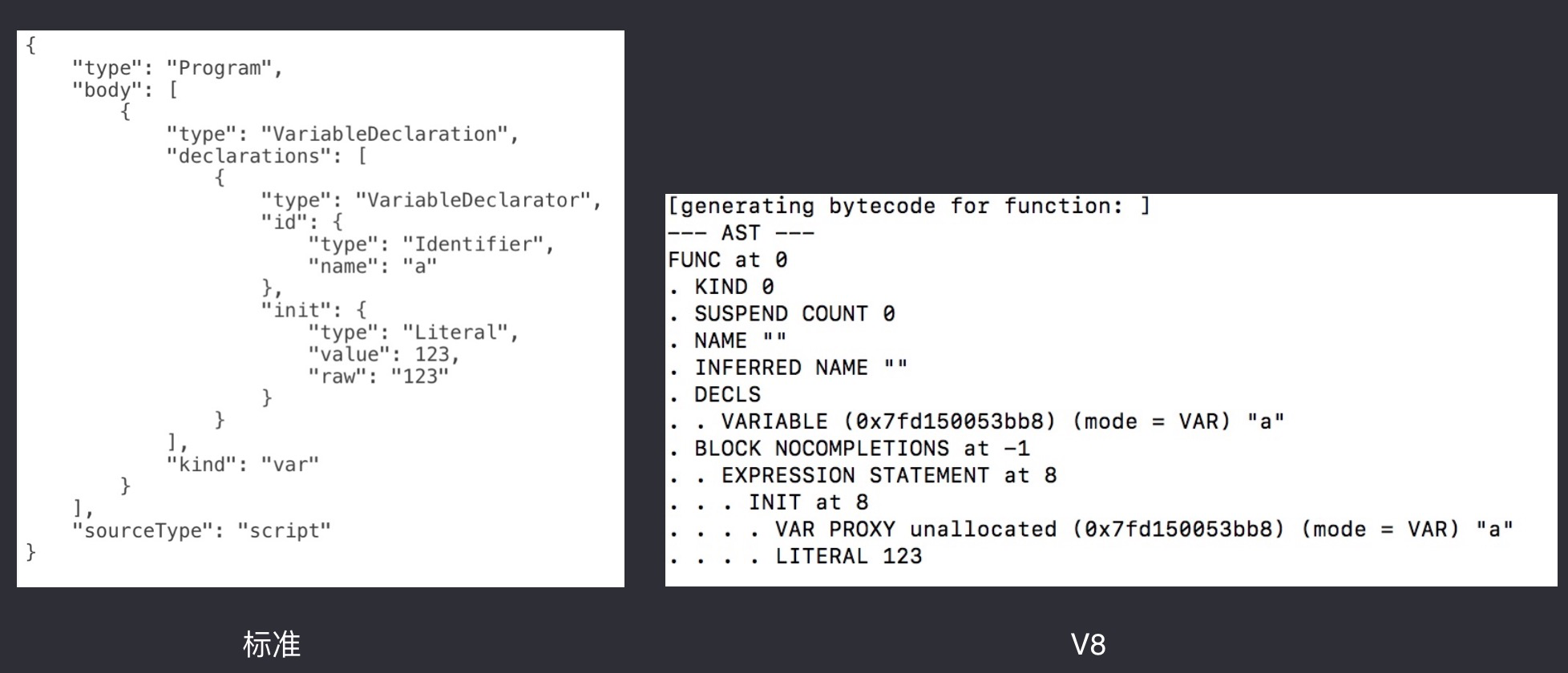
如果大家有认真看过上文并且进行了简单的实验,左边图标准的结构大家肯定可以理解,而右边图 v8 生成AST的通过自身的描述大概意思也能和代码结合起来,我们接着往下看这段代码:
var a = 6 * 7;
生成的结果:
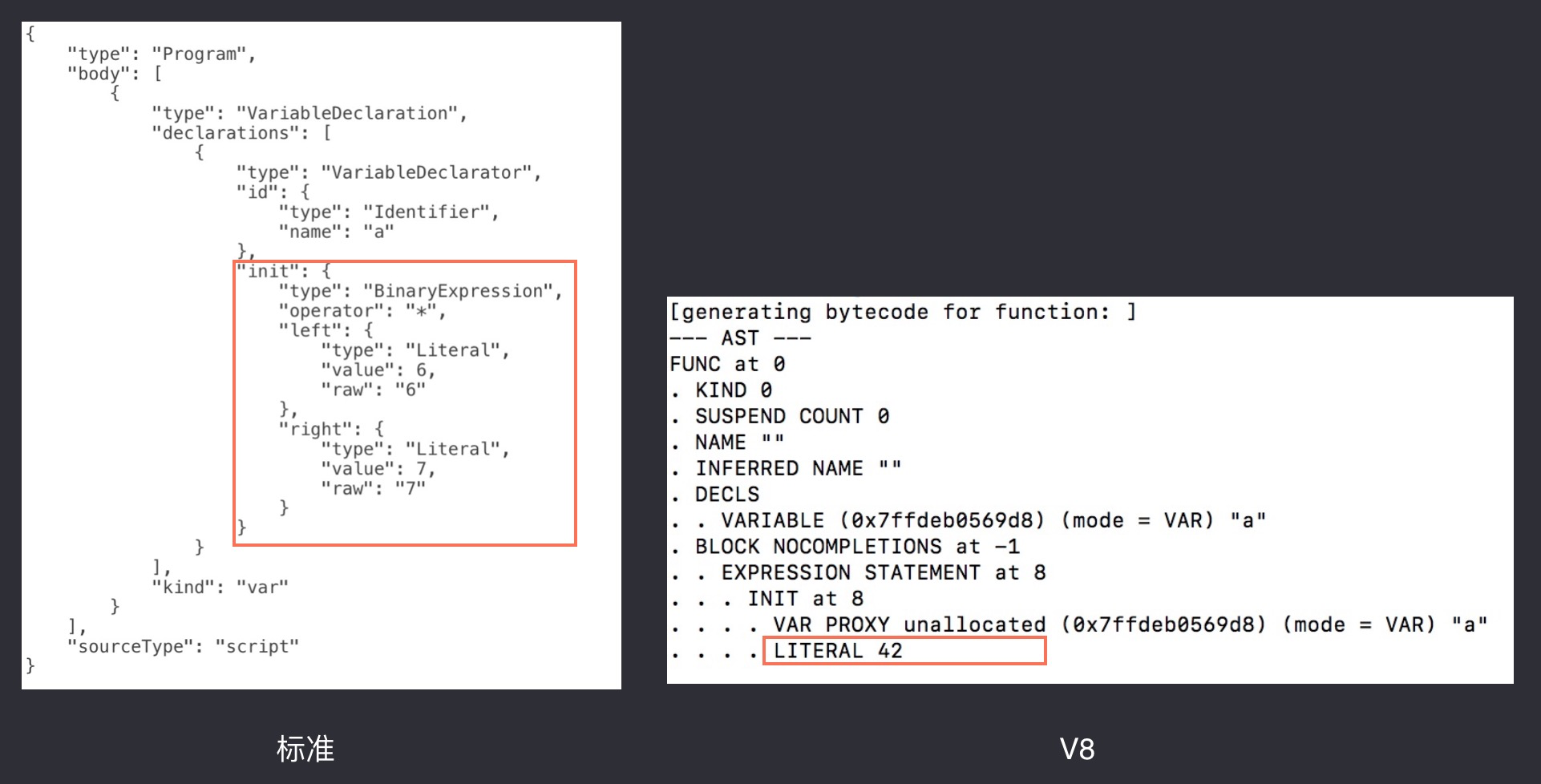
标准的结构下面描述了 6 * 7 的这个结构,而 v8 直接将计算出来的结果生成了出来,这样会减少 v8 后面通过Lgnition生成字节码所消耗的资源,从而进行性能的提升,如果你觉得光节省的这点消耗不算什么,那么我们继续往下看:
function test () {
return 1 + 2;
}
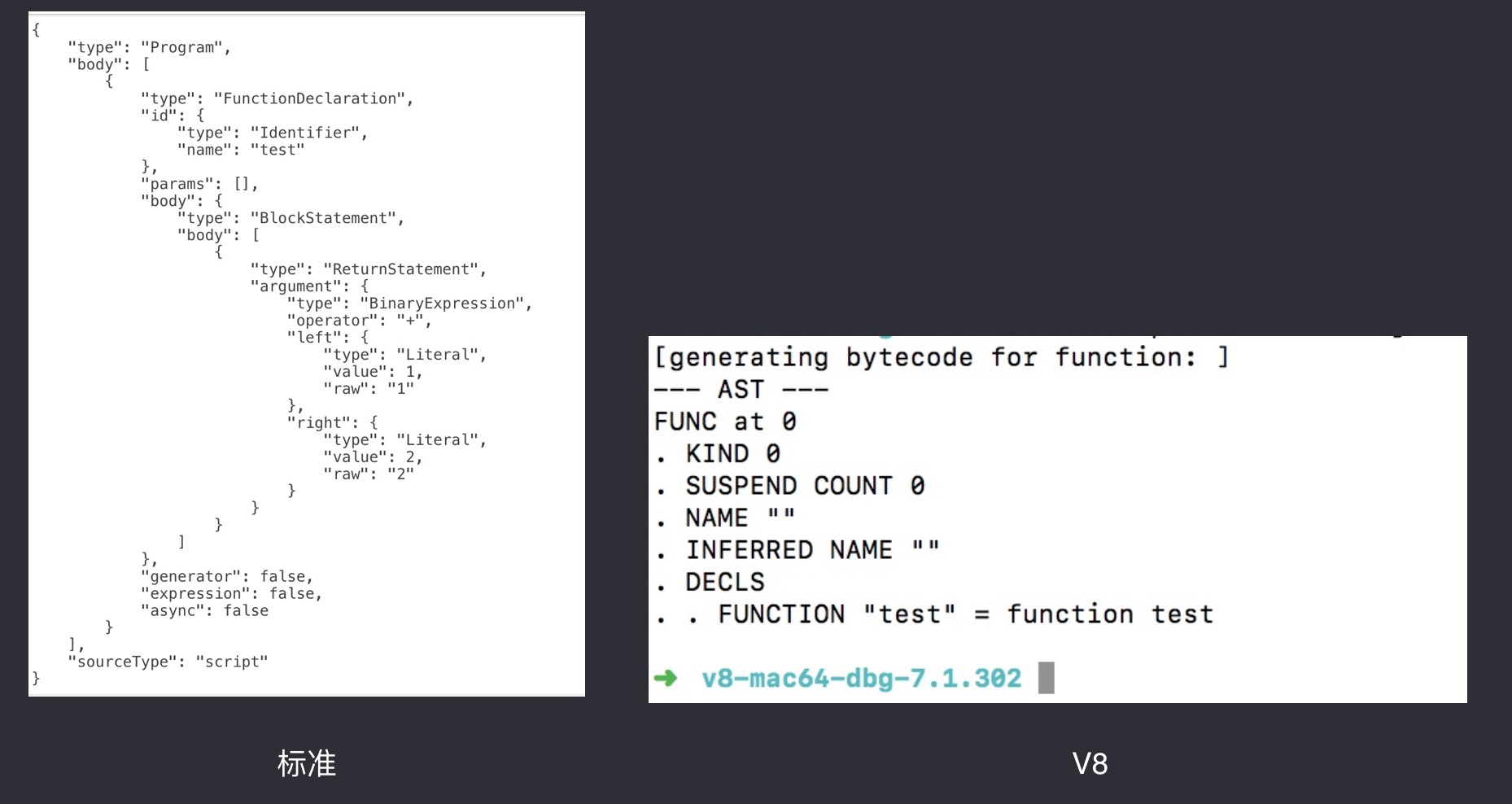
当 V8 发现了源文件只是声明了一个叫 test 的函数但是并没有调用时,根本没有解析里面的任何内容,那我们接下来继续看调用了会怎么样:
function test () {
return 1 + 2;
}
var a = test();
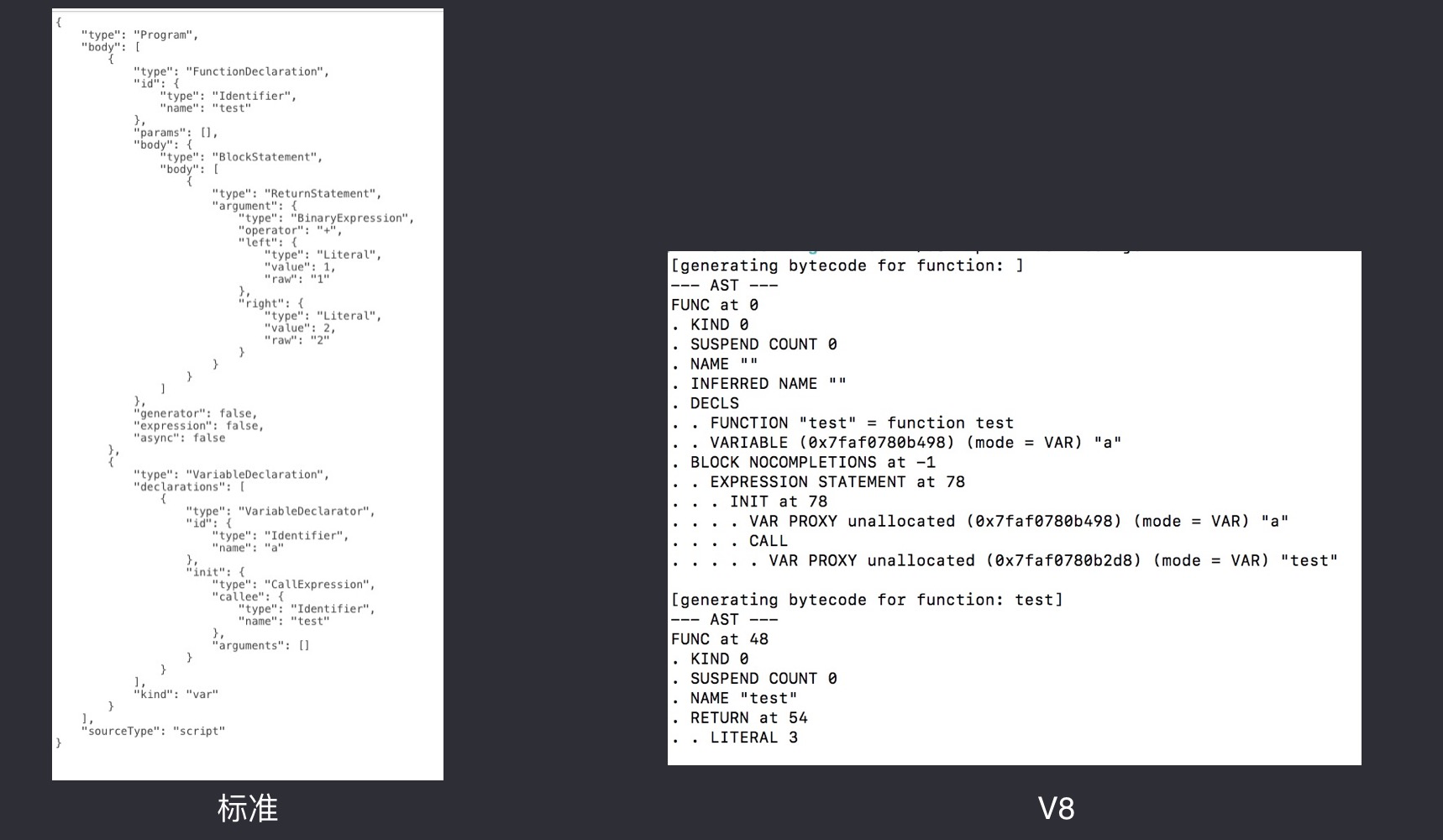
我们可以发现 v8 生成的AST树单独的为 test 函数生成了一个AST节点而不再generating主流程中,这样做有非常多的好处(比如在初始化的过程中,因为不是本文的重点就不多赘述),更显而易见的是随着js源码的增加v8生成的AST树的大小和标准结构的AST树大小的差距正在越拉越大,那么解析起来自然有更多优势。
上面几个简单的小例子只是用最简单易懂的代码来解释一下为什么 v8 生成的AST树并不是标准的规范的树(对没错、就是为速度而生)。
而实际上 v8 在生成AST树上所做的工作和优化的内容也远远不止我上面提过的这几个小例子,如果有兴趣想更深一步的了解 v8 Parser的实现策略可以看一下v8官方出的文档: v8.dev/blog/prepar…
总结
本文主要介绍了 v8引擎 将进行编译执行的第一步——生成AST,通过了解什么是AST,以及生成AST的流程包括解释了为什么 v8引擎 为什么没有遵循AST的规范,作者并没有通过源码层面来分析生成的过程,主要是想通过让更多人都能理解的方式来学习 v8引擎(主要是作者水平不够),如果有什么错误,请在评论中和作者一起讨论,如果您觉得本文对您有帮助请帮忙点个赞,感激不尽。
参考文章
v8.dev/blog/scanne…
v8.dev/blog/prepar…
cloud.tencent.com/developer/a…
系列文章
V8引擎详解(一)——概述
V8引擎详解(二)——AST
V8引擎详解(三)——从字节码看V8的演变
V8引擎详解(四)——字节码是如何执行的
V8引擎详解(五)——内联缓存
V8引擎详解(六)——内存结构
V8引擎详解(七)——垃圾回收机制
V8引擎详解(八)——消息队列
V8引擎详解(九)——协程&生成器函数
