

- 原文地址:Web Scraping with Puppeteer in Node.js
- 原文作者:Belle Poopongpanit
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:Badd
- 校对者:shixi-li
在 Node.js 中用 Puppeteer 实现网络爬虫

你是否曾想要用你最喜欢的公司或网站的 API 做一个新的 App 项目,结果发现人家要么压根没有 API 支持,要么已经不对外开放了?(说的就是你,Netflix)好吧,这事儿就发生在我身上,而鉴于我是一个不达目的不罢休的人,我最终还是找到了破局的办法:网络爬虫。
网络爬虫是一种使用软件从一个网站中自动提取和收集数据的技术。收集到数据之后,你就可以用来开发自己的 API 了。
有多种技术可以实现网络爬虫,Python 就是其中的明星。然而我可是 JavaScript 的迷妹。因此,我会在本文中介绍用 Node.js 和 Puppeteer 来实现的方式。
Puppeteer 是一个 Node.js 库,它让我们能够暗地里运行一个 Chrome 浏览器(即无头浏览器,因为它无需图形用户界面),来帮我们从网站中提取数据。
由于新冠肺炎,我们大多数都被囚禁在家中,于是在 Netflix 上刷剧刷片就成为了很多人打发时间的不二选择(除了哭泣,我们还能干嘛呢)。为了与其他像我这样有选择困难症而又百无聊赖的 Netflix 观众共飨福利,我找到了一个网站 —— www.digitaltrends.com/movies/best…,它列出了 2020 年 4 月份的近期最佳影片。等我爬取了这个页面并提取出数据,我就把数据存进一个 JSON 文件。这样,当我什么时候想要做一个 Netflix 近期最佳影片的 API,就直接从这个 JSON 文件拿数据就好了。
开动
首先,我在 VS Code 中新建一个 webscraper 文件夹。在此文件夹中新建一个 netflixscrape.js 文件。
我们需要在终端中安装 Puppeteer。
npm i puppeteer
然后,导入所需的模块和库。netflixscrape.js 中的开头代码如下:
const puppeteer= require('puppeteer')
const fs = require('fs')
fs 是 Node.js 的文件系统模块。我们要用这个模块来创建存数据的 JSON 文件。
写爬虫函数
现在就要开始写 scrape() 函数啦。
async function scrape (url) {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url)
scrape() 将会接收一个 url 作为参数。我们用 puppeteer.launch() 来启动无头浏览器。browser.newPage() 则在无头浏览器中打开一个空白页面。然后,我们让浏览器打开指定的 url。
如何取得想要爬取的数据
为了从网站中爬取我们想要的数据,我们需要通过数据所在的特定 HTML 元素来抓取它们。打开 www.digitaltrends.com/movies/best…,然后打开 Inspector 或者 Chrome 调试工具。可以用如下快捷键:
Mac 中为 “Command + Option + j”;Windows 中为 “Ctrl + Shift + i”
既然我想要从文章中抓取影片的标题和简介,那么就得选择 h2 元素(标题)和对应的兄弟元素 p(简介)。
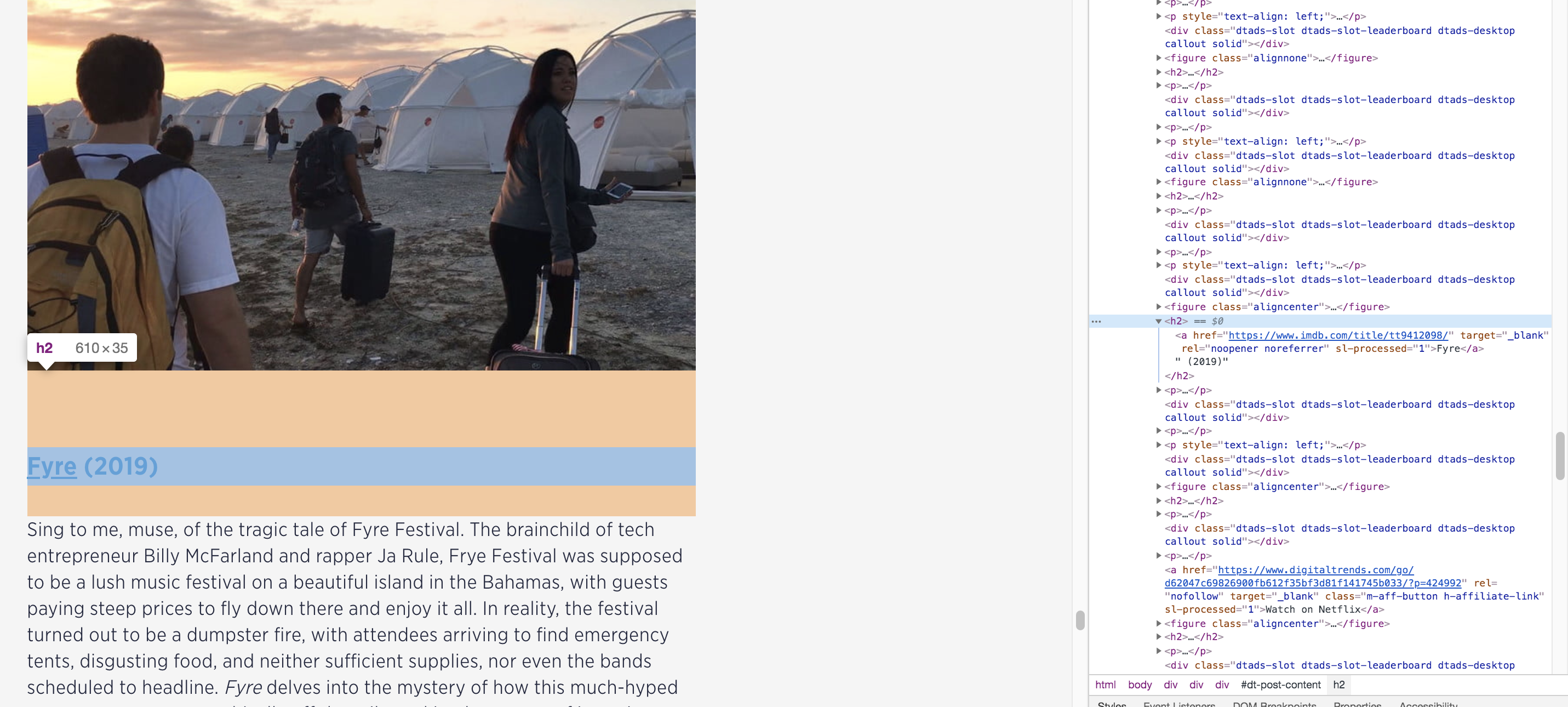
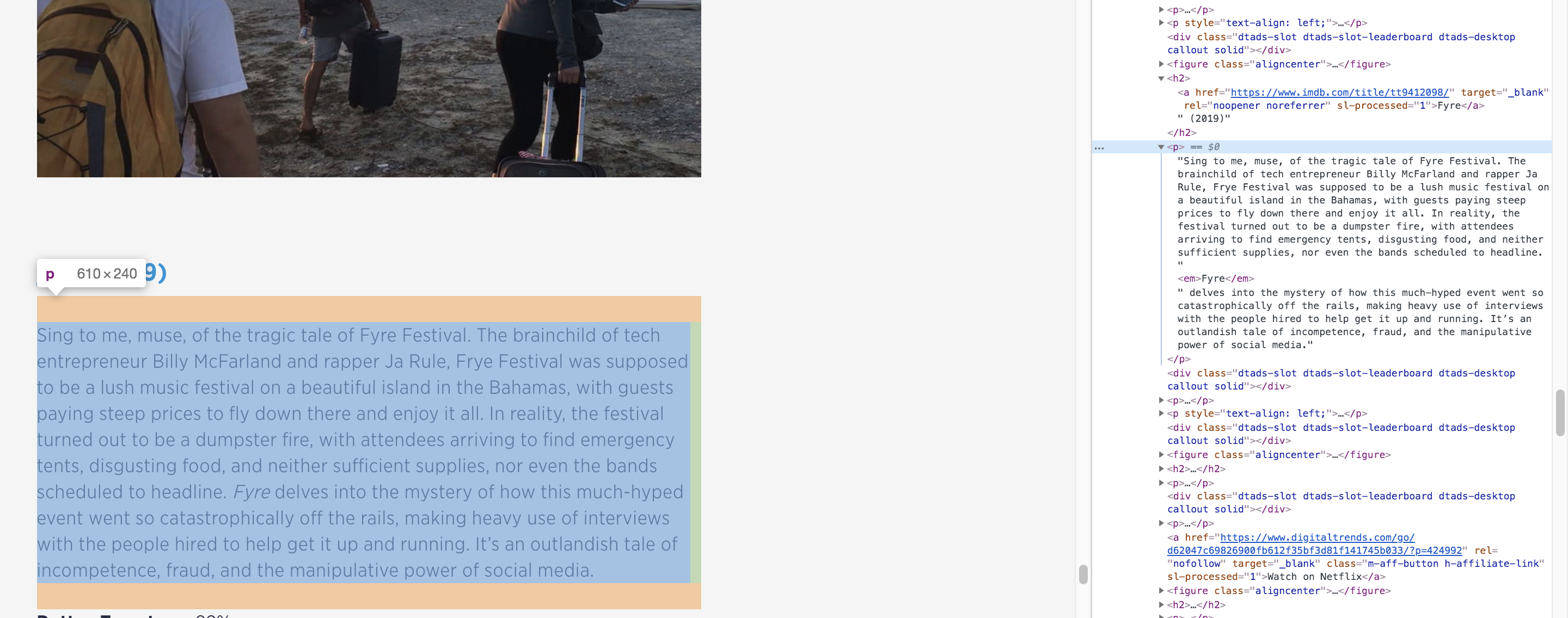
如何操作取到的元素
我们接着写代码:
var movies = await page.evaluate(() => {
var titlesList = document.querySelectorAll('h2');
var movieArr = [];
for (var i = 0; i < titlesList.length; i++) {
movieArr[i] = {
title: titlesList[i].innerText.trim(),
summary: titlesList[i].nextElementSibling.innerText.trim()
};
}
return movieArr;
})
我们用 page.evaluate() 来进入页面的 DOM 结构,这样就能像在调试工具的 Console 面板中那样执行我们自己的 JavaScript 代码了。
document.querySelector('h2') 选中了页面中所有的 h2 元素。我们把它们统统存到变量 titlesList 中。
然后,我们创建一个名为 movieArr 的空数组。
我们想把每个影片的标题和简介存到单独的对象中。于是我们运行了一个 for 循环。这个循环使得 movieArr 中的每个元素都是具有 title 和 summary 属性的对象。
为了取得影片标题,我们得遍历 titlesList —— 所有的 h2 元素节点都在其中。我们使用 innerText 属性来获得 h2 的文本内容。然后,我们用 .trim() 方法去除空格。
如果你仔细看过调试工具的 Console 面板,你会注意到,这个页面有很多没有指定唯一类名或 id 的 p 元素。这样的话,就真的很难精确地抓取到我们需要的影片简介 p 元素了。为了解决这个问题,我们在 h2 节点(即 titlesList[i])上调用了 nextElementSibling 属性。当你仔细看看 Console 面板,你会发现,包含影片简介的 p 元素是包含影片标题的 h2 元素的兄弟元素。
把爬取到的数据存到 JSON 文件中
到此,我们已经完成了主要的数据提取部分,可以把拿到的数据存入一个 JSON 文件了。
fs.writeFile("./netflixscrape.json", JSON.stringify(movies, null, 3), (err) => {
if (err) {
console.error(err);
return;
};
console.log("Great Success");
});
fs.writeFile() 新建了一个用来存储影片数据的 JSON 文件。它接收三个参数:
-
要新建的文件的名称
-
JSON.stringify() 方法把 JavaScript 对象转换为 JSON 字符串。它接收 3 个参数。要转换的对象:
movies对象,替换参数(用于把你不想要的属性过滤掉):null,空格(用于在输出的 JSON 字符串中插入空格,增加易读性):3。这样生成的的 JSON 文件就会又好看又整洁。 -
err,处理报错情况
err 接收一个回调函数,当程序出现错误时,这个回调函数就在控制台打印出错误信息。如果没有错误,就打印 “Great Success”。
最终,整体代码如下:
const puppeteer = require('puppeteer')
const fs = require('fs')
async function scrape (url) {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url)
var movies = await page.evaluate(() => {
var titlesList = document.querySelectorAll('h2');
var movieArr = [];
for (var i = 0; i < titlesList.length; i++) {
movieArr[i] = {
title: titlesList[i].innerText.trim(),
summary: titlesList[i].nextElementSibling.innerText.trim(),
};
}
return movieArr;
})
fs.writeFile("./netflixscrape.json", JSON.stringify(movies, null, 3), (err) => {
if (err) {
console.error(err);
return;
};
console.log("Great Success");
});
browser.close()
}
scrape("https://www.digitaltrends.com/movies/best-movies-on-netflix/")
我们增加了 browser.close() 来关闭 Puppeteer 的无头浏览器。在最后一行,我们调用 scrape() 函数并传入 url。
临门一脚:运行 scrape() 函数
在终端中键入 node netflixscrape.js 来运行这段代码。
如果一切顺利(那是必须的),你会在控制台看到 “Great Success” 字样,并且得到一个新鲜出炉的含有所有 Netflix 影片标题和简介的 JSON 文件。
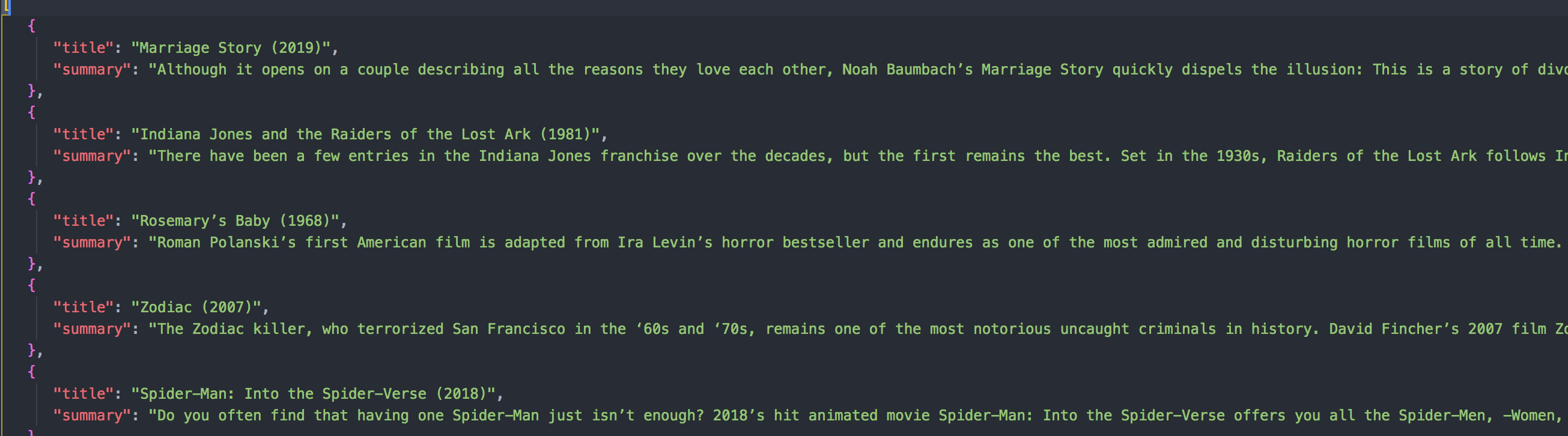
恭喜!!👏 你现在正式成为了一名黑客!好吧我开玩笑的。但现在你已经知道如何通过网络爬虫来获取数据、开发自己的 API 了,这样一说,是不是带劲儿多了?
如果发现译文存在错误或其他需要改进的地方,欢迎到 掘金翻译计划 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 本文永久链接 即为本文在 GitHub 上的 MarkDown 链接。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
