

富文本实现格式化,格式化的时候保留图文、文字换行、样式。
开始
有一个需求,粘贴的时候格式化富文本内容,但是保留图文、文字换行、样式。
一开始我做的时候是全部格式化,也就是粘贴的时候拿到html(怎么拿到百度下就有了,一般大家也都是对别人的富文本进行改造。),然后转DOM,然后getInnerText.大功告成。这时候产品说,保留图文和换行哦。
于是修改下。
保留图文和换行
这个比较简单,看下就行了。
- 流程:获取img并转存 -> 替换img标签 -> 获取到纯文本 -> 添加换行 -> 恢复图片
- 保存图片的话先把图片下载下来,然后拿到blob再上传到服务器。
不做解析。 (核心代码就这些)
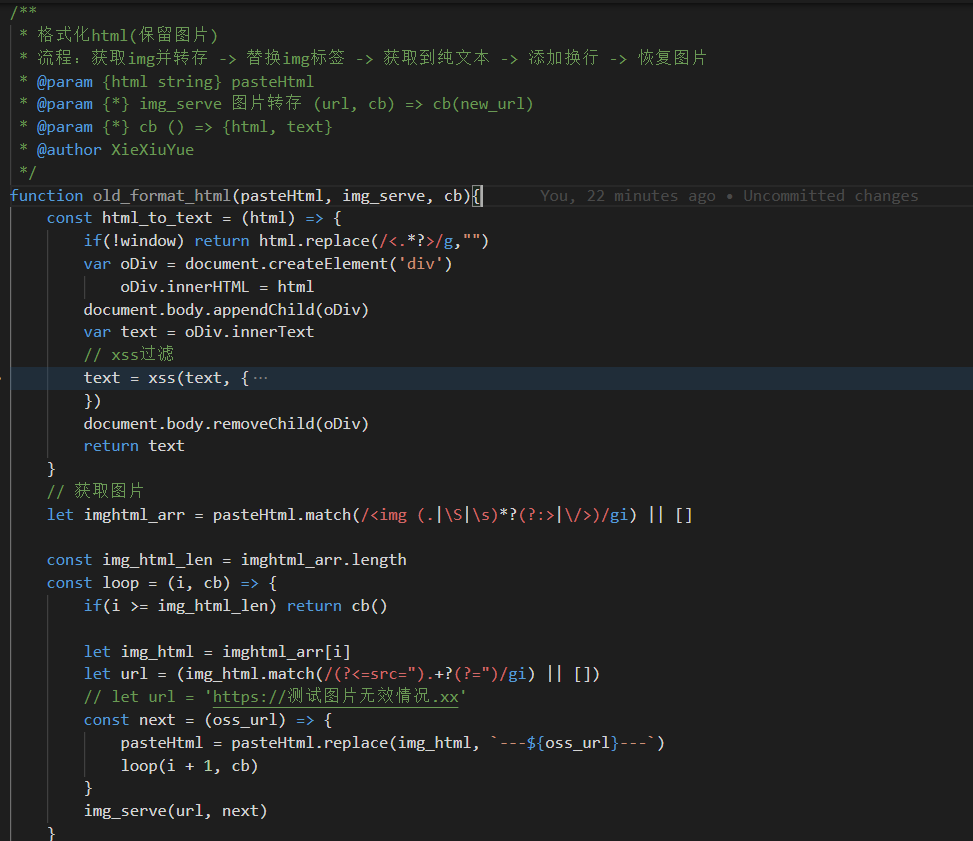
虽然比较简单,但是也有几个地方需要注意的是
- 图片复制粘贴进来的直接下载会跨域,也就别想绕过去了,弄个代理吧 (1)
- world复制竟来的别想了拿到图片,纯web做不到,因为拿到的是纯本地路径,可以提醒单图复制粘贴
- 复制进来图片最好先检验是否图片存在,检验可以新建一个img,然后看是否走入onload
- 微信公众号的比较特殊,如果用nginx(大神忽略), 返回图片是一个微信警告,可以用nodejs做代理
Koa代理代码
main.js
const error_img_url = 'https://hongqiaojiaoyu.oss-cn-shenzhen.aliyuncs.com/huazhang/imgs/error.png'
const Koa = require('koa');
const app = new Koa();
const get_url_buffer = require('./js/get_url_buffer')
const port = 3024
// 响应
app.use(async (ctx, next) => {
const path = ctx.request.path
console.log(path)
if(path.match(/^\/_proxy\/.*/)){
var body = await new Promise(function(resolve, reject) {
get_url_buffer(
(path.match(/(?:(?<=\/_proxy\/)).*/) || [error_img_url])[0],
(body) => {
resolve(body)
},
(uri) => {
console.log(uri)
}
)
})
ctx.set("Access-Control-Allow-Origin", "*")
ctx.status = 200
ctx.type = 'jpg'
ctx.length = Buffer.byteLength(body)
ctx.body = body
}
});
app.listen(port);
console.log(`启动完成 端口${port}`)
get_url_buffer.js
var http = require('http')
var https = require('https')
const url = require('url')
/**
* 获取图片buffer
* @param {*} _url 要转换的地址
* @param {*} success 成功 success(buffer)
* @param {*} fail 失败 fail(uri)
*/
var get_url_buffer = (_url, success, fail) => {
var uri = url.parse(_url)
// console.log(uri)
console.log(_url)
var option = {
...uri,
method: 'GET',
}
var handle_cb = (res) => {
if(res.statusCode === 301){
const url = res.headers['location']
console.log('重定向', url)
get_url_buffer(url, success, fail)
return
}
var img = []
var size = 0
res.on("data", (chunk) => {
img.push(chunk)
size += chunk.length
})
res.on("end", () => {
// console.log(size)
const buffer = Buffer.concat(img, size)
success(buffer)
})
}
if(uri.protocol === 'https:'){
return https.request(option, handle_cb).end()
}
if(uri.protocol === 'http:'){
return http.request(option, handle_cb).end()
}
console.log('协议异常', uri)
fail(uri)
}
module.exports = get_url_buffer
- 下载的时候判断是不是https的
- 判断是不是重定向了,重定向就拿到定向后的代码继续
到这里,我们实现了第一个功能
但是这时候需求添加了一条,如下
图文、换行,指定样式
这时候我们不好下手,我们需要做一个抉择
- 样式怎么来,换行怎么计算。
- 或者用哪个插件
- 或者要不换个富文本算了。
如果已经有一定修改这时候换富文本不太合适,只能去抄别人富文本的或者去找插件。
但是我遇到了如下两个问题,所以还是决定自己来
- 看起来抄代码很容易,其实代码绑定性质很强的
- 插件看了
slate-paste-html-plugin,但是用起来一堆报错,就放弃了
思路
1: 要去掉垃圾代码,我们就需要重组html格式
2: 去掉html但是样式不会影响
3: 要计算出换行
这个不太好说,我画了一张图
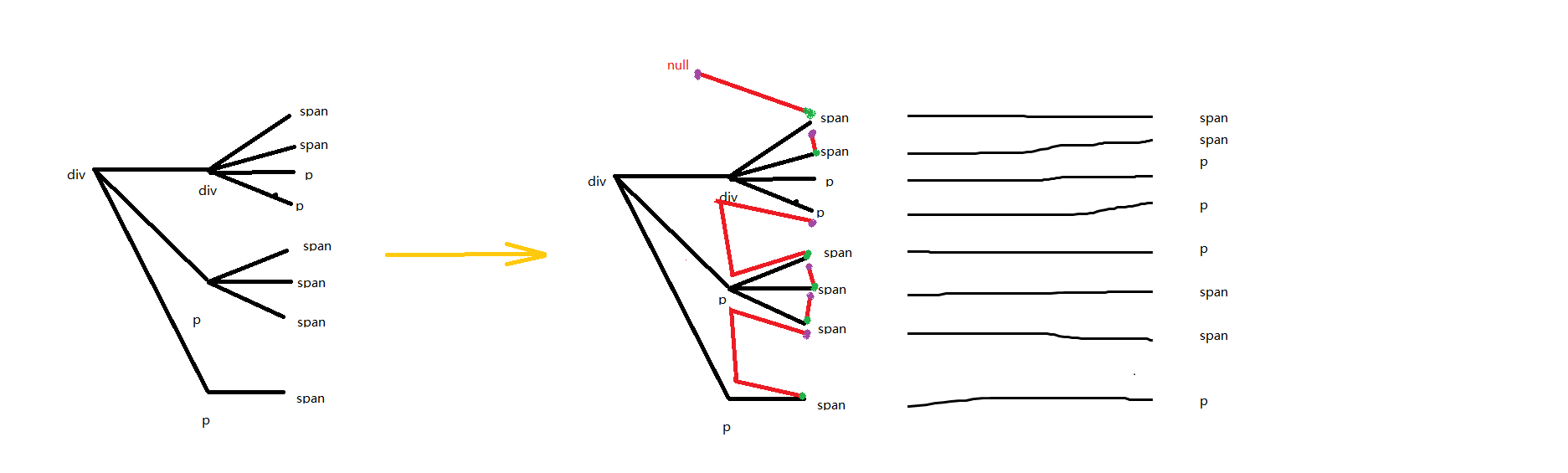
左侧那个是dom树,右侧是修改规则 (但是这个是理想状态,实际获取到的代码不会这么理想,稍后再说怎么解决)
- 通过左图可以看楚,div里面会有span或者p
- 当然还有其他,这个p代表的是块元素,span代表的是行内块元素
- 我们把dom拍扁,这样格式化出来就没有垃圾
- 排扁后我们需要对元素进行换行操作,这时候需要块元素和行内元素了,我们需要计算这个,计算规则在下一行
- 右侧图,红色代表寻找路径,绿色代表起点,红色经过的区域如果没有块元素,那么当前起点的dom就算是行内块,反之亦然
- 为了性能,我们需要先判断他是不是块元素,如果是块元素,就不需要再找路径了
有了思路,就可以实现了
实现
我们需要先递归获取每一个节点,如果是最后一个,那么就计算。 (嗯,很完美
but, 刚刚不是说了,有些不是很符合理想,比如长这样
<p>
我是文字
<span>我也是</span>
</p>
按照思路,我们不应该拿这样的dom
所以需要先转下, 代码如下,相信你们可以看懂。
补全span
/**
* 补全span
* @param {*} html html片段
*/
function tag_full(html){
const tag = 'span'
const reg1 = /(?<=\<(?:\/\w|\w).*>)([^<|>]*)(?=<\w.*>)/g
const reg2 = /(?<=\<(?:\/\w).*>)([^<|>]*)(?=<\/\w.*>)/g
const replace_value = (_, p1) => (p1.replace(/\s|\S|t|r/, '') == '' ? '' : `<${tag}>${p1}</${tag}>`)
return html.replace(reg1, replace_value).replace(reg2, replace_value)
}
转完之后,我们拿最后的节点,但是我们还缺少红色路径。
但是,红色路径怎么拿,看起来有点复杂,我们先拿到当前节点路径再说,就让其他的事情随风吧。
递归获取节点
function traverse_tree(node, path){
if (!node) return
if (node.children && node.children.length > 0) {
for (let i = 0; i < node.children.length; i++) {
let next_node = node.children[i]
traverse_tree(next_node, [...path, {node: node, index: i}])
}
}else{
// 其他代码...
}
}
通过递归,我们遍历的时候顺手拿下节点路径和每个路径下面的节点。
拿到之后,我们和上面一个node节点(这里指的是最后节点)计算分叉位置, 代码如下
获取分叉点
/**
* 获取分叉点
* @param {*} old_path [number]
* @param {*} path [number]
*/
function get_path_diff_index(old_path, path){
let index = 0
let k = 0
for(let item of path){
old_path[k] === item && index++
k++
}
return index
}
然后计算什么类型就可以了。
这时候,我们就可以再对img、等标签处理了,还有样式。
样式代码送上
设置样式
/**
* 根据style设置style
* @param {*} node node节点
* @param {<filter_styles>} styles ['bold']
*/
function set_style(node, filter_styles){
let style = {}
for(let item of filter_styles){
switch(item){
case 'bold': {
let key = 'font-weight'
let value = get_style(node, key)
value >= 600 && (style[key] = item)
break
}
case 'color': {
let value = get_style(node, item)
console.log(node, value)
style[item] = value
break
}
}
... 其他
}
return style
}
然后
合并HTML
/**
* 合并html
* @param {*} html_arr
*/
function merge_html(html_arr){
function get_style_string(style){
let style_string = ''
for(let key in style){
style_string += `${key}:${style[key]};`
}
return style_string ? ` style="${style_string}"` : ''
}
const res = html_arr
.map(e =>
e.tag === 'img' ? `<p><img src="${e.src}" class="userChoosImg" style="max-width:100%;display: inline-block;" /></p>` :
block_element_tags.includes(e.tag) ?
// 忽略空白文本
(e.text === '' ? '' :
`<${e.tag}${get_style_string(e.style)}>${e.text}</${e.tag}>`) :
``
)
.join('')
console.log('html_format_res: ', res)
return res
}
然后再循环判断img,把img合并处理,既然走之前的处理图片方法即可。
效果图
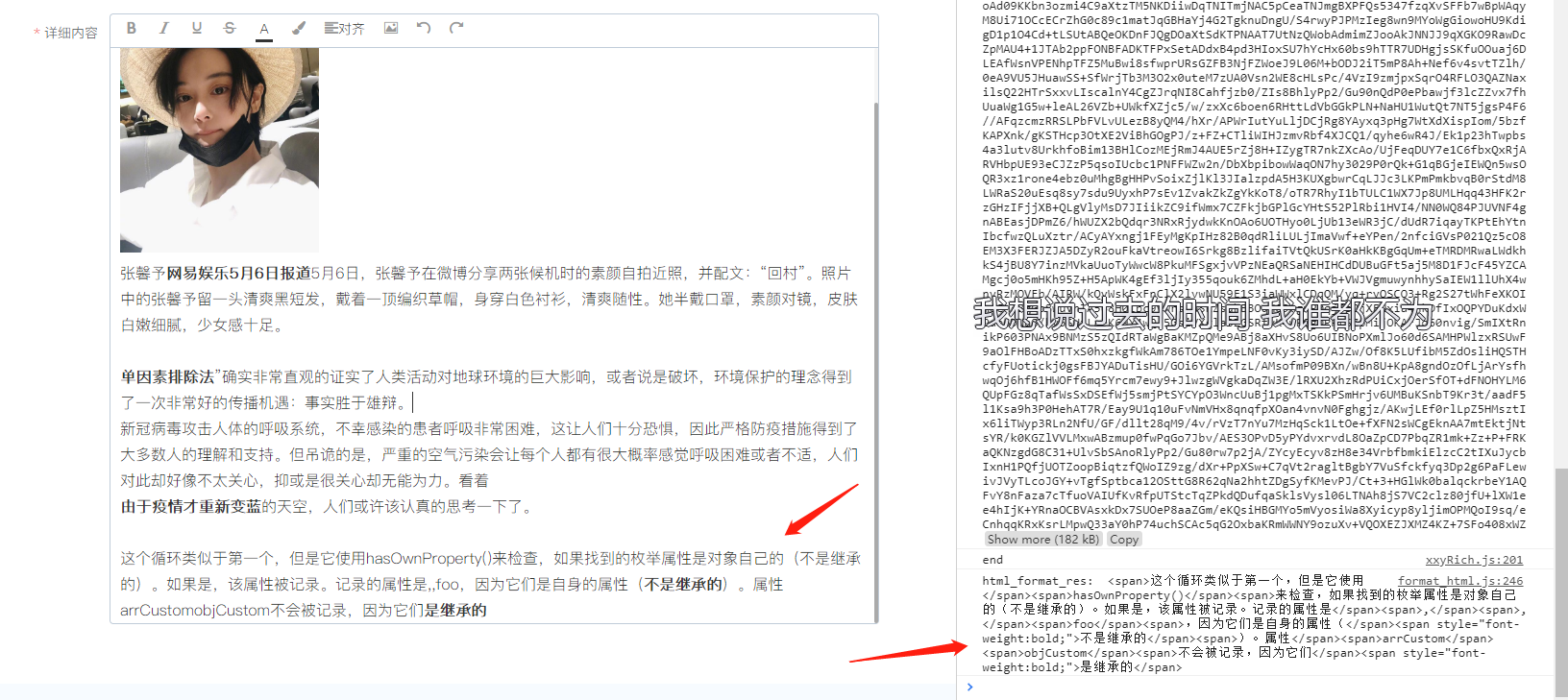
尾声
点个赞再走呗
--完--
