文/Yorkie
大家好,今天为大家正式介绍下 Pipcook,它是淘系技术部 D2C 团队研发的一款面向前端开发者的机器学习应用框架,我们希望 Pipcook 能成为前端人员学习和实践机器学习的一个平台,从而推进前端智能化的进程。
本篇文章的目的也是希望大家在阅读后,能了解到 Pipcook 已经做了哪些,以及想要做到哪些后,从而号召对前端智能化有想法和有代码的同学们一起加入,让前端智能化朝着我们想象中的样子演进。
为什么会有 Pipcook?

从上面的图中,可以看到 imgcook、ideacook、reviewcook 等等,它们统称为前端智能化项目,比如 ideacook,解决的是如何从产品文档生成产品代码的场景、imgcook 解决的是如何从视觉稿生成业务代码的问题,而 reviewcook 则是帮助我们解决一些代码上线前的智能化回归验证。
那么 Pipcook 的定位就是为上述这些智能化项目提供夯实可靠的机器学习平台,让前端人员就能完成上面提到的那些事情。
那么,在你决定开始使用 Pipcook 之前,不妨先问一下自己下面几个问题:
- 你是否想了解机器学习?
- 你是否想自己动手训练一个模型?
- 你是否想自己部署你的模型?
- 你是否想掌握不断优化自己模型的能力?
如果你有上面的想法的话,那么就可以继续了解 Pipcook 了,因为 Pipcook 也正是为了帮助前端开发者解决这些问题的。
灵活、丰富的 Pipeline
看到这里,你可以会懵到底什么是 Pipeline,不过没关系,我们先从一个例子开始:
{
"plugins": {
"dataCollect": {
"package": "@pipcook/plugins-mnist-data-collect",
"params": {
"trainCount": 8000,
"testCount": 2000
}
},
"dataAccess": {
"package": "@pipcook/plugins-pascalvoc-data-access"
},
"dataProcess": {
"package": "@pipcook/plugins-image-data-process",
"params": {
"resize": [28,28]
}
},
"modelDefine": {
"package": "@pipcook/plugins-tfjs-simplecnn-model-define"
},
"modelTrain": {
"package": "@pipcook/plugins-image-classification-tfjs-model-train",
"params": {
"epochs": 15
}
},
"modelEvaluate": {
"package": "@pipcook/plugins-image-classification-tfjs-model-evaluate"
}
}
}
上面的 JSON 就是我们称为一个 Pipeline 的东西,这也是 Pipcook 中的 “Pip” 的来源,我们希望每个应用就是由不同的 Pipeline 组成的,然后我们针对机器学习的流程,将 Pipeline 分为了不同的阶段,并且在每个阶段提供了不同的插件,这样做的好处是可以随时更换不同的插件以快速地获得结果,同时也隐藏掉了插件下面的技术和算法细节,从而降低 Pipeline 使用者的心智负担,大家只需要知道每个插件是做什么的就可以了。
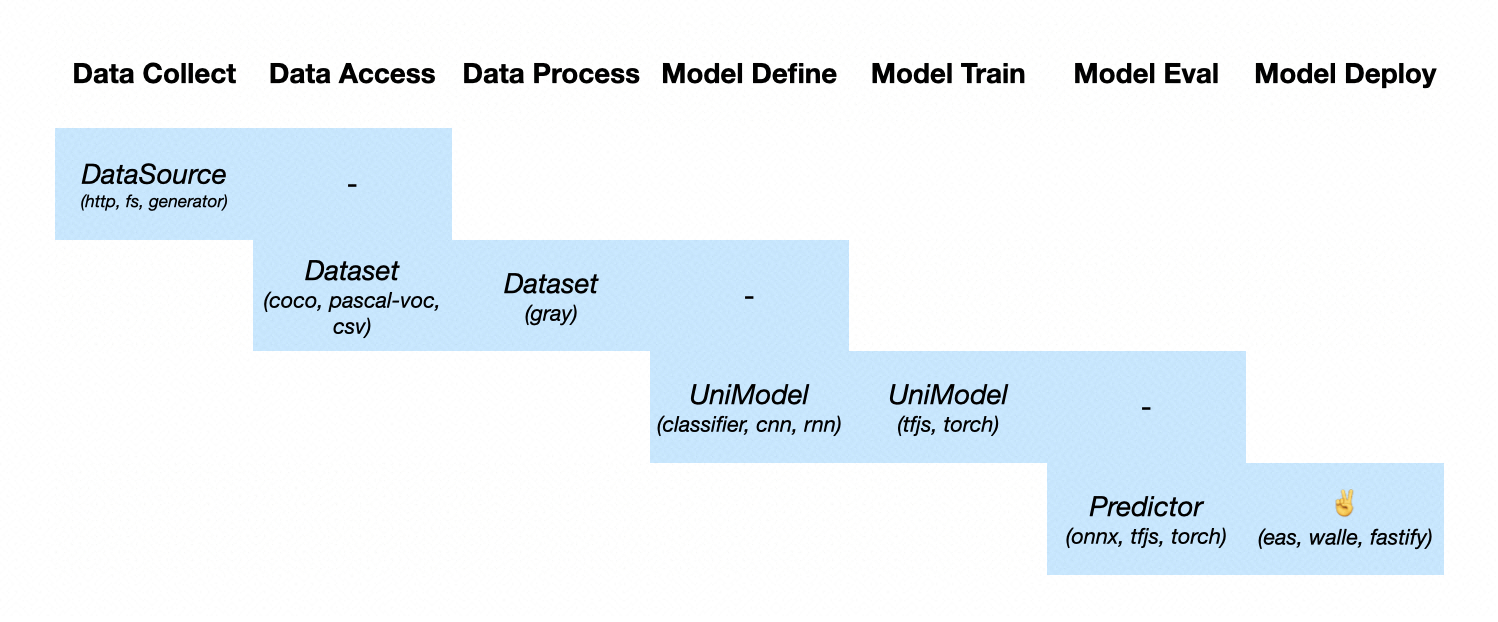
上图就是 Pipcook 中一个常规 Pipeline 的流程,他们分别是:
- Data Collect:用于收集你要用于机器学习训练的数据,比如图片、文本、音频等;
- Data Access:用于将上一个阶段收集的数据转换为模型可以接收的样本集;
- Data Process:对样本的数据做一些额外的处理,比如图片尺寸的统一、把图片变为灰度图、文本向量化等;
- Model Define:用于定义你用来训练的模型;
- Model Load:除了可以定义模型外,我们也提供了 Model Load 插件用于加载已经训练好的模型;
- Model Train:将 Data Process / Data Access 的样本,用来训练之前在 Model Define 定义好的模型;
- Model Evaluate:一般在模型训练完成后,都会需要评估模型的效果如何,就跟我们的单元测试一样;
- Model Deploy:最后模型评估结果如果是可以接受的话,那么就能将这个模型部署上线了,这个阶段的插件就是帮助大家完成模型的部署;
稳定、可靠的前端机器学习生态
前面说完了 Pipeline,接下来说一下插件,Pipcook 为每个插件会提供独立的运行时,在这个运行时中,我们特别增加了一种通过 JavaScript 调用到 Python 的能力——Boa。
const boa = require('@pipcook/boa');
const fs = require('fs');
const glob = require('glob').sync;
const acorn = require('acorn');
const { set, len, list } = boa.builtins();
const { DBSCAN } = boa.import('sklearn.cluster');
const { word2vec } = boa.import('gensim.models');
const cwd = process.cwd();
let files = [];
files = files.concat(glob(cwd + '/lib/**/*.js'));
const sentences = [];
const vec2word = {};
const samples = files
.map((f) => fs.readFileSync(f))
.map((s) => {
let ast;
try { ast = acorn.parse(s); } catch (e) {
console.error('just ignore the error');
}
return ast;
})
.filter((ast) => ast !== undefined)
.reduce((list, ast) => {
const fn = ast.body.filter((stmt) => stmt.type === 'FunctionDeclaration');
list = list.concat(fn);
return list;
}, []);
samples.forEach((sample) => sentences.push([ sample.id.name ]));
const { wv } = word2vec.Word2Vec(sentences, boa.kwargs({
workers: 1,
size: 2,
min_count: 1,
window: 3,
sg: 0
}));
const X = sentences
.map((s) => wv.__getitem__(s)[0])
.map((v, i) => {
const r = [ v[0] * 100, v[1] * 100 ];
vec2word[r] = samples[i].id.name;
return r;
});
const db = DBSCAN(boa.kwargs({ eps: 0.9 })).fit(X);
const labels = db.labels_;
const n_noise_ = list(labels).count(-1);
const n_clusters_ = len(set(labels));
console.log(n_noise_, n_clusters_, set(labels));
上面的代码完成了以下操作:
- 通过 acorn 库(JavaScript)来解析给定的 JavaScript 代码,获取所有的函数名;
- 通过调用 genmis.models 库(Python)中的 Word2Vec 来将步骤1的函数名转为向量表示;
- 通过调用 sklearn.cluster 库(Python)中的 DBSCAN 来完成将函数名进行分类的任务;
可以看到,通过 @pipcook/boa 我们将 Python 生态与 Node.js 生态几乎完美地结合在了一起,最后完成对给定文件内的函数名分类(聚类)的机器学习任务,更多关于 Boa 的文章可以从下面的文章中了解:
这篇文章中,我们主要为大家解释一个疑惑,那就是通过 Boa 调用 Python,和直接使用 Python 代码,到底会不会导致性能很差?我们的回答是不会,而且至少是跟纯 Python 代码保持几乎一致的性能。
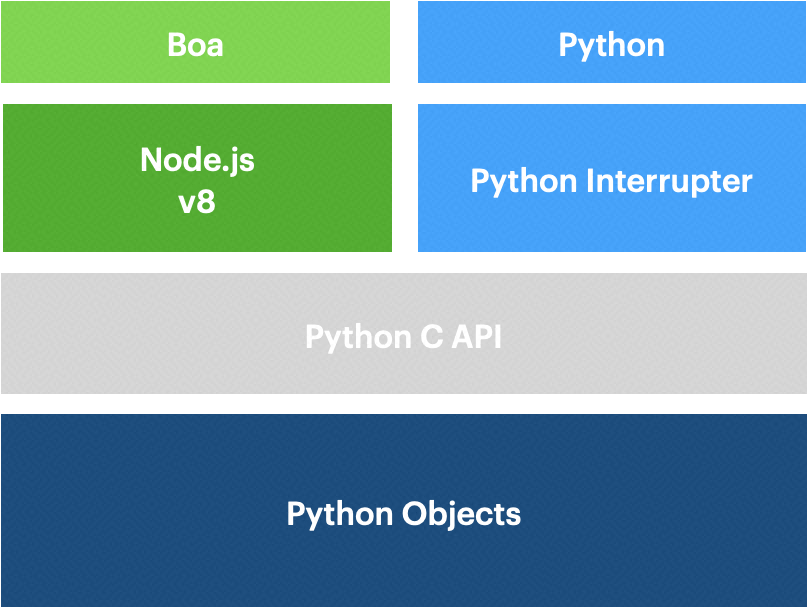
上面的图就是为了说明这个问题而画的。无论对于 Boa 还是 Python 来说,最下面一层都是 Python Objects,这里包含了 Python 中所有函数的定义、变量的定义以及操作符的定义等等,然后对于 Python 代码来说,就是通过它自己的解释器将 Python 代码转换成对 Python Objects C API 的调用。
对于 Boa 来说,也是一样的,由 V8 完成对 JavaScript 代码的解析,然后再将对应的操作映射到 Python Objects,因此两者的差异就在于 v8 和 Python Interrupter 对于各自代码的执行效率了,那么对于这一点来说,Python 和 JavaScript 都有各自的优化策略和方法,所以几乎是不相伯仲的。
其实这里想表达的是,虽然听上去是要从 JavaScript 调用到 Python,但其实从实现的机制来说,并非将 JavaScript 转成 Python 代码,然后再由 Python 解释器执行,而是直接与 Python 中的对象打交道,这样也就减少了中间那层额外的开销,所以大家可以放心使用。
在性能问题解决之后,我们再说一下 Boa 对于前端智能化的意义,它将意味着我们不再需要像 nodejieba 或者是其他这样的桥接库了,Boa 就像一扇通往机器学习新世界的大门,从此 JavaScript 的世界中,可以以非常低的成本就能够使用到最成熟、最前沿的机器学习生态了。
未来——面向前端开发者的应用框架
通过 Pipeline 以及 Boa,Pipcook 已经可以为开发者在机器学习道路上贡献不少基石了,但我们认为这——仍然远远不够,核心的门槛问题并没有得到解决,比如使用 Pipeline 部署了一个模型后,然后呢?比如使用 Boa 参照 sklearn 的例子完成了一个机器学习算法的开发,然后呢?
模型的效果不好,开发者如何优化?样本到底有没有问题?为什么我的这个模型最后的评估结果那么低?这些对于毫无基础的前端工程师来说,都是难以解决的问题,而这些问题将大部分的前端开发者拦在了机器学习之外。
因此在 Pipcook 正式发布 1.0 版本时,我们引入了一个叫 MLApp 的概念,即——机器学习应用框架,它跟 Vue、React、Angular 一样,就是帮助我们完成应用开发的,只不过它面向的是机器学习的应用。
我们还是先来看一段代码:

在 MLApp 中,我们通过 TypeScript 的类型系统,为每个涉及到机器学习的模块都声明了 ml.Function 类型,并通过 ml.create(fn) 函数创建,然后在创建的时候,可以在 fn 中使用机器学习的 API,最后只需要在任何的 Node.js 函数中调用创建的函数就可以了。
在写好代码后,先别着急运行,因为直接通过 ts-node/node 是无法成功执行的,因为机器学习本身是分为训练和预测两个阶段,但是在代码中我们并没有看到训练相关的代码,这是为什么呢?
原因是 MLApp 都封装在了 Pipcook 的命令中了,如下:
$ pipcook train example.ts --epoch=15 --sample_path=...
...
generated the model at example.ts.im
...
$ pipcook try example.ts
$ pipcook deploy example.ts --eas-config=...
正如上面的命令,我们将机器学习中的训练和预测都封装起来了,这样用户在写一个机器学习应用的时候,只需要关心我要做什么事,以及如何跟 Node.js 其他的功能集成起来,就像今天比如要使用 Node.js 写一个 PDF 的渲染服务,那么你需要做的就是调用 PDF 的渲染库,然后将它们与你的服务器路由集成起来。
那么未来的前端机器学习应用也是如此,通过 MLApp 表达你要做的机器学习任务类型和数据类型,然后 Pipcook 将会辅助你一步步完成从数据收集、数据处理、模型训练到最后 ML 应用部署。
在现有的 Pipcook 1.0 规划中,我们计划增加 NLP 和 Vision 的能力到我们的 MLApp API 中,大家如果感兴趣可以到我们的 issue#33 中参与讨论。
如何加入 Pipcook
如果你坚持读到了这里,一定是对于机器学习和 Pipcook 产生了一定的兴趣,那么我们非常欢迎你加入到我们的技术演进中来,贡献你的一份力量!
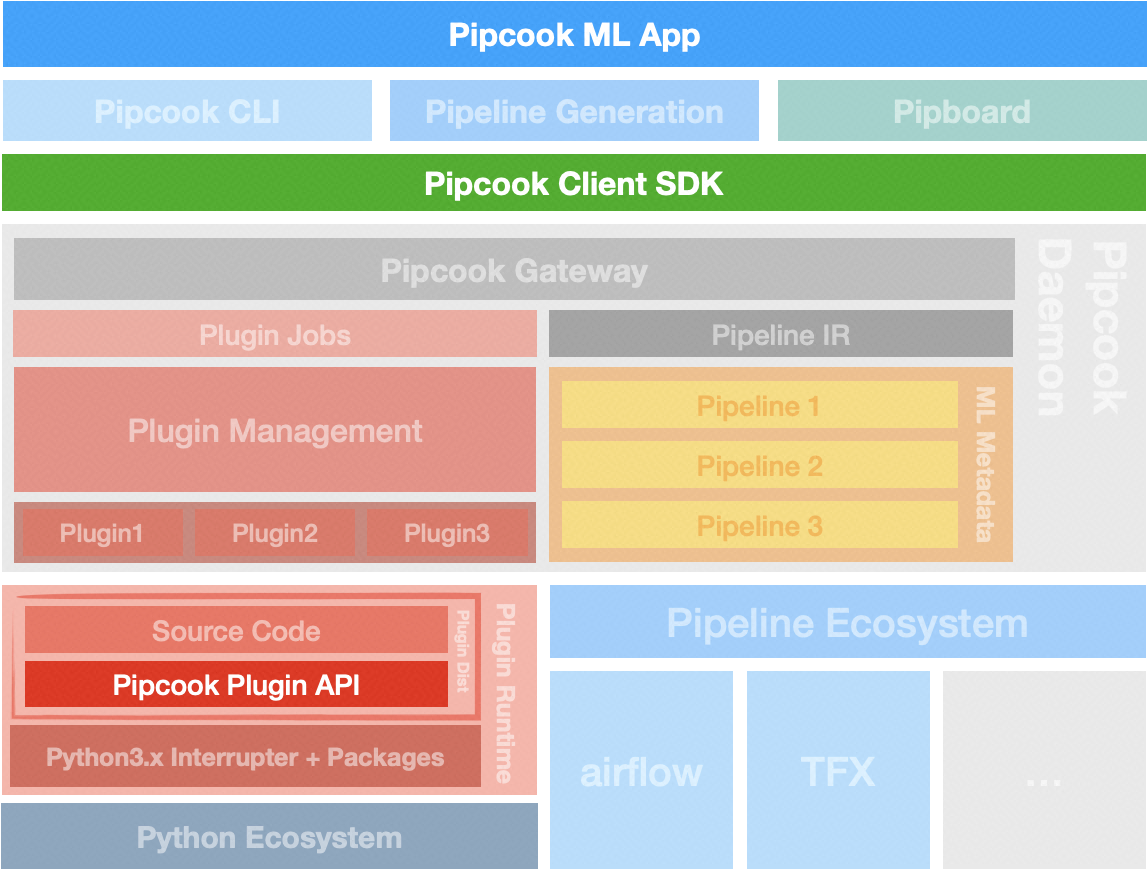
上图中,我们把几个关键节点已经明确地标注出来:
- 如果你对于定义机器学习应用框架感兴趣,那么可以从 MLApp 入手
- 如果你对于 Pipeline,还有机器学习工程框架感兴趣,可以从 Pipcook Client SDK 入手
- 如果你对于 Boa 以及提供稳定可靠的机器学习生态感兴趣的,那么可以从我们的 Plugin API 入手
另外,我们也整理了一些 Issue 方便你快速参与进来:
- 如果你想参与我们架构设计的讨论及实现,那么可以看这里:github.com/alibaba/pip…
- 如果你想参与代码贡献,我们提供了 Good first issue:github.com/alibaba/pip…
最后,也非常欢迎你加入到我们的 Pipcook Community 群里一起畅所欲言: