

概览
这是一篇hello world级别的文章, 给AI大佬们递茶🍵
此篇文章将带你了解
- 什么是tensorflow.js
- 如何使用预训练模型进行语音识别
- 如何用迁移学习训练自定义的模型
- 如何用自定义的模型进行语音识别
我们将识别的东北话如下
此篇待完善中...
tensorflow.js
首先看一个tensorflow.js的应用, 据说小姐姐们都喜欢, 请用马爸爸的APP扫码体验

推荐选择实时试色
这是小姐姐的真人教学

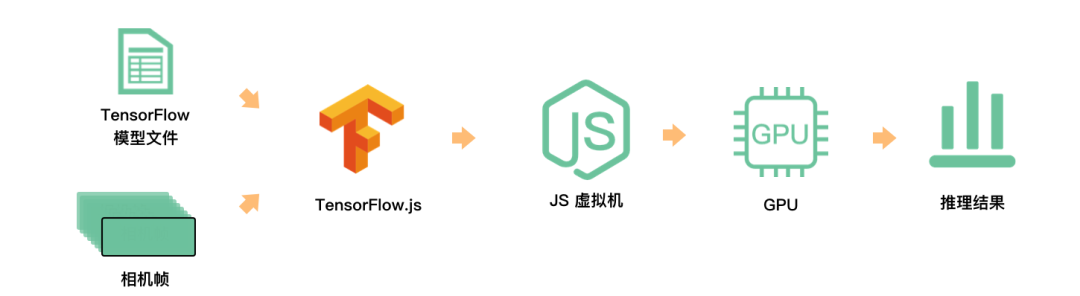
如下是这个炫酷APP的原理
然后祭出谷歌大法的tensorflow的官网: tensorflow.google.cn/
tensorflow.js是能在浏览器和Node.js中使用的机器学习库, 有更好的实时性
tensor, 张量, 是向量和矩阵向更高维度的扩展, 说人话, 相当于多维数组
神经网络, 一种网状的数据结构, 神经网络的每一层都要存储N维数组, 进行N层的for循环运算, Tensor可以把for循环向量化, 从而方便GPU加速
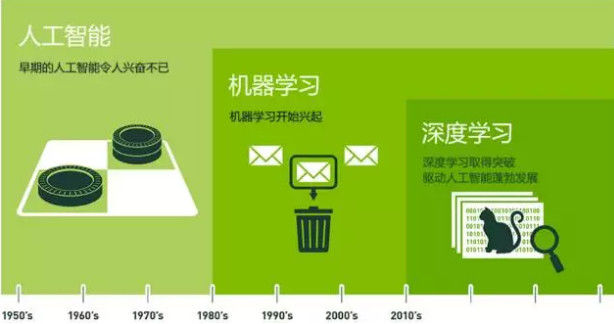
补充说一下人工智能, 机器学习, 深度学习的关系, 如下图
使用预训练模型进行语音识别
预训练模型: 某些大厂已经预先训练好的, 可以开箱即用的的模型, 这些模型有多种格式, tensorflow.js可以用web格式的模型文件
一些tensorflow.js模型可以在这里找到: github.com/tensorflow/…
其中有本文我们要用到的语音模型
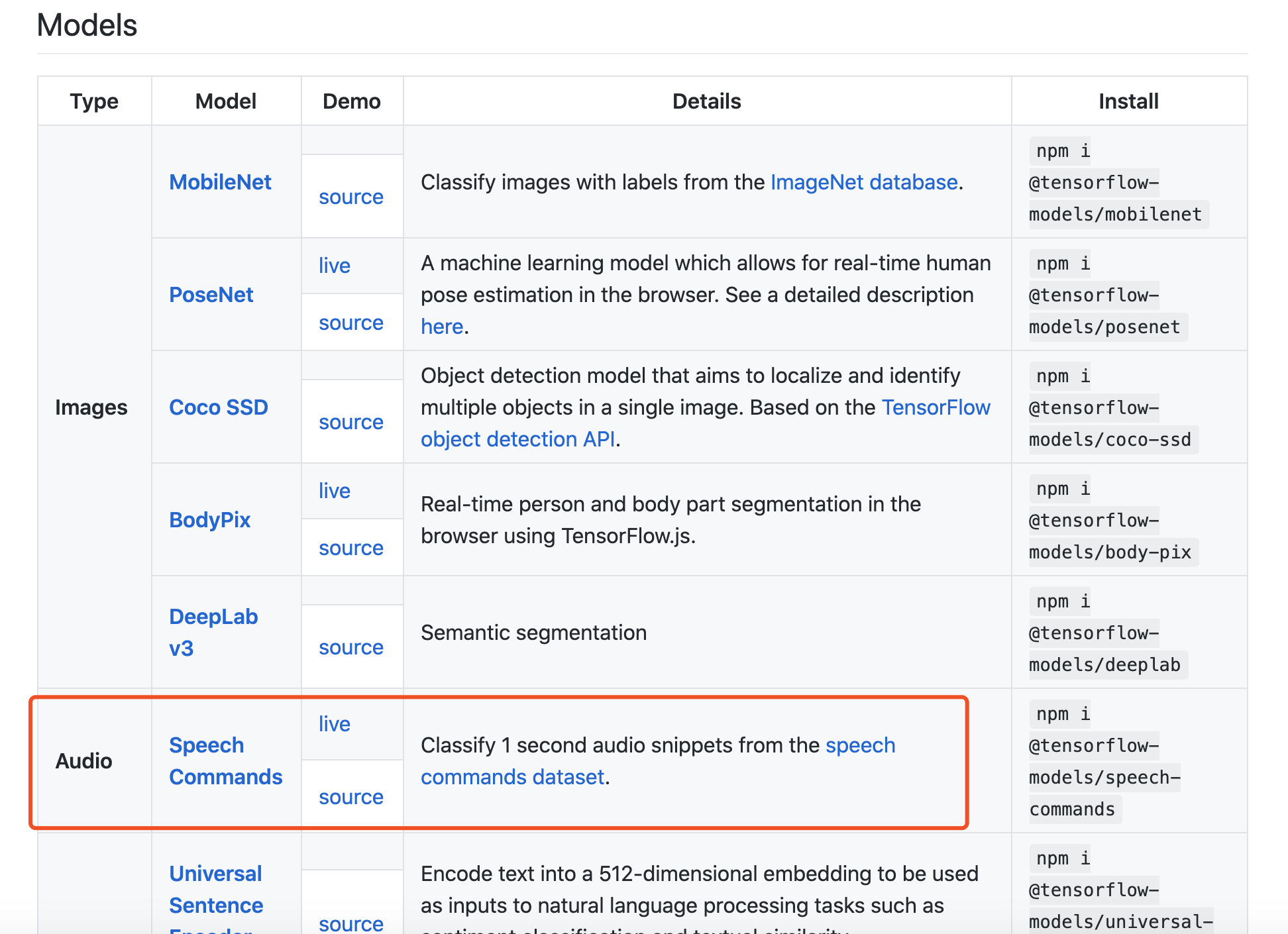
可以打开语音命令模型的测试链接体验一下: storage.googleapis.com/tfjs-speech…
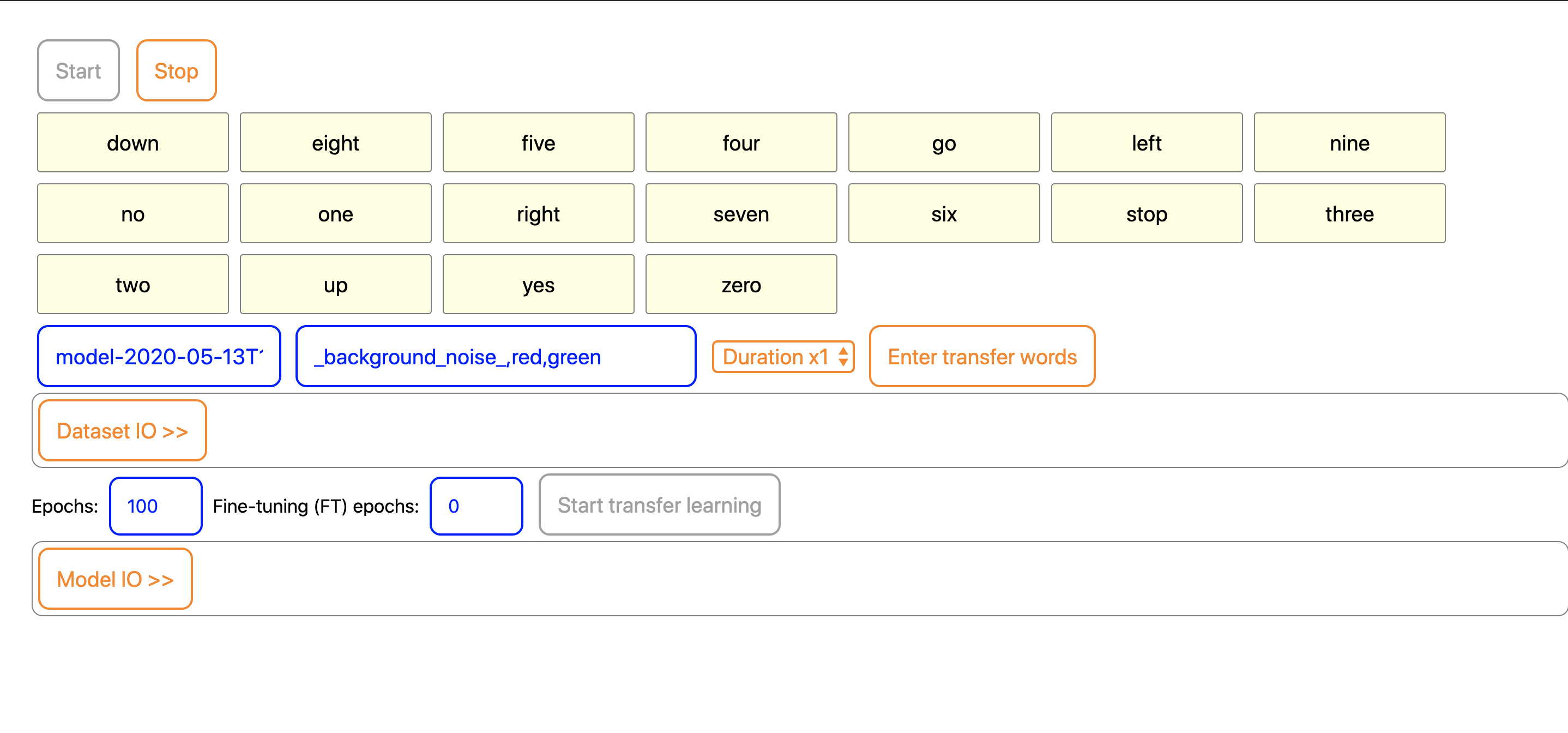
并且, 我们在测试链接里扒下来模型链接和元信息链接以及分片的模型数据(group1-shard1of2, group1-shard2of2)
语音识别的基本定义: 输入音频, 输出分类数据
语音识别的基本原理: 音频 -> 声谱图 -> 卷积神经网络识别图像
注意:
- 开启录音权限需要使用https协议
- 模型文件的链接需要使用绝对路径
<template lang='pug'>
.speech
button.btn(
v-for="(item, index) in labels"
:class="{'current': index === currentIndex }"
) {{ item }}
</template>
<script lang="ts">
/**
* @description 使用预训练模型进行语音识别
*/
import * as tf from '@tensorflow/tfjs'
import * as speechCommands from '@tensorflow-models/speech-commands'
import Vue from 'vue'
import Component from 'vue-class-component'
const PATH = window.location.origin + window.location.pathname
@Component
export default class SpeechComponent extends Vue {
labels = []
currentIndex = -1
mounted() {
this.init()
}
async init() {
const recognizer: speechCommands.SpeechCommandRecognizer
= speechCommands.create(
// 浏览器原生的傅里叶变换
'BROWSER_FFT',
// 自定义单词
null,
// 模型链接
PATH + 'data/speech/model.json',
// 元信息链接
PATH + 'data/speech/metadata.json'
)
// 识别器的确保模型加载好
await recognizer.ensureModelLoaded()
console.warn('recognizer', recognizer)
// 预训练模型里的单词
this.labels = recognizer.wordLabels()
console.warn('this.labels', this.labels)
// 注意用https, getUserMedia
// https://developer.mozilla.org/en-US/docs/Web/API/MediaDevices/getUserMedia
recognizer.listen(
result => {
const { scores } = result
const maxValue = Math.max(...(<Array<any>>scores))
this.currentIndex = (<Array<any>>scores).indexOf(maxValue)
return Promise.resolve()
},
// 流式识别的配置
{
// 重叠率
overlapFactor: 0.0001,
// 可能性阈值
probabilityThreshold: 0.9
}
)
}
}
</script>
<style scoped lang='stylus' rel='stylesheet/stylus'>
.speech
width 100vw
height 100vh
background-color #5CACEE
.label
float left
background-color #C9C9C9
font-size 17px
text-align center
height 25px
margin 5px
padding 5px
display table
color #ffffff
.current
background-color #CD69C9
color #9AC0CD
</style>
如何用迁移学习训练自定义模型
迁移学习: 存储已有问题的解决模型,并将其利用在其他不同但相关问题上.初衷是节省人工标注样本的时间,让模型可以通过已有的标记数据(source domain data)向未标记数据(target domain data)迁移。从而训练出适用于目标领域的模型。
说人话, 我们利用本来只识别英文单词的模型, 训练出能识别东北话的模型.
具体操作: 在浏览器中采集自定义语音训练数据, 包括背景噪音, 让模型知道哪些声音不用被识别, 然后保存并下载二进制的模型文件
<template lang="pug">
.container
button(@click="collect") 你瞅啥
button(@click="collect") 瞅你咋地
button(@click="collect") 背景噪音
pre {{ countInfo }}
button(@click="save") 保存
<br/>
button(@click="train") 训练
<br/>
span 录音开关
my-switch(class="switch" :isOpen="isRecording" @onSwitch="handleSwitch")
<br/>
span {{ result }}
</template>
<script lang="ts">
/**
* @description 使用预训练模型创建迁移学习器, 并产生自定义训练数据
*/
import * as tf from '@tensorflow/tfjs'
import * as speechCommands from '@tensorflow-models/speech-commands'
import * as tfvis from '@tensorflow/tfjs-vis'
import Vue from 'vue'
import Component from 'vue-class-component'
import MySwitch from '../common_components/switch.vue'
const PATH = window.location.origin + window.location.pathname
@Component({
components: {
MySwitch
}
})
export default class SpeechComponent extends Vue {
labels = []
currentIndex = -1
transferRecognizer: speechCommands.TransferSpeechCommandRecognizer = null
countInfo = ''
isRecording: Boolean = false
result = ''
mounted() {
this.createTransferRecognizer()
}
async createTransferRecognizer() {
const recognizer: speechCommands.SpeechCommandRecognizer
= speechCommands.create(
// 浏览器原生的傅里叶变换
'BROWSER_FFT',
// 自定义单词
null,
// 模型链接
PATH + 'data/speech/model.json',
// 元信息链接
PATH + 'data/speech/metadata.json'
)
// 识别器的确保模型加载好
await recognizer.ensureModelLoaded()
console.warn('recognizer', recognizer)
// 预训练模型里的单词
this.labels = recognizer.wordLabels()
console.warn('this.labels', this.labels)
this.transferRecognizer = recognizer.createTransfer('myTransfer')
}
async collect (e) {
const btn = e.target
btn.disabled = true
const label = btn.innerText
await this.transferRecognizer.collectExample(
label === '背景噪音' ? '_background_noise_' : label
)
btn.disabled = false
this.countInfo = JSON.stringify(
this.transferRecognizer.countExamples(),
null,
2,
)
}
async train () {
await this.transferRecognizer.train({
// 迭代次数
epochs: 100,
callback: tfvis.show.fitCallbacks(
{ name: '训练效果' },
// 度量, 查看损失, 准确度
['loss', 'acc'],
{ callbacks: ['onEpochEnd'] },
)
})
}
async handleSwitch () {
this.result = ''
if (!this.isRecording) {
this.isRecording = true
await this.transferRecognizer.listen(
result => {
const { scores } = result
console.warn('result', result)
const maxValue = Math.max(...(<Array<any>>scores))
const index= (<Array<any>>scores).indexOf(maxValue)
const labels = this.transferRecognizer.wordLabels()
console.log(labels[index])
this.result = ''
setTimeout(() => {
this.result = `你是不是在说 "${ labels[index] }"?`
}, 1000)
return Promise.resolve()
},
{
overlapFactor: 0.1,
probabilityThreshold: 0.9,
}
)
} else {
this.isRecording = false
this.transferRecognizer.stopListening()
}
}
save () {
const arrayBuffer: ArrayBuffer = this.transferRecognizer.serializeExamples()
const blob = new Blob([arrayBuffer])
const link = document.createElement('a')
link.href = window.URL.createObjectURL(blob)
link.download = 'data.bin'
link.click()
}
}
</script>
<style scoped lang="stylus" rel="stylesheet/stylus">
@import "~styles/custom.styl"
</style>
如何用自定义的模型进行语音识别
加载自定义模型, 训练完即可进行语音识别
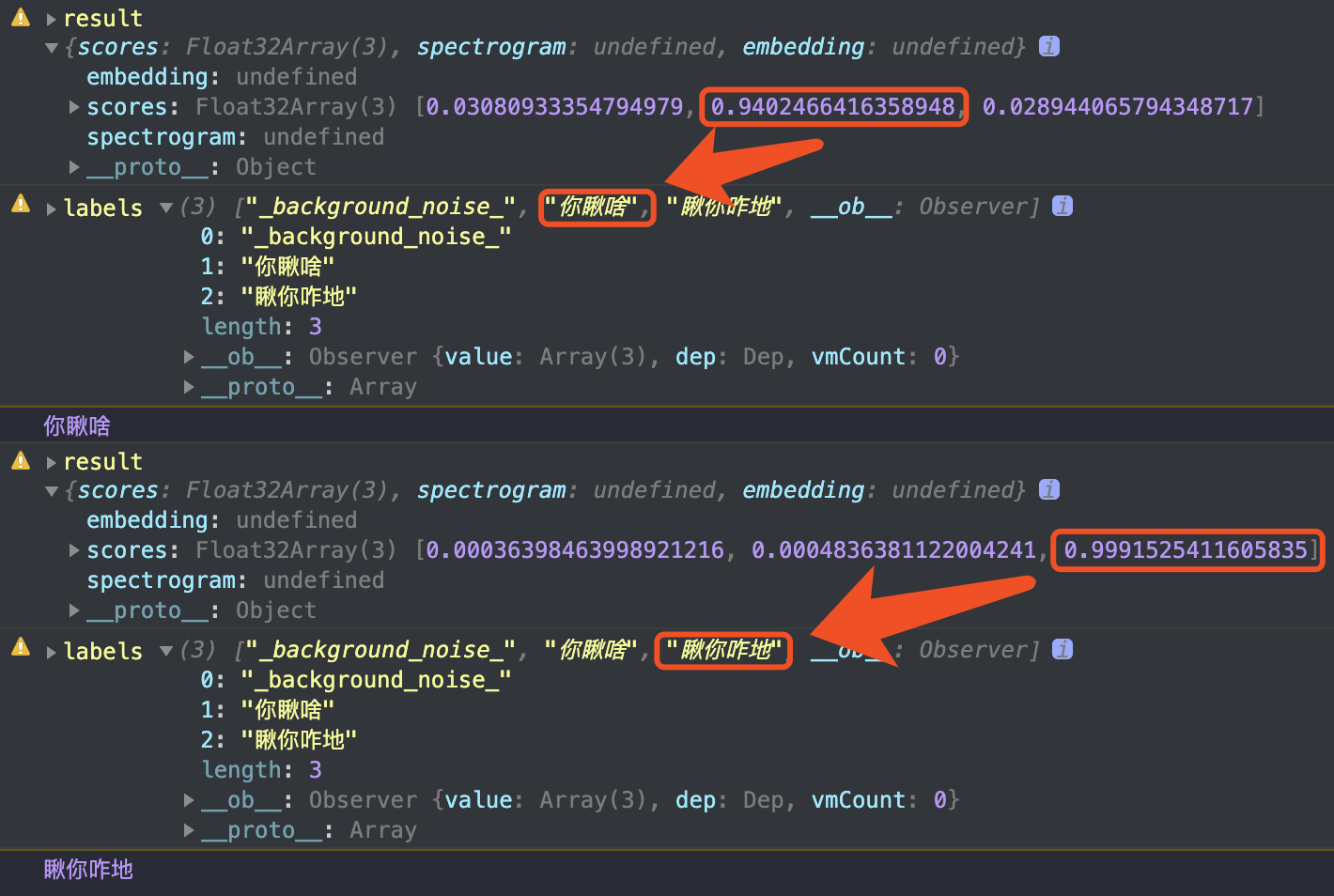
如下图, 第一次测评你瞅啥的可能性为94+,第二次测评瞅你咋地的可能性为99+
<template lang="pug">
.container(v-if="transferRecognizer")
span 操作步骤:
<br/>
span 1. 等待模型训练完
<br/>
span 2. 打开录音开关
<br/>
span 3. 说 "你瞅啥" / "瞅你咋地"
<br/>
<br/>
span 录音开关
my-switch(
:canOpen="canRecording"
:isOpen="isRecording"
@onSwitch="handleSwitch"
)
<br/>
span {{ result }}
</template>
<script lang="ts">
/**
* @description 使用自己的数据集训练模型并进行语音识别
*/
import * as tf from '@tensorflow/tfjs'
import * as speechCommands from '@tensorflow-models/speech-commands'
import * as tfvis from '@tensorflow/tfjs-vis'
import Vue from 'vue'
import Component from 'vue-class-component'
import MySwitch from '../common_components/switch.vue'
const PATH = window.location.origin + window.location.pathname
@Component({
components: {
MySwitch
}
})
export default class SpeechComponent extends Vue {
labels = []
currentIndex = -1
transferRecognizer: speechCommands.TransferSpeechCommandRecognizer = null
countInfo = ''
isTrainDone = false
isRecording = false
canRecording = false
result = ''
mounted() {
this.createTransferRecognizer()
}
async createTransferRecognizer() {
const recognizer: speechCommands.SpeechCommandRecognizer
= speechCommands.create(
// 浏览器原生的傅里叶变换
'BROWSER_FFT',
// 自定义单词
null,
// 模型链接
PATH + 'data/speech/model.json',
// 元信息链接
PATH + 'data/speech/metadata.json'
)
// 识别器的确保模型加载好
await recognizer.ensureModelLoaded()
console.warn('recognizer', recognizer)
// 预训练模型里的单词
this.labels = recognizer.wordLabels()
console.warn('this.labels', this.labels)
this.transferRecognizer = recognizer.createTransfer('myTransfer')
const res = await fetch(PATH + 'data/speech/data.bin')
const arrayBuffer = await res.arrayBuffer()
this.transferRecognizer.loadExamples(arrayBuffer)
console.warn(this.transferRecognizer.countExamples())
await this.transferRecognizer.train({
// 迭代次数
epochs: 100,
callback: tfvis.show.fitCallbacks(
{ name: '训练效果' },
// 度量, 查看损失, 准确度
['loss', 'acc'],
{ callbacks: ['onEpochEnd'] },
)
})
this.canRecording = true
}
async handleSwitch () {
this.result = ''
if (!this.isRecording) {
this.isRecording = true
await this.transferRecognizer.listen(
result => {
const { scores } = result
console.warn('result', result)
const maxValue = Math.max(...(<Array<any>>scores))
const index= (<Array<any>>scores).indexOf(maxValue)
const labels = this.transferRecognizer.wordLabels()
console.log(labels[index])
this.result = ''
setTimeout(() => {
this.result = `你是不是在说 "${ labels[index] }"?`
}, 1000)
return Promise.resolve()
},
{
overlapFactor: 0.1,
probabilityThreshold: 0.9,
}
)
} else {
this.isRecording = false
this.transferRecognizer.stopListening()
}
}
}
</script>
<style scoped lang="stylus" rel="stylesheet/stylus">
@import "~styles/custom.styl"
</style>
