

扫描下方二维码或者微信搜索公众号
菜鸟飞呀飞,即可关注微信公众号,阅读更多Spring源码分析、Java并发编程、Netty源码系列和MySQL工作原理文章。

1. 堆
二叉树可以被细分为普通二叉树、满二叉树、完全二叉树,而今天所分享的堆这种数据结构就是一种完全二叉树。
堆中的每个结点的值要么都大于左右子结点的值,要么都小于左右子结点的值。前者形成的是大顶堆,即堆顶元素是最大的;后者形成的是小顶堆,即堆顶元素是最小的。如下图所示,分表是一个大顶堆和小顶堆。
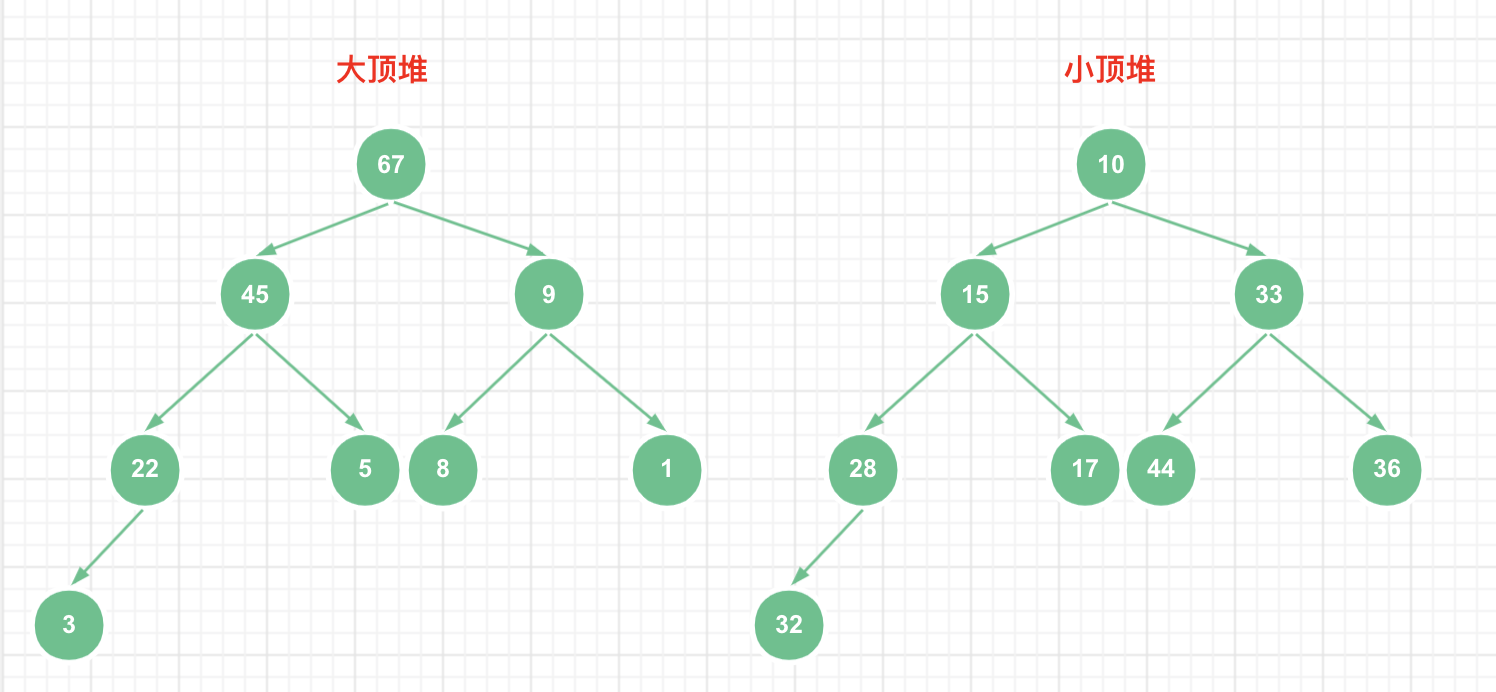
❝完全二叉树的特点是:最后一层的叶子结点靠左排列,从根结点到倒数第二层结点,是一颗满二叉树。通常储存二叉树这种数据结构的方法有链式存储和顺序存储,链式存储就是通过指针来维护左右子结点的关系,而顺序存储就是利用数组来存储。完全二叉树最适合用数组来存储,即堆这种数据结构适合用数组来存储。
❞
当用数组来存放堆元素时,如果堆顶的元素存放在索引为 1 的地方(不从 0 开始),那么左节点的索引为 2,右结点的索引为 3。也就是是说,如果父结点存放在数组索引为 i 的地方,那么左结点存放的位置为 2*i,右结点存放的位置为 2*i+1。
下面看下堆的常用操作:插入数据和删除堆顶数据
1.1 插入数据
以大顶堆为例,当向堆中插入数据时,新插入的数据首先放在数组的最后面,由于是大顶堆,而新插入的数据可能比父结点的值大,因此会出现不满足大顶堆性质的情况,这个时候需要调整数据的位置,这个过程,叫做堆化(heapify)。(堆化分两种:「向下堆化和向上堆化」,此时是向上堆化)
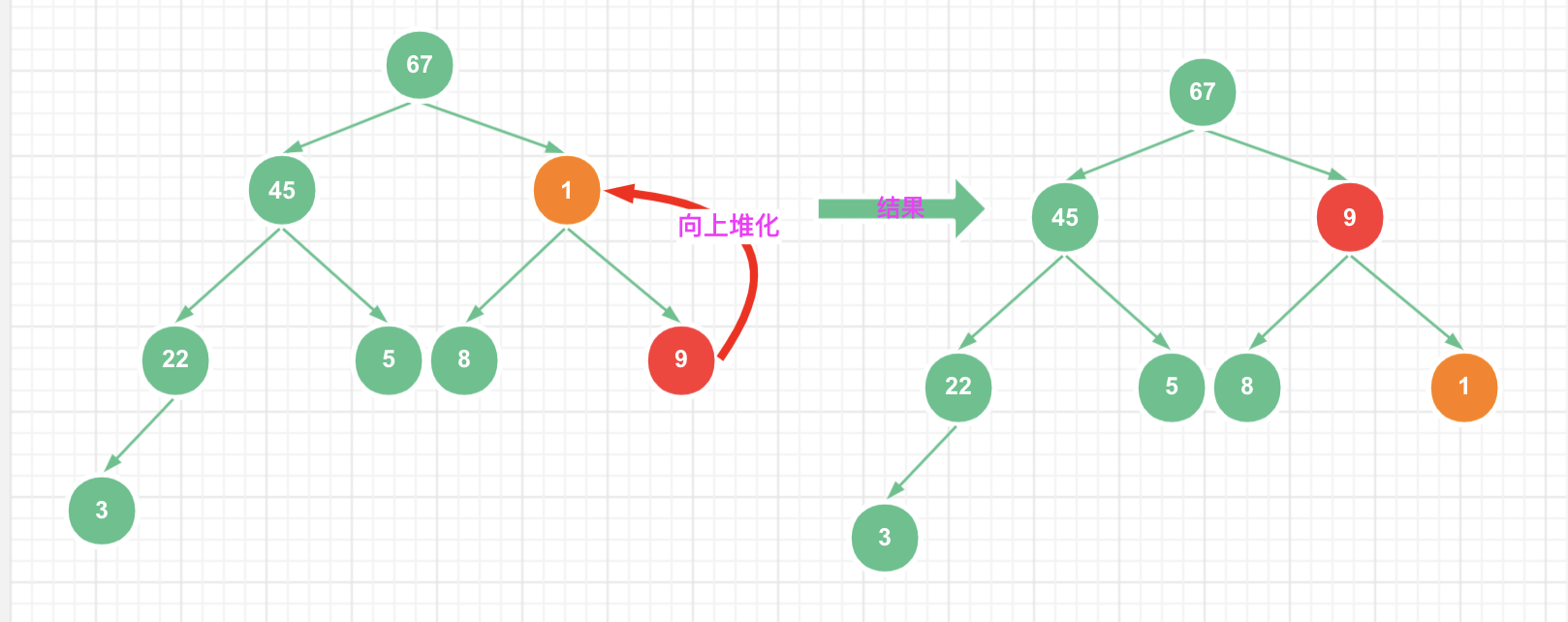
下面看下代码实现。
public class Heap {
private int[] heap; // 存放数据
private int capacity; // 堆的最大容量
private int count; // 堆中目前存放的数据个数
public Heap(int capacity) {
this.heap = new int[capacity + 1]; // 数组下标为0的地方不存放元素(这样计算左右子结点的位置的时候,方便表示)
this.capacity = capacity;
this.count = 0;
}
public void insert(int data) {
if (count >= capacity) return; // 堆满了
count++;
heap[count] = data;
int i = count;
while (i / 2 > 0 && heap[i] > heap[i / 2]) { // 如果子结点的数据比父结点大,就堆化,交换位置
swap(heap, i, i / 2); // 交换数据
i = i / 2;
}
}
// 交换下标a1和下标a2的数据
private static void swap(int[] heap, int a1, int a2) {
// 不借助额外的内存空间,来交换两个数
heap[a1] = heap[a1] ^ heap[a2];
heap[a2] = heap[a1] ^ heap[a2];
heap[a1] = heap[a1] ^ heap[a2];
/**
* 上面三行代码等价于这几行代码
* int tmp = heap[a2];
* heap[a2] = heap[a1];
* heap[a1] = tmp
*/
}
}
1.2 删除堆顶数据
还是以大顶堆为例,当要删除堆中最大的元素时,其实就是删除堆顶元素。删除完堆顶元素后,需要从堆中找出一个最大的元素放到堆顶。这个时候,通常是将数组中最后一个数据放到堆顶,由于这个数据可能不是最大的,因此也需要进行堆化,此时通常采用向下堆化的手段。代码实现如下:
// 删除最大元素
public void deleteMax() {
if (count == 0) return; // 空堆
heap[1] = heap[count];
count--;
heapify(heap, 1, count); // 从上往下堆化
}
// 堆化
private static void heapify(int[] heap, int i, int count) {
while (2 * i <= count) {
int maxIndex = i;
if (heap[i] < heap[2 * i]) maxIndex = 2 * i; // 和左结点比较
if ((2 * i + 1) <= count && heap[2 * i + 1] > heap[2 * i]) maxIndex = 2 * i + 1; // 如果右结点更大,则和右结点交换
if (maxIndex == i) return; // 如果左右子结点均小于当前结点,就表示不需要堆化了,直接返回
swap(heap, i, maxIndex); // 交换数据
i = maxIndex;
}
}
2. 堆排序
堆顶的元素要么是最大的,要么是最小的,如果我们每次从堆顶取一个元素,那么每次取到的数据就是最大或者最小,依次取完,那么取出来的数据就是有序的了。
使用堆排序有一个优点,就是「不需要额外的内存空间」,直接基于原数组,就可以完成排序操作。
堆排序大概分为两个步骤:「建堆和排序」。建堆是指根据指定的数组,将其变为满足堆这种数据结构的数据。建堆的思路有两种,一种是从下往上建堆(前面的插入数据过程就是从下往上建堆),一种是从上往下建堆。下面以从上往下建堆为例,构建一个大顶堆,示例代码如下。
// 建堆(从上往下建堆)
public static int[] buildHeap(int[] a) {
int length = a.length;
// 数组a的下标为0的地方不存放元素
for (int i = length / 2; i >= 1; i--) { // 叶子结点不需要堆化,因为叶子结点下面是没有左右子结点的,无法向下堆化
heapify(a, i, length - 1);
}
return a;
}
在从上往下建堆的过程中,叶子结点是不需要堆化,因为叶子结点下面是没有左右子结点的,无法向下堆化。
接下来是排序过程,排序过程中,由于是大顶堆,所以将堆顶元素与数组最后的元素交换,然后刨去数组最后一个元素,将剩余元素进行堆化,循环遍历,这样数组就是变成从小到大排列的有序数组了。示例代码如下:
// 排序
public static void sort(int[] a) {
a = buildHeap(a); // 先建堆
int i = a.length - 1;
while (i > 1) {
swap(a, 1, i); // 将第一个数放到数组后面
i--;
heapify(a, 1, i); // 堆化
}
}
3. 能用堆解决的问题
堆的应用十分广泛,例如 Top K 这一系类的问题,都能用堆来解决。假如现在有 10 亿数据,要取其中最大的 10 个数据,如果我们对这 10 亿个数据都进行排序,肯定能得到结果,但是数据量太大,如果都进行排序就会非常耗 CPU,而且我们只需要其中的 10 个数据,对所有数据排序,显然有点太浪费了。如果用堆来解决,我们可以建立一个可以存放 10 个数据的「小顶堆」,在初始时,可以先一次放入 10 个数据,后面在遍历剩下的数据时,判断是不是比堆顶的元素大,如果大,就将现在的堆顶元素删除,然后将当前数据放入到堆中;如果小于或者等于,则不做任何操作,这样最终就能得到这 10 亿个数据中最大的 10 个数据了。
另外,定时任务也可以用堆来实现。每个任务会在指定的时间来执行,这个时候,可以将任务达到时间最小的任务放到小顶堆的堆顶,那么每次执行时,就取堆顶的任务执行即可。
堆还可以用来实现优先级队列。在优先级队列中,每次从队列中取出的元素肯定是优先级最低或者最高的元素,这恰好与堆中的小顶堆和大顶堆对应。在 Java 中提供了工具类 PriorityQueue 来实现优先级队列,下一篇文章将结合 PriorityQueue 的源码来分析一下堆在 Java 中的应用。
4. 总结
总结一下,堆是一棵完全二叉树,它适合采用数组来存储数据。大顶堆的堆顶元素是堆中最大的元素,小顶堆中的堆顶元素是堆中最小的元素。
采用堆这种数据结构,对数据进行排序时,不需要占用额外的存储空间,效率也很高,时间复杂度为 O(nlogn)。
在文中的例子中,在使用数组存储堆的数据时,将数组下标为 0 的位置,没有存储元素,这是为了方便计算左右子结点的位置。实际上,下标为 0 的位置也可以用来存放元素,不同的是,计算左右子结点的位置的公式变了。
