

1. RabbitMQ起源和特点
RabbitMQ是采用 Erlang 语言开发的 AMQP(Advanced Message Queuing Protocol,高级消息队例协议)的开源实现。 它最初起源于金融系统,用于在分布式系统中存储转发消息。
RabbitMQ的具体特点可以概括为以下几点:
可靠性:RabbitMQ 使用一些机制来保证可靠性,如持久化、传输确认及发布确认等。灵活的路由:在消息进入队列之前,通过Exchange来路由消息。扩展性:多个MQ节点可以组成一个集群,可以根据根据实际业务情况动态扩展集群。高可用性:队列可以在集群机器上设置镜像,使得部分节点出现问题时队列仍然可用。- 多种协议:RabbitMQ 支持多种消息队列协议,除了AMQP外,还支持STOMP、MQTT等。
- 多语言客户端:RabbitMQ 几乎支持所有常用语言,比如 Java、Python、C等;
- 管理界面:RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息 、节点等。(Web管理界面也是一种插件,还可以通过HTTP API进行管理)
- 插件机制:RabbitMQ 提供了许多插件,来从多方面进行扩展,也可以编写自己的插件。
2. RabbitMQ相关概念
2.1 基本概念
RabbitMQ整体上是一个生产者与消费者模型,主要负责接收、存储和转发消息。
RabbitMQ模型架构如下图:
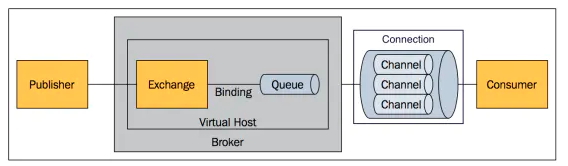
上图中涉及的概念主要有:
(1)消息(Message)
消息一般可以包含2个部分:消息体和消息属性。消息体(也成payload)一般是带有业务逻辑结构的数据,比如Json字符串;消息属性用于表述消息,比如消息对应的Exchange名称和RoutingKey。
(2)生产者(Producer)
生产者就是发送消息的一方。
- 个人理解本质上就是一个channel,channel执行了basicPublish的API。
(3)消费者(Consumer)
消费者就是接收消息的一方。
- 个人理解本质上是一个channel中basicConsume的对应的回调函数。
(4)队列(Queue)
队列在RabbitMQ中用于存储消息。生产者所发送的消息最终被投递到队列中,消费者从队列获取消息并消费。
- RabbitMQ中消息只存储在队列中,Exchange只做路由、不存储消息。
- 所有队列都绑定到默认交换机exchange="",并且绑定时使用的routingKey=queueName
(5)交换机(Exchange)
生产者将消息发送给Exchange,Exchange再将消息路由给队列。
- 消息的路径是:
生产者->交换机->队列。
(6)路由键(RoutingKey)
生产者在发送消息时,需要指定Exchange和RoutingKey,并且队列和Exchange之间的绑定关系也通过RoutingKey来标识。
(7)绑定(Binding)
绑定可以理解为一个三元组<queueName, exchangeName, bindingKey>,表示将queue用bindingKey绑定到exchange,该exchange收到的消息时,会根据exchange类型和消息的routingKey将消息路由到符合的队列。
- 也可以将交换机绑定到交换机。
(8)节点(Broker)
节点是一个RabbitMQ服务器实例,一个集群中有多个节点,这些节点可以在多台机器上,也可以在同一台机器上(端口不同)。
(9)虚拟主机(Virtual Host)
虚拟主机是共享相同身份认证和加密环境的独立服务器域。不同虚拟主机之间是相互隔离的,拥有独立的交换机、队列、绑定等。
- 可以将
虚拟主机与节点之间的关系理解为数据库与mysql之间的关系,一台mysql服务上有不同的数据库。
(10)连接(Connection)
Connection是客户端与服务器之间建立的一个网络连接。
(11)信道(Channel)
Channel可以理解为一种轻量连接,多个channel共享一个Connection。
由于创建和销毁Connection的开销大,所以在Connection内部建立Channel。
- 不同的Channel之间
互相隔离; - Channel是
双向的数据通道。 - RabbitMQ几乎所有操作均是
通过Channel完成,包括发送消息、创建队列、交换机等、消费消息。先创建Connection、然后创建Channel,再使用Channel执行操作。

2.2 Exchange
2.2.1 交换机参数
以Java Channel接口API来说明创建交换机的主要参数。
Exchange.DeclareOk exchangeDeclare(String exchange, String type, boolean durable, boolean autoDelete,
boolean internal, Map<String, Object> arguments) throws IOException;
exchange:交换机名称。type:交换机类型。durable:是否持久化。取值为true时,broker重启后交换机仍然存在。autoDelete:是否自动删除。有一个队列与该交换机绑定过,在该交换机所有绑定关系都被解绑时,交换机会被MQ自动删除。internal:是否是内置的。客户端无法直接将消息发送给内置交换机,只能通过其它交换机将消息路由到内置交换机。arguments
2.2.2 交换机类型
RabbitMQ常用交换机类型有fanout、direct、topic四种。
2.2.2.1 广播模式(fanout)
当一个交换机是广播模式的话,所有绑定到该交换机上的队列(或交换机)都能收到路由的消息,不论bindingKey的取值。
- 对
队列而言,无论队列与交换机绑定时bindingkey取值是什么、也不论生产者发送消息时的routingkey是什么,该队列都可以收到广播交换机上所有消息。 - 对于绑定到广播交换机上的
交换机而言,同样如此。
假设Exchange1是广播交换机,Exchange2是direct交换机,队列Queue1、Queue2绑定到Exchange2交换机。那么Exchange2可以收到Exchange1上所有消息,但是队列Queue1和Queue2只能收到routingKey(生产者设定)与bindingKey一致的消息。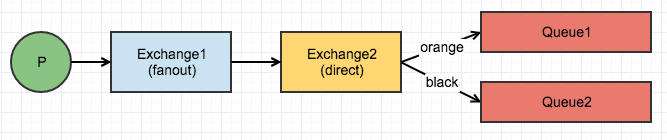
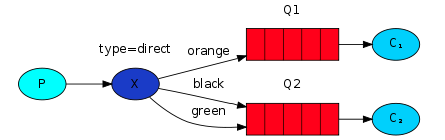
2.2.2.2 direct模式
direct类型交换机会将消息路由到bindingKey与routingKey完全一致的队列上。(不再特别讨论交换机绑定到交换机的情况)
- 一个队列可以使用不同的routingKey绑定到交换机多次,用于接收多种消息。比如对于消息时日志、日志分不同级别,queue1可以配置成接收debug、warning、info、error四种消息,queue2可以配置成只接收error消息。
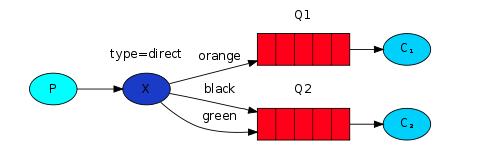
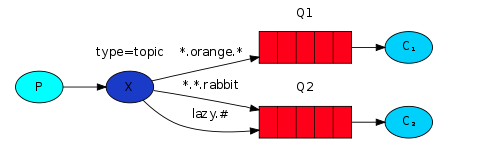
2.2.2.3 topic模式
当routingKey中采用点号“.”分割时,bindingKey可以表现为类似正则表达式形式,此时队列可以接收到符合bindingKey规则的多个routingKey的消息,而不用像direct模式一样进行多次绑定。
- 生产者发送消息时,使用的routingKey是完整的,且每个单词间用.分割。
- bindingKey中可以使用特殊字符*和#,*用于匹配一个单词,#用于匹配零或多个单词。
如下图,对于routingKey为quick.orange.rabbit、lazy.orange.elephant、quick.orange.fox、lazy.brown.fox、lazy.pink.rabbit,Q1可以收到前3个routingKey的消息,Q2可以收到第1、2、4、5个routingKey的消息。
2.3 队列
同样以Java Channel接口API来说明创建队列的主要参数:
public Queue.DeclareOk queueDeclare(String queue, boolean durable, boolean exclusive,
boolean autoDelete, Map<String, Object> arguments)
queue:队列名。durable:是否是持久化的。取值为true时,broker重启队列也存在。需要注意的是队列持久化不代表消息持久化;
提一个项目中遇到的问题,项目中使用了RabbitMQ Cluster,且使用了持久化队列。在RabbitMQ Cluster中,队列只存在于一个broker上,当该broker不可访问(宕机、发生网络分区等原因),且没有镜像队列来保证高可用性,会使得队列不可用。由于业务上可以容忍短时间内一些数据丢失,这时候选择在重连时进行队列的删除、重新创建等操作,不过由于队列设置了持久化,会使得剩余broker同样存有队列元数据,导致无法执行删除动作,后考虑将队列durable属性设为false,这样队列所在节点宕机后,其它节点上也不存在队列,可以重新创建队列,保证一定程度可用性。exclusive:是否是排他的。取值为true时,队列仅对首次声明它的Connection可见。包含以下含义:(1)队列存在时,后续执行声明队列的Connection无法访问队列;(2)占有队列的Connection内Channel都可以访问队列;(3)当占有队列的Connection断开时,队列将被自动删除。autoDelete:是否是自动删除的。当队列被消费者连接过,之后所有消费者连接都断开时,队列将会被自动删除。包含以下含义:(1)当一个队列被创建了,还没有被消费时,队列是不会被删除的;(2)所有消费连接断开时,队列会被删除,即便现在还有生产者在发送消息,队列已经不存在了。arguments。
需要注意的是,每个队列都绑定了默认direct模式交换机,且bindingKey为队列名。需要直接往队列发送消息的话,可以设置exchange=""、routingKey=queueName。
2.4 绑定
绑定可以分为队列绑定到交换机和交换机绑定到交换机。
2.4.1 队列绑定到交换机
以Java Channel接口API来说明队列绑定到交换机的主要参数:
public Queue.BindOk queueBind(String queue, String exchange,
String routingKey, Map<String, Object> arguments)
queue:队列名exchange:交换机名routingKey:称为bindingKey更加合适
2.4.2 交换机绑定到交换机
以Java Channel接口API来说明交换机绑定到交换机的主要参数:
public Exchange.BindOk exchangeBind(String destination, String source,
String routingKey, Map<String, Object> arguments)
destination:可以类比队列绑定的参数,用消息传递的目的方更好理解。source:被绑定的交换机,用消息传递的来源更好理解。routingKey:称为bindingKey更加合适。 被发送到source交换机的消息,如果消息的routingkey匹配destination交换机的bindingkey或者说source交换机是广播模式,那么消息将被转发到destination交换机。
2.5 其它概念
(1)consumerTag
consumerTag是消费者唯一标识,用于区分不同的消费者。
- 实际测试,同一channel里面不同consumer的consumerTag也不同。
(2)deliveryTag
deliveryTag是消息被投递给消费者时的唯一编号,该参数最常用与消费者ack消息。
- 实际测试,deliveryTag唯一的范围是
channel,而不是consumer。同一个channel的不同consumer收到消息时的deliveryTag不同。
(3)correlationId
correlationId是请求唯一标识,可用于将RPC的请求和响应关联起来,需要客户端在生产消息时生成并并设置给消息属性。
3. RabbitMQ特性
在相关概念之后,介绍一些RabbitMQ的常见特性。
3.1 消费方式
RabbitMQ消费方式分两种,推模式(basic.consume)和拉模式(basic.get)。
- 推模式下channel被设置为投递模式,在消费者订阅队列之后,RabbitMQ会不停将消息推送给消费者,直到取消订阅(或者未ack消息数目达到上限)。
- 推模式适合
持续订阅,拉模式适合订阅单条消息。 - 如果用在循环中basic.get来代替basic.consume,会严重影响RabbitMQ性能。推模式
吞吐量远高于拉模式,一般都应采用推模式;
3.2 生产者确认
生产者如何保证发送的消息被确实投递到RabbitMQ中呢?
RabbitMQ提供两种方式来实现生产者确认:
- 事务机制
- 发送方确认(publisher confirm)机制
3.2.1 事务机制
事务相关操作涉及事务开启(channel.txSelect())、事务提交(channel.txCommit())和事务回滚(channel.txRollback())。
先进行事务开启,然后发送消息,最后事务提交,提交失败进行事务回滚。在执行事务开启和事务提交之后,RabbitMQ都会回复OK回调。事务提交成功,则消息一定到达了RabbitMQ。
- 个人疑问,如果事务提交失败,是不是代表消息一定发送失败?此时重发是不是会有重复发送的可能性?
- 事务机制是可以用于消费者,可以回滚手动ack之类,实际需要测试一下。
需要注意的是,事务对性能影响巨大,批量发送消息开启事务和不开启事务性能可以相差百倍。
3.2.2 发送方确认机制(publisher confirm)
发送方可以将channel设置为confirm模式(channel.confirmSelect()),生产者发送消息后,RabbitMQ需要对生产者发送的消息进行confirm,生产者可以等待RabbitMQ回应的confirm(channel.waitForConfirms()),如果等待confirm返回false,认为消息发送失败,此时可以重新发送。
- 如果开启了持久化,消息落盘之后RabbitMQ才会confirm。
发送方确认机制弥补了事务机制的缺陷,提高了吞吐量。
需要注意的是,如果每发送一个消息后,都等待confirm,那么吞吐量和事务机制间并没有太大差距。发送方确认机制优势在于并不一定需要同步confirm,可以使用批量confirm和异步confirm。
批量confirm:发送一批消息后,执行等待confirm函数;异步confirm:提供回调函数,在收到RabbitMQ的confirm时执行回调,对于未能confirm的消息要进行重发。
3.3 消费者确认
https://www.rabbitmq.com/confirms.html
如果保证RabbitMQ发出的消息被消费者收到?或者说某个消费者因为机器负载较大不想处理消息,想由其它消费消费的话,该如何处理?
RabbitMQ提供了消费者确认机制,消费者执行basic.consume时可以设置autoAck。
autoAck为true时,当消息被发送出去(被写入到TCP中)时,消息就会被RabbitMQ从内存或磁盘删除(其实是先标记后删除)。
需要注意的是,这里不需要管消费者是否收到消息。autoAck为false时,只有当消费者手动ack后,消息才会被MQ删除,在收到Consumer的nack或者reject时会将消息重新放入队列或者丢弃掉。
3.4 消费者流控
RabbitMQ可以通过channel.Qos()设置prefetchCount或prefetchSize来控制Consumer接收消息的频率。(流控应该是只对推模式起作用)
prefetchCount:表示consumer未ack消息的数目上限,达到上限后consumer将无法消费消息,直至未ack消息数目降低。0表示没有上限。prefetchSize:表示consumer未ack消息的空间大小上限,单位是B。0表示没有上限。- 两者均可以设置global参数,表示是否channel中每个消费者都进行共享流控,共享流控时,假设prefetchCount是10,那么每个消费者的prefetchCount都是10。
3.5 持久化
RabbitMQ持久化分为交换机持久化、队列持久化和消息持久化。
交换机持久化:在声明交换机时,参数durable设置为true,borker重启后交换机仍存在。队列持久化:在声明队列,参数durable设置为true,borker重启后队列仍存在。消息持久化:消息持久化首先要求队列持久化,队列删除了消息也将丢失。在生产者发送消息时,可以通过设置BasicProperties中的deliveryMode=2,将投递模式设置为2,来进行消息持久化。
- 需要注意的是如果所有消息都开启持久化,会严重影响RabbitMQ性能。
参考文献
官网:https://www.rabbitmq.com/
https://www.rabbitmq.com/admin-guide.html
RabbitMQ实战指南
https://juejin.cn/post/6844903554721775629
https://www.cnblogs.com/vipstone/p/9350075.html
